该项目的灵感来自Adrian Rosebrock,Francisco Ingham和Jeremy Howard。
在本课程中,我们将从Google Images创建自己的数据集。
我将使用FastAI库中的Resnet34的架构。
在这个特别的项目中,我们将从谷歌下载四种不同类型的北极狗(阿拉斯加雪橇犬,西伯利亚雪橇犬,萨摩耶犬和秋田犬)图像,并建立可以通过这些图像进行分类的最先进模型。 在这个项目中,我们将逐步从Google中为每个品种下载200多张图片。
有很多方法可以为我们的训练数据集找到最有效的谷歌图像,但是,在这个项目中,我们只需打开谷歌图像并记录我们需要的特定品种。
我们需要滚动到页面末尾,然后单击到最底部“显示更多结果”。 (700张图片是Google图片可以显示的最大数量)
使用浏览器中的Javascript代码将URL下载到文本文件中。 对于Mac用户,按Cmd Opt J,在Windows / Linux中按Ctrl Shift J打开javascript控制台并运行以下命令:
urls = Array.from(document.querySelectorAll('.rg_di .rg_meta')).map(el=>JSON.parse(el.textContent).ou);window.open('data:text/csv;charset=utf-8,' + escape(urls.join('\n')));
将下载的文件命名为’dogbreed’.txt文件(确保此时暂停广告块),在这种情况下,我们将有4种不同的犬种:阿拉斯加雪橇犬,萨摩耶犬,西伯利亚雪橇犬和秋田犬。
使用FastAI库下载图像
Fast.AI有一个非常方便的功能,它将通过我们之前在文本文件中提供的URL为我们下载图像。 请注意,我们可以更改要下载的最大图片数量,我们只需要指定文本文件的路径和目标,然后函数将处理其余部分。
注意:由于某些图像无法从URL打开,因此在训练步骤中可能会产生冲突。 加载的错误图像将被忽略并移至下一个URL。
folder = ‘alaskan_malamute’
file = ‘urls_alaskan_malamute.txt’
path = Path(‘data/arctic_dogs’)
destination = path/folder
destination.mkdir(parents=True, exist_ok=True)
folder = 'alaskan_malamute'file = 'urls_alaskan_malamute.txt'path = Path('data/arctic_dogs')destination = path/folderdestination.mkdir(parents=True, exist_ok=True)# download_images(path/file, destination, max_pics=300)download_images(path/file, destination, max_pics=300, max_workers=0)
因为我们想训练模型的所有不同类型的犬种,因此需要做4次下载。 在这种情况下,请将文件夹名称更改为其他四种不同的狗品种,并确保文件名与先前使用javascript命令下载的文本文件的名称相匹配。
然后我们通过如下方式删除无法通过链接打开的图像:
classes = ['alaskan_malamute', 'samoyed', 'siberian_husky', 'akita']for c in classes:print(c)verify_images(path/c, delete=True, max_workers=8)
让我们来看看我们的数据!
我倾向于是每次运行时都有相同的随机图像,因此我们可以使用Numpy随机数种子来执行此操作。
np.random.seed(42)data = ImageDataBunch.from_folder(path,train=".",valid_pct=0.2,ds_tfms=get_transforms(),size=128,num_workers=4).normalize(imagenet_stats)
在这个项目中,我们将使用ImageDataBunch类来创建我们的数据集。 如果您查看文档,我们可以使用from_folder函数,因为我们的图像位于其尊重的文件夹名称(标签)中。 我们只需要传入我们的路径主目录’data / arctic_dogs’,在这种情况下指定我们要为数据集分区的验证集百分比为20%,注意我们从128x128的小尺寸图像开始,我们也是 指定使用4个进程来启动数据收集,并将数据规范化为张量。
我们可以使用以下代码显示我们创建的一批数据集:
data.show_batch(rows=3, figsize=(10,12))

