了解目标检测框架及其最近的发展

Machine-Vision团队@Fractal Analytics正致力于解决多个目标检测问题。我们已经使用了开源社区中提供的各种框架,并根据我们的用例对其进行了修改,以构建各种问题陈述的应用程序。我们已经构建了算法来处理各种图像数据集,如自然景观图像,交通拥堵图像,卫星图像,零售商店图像,过道图像等。我们还使用了我们的目标检测框架来增强我们的一些视频和图像分类解决方案-我们观察到使用多技术方法给了我们更好的结果。
虽然网上有大量资料,但知道在何处开始使用目标检测仍然非常困难。本博客将记录我们在此过程中学到的大量信息,对于那些希望开始学习目标检测的人来说应该非常有用。
目标检测在机器视觉中仍然是一个相对未解决的问题,预计未来几年会有很多改进。虽然图像分类准确率在ImageNet挑战中触及2.25%的“前5个错误率”,并且整个社区已宣布实现分类的“超过人类”级别准确度,但目标检测算法仍处于开发的早期阶段使用现有技术的目标检测算法,在COCO数据集上仅实现40.8 mAP(100是最大值)。在这些情况下,了解目标检测算法失败的位置并仔细策划特定用例的数据集是一种获得最佳结果的良好方法。
本博客将讨论深度学习研究社区如何发展目标检测问题的解决方案。我们将讨论有助于改善他们时代最新成果的关键研究论文和技术,并将了解他们如何影响研究人员探索新领域。
我们将在目标检测中讨论以下关键算法:
- R-CNN
- SPP
- Fast R-CNN
- Faster R-CNN
- 功能金字塔网络(Feature Pyramid networks)
- RetinaNet(焦点丢失)
- Yolo框架 - Yolo1,Yolo2,Yolo3
- SSD
目标检测技术的演变
传统上,使用简单的模板匹配技术实现目标检测。在这些方法中,用于裁剪的目标目标和使用特定描述符(如HOG和SIFT),用于生成相同的特征。该方法随后在图像上使用滑动窗口并将每个位置与目标特征向量的数据库进行比较。增强算法使用分类器,如训练有素的SVM分类器来代替这些数据库的使用。由于目标的大小不同,人们使用不同的窗口大小和图像大小(图像金字塔)。这些复杂的管道部分解决了目标检测问题,但有许多缺点。管道在计算上耗时,并且使用诸如HOG和SIFT之类的算法的手工设计特征不是非常准确。
随着机器视觉中使用深度学习的出现以及这些算法在2012年出现的图像分类挑战的惊人结果,研究人员开始研究解决目标检测问题的深度学习解决方案。使用深度学习解决目标检测的首要重要算法之一是R-CNN(CNN的区域提议)R-CNN
- 这是第一篇证明CNN可以显着提高目标检测性能的论文。它在VOC 2007数据集上实现了58.5 mAP。
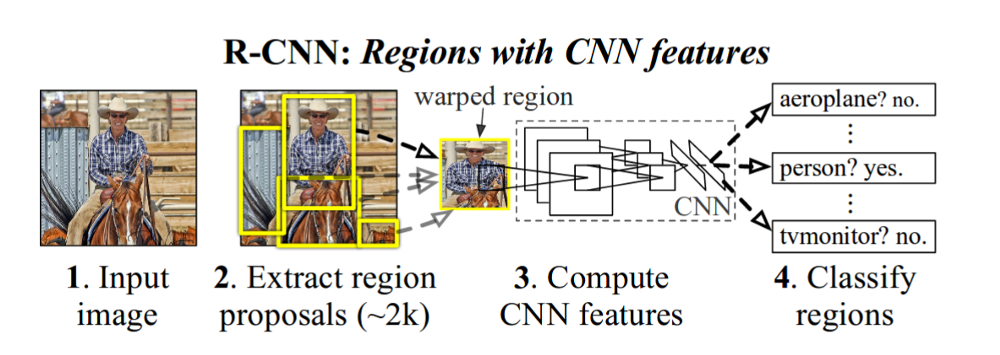
为了构建R-CNN目标检测流水线,可以使用以下方法
