当我开始编码神经网络时,我最终使用了我周围的其他人正在使用的东西。TensorFlow。
但最近,PyTorch已成为成为深度学习框架之王的主要竞争者。它真正引诱的是它的动态计算图范式。不要担心最后一行现在对你没有意义。到这篇文章结束时,它会。但请相信,它使调试神经网络更容易。
先决条件
在我们开始之前,我必须指出你应该至少有一个基本的想法:
- 与神经网络训练有关的概念,特别是反向传播和梯度下降。
- 应用链规则来计算导数。
- 类如何在Python中工作。(或者关于面向对象编程的一般概念)
万一,你错过了上述任何一个,我在文章的最后提供了链接来指导你。
那么,是时候开始使用PyTorch了。这是PyTorch系列教程中的第一篇。
这是我将描述基本构建块和Autograd的第1部分。
注意:需要注意的一点是,本教程是针对PyTorch 0.3及更低版本的。最新版本为0.4。我决定坚持使用0.3,因为截至目前,0.3是Conda和pip频道中的版本。此外,开源中使用的大多数PyTorch代码尚未更新,以包含0.4中提出的一些更改。但是,我会在某些地方指出0.3和0.4之间的差异。
Building Block#1:Tensors
如果您曾经在python中进行过机器学习,那么您可能会遇到NumPy。我们使用Numpy的原因是因为它在执行矩阵操作时比Python列表快得多。为什么?因为它在C中完成了大部分繁重的工作。
但是,在训练深度神经网络的情况下,NumPy阵列根本不会削减它。我懒得去做这里的实际计算(google为“在ResNet的一次迭代中获得一个想法的FLOPS),但仅使用NumPy阵列的代码将需要几个月来训练一些最先进的网络。
这是Tensors发挥作用的地方。PyTorch为我们提供了一个名为Tensor的数据结构,它与NumPy的ndarray非常相似。但与后者不同,张量可以利用GPU的资源来显着加速矩阵运算。
以下是制作张量的方法。
In [1]: import torchIn [2]: import numpy as npIn [3]: arr = np.random.randn((3,5))In [4]: arrOut[4]:array([[-1.00034281, -0.07042071, 0.81870386],[-0.86401346, -1.4290267 , -1.12398822],[-1.14619856, 0.39963316, -1.11038695],[ 0.00215314, 0.68790149, -0.55967659]])In [5]: tens = torch.from_numpy(arr)In [6]: tensOut[6]:-1.0003 -0.0704 0.8187-0.8640 -1.4290 -1.1240-1.1462 0.3996 -1.11040.0022 0.6879 -0.5597[torch.DoubleTensor of size 4x3]In [7]: another_tensor = torch.LongTensor([[2,4],[5,6]])In [7]: another_tensorOut[13]:2 45 6[torch.LongTensor of size 2x2]In [8]: random_tensor = torch.randn((4,3))In [9]: random_tensorOut[9]:1.0070 -0.6404 1.2707-0.7767 0.1075 0.4539-0.1782 -0.0091 -1.04630.4164 -1.1172 -0.2888[torch.FloatTensor of size 4x3]
Building Block#2:计算图
现在,我们处于业务方面。当训练神经网络时,我们需要针对每个权重和偏差计算损失函数的梯度,然后使用梯度下降来更新这些权重。
随着神经网络达到数十亿的权重,有效地完成上述步骤可以决定训练的可行性。
Building Block#2.1:计算图
计算图是现代深度学习网络工作方式的核心,PyTorch也不例外。让我们先了解它们是什么。
假设,您的模型描述如下:
b = w1 * ac = w2 * ad =(w3 * b)+(w4 * c)L = f(d)
如果我实际绘制计算图,它可能看起来像这样。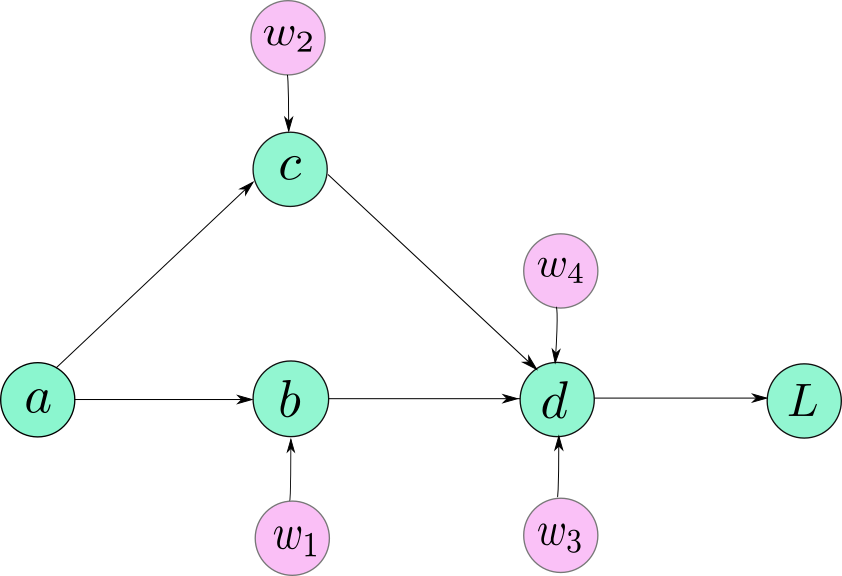
现在,您必须注意,上图并不完全准确地表示PyTorch如何在图表下表示图形。然而,就目前而言,它足以让我们的观点回家。
当我们可以按顺序执行计算输出所需的操作时,为什么要创建这样的图形?
想象一下,如果您不仅需要计算输出而且还要训练网络,那会发生什么。您必须计算紫色节点标记的所有权重的渐变。这将要求您围绕链规则找到方法,然后更新权重。
计算图只是一个数据结构,允许您有效地应用链规则来计算所有参数的渐变。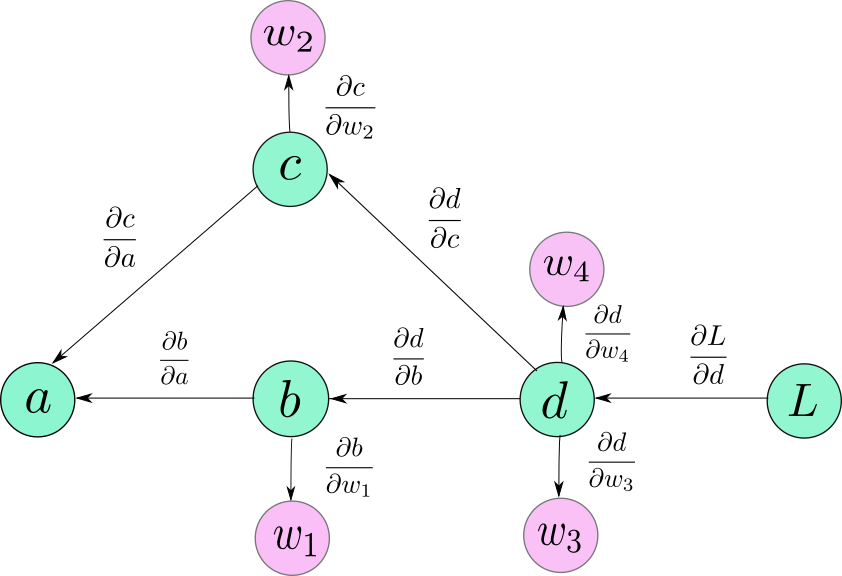
这里有几点需要注意。首先,箭头的方向现在在图中反转。那是因为我们正在向后传播,箭头标志着渐变的向后流动。
其次,为了这些例子,你可以把我写的渐变想象成边缘权重。请注意,这些渐变不需要计算链规则。
现在,为了计算任何节点的梯度,比如L,相对于任何其他节点,比如c(dL / dc),我们所要做的就是。
- 跟踪从L到c的路径。这将是L→d→c。
- 沿着此路径移动时,将所有边权重相乘。您最终得到的数量是:(dL / dd)*(dd / dc)=(dL / dc)
- 如果有多个路径,请添加其结果。例如,在dL / da的情况下,我们有两条路径。L→d→c→a和L→d→b→a。我们添加他们的贡献来获得L wrta的渐变
[(dL / dd)*(dd / dc)*(dc / da)] + [(dL / dd)*(dd / db)*(db / da)]
原则上,可以从L开始,然后开始向后遍历图形,计算沿途出现的每个节点的梯度。
Building Block#3:变量和Autograd
