
如何使用预训练的卷积神经网络进行PyTorch对象识别
虽然PyTorch可能不适合所有人,但此时不可能说出哪个深度学习库会出现在最前面,并且能够快速学习和使用不同的工具对于成为数据科学家来说至关重要。
该项目的完整代码在GitHub上以Jupyter Notebook的形式提供。这个项目源于我参加Udacity PyTorch奖学金挑战。
迁移学习的方法
我们的任务是训练可以识别图像中物体的卷积神经网络(CNN)。我们将使用Caltech 101数据集,该数据集包含101个类别的图像。大多数类别只有50个图像,这些图像通常不足以让神经网络学会高精度。因此,我们将使用预先构建和预先训练的模型来应用转移学习,而不是从头开始构建和训练CNN。
转移学习的基本前提很简单:采用在大型数据集上训练的模型,并将其知识转移到较小的数据集。对于使用CNN的对象识别,我们冻结网络的早期卷积层,并且仅训练进行预测的最后几层。这个想法是卷积层提取适用于图像的一般,低级特征 - 如边缘,图案,渐变 - 后面的图层识别图像中的特定特征,如眼睛或轮子。
因此,我们可以使用在大规模数据集(通常为Imagenet)中训练不相关类别的网络,并将其应用于我们自己的问题,因为图像之间共享通用的低级特征。Caltech 101数据集中的图像与Imagenet数据集中的图像非常相似,模型在Imagenet上学习的知识应该很容易转移到此任务。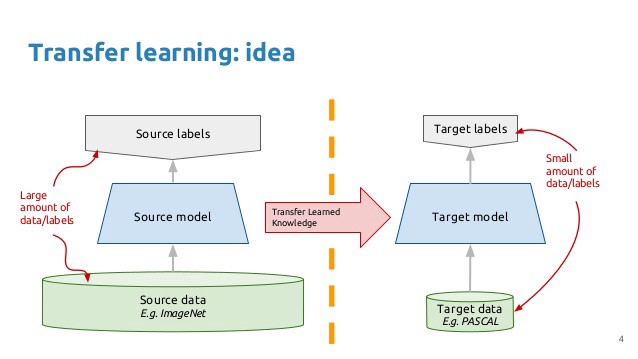
以下是物体识别转移学习的概要:
- 加载在大型数据集上训练的预训练CNN模型
- 冻结模型的较低卷积层中的参数(权重)
- 添加具有多层可训练参数的自定义分类器以进行建模
- 训练可用于任务的训练数据的分类器层
- 根据需要微调超参数并解冻更多层
事实证明,这种方法适用于广泛的领域。这是一个很好的工具,拥有你的武器库,通常是面对新的图像识别问题时应该尝试的第一种方法。
数据设置
对于所有数据科学问题,正确格式化数据将决定项目的成功或失败。幸运的是,Caltech 101数据集图像清晰,并以正确的格式存储。如果我们正确设置数据目录,PyTorch可以很容易地将正确的标签与每个类关联起来。我将数据分为训练,验证和测试集,分别为50%,25%,25%,然后按如下方式构建目录:
/datadir/train/class1/class2../valid/class1/class2../test/class1/class2..
