这里再次写信给我6个月前的自我……
在这篇文章中,我将主要关注语义分割,像素分类任务和特定的算法。 我将提供一些关于我最近一直在努力的案例的演练。
根据定义,语义分割是将图像划分为连贯的部分。 例如,对属于我们的数据集中的人,汽车,树或任何其他实体的每个像素进行分类。
语义分割与实例分割
与实例分割相比,语义分割相对容易。
在实例分割中,我们的目标不仅是对每个人,汽车或树进行像素预测,而且还分别将每个实体识别为人1,人2,树1,树2,汽车1,汽车2,汽车3 等等。 用于实例分割的现有技术算法是Mask-RCNN:具有多个子网络一起工作的两阶段方法:RPN(区域提议网络),FPN(特征金字塔网络)和FCN(完全卷积网络)[5, 6,7,8]。


案例研究:Data Science Bowl 2018
数据科学比赛2018刚刚结束,我从中学到了很多东西。也许我学到的最重要的一课,即使是深入学习,与传统的ML相比,更自动化的技术,前后处理对于获得好的结果可能是至关重要的。这些是从业者获得的重要技能,它们定义了您构建和建模问题的方式。
我不会详细讨论这个特定的比赛,因为对于任务本身和整个比赛中使用的方法都有大量的讨论和解释。但我会简要提及获胜的解决方案,因为它与这篇文章的基础有关。 [13]
数据科学比赛2018就像其他数据科学比赛一样,由Booz Allen基金会组织。今年的任务是在给定的显微镜图像中识别细胞核并独立地为每个细胞核提供掩模。
现在,花一两个时间来猜测这个任务需要哪种类型的细分;语义还是实例?
这是一个掩盖图像样本,它是原始的显微镜图像。
虽然起初听起来像是语义分段任务,但这里的任务是实例分割。我们需要独立地处理图像中的每个核,并将它们识别为核1,核2,核3,……类似于我们对汽车1,汽车2,人1等的示例。也许这项任务的动机是跟踪细胞样本中细胞核的大小,数量和特征。自动化该跟踪过程并进一步加速用于治疗各种疾病的不同治疗方法的实验是非常重要的。
现在,您可能会认为如果本文是关于语义分段的,并且如果Data Science Bowl 2018是实例分段任务的一个示例,那么为什么我一直在谈论这个特定的竞争。如果你正在考虑这个问题,那么你肯定是对的,而且这次比赛的最终目标确实不是语义分割的一个例子。但是,随着我们将继续前进,您将看到如何将此实例分段问题实际转变为多类语义分段任务。这是我尝试但在实践中失败的方法,但也成为获胜解决方案的高级动机。
在这3个月的比赛期间,只有两个模型(或其变体)在论坛中共享或至少明确讨论过; Mask-RCNN和U-Net。正如我之前提到的,Mask-RCNN是最先进的物体检测算法,它可以检测单个物体并预测其掩模,如实例分割。 Mask-RCNN的实施和培训更加困难,因为它采用了两阶段学习方法,您首先优化RPN(区域提案网络),然后同时预测边界框,类和掩模。
另一方面,U-Net是一种非常流行的端到端编码器 - 解码器网络,用于语义分割[9]。它最初是发明并首次用于生物医学图像分割,这是我们为Data Science Bowl所做的一项非常类似的任务。竞争中没有银弹,没有任何一个没有邮政或预处理的建筑或建筑设计中的任何小调整都没有得到最高分。我没有机会为这次比赛尝试Mask-RCNN,所以我在U-Net周围进行了实验并学到了很多东西。
此外,由于我们的主题是语义分割,我将把Mask-RCNN留给其他博客文章进行解释。但是如果你仍然坚持在自己的CV应用程序中尝试它们,这里有两个流行的github存储库,在Tensorflow和PyTorch中实现。 [10,11]
现在,我们可以继续使用U-Net并深入了解它的细节……
这是开始的架构:

对于熟悉传统卷积神经网络的人来说,架构的第一部分(表示为DOWN)将是熟悉的。第一部分被调用,或者您可能认为它是编码器部分,您应用卷积块,然后进行maxpool下采样,将输入图像编码为多个不同级别的要素表示。