PyTorch使用Autograd软件包完成了我们上面描述的内容。
现在,基本上有三个重要的事情需要了解Autograd的工作原理。
Building Block#3.1:变量
该变量,就像张量是用来存放数据的类。然而,它的使用方式不同。变量专门用于保存在神经网络训练期间发生变化的值,即我们网络的可学习参数。另一方面,张量用于存储不学习的值。例如,Tensor可用于存储每个示例生成的损失值。
from torch.autograd import Variablevar_ex = Variable(torch.randn((4,3)) #creating a Variable
甲变量类包装的张量。您可以通过调用Variable的.data属性来访问此张量 。
该变量还存储标量相对于它保持该参数的梯度(比方说,损失)。可以通过调用.grad属性来访问此渐变 。这基本上是直到该特定节点计算的梯度,并且每个后续节点的梯度可以通过将边缘权重与在其之前的节点处计算的梯度相乘来计算。
变量保存的第三个属性是grad_fn,一个创建变量的Function对象。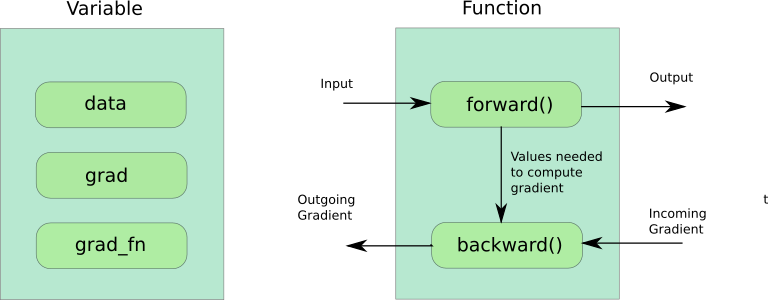
注意: PyTorch 0.4将Variable和Tensor类合并为一个,Tensor可以通过开关变为“变量”而不是实例化新对象。但是,因为我们在本教程中做了0.3,我们将继续。
Building Block#3.2:功能
我说上面的功能了吗?它基本上是一个函数的抽象。接受输入并返回输出的东西。例如,如果我们有两个变量a和b,那么,如果,
c = a + b
然后c是一个新变量,它的grad_fn是一个名为AddBackward(PyTorch的内置函数,用于添加两个变量),该函数将a和b作为输入,并创建c。
然后,你可能会问,为什么需要一个全新的类,当python确实提供了一种定义函数的方法?
在训练神经网络时,有两个步骤:前向传递和后向传递。通常,如果要使用python函数实现它,则必须定义两个函数。一,计算前向传递期间的输出,另一个计算要传播的梯度。
PyTorch抽象需要将两个单独的函数(用于前向和后向传递)写入一个名为torch.autograd.Function的类的两个函数成员中。
PyTorch结合了变量和函数来创建计算图。Building Block#3.3:Autograd
现在让我们深入研究PyTorch如何创建计算图。首先,我们定义变量。
from torch import FloatTensorfrom torch.autograd import Variable# Define the leaf nodesa = Variable(FloatTensor([4]))weights = [Variable(FloatTensor([i]), requires_grad=True) for i in (2, 5, 9, 7)]# unpack the weights