- 该方法从像VGG这样的标准网络或在Image-net上预训练的ResNet开始-该网络将像图像的特征提取器一样工作。该方法删除了类特定的分类层,并使用瓶颈层从图像中提取特征。在R-CNN中,该方法使用了VGG网络,我们为每个图像提议获得了4096-dim向量。

- 确保准确提取功能,他们使用这些扭曲的图像训练网络。在训练VOC数据集时,他们在最后放置20+1(n_class +背景)层并训练网络。每个批次大小包含32个正面窗口和96个背景窗口。如果地面真值框的IoU≥0.5,则称地区建议为正。通常从2幅图像(批量大小)中获取这128个(32+96)个提议。由于每张图像将有~2k个建议,我们分别对正图像和负图像(背景)图像进行采样。我们使用选择性搜索来生成这些提议。
- 在对网络进行微调之后,我们将通过网络发送提议并获得4096 dim矢量。本文的作者对IOU进行了网格搜索以选择正样本,0.3的IOU对他们来说效果很好。
- 对于每个目标类,训练SVM(一个与另一个)分类器。您可以使用硬负挖掘来提高分类准确性。
我们还训练了一个边界框回归器,以改善本地化错误。一旦特定于类的SVM分类器对目标进行分类,这将应用于提议。
测试算法
为了测试,R-CNN从输入图像生成大约2000个与类别无关的区域提议,使用CNN(VGG Net)为每个提议提取固定长度的特征向量,然后使用类别特定的线性SVM对每个区域进行分类。这为每个提议提供了类特定的“目标性”得分,然后发送非最大限度抑制算法。
- 测试时间推断在GPU上每个图像需要13秒,在CPU上需要53秒/图像。
这种方法的主要问题是:
- 向神经网络发送约2000个提议,从而使GPU上的测试时间达到13秒。
- 用于训练和推理的复杂管道。没有端到端的训练渠道。神经网络是单独训练的,SVM分类器是单独训练的(这些在SPP网中稍微克服)
SPP-net
R-CNN的主要问题是通过将每个提议分别传递给网络来单独计算〜2000个提议的特征向量。此外,当将图像传递到VGG-net时,我们需要一个固定大小的图像形状(224*224),为了实现我们要么扭曲或裁剪图像,SPP使用空间金字塔池图层去除这个约束。我们将在本节中研究这两件事。空间金字塔汇集层
这不是特定于目标检测,但通常有助于训练任何神经网络。每个CNN都采用固定大小的图像,因为末端FC层需要相同大小的输入。这可以通过以下示例来理解
假设输入大小为224图像大小,conv5(最后一个转换层)具有1313特征映射,而另一个输入大小为180,则conv5层的大小现在为1010。如果应用22的简单池,输出大小将分别为77和55,输入大小分别为224和180。转换这将转换网络将给出49256(256个特征映射)和25256大小的层到底。附加到FC层的权重矩阵无法对此起作用,因为它需要固定的特征向量。所以SPP层进入我们的救援阶段,我们使用l级的金字塔池化层。
