
来自社会科学,我习惯于使用具有几个分类变量的数据集。这些通常是实验条件(控制与干预),性别(女性与男性)或国籍(荷兰与德国对比利时对比其他)。但作为方法数据科学社区第2周练习的一部分,我的团队正在解决一个带有许多分类变量的Kaggle挑战。由于我的笔记本电脑仍在使用单热编码,因此需要一种不同的解决方案。我的团队成员Chris Dinant已经建议将Catboost作为处理分类数据的一种方式。这篇文章将深入研究这种方法,解释可以应用它的情况,以及如何应用它。
分类变量有什么问题?
当社会科学家使用分类变量时,他们通常使用两种解决方案中的一种:首先,使用ANOVA或MANOVA。通过使用因子设计,可以干扰组之间的差异。其次,如果分类变量只有两个级别,则将其作为虚拟变量包含在回归中。国籍通常仅作为控制变量。在这种情况下,与结果变量正相关或负相关的国籍通常无关紧要。只是在那里控制潜在的民族和文化倾向。
运行机器学习算法时,如果类别只有两个级别,只需将数字分配给分类变量即可。这是性别(男/女),购买产品(是/否),参加课程(是/否)的情况。当一个类别具有多个级别时,与国籍一样,为每个级别分配数字意味着级别的顺序。这意味着该类别的一个级别的排名低于另一个级别。虽然这对于有序变量(例如,食品的偏好或教育程度)是有意义的,但对于诸如颜色偏好,国籍,住宅城市等名义变量而言,这是错误的假设。
转型:单热编码和傻瓜
为了处理具有两个以上级别的分类变量,解决方案是一热编码。这需要该类别的每个级别(例如,荷兰语,德语,比利时语和其他级别),并将其转换为具有两个级别(是/否)的变量。在我们的例子中,变量国籍将被转换为四个变量(荷兰语,德语,比利时语和其他),如果参与者具有国籍,则每个变量取值为1,否则取0。
## Creating an example datasetimport pandas as pddf = pd.DataFrame([['German', 'Female', 23, 'marketing'],['Dutch', 'Female, 25, 'economics'],['Belgian', 'Male', 21, 'strategy'],['other', 'Female', 24, strategy']])df.columns = ['nationality', 'gender', 'age', 'major']## wrong way of encoding nominal values. This turns them into ordinal variableX = df[['nationality', 'age']].valuesnationality_le = LabelEncoder()X[:, 0] = nationality_le.fit_transform(X[:, 0])## Correct way of encoding nominal values (option 1)from sklearn.preprocessing import OneHotEncoderohe = OneHotEncoder(categorical_features=[0])ohe.fit_transform(X).toarray()## Correct way of encoding nominal values (option 2)pd.get_dummies(df[['nationality', 'age']])

上面代码的输出:数据集df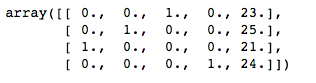
上面代码的输出:数组X.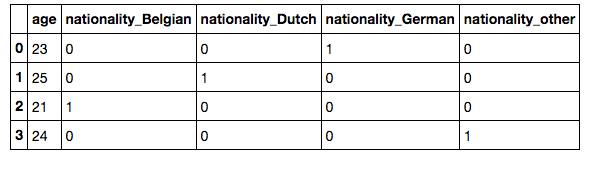
上面代码的输出:使用get_dummies后的数据集pd
直接使用名义变量:Catboost
Catboost由Yandex的研究人员和工程师开发,用于评估任务,预测和提出建议。简而言之,它是决策树上的梯度增强方法。
梯度增强是一种方法,通过该方法将几个不太好的回归或分类模型组合起来以得出预测。这些回归或分类被称为不太好,因为它们很弱。这意味着它们只比先前尝试过的模型略胜一筹。通过组合不同的弱预测,创建了一组模型。这也称为堆叠模型。
更多关于梯度增强的阅读:
- 浅谈机器学习的梯度提升算法:方法和实例介绍
- 从头开始提升梯度:如果你喜欢数学公式,请查看这篇文章
决策树是用于回归和分类任务的方法和算法,其中在每个步骤中,如果某个观察属于先前的观察,则做出决定。决策树以root开头,即应该预测的值。然后它会进一步散发出来,各种变量的值被分配给不同的分支。
关于决策树的更多读数:
现在了解梯度提升是什么以及决策树是什么,我们现在可以更好地了解catboost应该做什么:它是一种结合了不同决策树的预测能力的算法。
Catboost和处理分类功能
在他们的论文中, Anna Veronika Dorogush,Vasily Ershov和Andrey Gulin描述了catboost如何处理分类特征。标准方法是根据类别的标签值计算一些统计数据,例如中位数。但是,如果标签值只有一个示例,则会产生问题。在这种情况下,类别的数值将与标签值相同。例如,如果在我们的国籍示例中,比利时人的类别被赋值为2,并且只有1名比利时学生,则该学生将获得2的国籍。这可能会产生过度拟合的问题。
当模型能够很好地预测训练数据集中的结果变量时会发生> 过度拟合,但是在预测另一个数据集中的结果变量时非常糟糕。在这种情况下,模型已经过度工作以适应训练数据集。
为了避免这个问题,作者设计了一个解决方案,它涉及随机改变整个数据集中行的顺序
我们对数据集执行随机排列,并且对于每个示例,我们计算示例的平均标签值,其中相同的类别值放置在排列中的给定值之前(第2页)
在他们的论文中,他们还描述了如何组合不同的功能来创建新功能。想一想,对分类和数值数据点的每个单独观察都描述了一个观察。两次观察完全相同的可能性很小。因此,可以组合不同的分类值和数值以创建包含所有不同个体选择的唯一合并分类变量。虽然这听起来很容易,但对所有可能类型的组合执行此操作将是计算密集型的。
组合不同功能的另一种方法是在每次树分割时进行贪婪搜索。Catboost通过将当前树中的所有分类和数值与数据集中的所有分类值组合来实现此目的。
贪婪搜索是指您寻找解决方案,但不考虑所有潜在的组合和决策点。相反,你专注于当地的周围。这意味着做出局部最佳选择。这与穷举搜索形成对比,其中考虑了所有潜在的组合。
Catboost提供教程。

若有收获,就点个赞吧
0 人点赞