按类别划分的训练图像数量(我可以互换地使用术语类别和类别):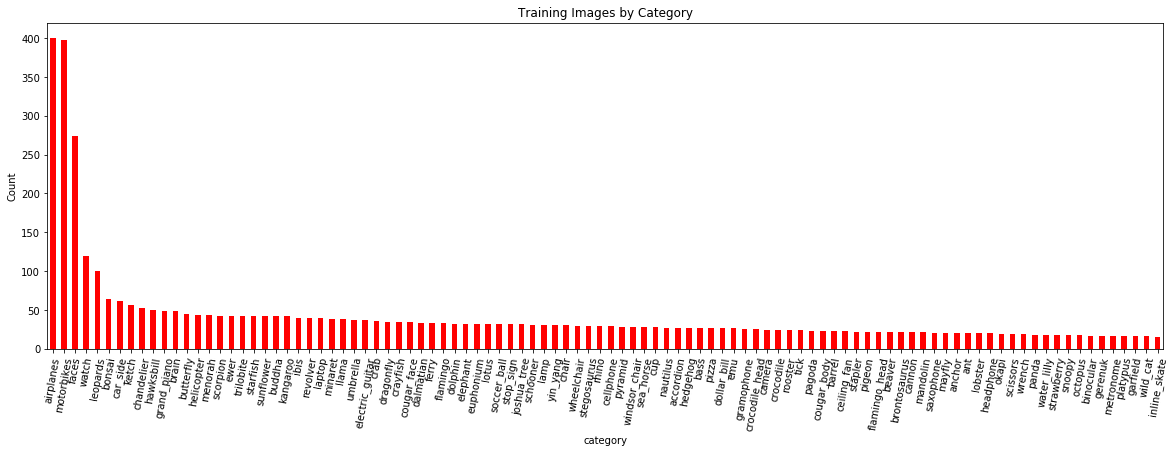
我们希望模型在具有更多示例的类上做得更好,因为它可以更好地学习将要素映射到标签。为了处理有限数量的训练样例,我们将在训练期间使用数据增加(稍后)。
作为另一项数据探索,我们还可以查看大小分布。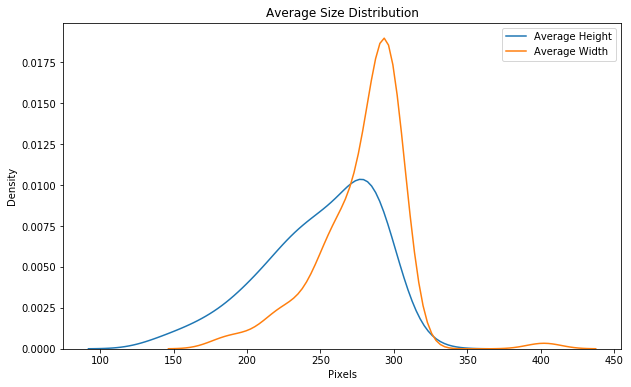
Imagenet模型需要224 x 224的输入大小,因此其中一个预处理步骤将是调整图像大小。预处理也是我们为训练数据实施数据增强的地方。
数据扩充
数据增强的想法是通过对图像应用随机变换来人为地增加模型看到的训练图像的数量。例如,我们可以随机旋转或裁剪图像或水平翻转它们。我们希望我们的模型能够区分对象,而不管方向如何,数据扩充也可以使模型对输入数据的转换不变。
无论面对大象,大象仍然是大象!
增强通常仅在训练期间完成(尽管在[fast.ai](https://blog.floydhub.com/ten-techniques-from-fast-ai/)库中可以进行测试时间增加)。每个时期 - 通过所有训练图像的一次迭代 - 对每个训练图像应用不同的随机变换。这意味着如果我们遍历数据20次,我们的模型将看到每个图像的20个略有不同的版本。整体结果应该是一个模型,它可以学习对象本身,而不是如何呈现它们或图像中的工件。
图像预处理
这是处理图像数据最重要的一步。在图像预处理期间,我们同时为网络准备图像并将数据增强应用于训练集。每个模型都有不同的输入要求,但如果我们读完Imagenet所需的内容,我们就会发现我们的图像需要为224x224并且标准化为一个范围。
要在PyTorch中处理图像,我们使用transforms 应用于数组的简单操作。验证(和测试)转换如下:
- 调整
- 中心裁剪为224 x 224
- 转换为张量
- 用均值和标准偏差归一化
通过这些转换的最终结果是可以进入我们网络的张量。训练变换是相似的,但增加了随机增强。
首先,我们定义培训和验证转换:
from torchvision import transforms# Image transformationsimage_transforms = {# Train uses data augmentation'train':transforms.Compose([transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),transforms.RandomRotation(degrees=15),transforms.ColorJitter(),transforms.RandomHorizontalFlip(),transforms.CenterCrop(size=224), # Image net standardstransforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]) # Imagenet standards]),# Validation does not use augmentation'valid':transforms.Compose([transforms.Resize(size=256),transforms.CenterCrop(size=224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),}
然后,我们创建datasets和DataLoaders 。通过使用datasets.ImageFolder制作数据集,PyTorch会自动将图像与正确的标签相关联,前提是我们的目录设置如上。然后将数据集传递给一个DataLoader 迭代器,该迭代器产生批量的图像和标签。
from torchvision import datasetsfrom torch.utils.data import DataLoader# Datasets from foldersdata = {'train':datasets.ImageFolder(root=traindir, transform=image_transforms['train']),'valid':datasets.ImageFolder(root=validdir, transform=image_transforms['valid']),}# Dataloader iterators, make sure to shuffledataloaders = {'train': DataLoader(data['train'], batch_size=batch_size, shuffle=True),'val': DataLoader(data['valid'], batch_size=batch_size, shuffle=True)}