假设特征图的大小是 a和金字塔等级n*n。步幅是地板(a/n),窗口大小是ceil(a/n)。对于金字塔等级3,我们有3x3,2x2,1x1的箱子。下图显示了进一步的计算。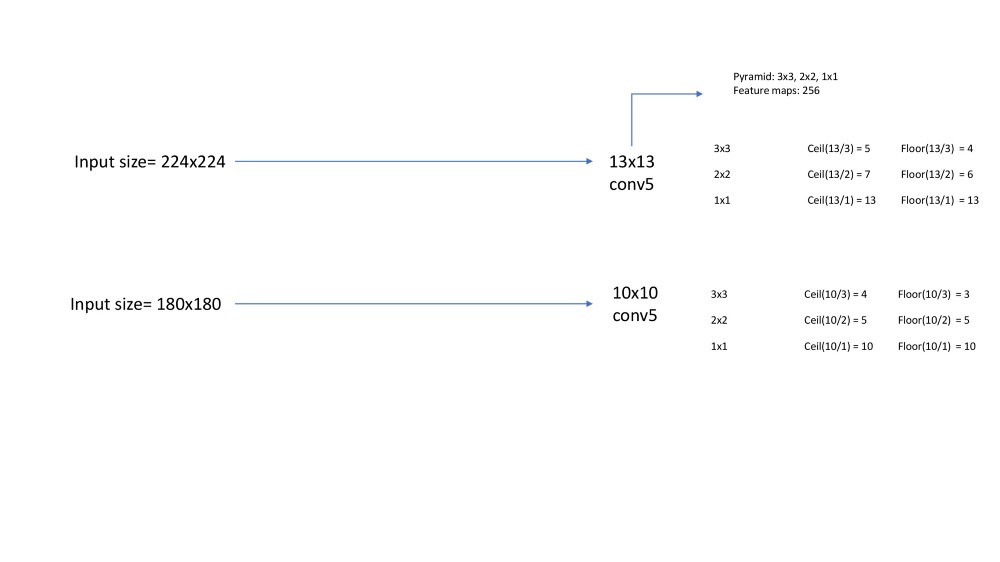
出于计算目的,它们仅在每个时期之后改变了大小。虽然SPP很好,但现在这些都已经过时了,全球平均汇集层也占据了一席之地。SPP-Net用于目标检测
由于特征提取是测试中的主要时间瓶颈,因此在SPP-Net中,作者在整个图像上应用CNN网络并提取特征图(conv5),输入大小为416x416(他们实际上在训练网络时使用了5个等级)conv5处的特征映射大小为26*26(二次采样为16)。
接下来,我们将使用选择性搜索生成约2000个提议。对于每个提议,我们需要从特征图中提取固定长度的特征向量。这通过以下方式应用。
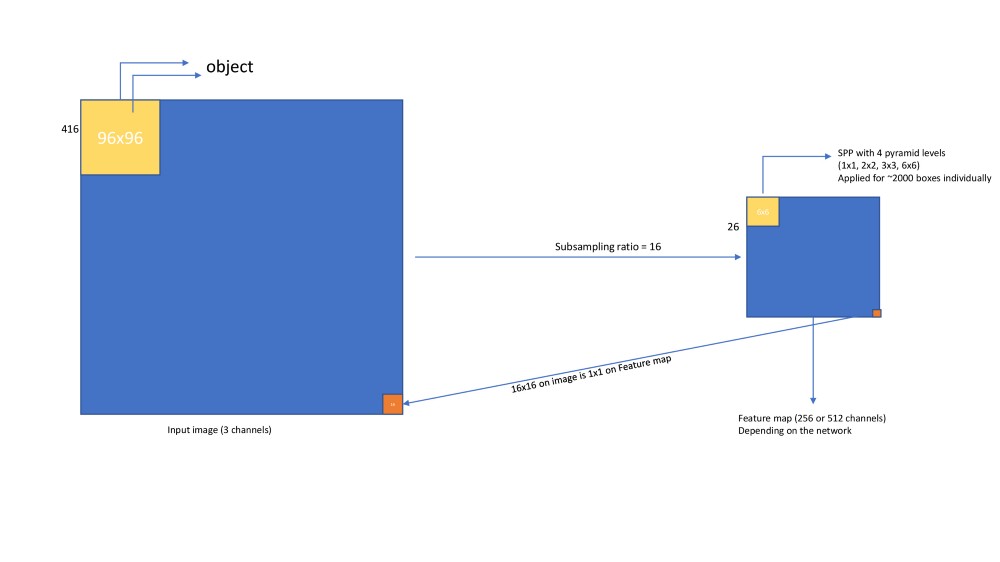
现在,在每个提议获得固定长度的特征向量之后,我们可以使用与R-CNN中相同的技术训练SVM分类器。
结果
- 使用ZF-Net和SPP,他们在VOC数据集上实现了59.2%的mAP。使用多尺度,它实现了63.1%的mAP。
- 单一规模的SPP网络推断需要0.053秒,而R-CNN则为14.37秒。在5级,它需要0.29秒,仍然快49倍。
Fast R-CNN
本文提供了突破性的结果,并为随后的接近标准设定了标准。Fast R-CNN对SPP-Net带来的主要差异是
- 删除了SVM分类器并将回归和分类层添加到网络中。从而使其成为单阶段训练和推理网络
- 删除SPP池化层并将其与ROI池化层连接。
- 使用VGGNet作为后端而不是SPP-Net使用的ZFNet。
- 建立对异常值不太敏感的新损失函数。
Fast R-CNN网络以下列方式工作
- 网络处理整个图像以产生卷积特征图。然后,对于每个目标提议,ROI池化层提取固定长度的特征向量,最终将其传递给后续的FC层。
- FC层分支为两个兄弟输出层,一个估计在K+1个目标类上的softmax概率,另一个层生成精细的边界框位置。
- 特定图像的2000个提议不像R-CNN那样通过网络传递,相反,图像只传递一次,计算的特征在~2000个提议中共享,就像在SPP Net中一样。
- 此外,ROI池化层在大小为h/HX w/W的每个子窗口中进行最大池化。H和W是超参数。这是具有一个金字塔等级的SPP层的特例。
- 两个兄弟输出层的输出用于计算每个标记的ROI上的多任务损失,以共同训练分类和边界框回归。
- 他们使用L1损失进行边界框回归,而不是R-CNN中的L2损失和对异常值更敏感的SPP-Net。
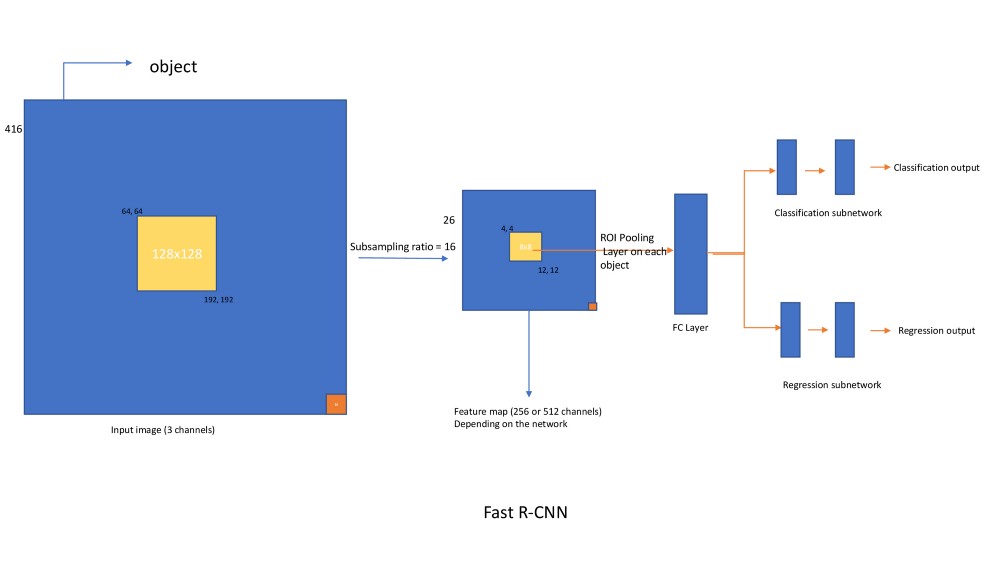
RoI Pooling
