链接
通过对基本概念的直观解释,了解对象检测和本地化的最新进展。
目标检测是计算机视觉领域中非常迅速成熟的领域之一。 感谢深度学习! 每年,新的算法/模型都会比以前更好。 事实上,Facebook AI团队上周刚刚发布了最先进的物体检测软件系统之一。 该软件称为Detectron,它包含许多用于物体检测的研究项目,并由Caffe2深度学习框架提供支持。
今天,有大量用于目标检测的预训练模型(YOLO,RCNN,Faster RCNN,Mask RCNN,Multibox等)。 因此,只需花费少量精力即可检测视频或图像中的大多数对象。 但我的博客的目标不是谈论这些模型的实现。 相反,我试图以清晰简洁的方式解释基本概念。
我最近完成了3周的Andrew Ng的卷积神经网络课程,其中他谈到了目标检测算法。 此博客的大部分内容都受到该课程的启发。
编辑:我目前正在进行Fast.ai的尖端深度学习编码课程,由Jeremy Howard教授。 现在,我使用PyTorch和fast.ai库实现了下面讨论的算法。 这是代码的链接。 如果您想了解下面讨论的算法的实现部分,请查看此信息。 该实现已经从fast.ai课程笔记本借用,附有评论和注释。
关于CNN的简介
在我解释目标检测算法的工作之前,我想在卷积神经网络(也称为CNN或ConvNets)上写上几笔。 CNN是深度学习时代大多数计算机视觉任务的基本构建模块。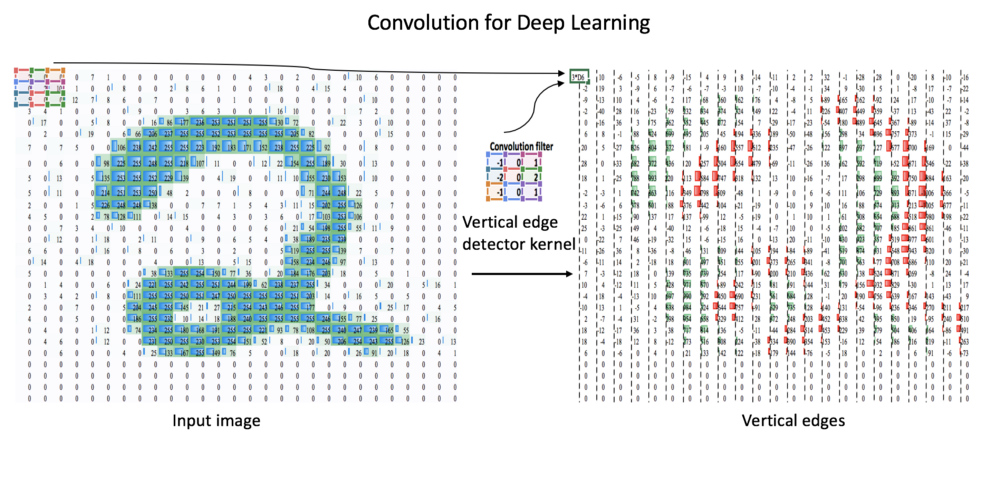
我们想要什么? 我们需要一些查看图像的算法,查看图像中的图案并告知图像中的对象类型。 例如,是猫或狗的形象。
什么是电脑的图像? 只是数字矩阵。 对于例如 见上图1。 左边的图像只是手写数字2的28 28像素图像(取自MNIST数据),在Excel电子表格中表示为数字矩阵。
我们怎样才能教电脑学会识别图像中的物体? 通过让计算机学习垂直边缘,水平边缘,圆形以及许多其他人类未知的模式。
计算机如何学习模式?卷积!
