撰稿:2017年11月13日由Rachel Thomas撰写
一个非常常见的场景:看似令人印象深刻的机器学习模型在生产中实施时是完全失败的。这些影响包括那些现在对机器学习持怀疑态度且不愿意再次尝试的领导者。怎么会发生这种情况?
对于开发结果与生产结果之间的这种脱节的最可能的罪魁祸首之一是选择不当的验证集(或者更糟糕的是,根本没有验证集)。根据数据的性质,选择验证集可能是最重要的一步。尽管sklearn提供了一种train_test_split方法,但该方法采用了数据的随机子集,这对于许多现实问题来说是一个糟糕的选择。
培训,验证和测试集的定义可能相当细微,有时不一致地使用这些术语。在深度学习社区中,“测试时间推断”通常用于指对生产中的数据进行评估,这不是测试集的技术定义。如上所述,sklearn有一种train_test_split方法,但没有train_validation_test_split。Kaggle只提供培训和测试集,但要做得好,您需要将他们的训练集分成您自己的验证和训练集。而且,事实证明Kaggle的测试集实际上被细分为两组。很多初学者可能会感到困惑,这并不奇怪!我将在下面解决这些微妙之处。
首先,什么是“验证集”?
在创建机器学习模型时,最终目标是使其准确处理新数据,而不仅仅是用于构建数据的数据。考虑下面一组数据的3种不同模型的例子: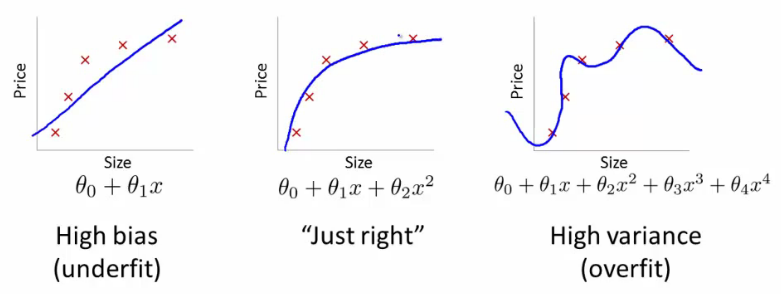
资料来源:Andrew Ng的机器学习课程
对于最右侧的模型,图示数据点的误差最小(蓝色曲线几乎完美地穿过红点),但它不是最佳选择。这是为什么?如果你要收集一些新的数据点,它们很可能不在右边图表中的那条曲线上,而是更接近中间图形中的曲线。
根本的想法是:
- 训练集用于训练给定的模型
- 验证集用于在模型之间进行选择(例如,随机森林或神经网络是否更适合您的问题?您想要一个有40棵树或50棵树的随机森林吗?)
- 测试集告诉你你是怎么做的。如果您已经尝试了很多不同的模型,那么您可能只是偶然得到一个在验证集上表现良好的模型,并且拥有测试集有助于确保不是这种情况。
验证和测试集的一个关键属性是它们必须代表您将来会看到的新数据。这可能听起来像一个不可能的命令!根据定义,您还没有看到这些数据。但是你仍然知道一些事情。
什么时候随机子集不够好?