Aka感兴趣区域汇集,重要的是要理解它在Faster R-CNN和掩码R-CNN中使用。
问题:由于目标具有不同的大小,因此需要将池化层应用于不同大小的特征图。
假设在上图中,图像上的目标位置[64,64,192,192]在特征图上是[4,4,12,12]。图像上的目标位置[128,128,384,400]在特征图上为[8,8,24,25]。现在,两个汇集层都应该应用于[4,4,12,12]和[4,4,16,18]并提取固定长度的特征向量。
这里是RoI汇集层来拯救你的地方。下面是它如何工作的图表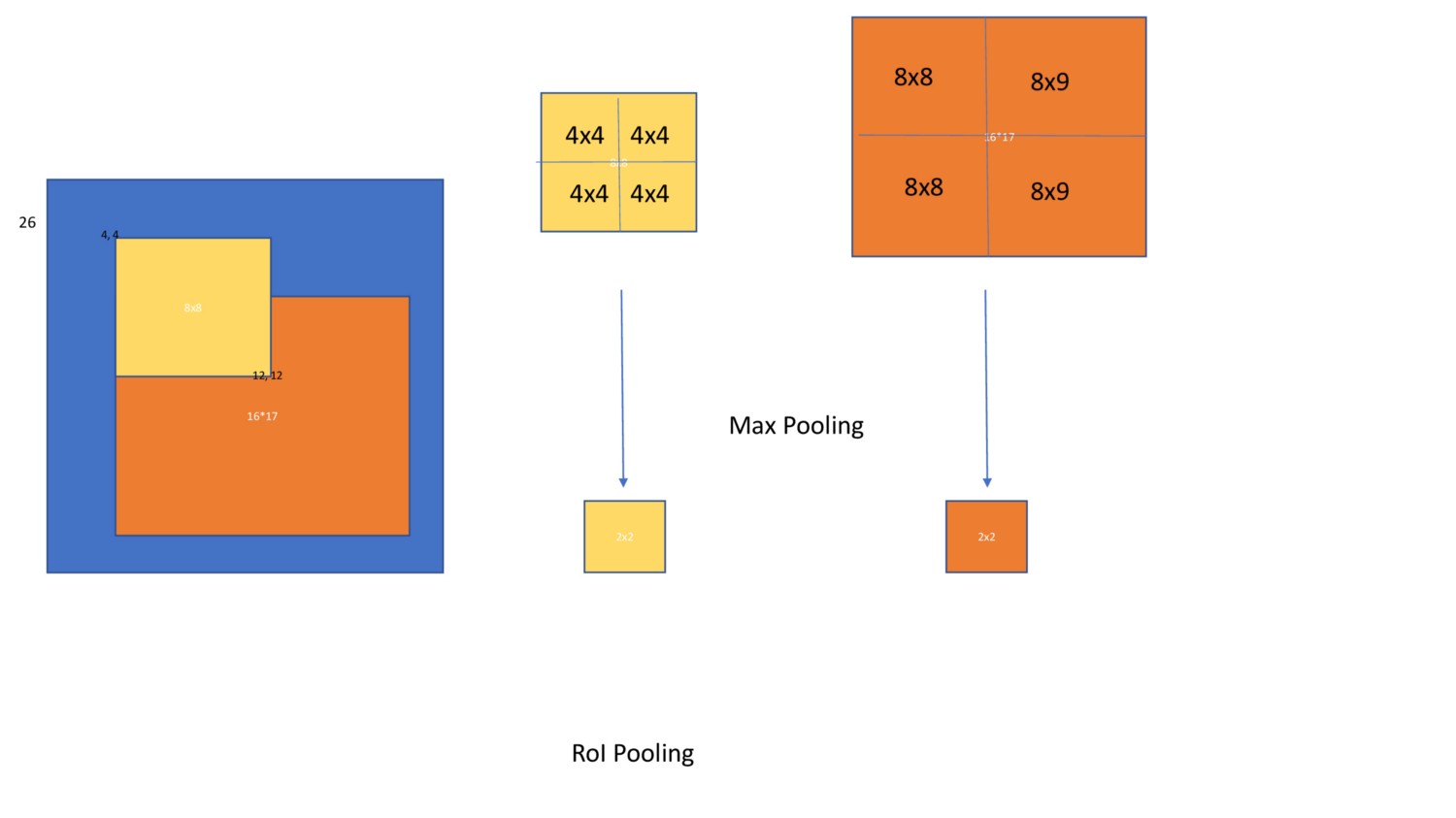
损失函数
如上所述,Fast R-CNN网络具有两个兄弟网络,分类层输出离散概率分数,而回归层输出目标的x,y,w,h值的偏移。对于分类,我们可以使用交叉熵损失。对于回归,使用平滑的L1损失。
训练
虽然训练Fast R-CNN使用2的批量大小。由于批量大小为2,我们有~2000 x 2 = 4000个箱体,并且大多数不包含目标,在训练此网络时将存在极端的类不平衡。为此,我们从~4000个箱体中随机抽取64+ve箱体和64-ve个箱体,并仅为这些箱体计算损失。如果我们有更少的+ ve箱体,我们将填充负箱体。总的来说,每次迭代我们将有128个箱体。同样的方法也用于Faster R-CNN。
编码器
如果提议在任何边界框中具有 ,则称其为前景,我们将相应地为提议分配类。有[0.1,0.5]的提议被称为否定的。保留所有将被忽略的提议
,则称其为前景,我们将相应地为提议分配类。有[0.1,0.5]的提议被称为否定的。保留所有将被忽略的提议
结果
- 训练比R-CNN快9倍。推断Fast R-CNN比R-CNN快213倍。同样地使用VGG16,与SPP Net相比,Fast R-CNN在训练时快3倍,而推理时快10倍。
VOC-2007-12数据集的mAP达到71.8%。在COCO Pascal风格的mAP是35.9。新的COCO Pascal-style 的mAP(平均超过IoU阈值)在coco数据集上为19.7%
Faster R-CNN
这种方法仍然是大多数研究人员的最佳选择,并取得了令人难以置信的成果。该算法在精度和速度方面都超过了以前的所有结果。Faster R-CNN也提出了新技术,这些技术已成为所有即将推出的框架的黄金标准。让我们深入研究这些方法。
对Fast R-CNN的更改
删除了选择性搜索并添加了深度神经网络以生成提议(RPN网络)
- 引入锚箱
这是Fast R-CNN带来的两大变化。对于所有框架,锚框在这里变得非常普遍。RPN网络可以作为单个目标检测器工作,也可以为Fast R-CNN网络生成建议。有一件事是肯定的,我们完全取消了传统的计算机视觉技术,并建立了一个完整的深度神经网络,并进行了端到端的训练。
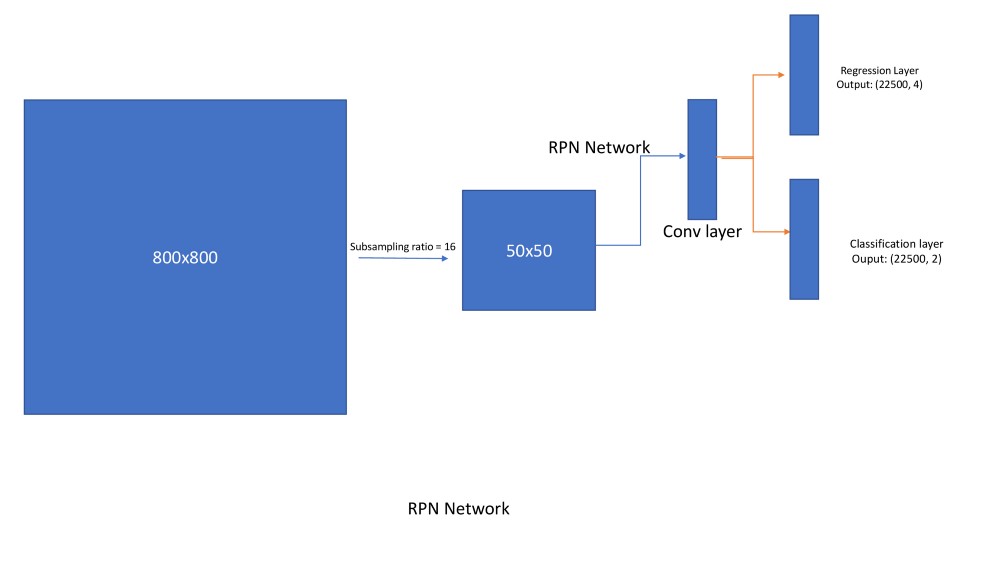