网络的第二部分包括上采样和连接,然后是常规卷积操作。 CNN中的上采样可能是一些读者的新概念,但这个想法相当简单:我们正在扩展要素尺寸以使用左边相应的连接块来满足相同的尺寸。您可能会看到灰色和绿色箭头,我们将两个要素图连接在一起。与其他完全卷积分割网络相比,U-Net在这种意义上的主要贡献在于,在网络中进行上采样和深入研究的同时,我们将更高分辨率的特征从下部与上采样特征连接起来,以便更好地定位和学习表示。以下卷积。由于上采样是稀疏操作,因此我们需要从早期阶段获得良好的优先级以更好地表示本地化。在FPN(特征金字塔网络)中也可以看到组合匹配级别的类似想法。 [7]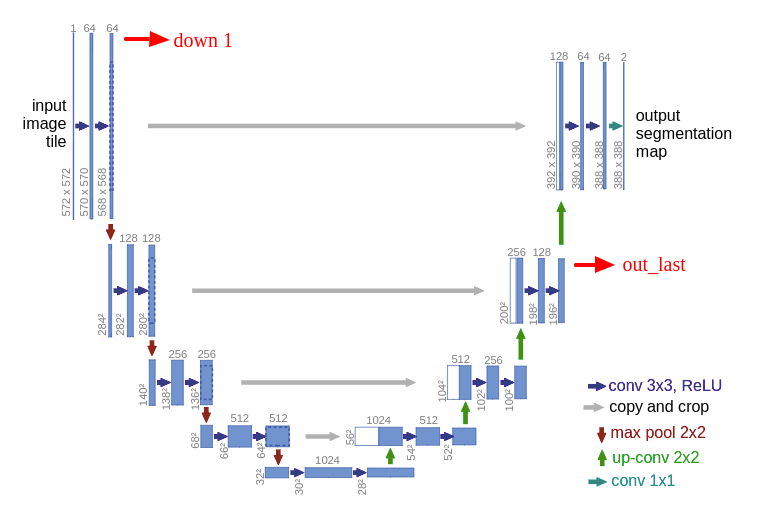
我们可以在下部定义一个操作块作为卷积→下采样。
# a sample down blockdef make_conv_bn_relu(in_channels, out_channels, kernel_size=3, stride=1, padding=1):return [nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True)]self.down1 = nn.Sequential(*make_conv_bn_relu(in_channels, 64, kernel_size=3, stride=1, padding=1 ),*make_conv_bn_relu(64, 64, kernel_size=3, stride=1, padding=1 ),)# convolutions followed by a maxpooldown1 = self.down1(x)out1 = F.max_pool2d(down1, kernel_size=2, stride=2)
类似地,我们可以将一个操作块定义为上采样→连接→卷积。
# a sample up blockdef make_conv_bn_relu(in_channels, out_channels, kernel_size=3, stride=1, padding=1):return [nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True)]self.up4 = nn.Sequential(*make_conv_bn_relu(128,64, kernel_size=3, stride=1, padding=1 ),*make_conv_bn_relu(64,64, kernel_size=3, stride=1, padding=1 ))self.final_conv = nn.Conv2d(32, num_classes, kernel_size=1, stride=1, padding=0 )# upsample out_last, concatenate with down1 and apply conv operationsout = F.upsample(out_last, scale_factor=2, mode='bilinear')out = torch.cat([down1, out], 1)out = self.up4(out)# final 1x1 conv for predictionsfinal_out = self.final_conv(out)
通过仔细检查图形,您可能会注意到输出尺寸(388 x 388)与原始输入(572 x 572)不同。如果您希望获得一致的大小,您可以应用填充卷积来保持跨越级联级别的维度,就像我们在上面的示例代码中所做的那样。
当提到这样的上采样时,您可能会遇到以下任一项:转置卷积,上卷积,反卷积或上移。包括我自己和PyTorch文档在内的许多人都不喜欢反卷积这个术语,因为在上采样阶段我们实际上正在进行常规的卷积运算,并且没有任何关于它的信息。如果您不熟悉基本的卷积运算及其算术,我会强烈建议您访问此处。 [12]
我将解释从最简单到更复杂的上采样方法。以下是在PyTorch中对2D张量进行上采样的三种方法:
最近邻
这是在将张量调整(转换)为更大张量时找到丢失像素值的最简单方法,例如, 2x2到4x4,5x5或6x6。
让我们使用Numpy逐步实现这个基本的计算机视觉算法:
def nn_interpolate(A, new_size):"""Nearest Neighbor Interpolation, Step by Step"""# get sizesold_size = A.shape# calculate row and column ratiosrow_ratio, col_ratio = new_size[0]/old_size[0], new_size[1]/old_size[1]# define new pixel row position inew_row_positions = np.array(range(new_size[0]))+1new_col_positions = np.array(range(new_size[1]))+1# normalize new row and col positions by ratiosnew_row_positions = new_row_positions / row_rationew_col_positions = new_col_positions / col_ratio# apply ceil to normalized new row and col positionsnew_row_positions = np.ceil(new_row_positions)new_col_positions = np.ceil(new_col_positions)# find how many times to repeat each elementrow_repeats = np.array(list(Counter(new_row_positions).values()))col_repeats = np.array(list(Counter(new_col_positions).values()))# perform column-wise interpolation on the columns of the matrixrow_matrix = np.dstack([np.repeat(A[:, i], row_repeats)for i in range(old_size[1])])[0]# perform column-wise interpolation on the columns of the matrixnrow, ncol = row_matrix.shapefinal_matrix = np.stack([np.repeat(row_matrix[i, :], col_repeats)for i in range(nrow)])return final_matrixdef nn_interpolate(A, new_size):"""Vectorized Nearest Neighbor Interpolation"""old_size = A.shaperow_ratio, col_ratio = np.array(new_size)/np.array(old_size)# row wise interpolationrow_idx = (np.ceil(range(1, 1 + int(old_size[0]*row_ratio))/row_ratio) - 1).astype(int)# column wise interpolationcol_idx = (np.ceil(range(1, 1 + int(old_size[1]*col_ratio))/col_ratio) - 1).astype(int)final_matrix = A[:, row_idx][col_idx, :]return final_matrix

[PyTorch] F.upsample(…, mode = “nearest”)
>>> input = torch.arange(1, 5).view(1, 1, 2, 2)>>> input(0 ,0 ,.,.) =1 23 4[torch.FloatTensor of size (1,1,2,2)]>>> m = nn.Upsample(scale_factor=2, mode='nearest')>>> m(input)(0 ,0 ,.,.) =1 1 2 21 1 2 23 3 4 43 3 4 4[torch.FloatTensor of size (1,1,4,4)]
双线性插值
双线性插值算法的计算效率低于最近邻居,但它是一种更精确的近似。 根据距离计算单个像素值作为所有其他值的加权平均值。