(阅读本文时请看上图)卷积是两个矩阵之间的数学运算,给出第三个矩阵。 我们称之为滤波器或内核(图1中的3x3)的较小矩阵在图像像素矩阵上操作。 根据滤波器矩阵中的数字,输出矩阵可以识别输入图像中存在的特定模式。 在上面的示例中,滤波器是垂直边缘检测器,其学习输入图像中的垂直边缘。 在深度学习的背景下,输入图像及其后续输出从许多这样的滤波器传递。 过滤器中的数字是通过神经网络学习的,模式是自己导出的。
*为什么卷积有效? 因为在大多数图像中,对象具有可以通过卷积来利用的相对像素密度(数字的大小)的一致性。
我知道CNN上只有几行对于不了解CNN的读者来说是不够的。 但CNN不是本博客的主题,我已经提供了基本介绍,因此读者可能不需要再打开10个链接来先了解CNN,然后再继续。
阅读本博客后,如果您仍想了解更多关于CNN的信息,我强烈建议您阅读Adam Geitgey撰写的这篇博客。
计算机视觉任务的分类
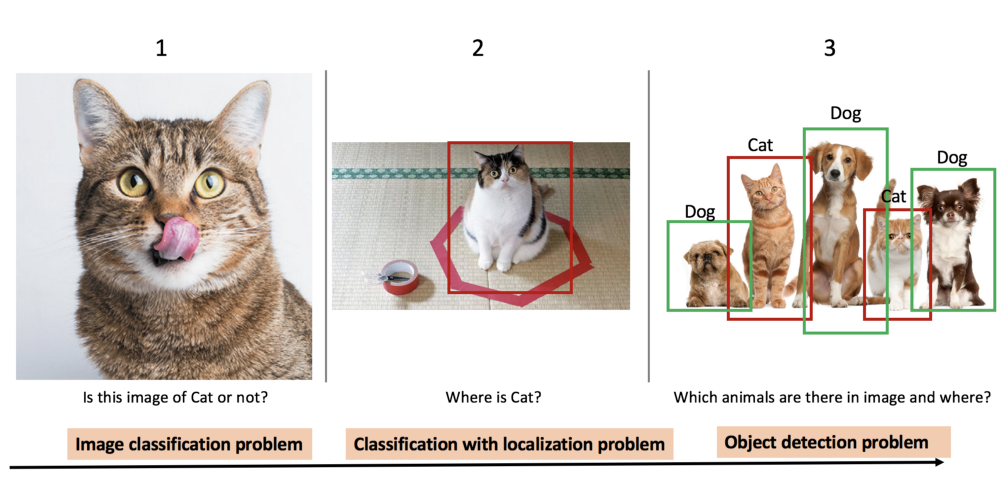
以图2中的猫狗图像为例,以下是计算机视觉建模算法最常见的任务:
图像分类:这是最常见的计算机视觉问题,其中算法查看图像并对其中的对象进行分类。 图像分类具有广泛的应用,从社交网络上的面部检测到医学中的癌症检测。 通常使用卷积神经网络(CNN)对这些问题进行建模。
目标分类和定位:假设我们不仅想知道图像中是否有猫,而且猫的确切位置。 对象定位算法不仅标记对象的类,还在图像中的对象位置周围绘制边界框。
多个目标检测和定位:如果图像中有多个物体(如上图中的3只狗和2只猫),我们想要检测它们,该怎么办? 这将是一个对象检测和定位问题。 众所周知的应用是在自动驾驶汽车中,该算法不仅需要检测汽车,还需要检测车架中的行人,摩托车,树木和其他物体。 这些问题需要利用从图像分类和对象定位中学到的思想或概念。
现在回到计算机视觉任务。 在深度学习的背景下,上述3种任务之间的基本算法差异就是选择相关的输入和输出。 让我用信息图解释这一行。
1 图像分类
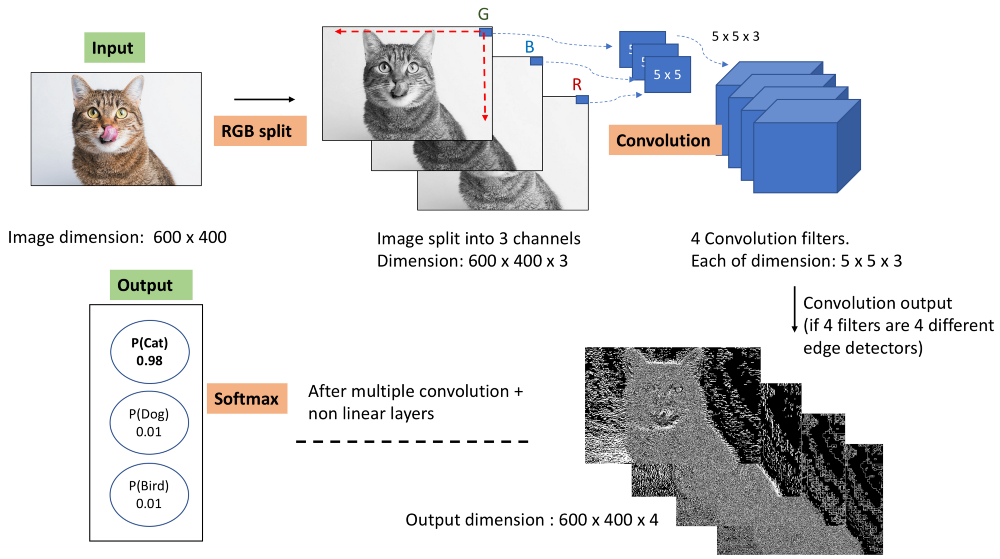