RPN如何运作?
- 获取800x800的输入图像并将其发送到网络。对于VGG网络,在二次采样率为16之后,输出将为[512,50,50]。在此特征图上应用RPN网络,生成(50509)框回归和分类分数。因此回归输出为505094(x,y,w,h),分类输出为505092(目标是否存在)。这里9表示每个位置的锚箱数量。下面是关于如何在图像上生成锚框的过程。(注意:稍作修改,这就是锚框在所有框架上的应用方式)
锚箱
在每个位置,我们有9个锚箱,它们具有不同的比例和纵横比。以下是定义的
anchors_boxes_per_location = 9scale = [ 8,16,32 ]ratios = [0.5,1,2]ctr_x,ctr_y = 16/2,16/2 [at(1,1)location)
在特征映射位置1,1映射到图像上的[0,0,16,16]框。这个中心位于8,8。现在我们需要使用上述尺度和比例绘制9个锚箱。看看图像上的所有中心
anchor_base = np.zeros((len(ratios) * len(scales), 4), dtype=np.float32)print(anchor_base)#Out:# array([[0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.]], dtype=float32)for i in range(len(ratios)):for j in range(len(anchor_scales)):h = sub_sample * anchor_scales[j] * np.sqrt(ratios[i])w = sub_sample * anchor_scales[j] * np.sqrt(1./ ratios[i])index = i * len(anchor_scales) + janchor_base[index, 0] = ctr_y - h / 2.anchor_base[index, 1] = ctr_x - w / 2.anchor_base[index, 2] = ctr_y + h / 2.anchor_base[index, 3] = ctr_x + w / 2.#Out:# array([[ -37.254833, -82.50967 , 53.254833, 98.50967 ],# [ -82.50967 , -173.01933 , 98.50967 , 189.01933 ],# [-173.01933 , -354.03867 , 189.01933 , 370.03867 ],# [ -56. , -56. , 72. , 72. ],# [-120. , -120. , 136. , 136. ],# [-248. , -248. , 264. , 264. ],# [ -82.50967 , -37.254833, 98.50967 , 53.254833],# [-173.01933 , -82.50967 , 189.01933 , 98.50967 ],# [-354.03867 , -173.01933 , 370.03867 , 189.01933 ]],# dtype=float32)