看一些例子是有益的。虽然这些例子中有很多来自Kaggle比赛,但它们代表了您在工作场所会遇到的问题。
时间序列
如果您的数据是时间序列,那么选择数据的随机子集将非常简单(您可以在您尝试预测的日期之前和之后查看数据)并且不代表大多数业务用例(您在哪里)正在使用历史数据来构建将来使用的模型。如果您的数据包含日期并且您要构建将来使用的模型,则需要选择具有最新日期的连续部分作为验证集(例如,可用数据的最后两周或上个月) 。
假设您要将下面的时间序列数据拆分为训练和验证集: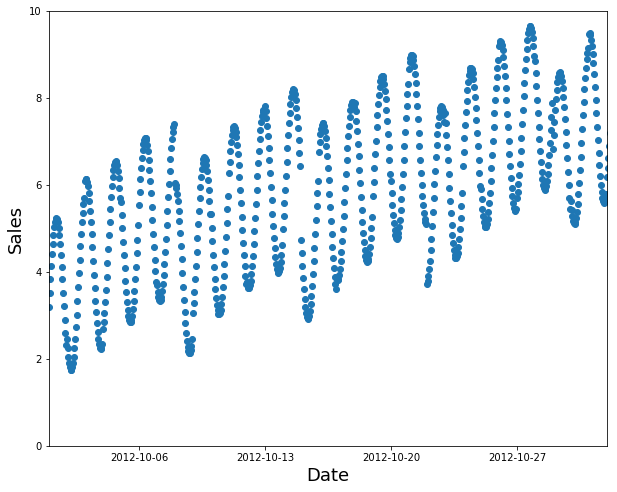
时间序列数据
随机子集是一个糟糕的选择(太容易填补空白,并不表示您在生产中需要什么):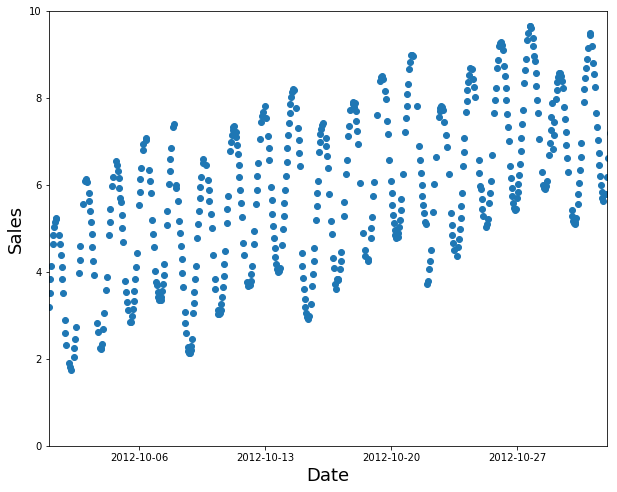
训练集的选择不佳
使用较早的数据作为训练集(以及验证集的后续数据):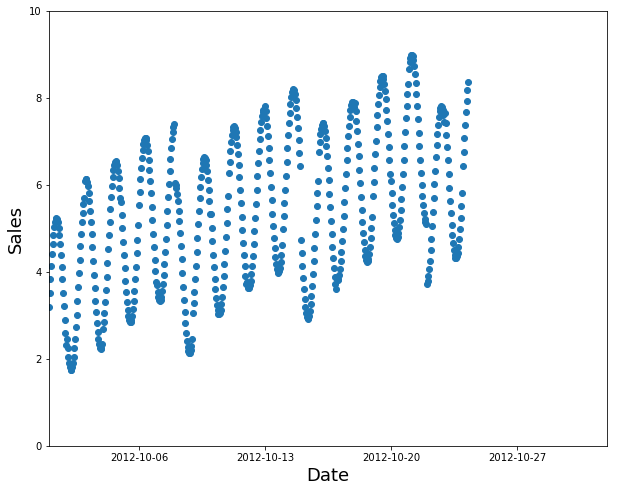
为您的训练集提供更好的选择
Kaggle目前正在竞争预测一系列厄瓜多尔杂货店的销售情况。Kaggle的“培训数据”从2013年1月1日至2017年8月15日运行,测试数据跨越2017年8月16日至2017年8月31日。一个好方法是使用2017年8月1日至8月15日作为验证集,以及所有早期数据作为你的训练集。
新人,新船,新…
您还需要考虑在生产中进行预测的数据可能与您训练模型所需的数据有何不同。
在Kaggle 分心驾驶员竞赛中,独立数据是汽车驾驶员的照片,因变量是一个类别,如发短信,吃饭或安全向前看。如果您是从这些数据构建模型的保险公司,请注意您最感兴趣的是模型在您之前没有见过的驱动程序上的表现(因为您可能只为一小部分人提供培训数据)。对于Kaggle比赛也是如此:测试数据由未在训练集中使用的人组成。

同一个人驾驶时在电话上交谈的两个图像。
如果您将上述图像之一放入训练集中,并将其中一个放在验证集中,那么您的模型似乎表现得比新人更好。另一个观点是,如果你使用所有人来训练你的模型,你的模型可能过分适应那些特定人的特殊性,而不仅仅是学习状态(发短信,吃饭等)。
在Kaggle渔业竞赛中也有类似的动态,以确定渔船捕获的鱼类种类,以减少非法捕捞濒危种群。测试集由未出现在训练数据中的船组成。这意味着您希望验证集包含不在训练集中的船只。
有时可能不清楚您的测试数据会有何不同。例如,对于使用卫星图像的问题,您需要收集有关训练集是否仅包含某些地理位置的更多信息,或者是否来自地理位置分散的数据。
交叉验证的危险