图2中的信息图显示了用于图像分类的典型CNN的外观。通过n滤波器(图3中n = 4)卷积一些高度,宽度和通道深度(上面的情况下为940,550,3)的输入图像[如果你仍然感到困惑究竟卷积是什么意思,请检查 这个链接来理解深度神经网络中的卷积]。
卷积的输出用非线性变换处理,通常是Max Pool和RELU。
Convolution,Max Pool和RELU的上述3个操作被执行多次。
最终层的输出被发送到Softmax层,该层转换0和1之间的数字,从而给出图像特定类的概率。 我们将损失降至最低,以便使最后一层的预测接近实际值。
2.物体分类和定位
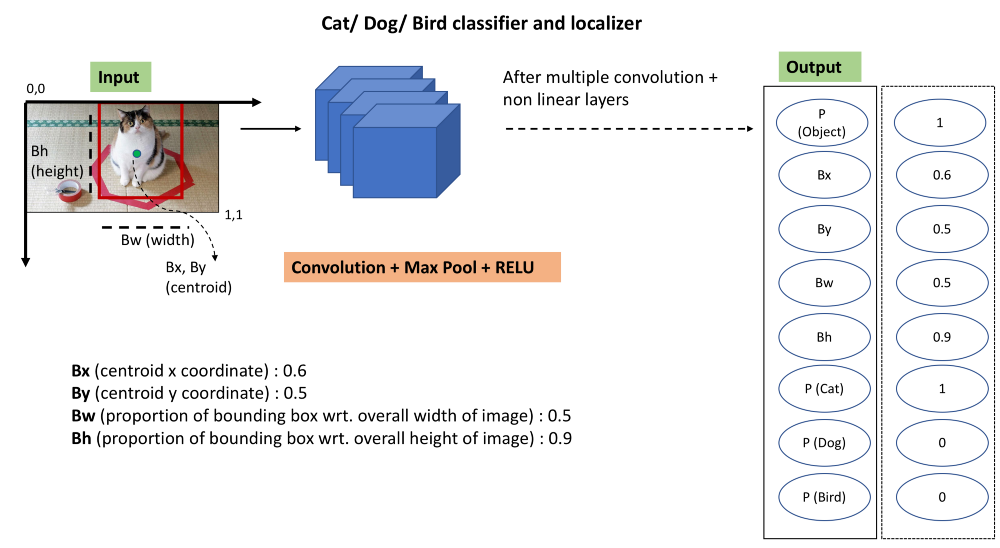
现在,为了使我们的模型绘制对象的边界框,我们只需更改前一算法的输出标签,以使我们的模型学习对象类以及对象在图像中的位置。 我们在输出层添加4个数字,包括对象的质心位置和图像中边界框的宽度和高度的比例。
简单吧? 只需添加一堆输出单元即可吐出您想要识别的不同位置的x,y坐标。 对于我们拥有的所有图像中的特定对象,这些不同的位置或界标将是一致的。 对于例如对于汽车而言,高度将小于宽度,并且与图像中的其他点相比,质心将具有一些特定的像素密度。
隐含相同的逻辑,如果图像中有多个对象并且我们想要对所有这些对象进行分类和定位,您认为会发生什么变化? 我建议你暂时停下来思考,你可能会自己得到答案。
3.目标检测和定位
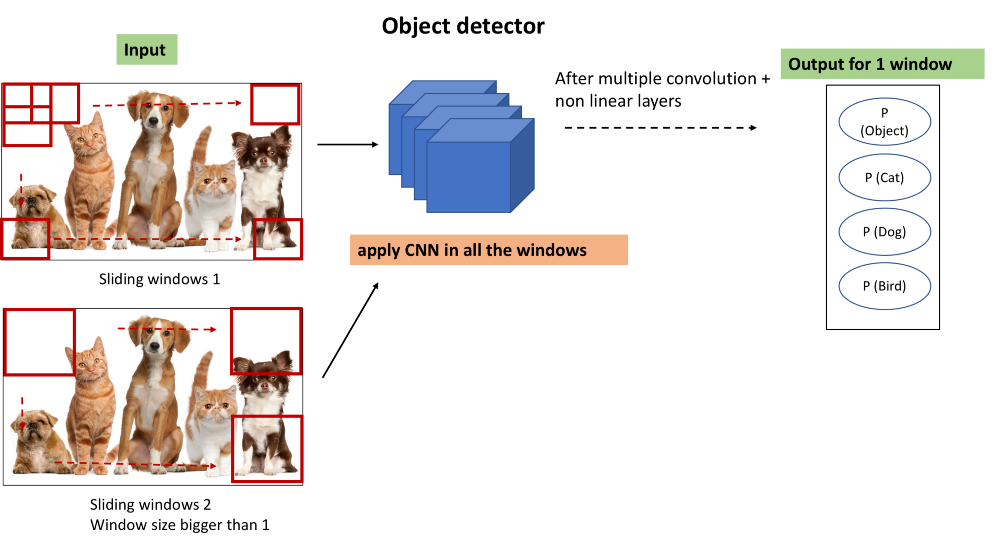
为了检测图像中的各种对象,我们可以直接使用我们从目前为止学到的东西。 不同之处在于我们希望我们的算法能够对图像中的所有对象进行分类和定位,而不仅仅是一个。 因此,我们的想法是,只需将图像裁剪成多个图像,然后为所有裁剪的图像运行CNN以检测对象。
算法的工作方式如下:
制作一个比实际图像尺寸小得多的窗口。 裁剪它并将其传递给ConvNet(CNN)并让ConvNet进行预测。
继续滑动窗口并将裁剪后的图像传递到ConvNet。
在使用此窗口大小裁剪图像的所有部分后,再次重复所有步骤以获得更大的窗口大小。 再次将裁剪后的图像传递到ConvNet并让它进行预测。