这是针对一个位置,现在我们需要申请所有锚点中心。因为有50*50锚定中心,每个锚定中心有9个锚点。我们总共得到22500个锚。
fe_size = 50anchors = np.zeros((fe_size * fe_size * 9), 4)index = 0for c in ctr:ctr_y, ctr_x = cfor i in range(len(ratios)):for j in range(len(anchor_scales)):h = sub_sample * anchor_scales[j] * np.sqrt(ratios[i])w = sub_sample * anchor_scales[j] * np.sqrt(1./ ratios[i])anchors[index, 0] = ctr_y - h / 2.anchors[index, 1] = ctr_x - w / 2.anchors[index, 2] = ctr_y + h / 2.anchors[index, 3] = ctr_x + w / 2.index += 1print(anchors.shape)#Out: [22500, 4]
看一下图像上的(400,400)锚点
- 因此,RPN为每个锚箱生成目标建议以及它们的目标性得分。如果一个锚箱具有max_iou与地面实况目标或者大于0.7,则为其分配+ ve。如果锚点
 ,则为锚点框指定负数。所有具有iou [0.4,0.7]的锚框都被忽略。落在图像之外的锚箱也被忽略。
,则为锚点框指定负数。所有具有iou [0.4,0.7]的锚框都被忽略。落在图像之外的锚箱也被忽略。 - 同样,由于它们中的绝大多数将具有负样本,我们将使用相同的Fast R-CNN策略来采样128+ve样本和128-ve样本(总共256个),批量大小为2用于训练。
- 平滑L1损失和交叉熵损失可用于回归和分类。使用以下公式使用锚箱位置偏移回归输出
t_{x} = (x - x_{a})/w_{a}t_{y} = (y - y_{a})/h_{a}t_{w} = log(w/ w_a)t_{h} = log(h/ h_a)
x,y,w,h是地面实况框中心坐标,宽度和高度。x_a,y_a,h_a和w_a以及锚箱中心cooridinates,宽度和高度。