让我们训练我们的模型!
让我们为我们的模型使用Resnet34架构,并显示每个训练周期的error_rate。
learn = create_cnn(data, models.resnet34, metrics=error_rate)#Let's do 4 cycles and see how good is our modellearn.fit_one_cycle(4)

在用resnet34架构的训练了几个周期之后,我们可以看到error_rate的减少。 我们发现错误率大约下降了2%,错误率大约为17%,这使得我们对这些北极狗的分类准确率达到了83%。 但这还不够好!
模型行为的可解释
我们可以使用FastAI的ClassificationInterpretation类来查看哪些类具有最多的错误和错误分类,以便我们可以微调我们的数据,学习速率,训练周期和我们的数据转换本身。
learn.save('stage-1-128')learn.load('stage-1-128')interpretation = ClassificationInterpretation.from_learner(learn)#Plot the confusion matrix to see where does the most errors are madeinterpretation.plot_confusion_matrix()
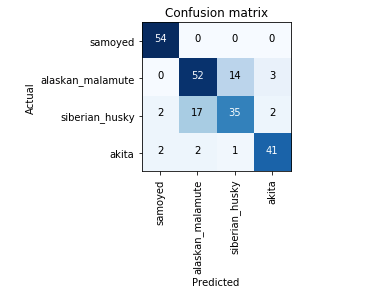
我们可以清楚地看到,大多数错误都发生在阿拉斯加雪橇犬和西伯利亚雪橇之间,我们的模型训练非常适合预测萨摩耶和秋田犬。
清理数据
我们在这里优化模型的方法是删除与我们的数据集无关的图像。 我们可以在目录中手动删除这些文件。
# Get the top losses, that has the worse error and the indexes of these imageslosses, indexes = interpretation.top_losses()# Get the paths of these highest losses images from our validation data settop_loss_paths = data.valid_ds.x[indexes]# Print the paths of these imagesprint(top_loss_paths)
我们需要找到造成这个问题的原因。一般来讲,训练损失应小于验证损失,从而说明我们的模型训练正确。 而通过上面的结果,我们可以得出结论,在我们的模型中有许多可以改进的东西,使它将达到至少90%的准确度。 幸运的是,Fast.AI有一个功能,我们可以绘制模型丢失时使用的学习率。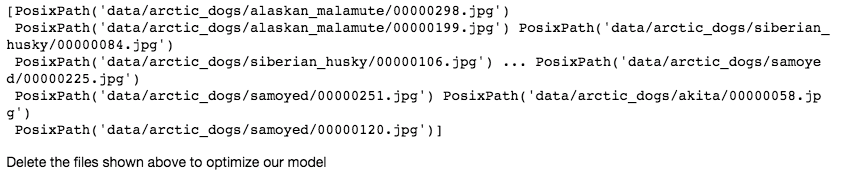
让我们做迁移学习来优化我们的模型
优化我们的模型的一个技巧是从较小的图像尺寸开始,并将学习的权重转移到更大图像尺寸的新数据集,并在优化学习速率的同时查看错误率的差异。 我们可以解冻我们的模型,并为下一个训练周期寻找最佳学习率。
# Let's find the best learning ratelearn.unfreeze()learn.lr_find()# Plot the learning ratelearn.recorder.plot()
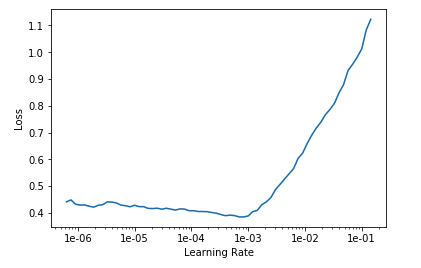
我们可以清楚地看到低于1e-03的学习率,损失比较低。 按照惯例,我们可以使用比1e-03小10倍的下一个学习率,在这种情况下1e-04,在反向传播期间给予它更加保守的变化率。
# Train the model again using the same convention as beforelr = 1e-04# Train the model twice with the new learning ratelearn.fit_one_cycle(2, slice(lr))