for nicer assignmentw1, w2, w3, w4 = weightsb = w1 * ac = w2 * ad = w3 * b + w4 * cL = (10 - d)L.backward()for index, weight in enumerate(weights, start=1):gradient, *_ = weight.grad.dataprint(f"Gradient of w{index} w.r.t to L: {gradient}")
上面代码行的结果是,
Gradient of L w.r.t to w1: -36.0Gradient of L w.r.t to w2: -28.0Gradient of L w.r.t to w3: -8.0Gradient of L w.r.t to w4: -20.0
现在,让我们剖析一下这里到底发生了什么。如果你看一下源代码,这就是事情的发展方向。
- 定义图的叶变量(第5-9行)。我们首先定义一堆“变量”(Normal,python使用语言,而不是pytorch 变量)。如果您注意到,我们定义的值是计算图中的叶节点。我们必须定义它们才有意义,因为这些节点不是任何计算的结果。此时,这些人现在占用我们的Python命名空间中的内存。手段,他们百分之百真实。我们必须将requires_grad 属性设置为True,否则,这些变量将不会包含在计算图中,并且不会为它们计算梯度(以及其他变量,这些变量依赖于梯度流的这些特定变量)。
- 创建图形(第12-15行)。直到现在,我们的记忆中没有任何计算图形。只有叶节点,但是一旦你写了12-15行,就会在飞行中生成一个图形。非常重要的是指定这个细节。在飞行中。当你写b = w1 * a时,它就是图形创建开始的时候,并一直持续到第15行。这正是我们模型的正向传递,当输出是根据输入计算的。每个变量的前向函数可以缓存一些输入值,以便在后向传递上计算梯度时使用。(例如,如果我们的前向函数计算W * x,那么d(W * x)/ d(W)是x,需要缓存的输入)
- 现在,我告诉你我之前绘制的图表的原因并不准确?因为当PyTorch创建图形时,它不是作为图形节点的Variable对象。它是一个Function对象,恰恰是构成图形节点的每个Variable的grad_fn。所以,PyTorch图看起来像。
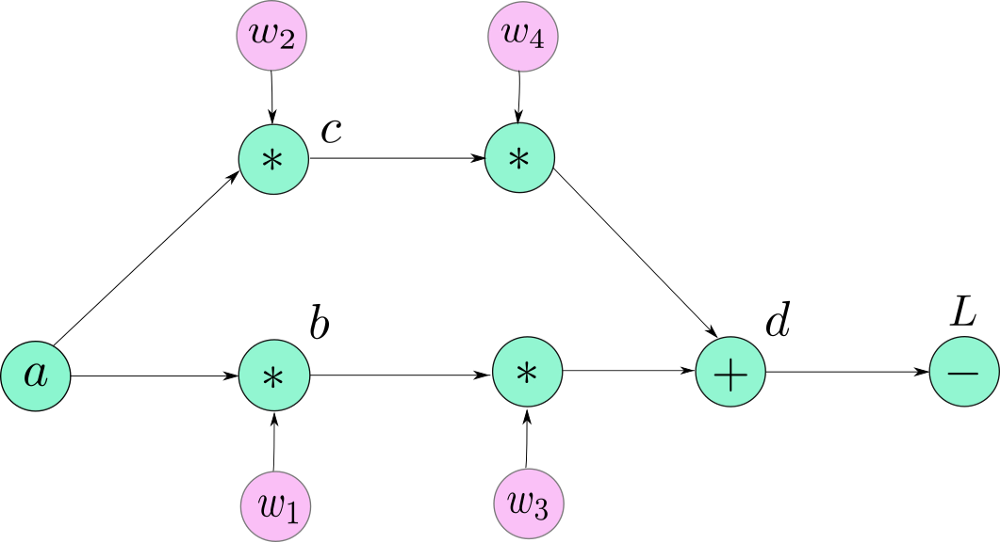
- 我用它们的名字来表示叶子节点,但是它们也有它们的grad_fn(它返回一个None值。这是有道理的,因为你不能在叶子节点之外反向传播)。其余的节点现在由他们的grad_fn替换。我们看到单个节点d被三个函数,两个乘法和一个加法所取代,而损失则被减去函数所取代。
- 计算梯度(第18行)。我们现在通过调用L上的.backward()函数来计算渐变 。到底发生了什么?首先,L处的梯度简单地为1(dL / dL)。然后,我们调用它的向后函数,它基本上具有计算的输出的梯度的一个工作功能对象,WRT到的输入功能对象。这里,L是10-d的结果,这意味着,向后函数将梯度(dL / dd)计算为-1。
