
自从2014年推出以来,XGBoost一直被誉为机器学习黑客马拉松和竞赛的圣杯。从预测广告点击率到分类高能物理事件,XGBoost已经证明了它在性能和速度方面的优势。
在任何ML黑客马拉松中,我总是将XGBoost作为我的首选算法。它始终如一的精确度和节省的时间证明了它的实用性。但它是如何实际工作的?什么样的数学能力XGBoost?我们很快就会找到这些问题的答案。
XGBoost的联合创始人之一Tianqi Chen宣布(2016年)XGBoost的创新系统功能和算法优化使其比大多数机器学习解决方案的速度快10倍。一个真正神奇的技术!
在本文中,我们将首先看看XGBoost的强大功能,然后深入探讨这种流行且强大的技术的内部运作。能够在Python或R中实现它是件好事,但了解算法的细节可以帮助您成为更好的数据科学家。
注意:我们建议您仔细阅读以下文章,以完全理解本文中提到的各种术语和概念:
目录
- XGBoost的力量
- 为什么要合奏学习?
- 展示推动潜力
- 使用梯度下降来优化损失函数
- XGBoost的独特功能
XGBoost的力量
这种强大算法的优点在于其可扩展性,通过并行和分布式计算推动快速学习,并提供高效的内存使用。
因此,欧洲核子研究中心认为它是对大型强子对撞机信号进行分类的最佳方法也就不足为奇了。欧洲核子研究中心提出的这一特殊挑战需要一种可扩展的解决方案,以便以每年3PB的速率处理数据,并在复杂的物理过程中有效地区分极为罕见的信号和背景噪声。XGBoost成为最有用,最直接和最强大的解决方案。
现在,让我们深入探讨XGBoost的内部运作。
为什么合奏学习?
XGBoost是一种集成学习方法。有时,依靠一个机器学习模型的结果可能还不够。集成学习提供了一种系统的解决方案,可以结合多个学习者的预测能力。结果是单个模型,它给出了几个模型的聚合输出。
形成整体的模型,也称为基础学习者,可以来自相同的学习算法或不同的学习算法。套袋和助力是两种广泛使用的整体学习者。虽然这两种技术可以与几种统计模型一起使用,但最主要的用法是使用决策树。
在更详细地介绍一下增强的概念之前,让我们先简单讨论一下装袋。
套袋
虽然决策树是最容易解释的模型之一,但它们表现出高度可变的行为。考虑我们随机分成两部分的单个训练数据集。现在,让我们使用每个部分来训练决策树,以获得两个模型。
当我们适合这两种模型时,它们会产生不同的结果。据说决策树由于这种行为而与高方差相关联。套袋或增强聚合有助于减少任何学习者的差异。并行生成的几个决策树构成了装袋技术的基础学习者。将替换样本数据提供给这些学习者进行培训。最终预测是所有学习者的平均输出。
推进
在增强中,树是顺序构建的,使得每个后续树旨在减少先前树的错误。每棵树都从其前身学习并更新残差。因此,序列中接下来生长的树将从残差的更新版本中学习。
提升的基础学习者是弱学习者,其中偏见很高,预测能力比随机猜测好一点。这些弱学习者中的每一个都为预测提供了一些重要信息,通过有效地结合这些弱学习者,使得提升技术能够产生强大的学习者。最后的强大学习者会降低偏见和差异。
与随机森林这样的套袋技术形成对比,其中树木最大程度地生长,增强使用树木,分裂较少。这种不太深的小树是高度可解释的。可以通过诸如k折交叉验证的验证技术来最佳地选择诸如树的数量或迭代,梯度增强学习的速率以及树的深度之类的参数。拥有大量树木可能会导致过度拟合。因此,有必要仔细选择提升的停止标准。
提升包括三个简单的步骤:
- 定义初始模型F0以预测目标变量y。该模型将与残差(y - F0)相关联
- 新模型h1适合于前一步骤的残差
- 现在,F0和h1组合起来给F1,F0的提升版本。F1的均方误差将低于F0的误差:
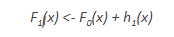
为了提高F1的性能,我们可以在F1的残差之后建模并创建一个新模型F2: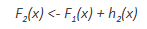
这可以在‘m’次迭代中完成,直到残差尽可能地最小化: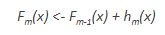
这里,加法学习者不会干扰前面步骤中创建的功能。相反,他们传授自己的信息来减少错误。
展示推动潜力
考虑以下数据,其中多年的经验是预测变量,工资(以千美元计)是目标。使用回归树作为基础学习者,我们可以创建一个模型来预测薪水。为简单起见,我们可以选择平方损失作为我们的损失函数,我们的目标是最小化平方误差。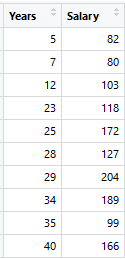
作为第一步,应使用函数F0(x)初始化模型。F0(x)应该是一个最小化损失函数或MSE(均方误差)的函数,在这种情况下:
将上述等式的第一个微分相对于γ,可以看出该函数在平均值i = 1nyin处最小化。因此,可以通过以下方式启动增强模型: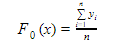
F0(x)给出了我们模型第一阶段的预测。现在,每个实例的残差为(yi-F0(x))。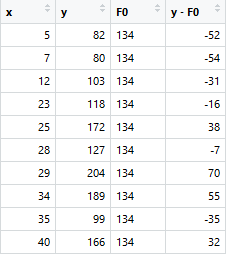
我们可以使用F0(x)中的残差来创建h1(x)。h1(x)将是一个回归树,它将尝试减少前一步骤中的残差。h1(x)的输出不是y的预测; 相反,它将有助于预测连续函数F1(x),这将减少残差。
加法模型h1(x)计算树的每个叶子的残差(y-F0)的平均值。通过对F0(x)和h1(x)求和来获得增强函数F1(x)。这样,h1(x)从F0(x)的残差中学习并在F1(x)中对其进行抑制。
这可以重复2次迭代以计算h2(x)和h3(x)。这些加法学习器中的每一个,hm(x),将利用来自前一函数Fm-1(x)的残差。
F0(x),F1(x)和F2(x)的MSE分别为875,692和540.令人惊讶的是,这些简单的弱学习者可以大大减少错误!