我们可以看到DataLoader使用以下内容的迭代行为:
# Iterate through the dataloader oncetrainiter = iter(dataloaders['train'])features, labels = next(trainiter)features.shape, labels.shape(torch.Size([128, 3, 224, 224]), torch.Size([128]))
批次的形状是(batch_size, color_channels, height, width)。在训练,验证和最终测试期间,我们将遍历DataLoaders整个数据集,包括一个时期。每个时期,训练DataLoader将对图像应用略微不同的随机变换以用于训练数据增强。
用于图像识别的预训练模型
随着我们的数据形状,我们接下来将注意力转向模型。为此,我们将使用预先训练的卷积神经网络。PyTorch有许多模型已经在Imagenet的 1000个类中训练了数百万个图像。完整的模型列表可以在这里看到。这些模型在Imagenet上的性能如下所示: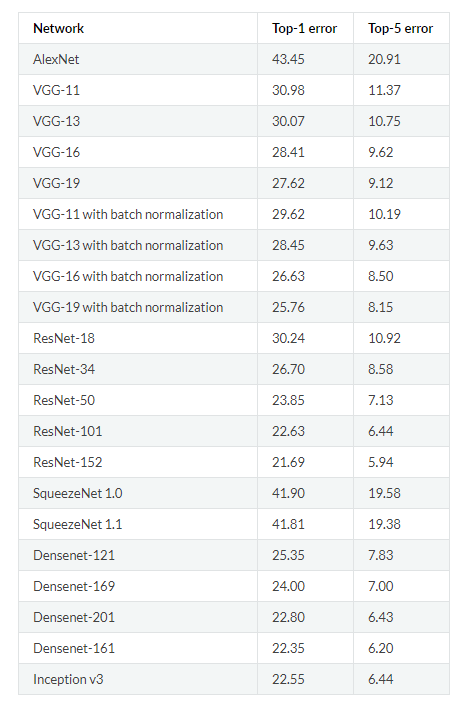
对于这个实现,我们将使用VGG-16。虽然它没有记录最低的错误,但我发现它适用于任务,并且比其他模型更快地训练。使用预训练模型的过程已经建立:
- 从在大型数据集上训练的网络加载预训练的权重
- 冻结较低(卷积)图层中的所有权重:根据新任务与原始数据集的相似性调整要冻结的图层
- 用自定义分类器替换网络的上层:输出数必须设置为等于类的数量
- 仅训练任务的自定义分类器层,从而优化较小数据集的模型
在PyTorch中加载预先训练的模型很简单:
from torchvision import modelsmodel = model.vgg16(pretrained=True)
这个模型有超过1.3亿个参数,但我们只训练最后几个完全连接的层。最初,我们冻结了模型的所有权重:
# Freeze model weightsfor param in model.parameters():param.requires_grad = False
然后,我们使用以下图层添加我们自己的自定义分类器:
- 与ReLU激活完全连接,shape =(n_inputs,256)
- 辍学有40%的机会下降
- 与log softmax输出完全连接,shape =(256,n_classes)
import torch.nn as nn# Add on classifiermodel.classifier[6] = nn.Sequential(nn.Linear(n_inputs, 256),nn.ReLU(),nn.Dropout(0.4),nn.Linear(256, n_classes),nn.LogSoftmax(dim=1))
将额外图层添加到模型时,默认情况下将它们设置为可训练(require_grad=True)。对于VGG-16,我们只改变最后一个原始的全连接层。卷积层和前5个完全连接层中的所有权重都是不可训练的。
# Only training classifier[6]model.classifierSequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace)(2): Dropout(p=0.5)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace)(5): Dropout(p=0.5)(6): Sequential((0): Linear(in_features=4096, out_features=256, bias=True)(1): ReLU()(2): Dropout(p=0.4)(3): Linear(in_features=256, out_features=100, bias=True)(4): LogSoftmax()))
网络的最终输出是我们数据集中100个类中每个类的对数概率。该模型共有1.35亿个参数,其中只有100多万个将被训练。
# Find total parameters and trainable parameterstotal_params = sum(p.numel() for p in model.parameters())print(f'{total_params:,} total parameters.')total_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f'{total_trainable_params:,} training parameters.')135,335,076 total parameters.1,074,532 training parameters.