- 现在,这个计算的梯度乘以累积的梯度(存储在与当前节点对应的变量的grad属性中,在我们的例子中是dL / dL = 1),然后发送到输入节点,存储在与输入节点对应的变量的grad属性。从技术上讲,我们所做的是应用链规则(dL / dL)*(dL / dd)= _
- 现在,让我们了解如何为变量 d传播渐变。d由其输入(w3,w4,b,c)计算得出。在我们的图中,它由3个节点,2个乘法和1个加法组成。
- 首先,函数AddBackward(表示我们图中节点d的加法运算)计算它输出的渐变(w3 b + w4 c)和它的输入(w3 b和w4 c),两者都是1 )。现在,将这些局部梯度乘以累积梯度(两者的dL / dd x 1 = -1),并将结果保存在各个输入节点的grad属性中。
- 然后,功能MulBackward(较乘法运算W4 * C)计算它的梯度的输入输出WRT到它的输入端(C ^ W4和)一个秒(C和W4)分别。局部梯度乘以累积梯度(dL / d(w4 * c) = -1)。然后将结果值(-1 × c和-1× w4)分别存储在变量w4和c的grad属性中。
- 以类似的方式计算所有节点的梯度。
- 可以通过调用访问任何节点的L的梯度。如果它是一个叶子节点,那么对应于该节点的变量上的grad(PyTorch的默认行为不允许您访问非叶节点的渐变。稍后会详细介绍)。现在我们已经获得了渐变,我们可以使用SGD或您喜欢的任何优化算法来更新我们的权重。
w1 = w1 - (learning_rate)* w1.grad #update使用GD的wieghts
Autograd的一些漂亮细节
所以,我没有告诉你,你无法访问非叶子变量的grad属性。是的,那是默认行为。您可以通过调用覆盖它。在定义它之后,在变量上使用retain_grad(),然后你就可以访问它的grad属性了。但实际上,在包装下发生了什么。
动态计算图
PyTorch创建了一个名为Dynamic Computation Graph的东西,这意味着图形是即时生成的。在调用Variable 的forward函数之前,图中的Variable(它的grad_fn)没有节点。该图是作为调用的许多变量的前向函数的结果而创建的。只有这样,缓冲区才会分配给图形和中间值(以后用于计算梯度)。当您调用backward()时,随着计算渐变,这些缓冲区基本上被释放,图形被破坏。您可以尝试向后拨打电话()在图表上不止一次,你会看到PyTorch会给你一个错误。这是因为图形在第一次调用backward()时被破坏,因此,第二次没有图形向后调用。
如果再次呼叫前转,则会生成一个全新的图表。分配了新的内存。
默认情况下,仅保存叶节点的渐变(grad属性),并销毁非叶节点的渐变。但是如上所述可以改变这种行为。