哇! 使用新的学习率后,我们可以看到错误率差异减少2%。 现在让我们通过创建大小为256的新数据来开始转移学习,以查看差异。
# Create new ImageDataBunch with size 256data_bigger = ImageDataBunch.from_folder(path,train=".",valid_pct=.2,ds_tfms=get_transforms(),size=256,num_workers=4).normalize(imagenet_stats)# Update the learn data to use this bigger size datalearn.data = data_bigger# Unfreeze() the model and look for learning rateslearn.unfreeze()# Plot the learning rate graphlr_find(learn)learn.recorder.plot()
现在是该使用迁移学习方法的时候了。 我们将使用先前训练的权重,并输入具有256x256更大图片大小的新数据集,以查看训练差异。 我们解冻模型并开始寻找此模型的最佳学习率。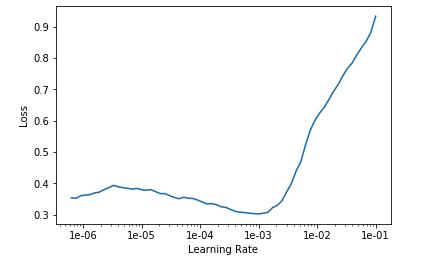
调整学习率
按照惯例,当数据大小为128时,我们可以通过使用新建立的学习率和先前找到的学习率来切片学习率。切片(新学习率,先前学习率/ 5),我们将先前的学习率除以 5找到最大切片的中间点。
previous_lr = 1e-05learn.fit_one_cycle(3, slice(1e-04, previous_lr/5))
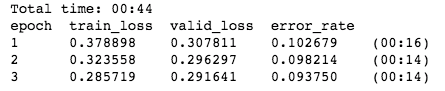
learn.save('stage-2-transfer')
结论
我们在这里可以看到显着的差异。 从使用128图像尺寸开始,我们的最佳错误率约为14%。 在实施转移学习方案后,我们将错误率从大约14%降低到9%错误率,使我们对北极狗的分类准确率大约为91%!
我们可以看到混淆矩阵,并与我们的第一个模型相比,看到误差的差异:
learn.load('stage-2-transfer')interpretation = ClassificationInterpretation.from_learner(learn)interpretation.plot_confusion_matrix()
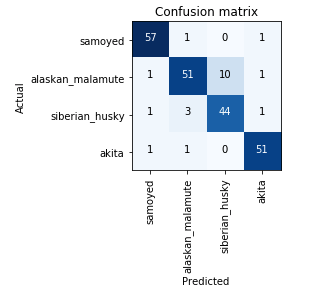
我们可以看到,与我们的第一个模型相比,差异是巨大的,这次我们在用阿拉斯加雪橇犬对西伯利亚雪橇犬进行分类时只犯了3个错误。 此前该模型错误地预测了17次,并且显着下降。
让我们尝试提供图像并查看预测
img = open_image(path/'siberian_husky'/'00000117.jpg')img

拾取的图像用于输入我们的模型预测。
# Lets create a single data bunch and feed our model to predict the dog breed.classes = ['alaskan_malamute', 'samoyed', 'siberian_husky', 'akita']# Create single data ImageDataBunchsingle_data = ImageDataBunch.single_from_classes(path,classes,tfms=get_transforms(),suze-256).normalize(imagenet_stats)# Create new learner with the single datalearn = create_cnn(single_data, models.resnet34, metrics=accuracy)# Load the previous modellearn.load('stage-2-transfer')
现在让我们开始预测
# Get the predicted class, the index and the outputspredicted_class, predicted_index, outputs = learn.predict(img)predicted_class
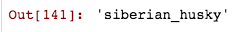
完美! 我们成功优化了我们的模型,从大约83%的精度到91%。 这是一个显着的增长,如果我们用几个周期再次训练模型,它可能更准确。
非常感谢您的时间,请查看此存储库以获取完整代码!

若有收获,就点个赞吧
0 人点赞