将模型移动到GPU(s)
PyTorch的最佳方面之一是可以轻松地将模型的不同部分移动到一个或多个gpus,以便您可以充分利用您的硬件。由于我使用2 gpus进行训练,我首先将模型移动到cuda然后创建一个DataParallel分布在gpus上的模型:
# Move to gpumodel = model.to('cuda')# Distribute across 2 gpusmodel = nn.DataParallel(model)
(这个笔记本应该在一个gpu上运行,以便在合理的时间内完成。对CPU的加速可以轻松达到10倍或更多。)
训练损失和优化
训练损失(预测和真值之间的误差或差异)是负对数似然(NLL)。(PyTorch中的NLL损失需要对数概率,因此我们从模型的最后一层传递原始输出。)PyTorch使用自动微分,这意味着张量不仅跟踪它们的值,而且还跟踪每个操作(乘法,加法,激活) ,等)有助于价值。这意味着我们可以针对任何先前张量计算网络中任何张量的梯度。
这在实践中意味着损失不仅跟踪误差,而且跟踪模型中每个权重和偏差对误差的贡献。在我们计算损失之后,我们可以找到关于每个模型参数的损失梯度,这个过程称为反向传播。获得渐变后,我们使用它们来使用优化器更新参数。(如果一开始没有陷入困境,请不要担心,需要花一点时间来掌握!这个powerpoint有助于澄清一些观点。)
所述优化器是亚当,一种有效的变体中的梯度下降,其通常不需要手工调整学习率。在训练期间,优化器使用损失的梯度来尝试通过调整参数来减少模型输出的误差(“优化”)。只会优化我们在自定义分类器中添加的参数。
损失和优化器初始化如下:
from torch import optim# Loss and optimizercriteration = nn.NLLLoss()optimizer = optim.Adam(model.parameters())
通过预先训练的模型,自定义分类器,损失,优化器以及最重要的数据,我们已准备好进行培训。
训练
PyTorch中的模型训练比Keras更具实际操作性,因为我们必须自己进行反向传播和参数更新步骤。主循环遍历多个时期,并且在每个时期迭代通过火车DataLoader 。该DataLoader收益率一批,我们通过模型数据和指标。在每个训练批次之后,我们计算损失,反向传播相对于模型参数的损失梯度,然后用优化器更新参数。
我建议您查看笔记本上的完整培训详细信息,但基本的伪代码如下:
for epoch in range(n_epochs):for data, targets in trainloader:# Generate predictionsout = model(data)# Calculate lossloss = criterion(out, targets)# Backpropagationloss.backward()# Update model parametersoptimizer.step()
我们可以继续迭代数据,直到达到给定数量的时期。然而,这种方法的一个问题是我们的模型最终将开始过度拟合训练数据。为了防止这种情况,我们使用验证数据并提前停止。
提前停止
早期停止意味着当验证损失在许多时期没有减少时停止训练。在我们继续培训时,培训损失只会减少,但验证损失最终将达到最低限度并且平稳或开始增加。理想情况下,当验证损失最小时,我们希望停止培训,希望此模型能够最好地推广到测试数据。当使用早期停止时,验证损失减少的每个时期,我们保存参数,以便我们以后可以检索具有最佳验证性能的那些。
我们通过在DataLoader每个训练时期结束时迭代验证来实现早期停止。我们计算验证损失并将其与最低验证损失进行比较。如果到目前为止损失最小,我们保存模型。如果在一定数量的时期内损失没有改善,我们停止训练并返回已保存到磁盘的最佳模型。
同样,完整的代码在笔记本中,但伪代码是:
# Early stopping detailsn_epochs_stop = 5min_val_loss = np.Infepochs_no_improve = 0# Main loopfor epoch in range(n_epochs):# Initialize validation loss for epochval_loss = 0# Training loopfor data, targets in trainloader:# Generate predictionsout = model(data)# Calculate lossloss = criterion(out, targets)# Backpropagationloss.backward()# Update model parametersoptimizer.step()# Validation loopfor data, targets in validloader:# Generate predictionsout = model(data)# Calculate lossloss = criterion(out, targets)val_loss += loss# Average validation lossval_loss = val_loss / len(trainloader)# If the validation loss is at a minimumif val_loss < min_val_loss:# Save the modeltorch.save(model, checkpoint_path)epochs_no_improve = 0min_val_loss = val_losselse:epochs_no_improve += 1# Check early stopping conditionif epochs_no_improve == n_epochs_stop:print('Early stopping!')# Load in the best modelmodel = torch.load(checkpoint_path)
要了解提前停止的好处,我们可以查看显示培训和验证损失和准确性的培训曲线: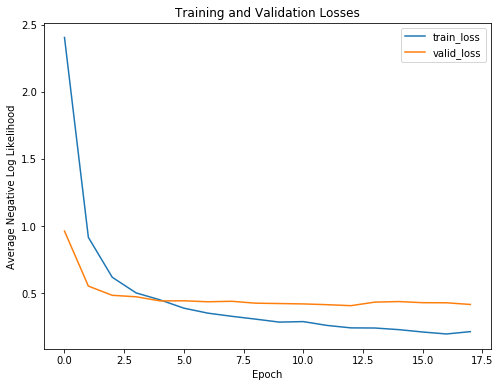
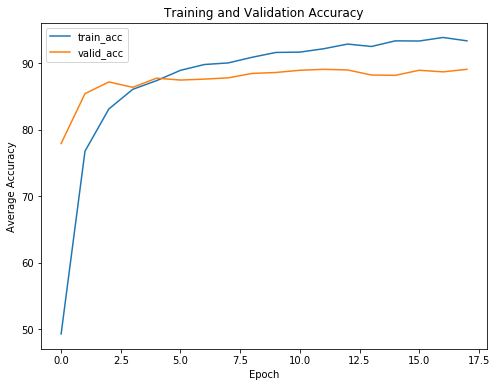
正如预期的那样,随着进一步的培训,培训损失只会继续减少。另一方面,验证损失达到最低和稳定。在某个时代,进一步训练没有回报(甚至是负回报)。我们的模型将仅开始记忆训练数据,并且无法概括为测试数据。
如果没有提前停止,我们的模型将训练超过必要的时间> 并且将过度训练数据。
我们从训练曲线中可以看到的另一点是我们的模型并没有过度拟合。总是存在一些过度拟合,但是在第一个可训练的完全连接层之后的退出可以防止训练和验证损失过多。
做出预测:推论
在笔记本中我处理了一些无聊 - 但必要的 - 保存和加载PyTorch模型的细节,但在这里我们将向右移动到最佳部分:对新图像进行预测。我们知道我们的模型在训练甚至验证数据方面做得很好,但最终的测试是它在一个前所未见的保持测试集上的表现。我们保存了25%的数据,以确定我们的模型是否可以推广到新数据。
使用训练有素的模型进行预测非常简单。我们使用与训练和验证相同的语法:
for data, targets in testloader:log_ps = model(data)# Convert to probabilitiesps = torch.exp(log_ps)ps.shape()(128, 100)
我们概率的形状是(batch_size ,n_classes)因为我们有每个阶级的概率。我们可以通过找到每个示例的最高概率来找到准确性,并将它们与标签进行比较:
# Find predictions and correctpred = torch.max(ps, dim=1)equals = pred == targets# Calculate accuracyaccuracy = torch.mean(equals)
在诊断用于对象识别的网络时,查看测试集和各个预测的整体性能会很有帮助。
模型结果
以下是模型指甲的两个预测: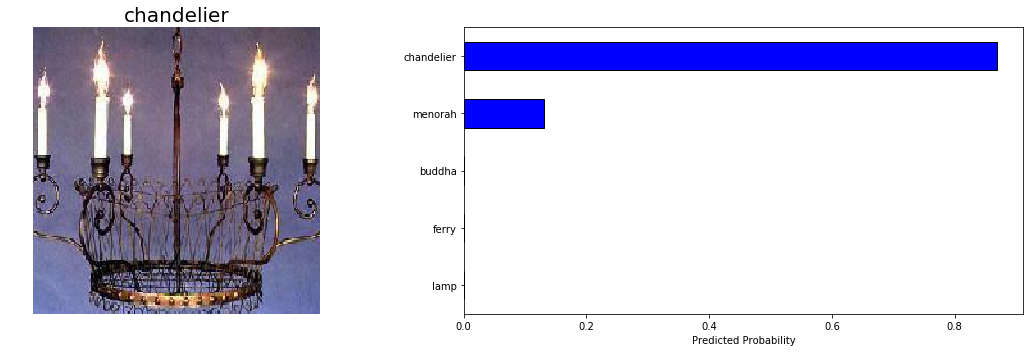

这些都很简单,所以我很高兴模型没有问题!