这与TensorFlow使用的Static Computation Graph 形成对比,TensorFlow 在运行程序之前声明了图形。动态图表范例允许您在运行时更改网络体系结构,因为只有在运行一段代码时才会创建图形。这意味着可以在程序的生命周期内重新定义图形。但是,对于静态图形而言,这是不可能的,其中图形在运行程序之前创建,并且仅在稍后执行。动态图表也使调试更容易,因为错误源很容易追踪。
一些贸易伎俩
requires_grad
这是Variable类的一个属性。默认情况下,它是假的。当您必须冻结某些图层并在训练时阻止他们更新参数时,它会派上用场。您可以简单地将requires_grad设置为False,并且这些变量不会包含在计算图中。因此,没有梯度将传播到它们,或者传播到依赖于这些层用于梯度流动的那些层。requires_grad,当设置为True时具有 传染性,这意味着即使操作的一个操作数将requires_grad设置为True,结果也是如此。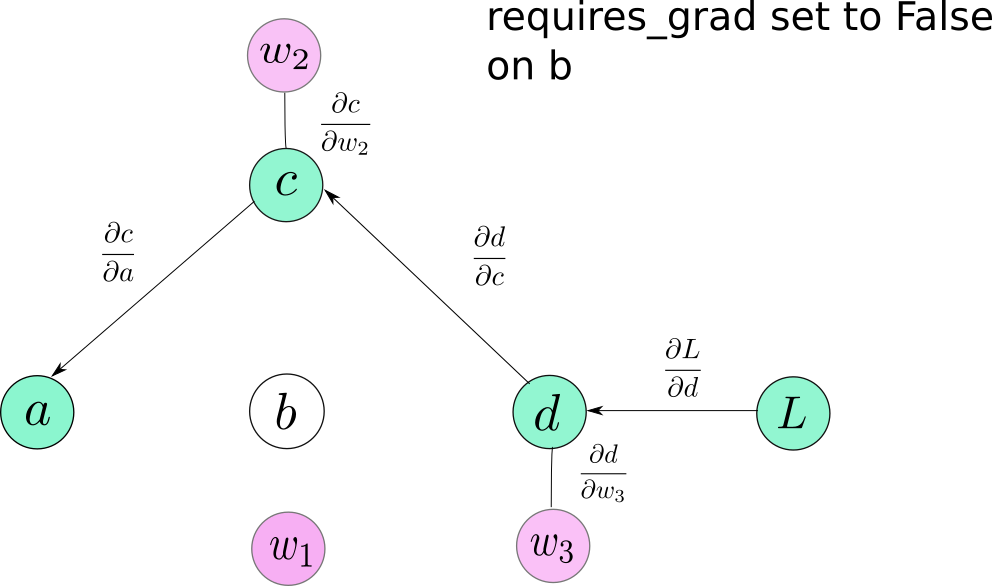
挥发物
这又是Variable类的一个属性,当它设置为True时,会导致变量从计算图中排除。它似乎与requires_grad非常相似,因为它在设置为True时也具有传染性。但它的优先级高于requires_grad 。具有requires_grad的变量等于True且volatile等于True,不会包含在计算图中。
你可能会想,当我们可以简单地将requires_grad设置为False 时,有什么需要让另一个开关覆盖requires_grad?让我离题一段时间。
在我们进行推理时,不创建图形非常有用,并且不需要渐变。首先,消除了创建计算图的开销,并且提高了速度。其次,如果我们创建一个图形,并且由于没有向后调用后跟,那么用于缓存值的缓冲区永远不会被释放,并可能导致内存不足。
通常,我们在神经网络中有许多层,我们可能在训练时将requires_grad设置为True。为了防止图形在推理中产生,我们可以做两件事之一。在所有图层上设置r equires_grad False (可能是152个?)。或者,仅在输入上设置volatile True,并且我们确保没有结果操作将导致生成图表。你的选择。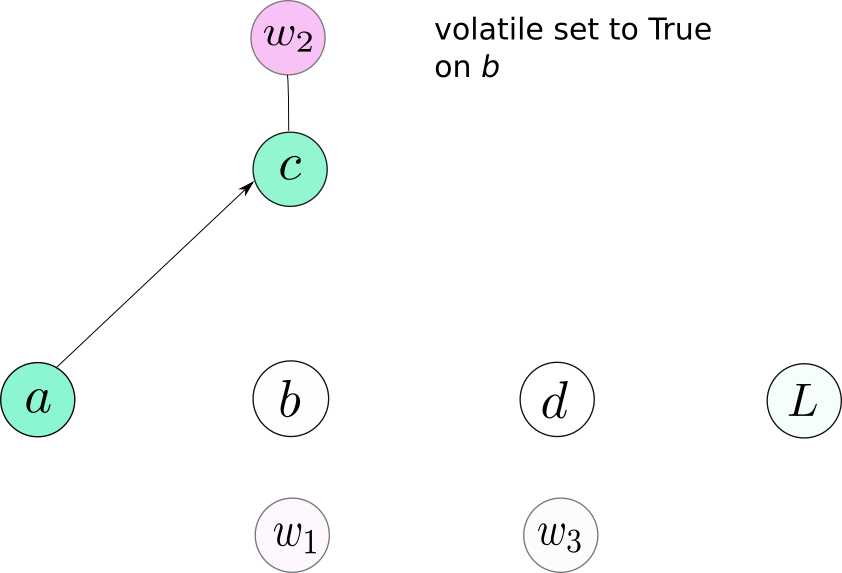
注意: PyTorch 0.4对于组合的Tensor / Variable类没有volatile参数。相反,推理代码应放在torch.no_grad()上下文管理器中。 与torch.no_grad():
——-您的推理代码在这里——结论
所以,这对你来说是Autograd。了解Autograd的工作方式可以让您在遇到某个地方时遇到很多麻烦,或者在您刚开始时处理错误。感谢您的阅读。我打算在PyTorch上编写更多的教程,讨论如何使用内置函数快速创建复杂的体系结构(或者,可能不是那么快,但比逐块编码更快)。所以,请继续关注!
进一步阅读

若有收获,就点个赞吧
0 人点赞