sklearn没有train_validation_test拆分的原因是假设您经常使用交叉验证,其中训练集的不同子集用作验证集。例如,对于3倍交叉验证,数据被分为3组:A,B和C.首先训练模型A和B组合作为训练集,并在验证集C上进行评估。 ,将模型训练为A和C组合作为训练集,并在验证集B上进行评估。依此类推,最终将3倍的模型性能平均化。
但是,交叉验证的问题在于,由于上述各节中描述的所有原因,它很少适用于现实世界的问题。交叉验证仅适用于您可以随机调整数据以选择验证集的相同情况。
Kaggle的“训练集”=你的训练+验证集
Kaggle比赛的一个好处是它们会迫使你更严格地考虑验证集(为了做得好)。对于那些刚接触Kaggle的人来说,它是一个举办机器学习比赛的平台。Kaggle通常会将数据分为两组,您可以下载:
- 一个训练集,其中包括独立的变量,以及对因变量(你正在尝试预测)。对于试图预测销售的厄瓜多尔杂货店的例子,自变量包括商店ID,商品ID和日期; 因变量是销售数量。对于尝试确定驾驶员是否在车轮后面进行危险行为的示例,自变量可以是驾驶员的图片,并且因变量是类别(例如发短信,吃饭或安全地向前看)。
- 一个测试集,它只有自变量。您将对测试集进行预测,您可以将其提交给Kaggle,并获得您的评分。
这是开始机器学习所需的基本思想,但要做得好,理解起来要复杂一些。您将需要创建自己的培训和验证集(通过拆分Kaggle“培训”数据)。您将使用较小的训练集(Kaggle训练数据的子集)来构建模型,并且在提交给Kaggle之前,您可以在验证集(也是Kaggle的训练数据的子集)上对其进行评估。
最重要的原因是Kaggle将测试数据分为两组:公共和私人排行榜。您在公共排行榜上看到的分数仅适用于您预测的一部分(您不知道哪个子集!)。您的预测在私人排行榜上的表现将不会在比赛结束前公布。这一点很重要的原因是你最终可能会过度适应公共排行榜,直到最后你在私人排行榜上做得不好时才会意识到这一点。使用良好的验证集可以防止这种情况。您可以通过查看您的模型是否具有与Kaggle测试集相比较的相似分数来检查您的验证集是否有用。
创建自己的验证集很重要的另一个原因是Kaggle限制您每天提交两次,并且您可能希望尝试更多。第三,确切地看到你在验证集上出错的地方是有益的,而且Kaggle没有告诉你测试集的正确答案,甚至没有告诉你哪些数据点你的错误,只是你的整体得分。
理解这些区别不仅对Kaggle有用。在任何预测性机器学习项目中,您希望模型能够在新数据上表现良好。

若有收获,就点个赞吧
0 人点赞