最后,您将拥有一组裁剪区域,这些区域将包含一些对象,以及对象的类和边界框
该解决方案被称为具有滑动窗口的物体检测。 这是非常基本的解决方案,有以下几点需要注意:
A.计算成本高:裁剪多个图像并通过ConvNet传递它将在计算上非常昂贵。
解决方案:有一个简单的hack来提高滑动窗口方法的计算能力。 它是用1x1卷积层替换ConvNet中的完全连接层,对于给定的窗口大小,只传递一次输入图像。 因此,在实际实现中,我们不会一次传递一个裁剪后的图像,但我们会立即传递完整的图像。
B.不准确的边界框:我们在整个图像上滑动方形窗口,也许对象是矩形的,或者没有一个正方形与对象的实际大小完全匹配。 虽然该算法具有查找和定位图像中多个对象的能力,但是边界框的准确性仍然很差。
我已经谈到了对象检测问题的最基本的解决方案。 但它有许多警告,并不是最准确的,并且实施起来计算成本很高。 那么,我们如何才能使我们的算法更好更快?
好的解决方案?YOLO
事实证明,我们有YOLO(你只看一次),它比滑动窗口算法更准确,更快。 它仅基于我们已经知道的算法顶部的微小调整。 我们的想法是将图像分成多个网格。 然后我们改变数据的标签,以便我们为每个网格单元实现定位和分类算法。 让我再向您解释一下这个信息图。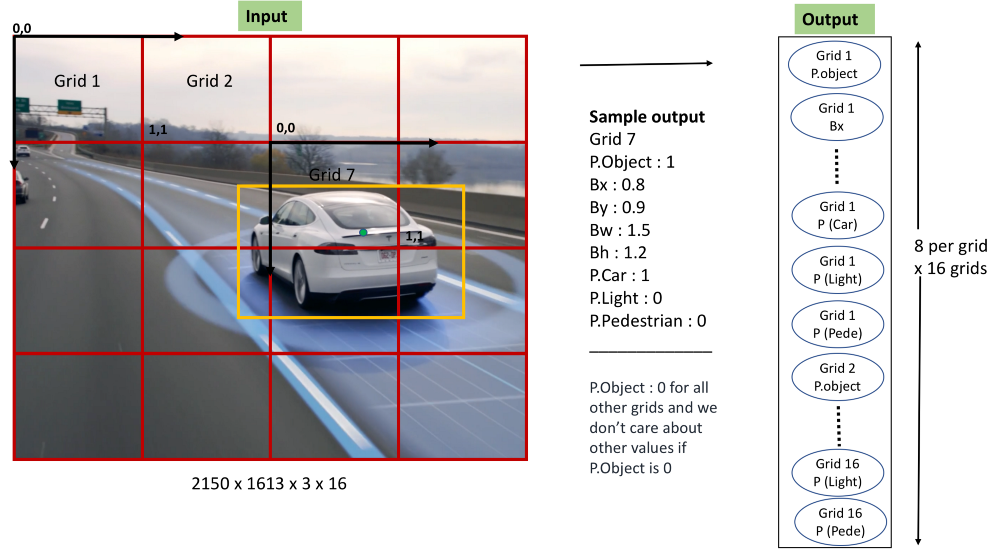
YOLO简单的步骤:
将图像分成多个网格。 为了说明,我在上图中绘制了4x4网格,但YOLO的实际实现具有不同的网格数量。 (7x7用于在PASCAL VOC数据集上培训YOLO)
标记训练数据,如上图所示。 如果C是我们数据中唯一对象的数量,S S是我们分割图像的网格数,那么我们的输出向量将是长度S S (C + 5)。 对于例如 在上面的例子中,我们的目标向量是4 4 (3 + 5),因为我们将图像划分为4 4网格,并训练3个独特的对象:汽车,光和行人。
制作一个具有损失函数的深度卷积神经网络作为输出激活和标签矢量之间的误差。 基本上,该模型通过ConvNet仅在输入图像的一个前向通道中预测所有网格的输出。