[PyTorch] F.upsample(…,mode =“bilinear”)
>>> input = torch.arange(1, 5).view(1, 1, 2, 2)>>> input(0 ,0 ,.,.) =1 23 4[torch.FloatTensor of size (1,1,2,2)]>>> m = nn.Upsample(scale_factor=2, mode='bilinear')>>> m(input)(0 ,0 ,.,.) =1.0000 1.2500 1.7500 2.00001.5000 1.7500 2.2500 2.50002.5000 2.7500 3.2500 3.50003.0000 3.2500 3.7500 4.0000[torch.FloatTensor of size (1,1,4,4)]
转置卷积
在转置卷积中,我们通过反向传播学习权重。 在论文中,我遇到了针对各种情况的所有这些上采样方法,并且在实践中,您可能会更改您的体系结构并尝试所有这些以查看哪种方法最适合您自己的问题。 我个人更喜欢转置卷积,因为我们对它有更多的控制权,但你也可以选择双线性插值或最近邻居。
[PyTorch] nn.ConvTranspose2D(…, stride=…, padding=…)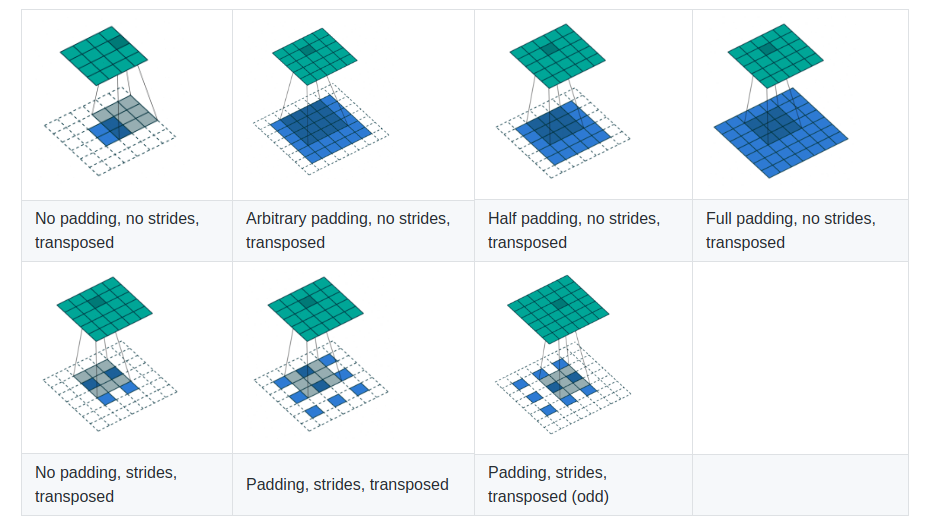
如果我们回到最初的案例,数据科学碗,在竞争中使用香草U-Net方法的主要缺点是重叠核。 如上图所示,如果您创建一个二元蒙版并将其用作目标,U-Net肯定会预测类似于此的东西,并且您将拥有多个核的组合掩模,这些核重叠或彼此非常接近。
关于重叠实例问题,U-Net论文的作者使用加权交叉熵来强调学习细胞的边界。 此方法帮助他们分离重叠的实例。 基本的想法是更多地加权边界,并推动网络在近距离实例之间找到学习差距。[9]
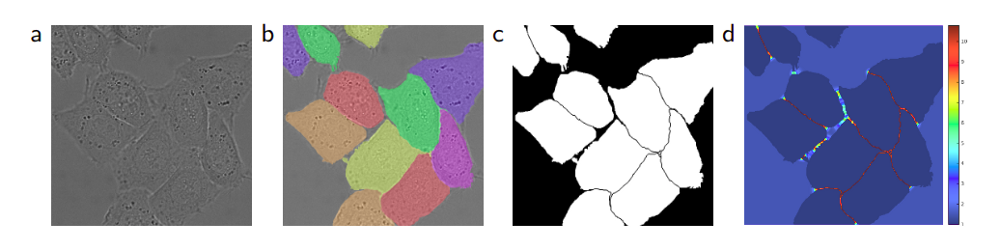
这种问题的另一种解决方案是许多竞争者使用的方法,包括获胜的解决方案,是将二进制掩码转换为多类目标。 U-Net的优点在于,您可以构建网络以根据需要输出任意数量的通道,并通过在最后一层使用1x1卷积来表示任何通道中的任何类。
引自Data Science Bowl获奖解决方案:
用于具有S形激活的网络的2通道掩模,即(掩模 - 边界,边界)或用于具有softmax激活的网络的3通道掩模,即(掩模 - 边界,边界,1 - 掩模 - 边界) 2通道全面罩即(面罩,边框)
在进行这些预测之后,诸如分水岭的经典图像处理算法可以用于后处理以进一步分割单个核。[14]
这是第一次正式的计算机视觉竞赛,我有勇气参加Kaggle,它是一个数据科学碗。虽然我只在前20%(这被认为是平均分数)完成了比赛,但我感到很高兴参加数据科学碗并学习如果我实际上没有参与的话我可能永远不会学到的东西并试着靠自己。积极学习远比观看或阅读来自在线资源的类似方法更富有成效。
作为一名刚刚开始用Fast.ai开始练习数月的深度学习练习者,这对我来说是一个重要的一步,也是我永无止境的旅程,在获得经验方面非常有价值。所以,对于那些在你之前从未见过或已经解决的挑战感到暗示的人,我强烈建议你专门去处理这些类型的挑战,以便感受学习以前你不知道的东西的乐趣。
我在本次比赛中学到的另一个有价值的教训是,在计算机视觉中(这也适用于NLP)竞赛,通过眼睛检查每一个预测非常重要,看看哪些有效,哪些无效。如果您的数据足够小,您应该去检查每个输出。如果出现问题,这将允许您进一步提出更好的想法,甚至调试代码。
转移学习及其他
到目前为止,我们已经定义了vanilla U-Net的构建块,并提到了我们如何操纵目标来解决实例分割问题。现在我们可以进一步讨论这些类型的编码器 - 解码器网络的灵活性。通过灵活性,我的意思是你拥有它的自由以及你可以对它进行设计的创造力。
任何在某些时候进行深度学习的人都会转移学习,因为这是一个非常强大的想法。简而言之,转移学习是使用预训练网络的概念,该网络在许多样本上进行训练,以完成我们所面临的类似任务,但缺少相同数量的数据。即使有足够的数据传输,学习也可以在一定程度上提升性能,不仅适用于计算机视觉任务,也适用于NLP。