- 一旦生成了RPN输出,我们需要在发送到RoI池化层(也称为Fast R-CNN网络)之前处理它们。Faster R_CNN说,RPN提议彼此高度重叠。为了减少冗余,我们根据其cls分数对提议区域采用非最大抑制(NMS)。我们将NMS的IoU阈值修正为0.7,这使得每个图像大约有2000个提议区域。在消融研究之后,作者表明NMS不会损害最终的检测准确性,但会大大减少提议的数量。在NMS之后,我们使用排名前N的提议区域进行检测。在下文中,我们使用2000个RPN提议训练Fast R-CNN。在测试过程中,他们仅评估了300个提议,他们已经使用不同的数字对此进行了测试。
nms_thresh = 0.7n_train_pre_nms = 12000n_train_post_nms = 2000n_test_pre_nms = 6000n_test_post_nms = 300min_size = 16
- 生成~2000提议后,使用以下公式对其进行转换
x = (w_{a} * ctr_x_{p}) + ctr_x_{a}y = (h_{a} * ctr_x_{p}) + ctr_x_{a}h = np.exp(h_{p}) * h_{a}w = np.exp(w_{p}) * w_{a}and later convert to y1, x1, y2, x2 format
现在这2000个提议类似于Fast R-CNN中选择性搜索产生的提议。因此,该过程的其余部分类似于Fast R-CNN。
Fast RCNN在Faster RCNN工作流程中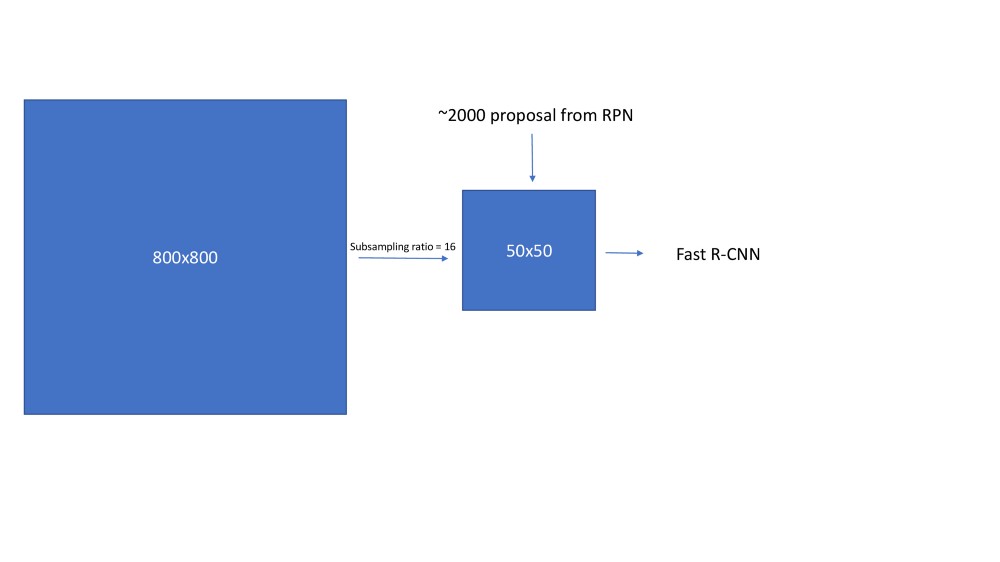
结果
在GPU上以5 FPS进行推理
- 使用VGG后端,在ImageNet和COCO上进行预训练,在VOC上Faster RCNN达到了73.2%的mAP。
- 在COCO数据集上,Faster R-CNN达到了21.9 mAP(coco类型)。
金字塔特征网络
在这一行中,研究人员观察到Faster R-CNN存在两个问题。首先它无法检测到小物体,第二类不平衡没有正确聚焦(随机采样256个样本和计算损失不是正确的方法)。因此研究引入了两个新概念
金字塔特征网络(Feature Pyramid networks)
如果你看一下Faster RCNN,它几乎无法捕捉到图像中的小物体。COCO和ILSVRC主要通过大多数获胜团队使用图像金字塔来解决这个问题。下面给出了一个简单的图像金字塔,您可以将图像缩放到不同的大小并将其发送到网络。一旦在每个比例上检测到目标,所有预测都将使用不同的方法进行组合。虽然这种方法有效,但推理是一个代价高昂的过程,因为每个图像应该独立地以各种比例计算。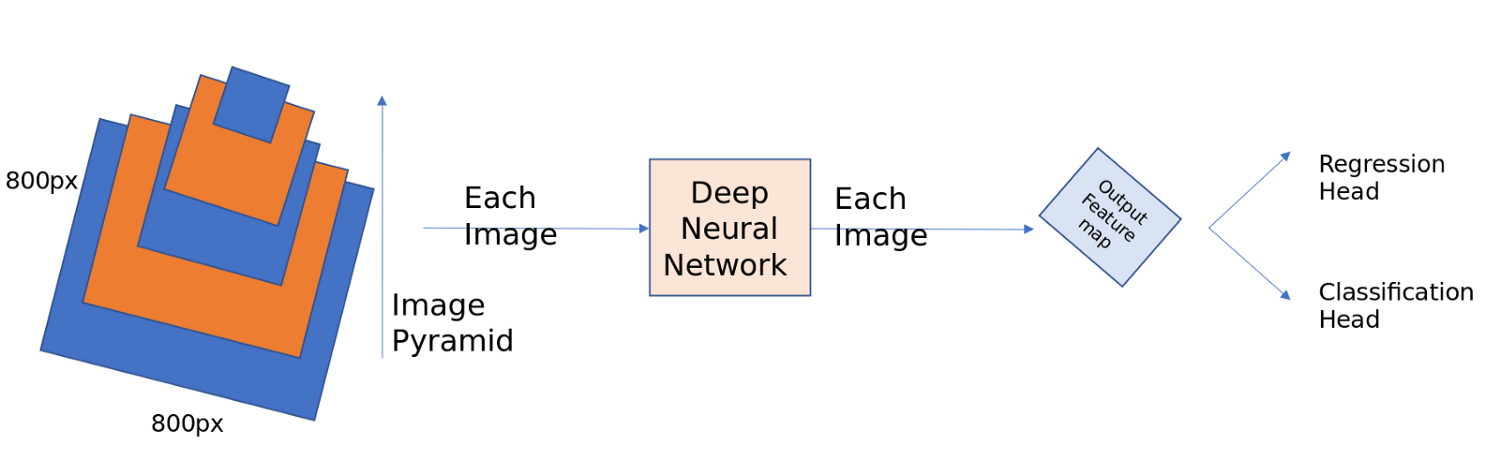
深层ConvNet逐层计算特征层次结构,对于子采样层,特征层次结构具有固有的多尺度金字塔形状。此网内特征层次结构生成不同空间分辨率的特征映射。首先让我们看看FPN是如何工作的,之后我们将进入直觉部分。