我们不仅仅想关注正确的预测,我们很快就会看到一些错误的输出。现在让我们评估整个测试集的性能。为此,我们希望迭代测试DataLoader并计算每个示例的损失和准确性。
用于对象识别的卷积神经网络通常根据topk精度来测量。这指的是真实类是否在k最可能预测的类中。例如,前5个准确度是右类在5个最高概率预测中的百分比。您可以从PyTorch张量中获取topk最可能的概率和类,如下所示:
top_5_ps,top_5_classes = ps.topk(5,dim = 1)top_5_ps.shape(128,5)
在整个测试集上评估模型,我们计算指标:
最终测试前1加权精度= 88.65%最终测试前5加权精度= 98.00%每个图像的最终测试交叉熵= 0.3772。
这些与验证数据中接近90%的前1精度相比是有利的。总的来说,我们得出结论,我们的预训练模型能够成功地将其知识从Imagenet转移到我们较小的数据集。
模型调查
尽管该模型表现良好,但可能采取的措施可以使其更好。通常,弄清楚如何改进模型的最佳方法是调查其错误(注意:这也是一种有效的自我改进方法。)
我们的模型不太适合识别鳄鱼,所以我们来看看这个类别的一些测试预测: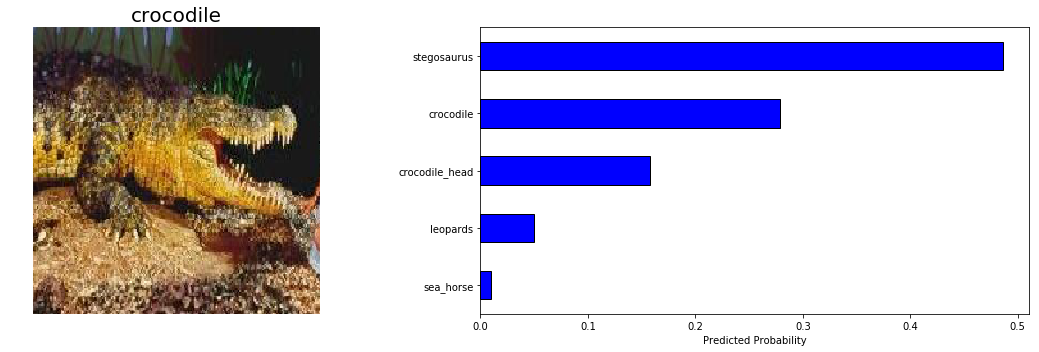


鉴于之间的微妙区别crocodile和crocodile_head ,和第二图像的困难,我会说我们的模式是不是在这些预测完全不合理的。图像识别的最终目标是超越人类的能力,我们的模型几乎就在那里!
最后,我们希望模型在具有更多图像的类别上表现更好,因此我们可以查看给定类别中的准确度图表与该类别中的训练图像数量: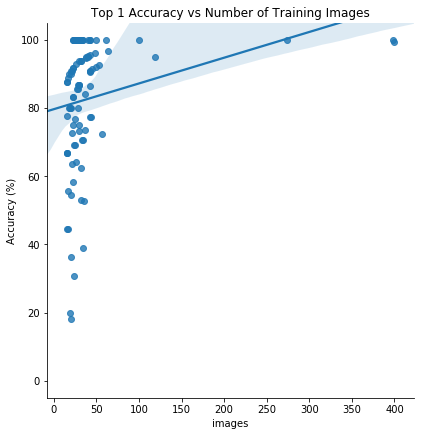
在训练图像的数量和前1个测试精度之间似乎存在正相关。这表明更多的训练数据增加可能是有帮助的,或者,甚至我们应该使用测试时间增加。我们还可以尝试不同的预训练模型,或者构建另一个自定义分类器。目前,深度学习仍然是一个经验领域,通常需要进行实验!
结论
虽然有更容易使用的深度学习库,但PyTorch的好处是速度,对模型架构/培训的各个方面的控制,具有张量自动区分的反向传播的有效实现,以及由于PyTorch图的动态特性而易于调试代码。对于生产代码或您自己的项目,我不知道有尚未使用的,而不是用温和的学习曲线,如图书馆PyTorch一个令人信服的理由Keras,但它有助于了解如何使用不同的选项。
通过这个项目,我们能够看到使用PyTorch的基础知识以及转移学习的概念,这是一种有效的对象识别方法。我们可以使用已在大型数据集上进行过培训的现有体系结构,然后根据我们的任务调整它们,而不是从头开始训练模型。这减少了训练时间,并且通常可以带来更好的整体表现。这个项目的成果是转移学习和PyTorch的一些知识,我们可以构建它来构建更复杂的应用程序。
我们真正生活在一个令人难以置信的深度学习时代,任何人都可以利用轻松可用的资源建立深度学习模型!现在走出去,通过构建自己的项目来利用这些资源。

若有收获,就点个赞吧
0 人点赞