请注意,每个学习者hm(x)都会对残差进行训练。增强中的所有加性学习者都是在每个步骤的残差之后建模的。直觉上,可以观察到提升学习者利用剩余误差中的模式。在通过增强达到最大精度的阶段,残差看起来是随机分布的,没有任何模式。
Fn和hn的情节
使用梯度下降来优化损失函数
在上面讨论的情况下,MSE是损失函数。平均值最小化了错误。当MAE(平均绝对误差)是损失函数时,中值将用作F0(x)来初始化模型。y的单位变化也会导致MAE的单位变化。
对于MSE,观察到的变化大致呈指数变化。不是在残差上拟合hm(x),而是将其拟合在损失函数的梯度上,或者发生损失的步骤,将使该过程通用并适用于所有损失函数。
梯度下降有助于我们最小化任何可微分的功能。之前,hm(x)的回归树预测了树的每个终端节点的平均残差。在梯度增强中,将计算平均梯度分量。
对于每个节点,存在乘以hm(x)的因子γ。这说明了拆分的每个分支的影响差异。与传统的梯度下降技术不同,梯度增强有助于预测附加模型的最佳梯度,这种技术可减少每次迭代时输出的误差。
梯度增强涉及以下步骤:
- F0(x) - 用于初始化增强算法 - 将被定义:
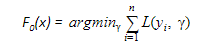
- 迭代计算损失函数的梯度:
- 每个hm(x)适合在每个步骤获得的梯度
- 导出每个终端节点的乘法因子γm,并定义增强模型Fm(x):
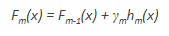
XGBoost的独特功能
XGBoost是渐变增强的流行实现。让我们来讨论XGBoost的一些功能,让它变得如此有趣。
- 正规化: XGBoost可以通过L1和L2正则化来惩罚复杂模型。正规化有助于防止过度拟合
- 处理稀疏数据:缺少值或数据处理步骤(如单热编码)会使数据稀疏。XGBoost采用了稀疏感知的拆分查找算法来处理数据中不同类型的稀疏模式
- 加权分位数草图:大多数现有的基于树的算法可以在数据点具有相等权重时找到分裂点(使用分位数草图算法)。但是,他们没有能力处理加权数据。XGBoost具有分布式加权分位数草图算法,可有效处理加权数据
- 并行学习的块结构:为了加快计算速度,XGBoost可以在CPU上使用多个内核。这是可能的,因为其系统设计中的块结构。数据被分类并存储在称为块的内存单元中。与其他算法不同,这使得数据布局可以通过后续迭代重用,而不是再次计算。此功能还可用于拆分查找和列子采样等步骤
- 缓存感知:在XGBoost中,需要非连续内存访问才能按行索引获取渐变统计信息。因此,XGBoost旨在最佳地利用硬件。这是通过在每个线程中分配内部缓冲区来完成的,其中可以存储梯度统计信息
- 核外计算:此功能可优化可用磁盘空间,并在处理不适合内存的大型数据集时最大化其使用率
结束笔记
所以这就是为流行的XGBoost算法提供动力的数学。如果你的基础知识是坚实的,那么这篇文章对你来说一定是轻而易举的。它是如此强大的算法,虽然还有其它技术(如CATBoost),但XGBoost仍然是机器学习社区的改变者。
如果您对该文章或任何上述概念有任何疑问,请在下面的评论部分与我联系。

若有收获,就点个赞吧
0 人点赞