迁移学习也被证明是U-Net类似架构的强大技术。我们之前已经定义了U-Net的两个主要组件;向上和向上。我们这次将这些部分重新编号为编码器和解码器。编码器部分基本上接受输入并将其编码在低维特征空间中,该特征空间表示我们在较低维度中的输入。现在想象用你最喜欢的ImageNet获胜者替换这个编码器; VGG,ResNet,Inception,NasNet,……你想要的。这些网络经过精心设计,可以做一个常见的事情:以最佳方式编码自然图像进行分类,ImageNet上的预训练重量等待您在线抓取它们。
那么为什么不使用这些架构之一作为我们的编码器并以与原始U-Net相同的方式构建解码器,但更好的是,使用类固醇。
TernausNet是Kaggle Carvana挑战赛的赢家架构,它使用与VGG11相同的传输学习理念作为编码器。 [15,16]
Fast.ai:动态U-Net
受到TernausNet论文和许多其他优秀资源的启发,我想概括为U-Net架构使用预训练或自定义编码器的想法。 所以,我想出了一个通用的架构:动态Unet。
Dynamic Unet是这个想法的一个实现,它通过为您完成所有计算和匹配,自动为任何给定的编码器创建解码器部分。 编码器既可以是现成的预训练网络,也可以是您自己定义的任何自定义架构。
它是用PyTorch编写的,目前在Fast.ai库中。 您可以参考此笔记本以查看其中的操作或查看来源。 Dynamic Unet的主要目标是节省实践者的时间,并允许使用尽可能少的代码更容易地使用不同的编码器进行实验。
在第2部分中,我将解释体积数据的3D编码器解码器模型,例如MRI扫描,并给出我一直在研究的真实世界的例子。
References
[5] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks: https://arxiv.org/abs/1506.01497
[6] Mask R-CNN: https://arxiv.org/abs/1703.06870
[7] Feature Pyramid Networks for Object Detection: https://arxiv.org/abs/1612.03144
[8] Fully Convolutional Networks for Semantic Segmentation: https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf
[9] U-net: Convolutional Networks for Biomedical Image Segmentation: https://arxiv.org/abs/1505.04597
[10] Tensorflow Mask-RCNN: https://github.com/matterport/Mask_RCNN
[11] Pytorch Mask-RCNN: https://github.com/multimodallearning/pytorch-mask-rcnn
[12] Convolution Arithmetic: https://github.com/vdumoulin/conv_arithmetic
[13] Data Science Bowl 2018 Winning Solution, ods-ai: https://www.kaggle.com/c/data-science-bowl-2018/discussion/54741
[14] Watershed Algorithm https://docs.opencv.org/3.3.1/d3/db4/tutorial_py_watershed.html
[15] Carvana Image Masking Challenge: https://www.kaggle.com/c/carvana-image-masking-challenge
[16] TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation: https://arxiv.org/abs/1801.05746

若有收获,就点个赞吧
0 人点赞