请记住,对象存在于网格单元格(P.Object)中的标签由该网格中对象的质心的存在决定。 重要的是不允许在不同的网格中多次对一个对象进行计数。
YOLO的注意事项及其解决方案:
- A.无法检测同一网格中的多个对象。
通过选择较小的网格大小可以解决此问题。 但即使选择较小的网格大小,在对象彼此非常接近的情况下,算法仍然会失败,如鸟群的图像。
解决方案:Anchor boxes。 除了每个网格单元具有5 + C标签(其中C是不同对象的数量)之外,Anchor boxes的想法是每个网格单元具有(5 + C) A标签,其中A是必需的Anchor boxes。 如果将一个对象分配给一个网格中的一个Anchor boxes,则可以将另一个对象分配给同一网格的另一个*Anchor boxes。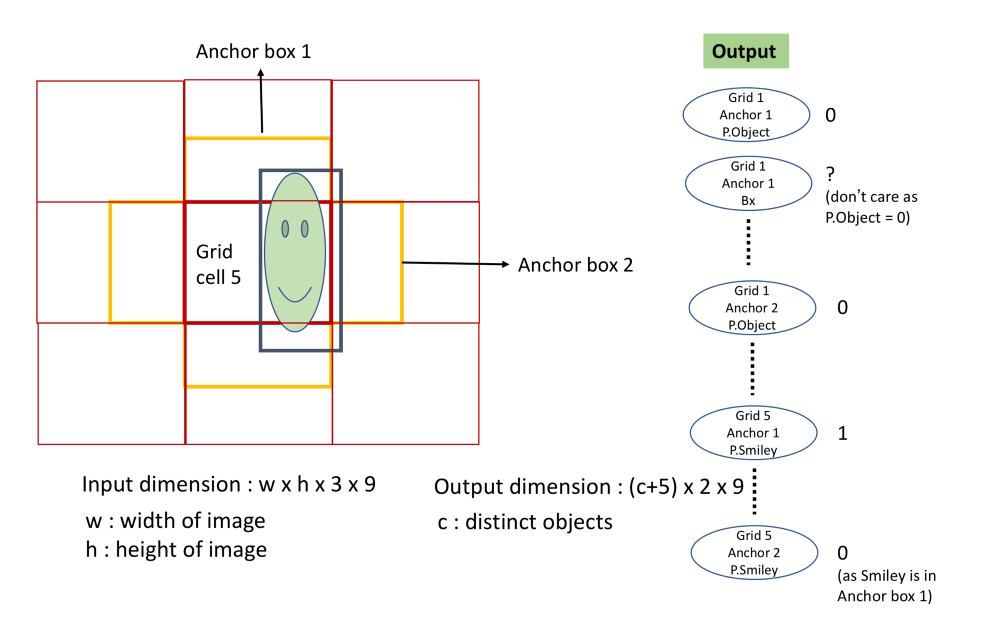
- B.可多次检测一个物体的可能性。
解决方案:非最大抑制。 非最大抑制消除了非常接近高概率边界框的低概率边界框。
结论:
截至今天,有多种版本的预训练YOLO模型可用于不同的深度学习框架,包括Tensorflow。 最新的YOLO论文是:“YOLO9000:更好,更快,更强”。 该模型接受了9000个课程的培训。 还有一些基于选择性区域提案的区域CNN(R-CNN)算法,我没有讨论过。 由Facebook AI开发的Detectron软件系统也实现了R-CNN,Masked R-CNN的变体。
参考文献:
You Only Look Once: Unified, Real-Time Object Detection
https://arxiv.org/pdf/1506.02640.pdfYOLO9000: Better, Faster, Stronger
https://arxiv.org/pdf/1612.08242.pdfConvolutional Neural Networks by Andrew Ng (deeplearning.ai)
https://www.coursera.org/learn/convolutional-neural-networks

若有收获,就点个赞吧
0 人点赞