- 首先采用标准的resnet架构(Ex ResNet50)。在上面讨论的Faster R-CNN中,我们考虑仅采用子采样率16的特征图来计算区域提议,然后将RPN输出传递给Fast RCNN。这是通过以下方式完成的,
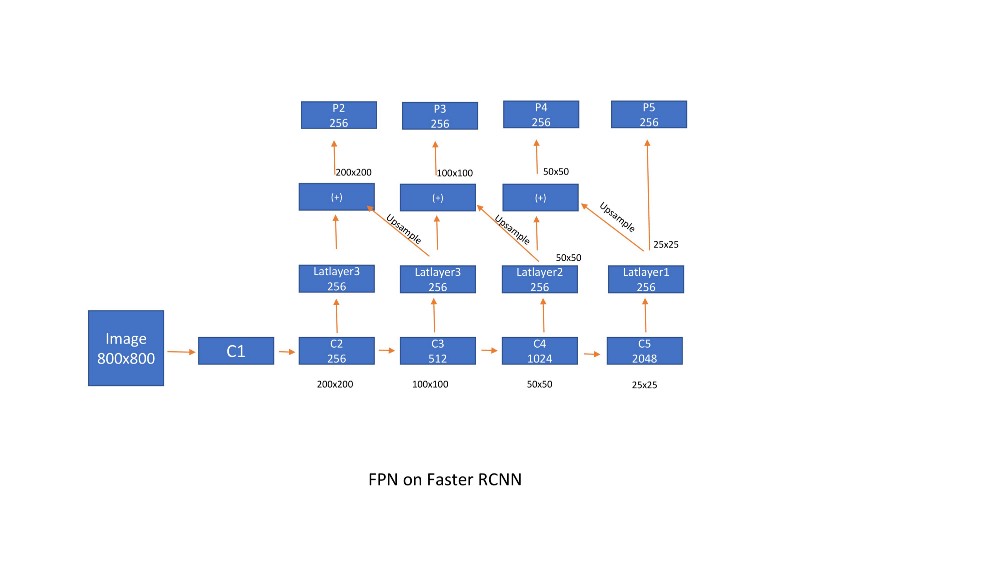
- 过度子采样的问题是它会导致本地化不良。如果我们想要使用早期图层中的特征(比如子样本8),则不能非常清楚地捕获目标的语义。所以,我们必须充分利用这两个世界。凭借这种直觉功能,金字塔网络或FPN首先在Faster RCNN上设计。Latlayers减小了通道尺寸(特征图的数量),上采样并添加到前一层输出。由于使用双线性插值完成上采样,因此它们在此输出中添加了另一个转换层,以便消除上采样的混叠效应。由于计算复杂性,我们忽略了p1(它生成(单个特征映射p1的4004003 = 480k建议)。
锚箱分别设计在每个特征图上。由于规模由FPN处理,因此在每个位置我们采用3纵横比[1:2,2:1,1:1]的锚点。总的来说,我们在特征地图比例上的每个位置获得9个锚点。
用于RPN的FPN
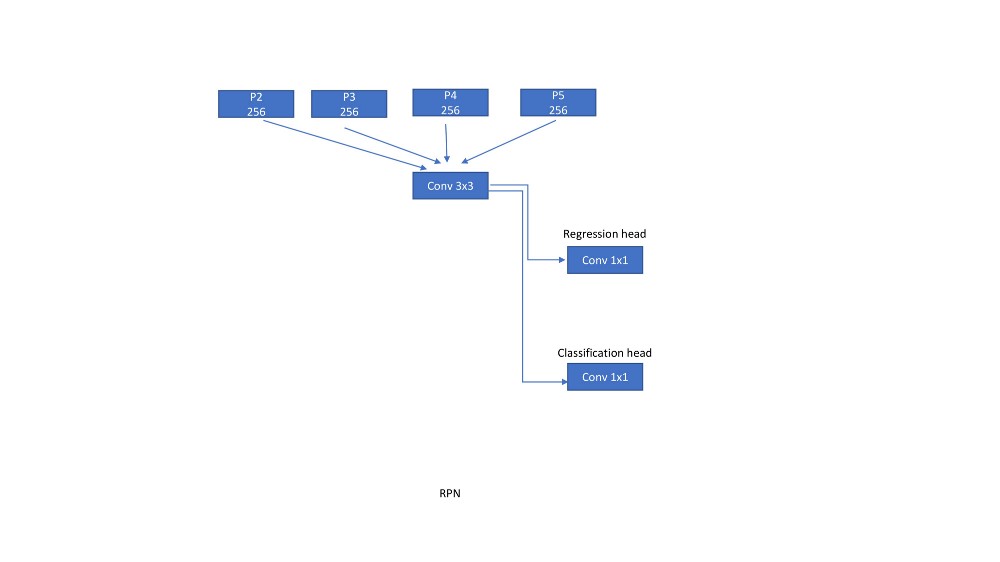
在Faster RCNN中,3x3转换层在特征映射上滑动并提取进一步由两个兄弟网络评估的特征,一个用于回归(1x1转换),另一个用于分类(1x1转换)。现在,在实施FPN时,我们构建了相同的网络,但是在这里我们在每个功能映射上移动网络。
FPN用于Fast R-CNN
与RPN类似,RoI池化图层附加到每个特征图比例。子网络分别为每个比例预测边界框和类。该子网络与RPN中的相同级别共享参数。
结果:
一些消融研究表明,使用FPN,平均精度(AR ^(1k)比单一尺度RPN提高了8.0分。它还将大幅度的表现提升了12.9点。
- 横向连接将AP提高了10个点。
- COCO AP为33.9,VOC AP @ 5为56.9。在小物体上,可可风格AP从9.6%提高到17.8%。
- 使用ResNet-101作为后端,VOC AP为59.1%,coco样式mAP为36.2%。
使用resnet101作为后端时,对每个图像的推断需要176 ms。
RetinaNet(焦点丢失和FPN组合)
我们在目标检测中看到的所有技术都是两阶段,RPN生成目标提议,然后Fast RCNN在这些预测目标提议之上进行分类和回归。一个相关的问题是我们可以建立单级探测器吗?
其次,当在Fast RCNN(FPN)网络中评估1⁰⁴到1⁰⁵锚箱时,大多数箱子不包含物体,导致极端的不平衡。为了对抗类不平衡,我们从每个小批量(128+ve和128-ve)中抽取256个提议。然而,这不是一种机器人方法,本文的作者提出了一种称为Focal loss的损失函数,它试图有效地解决类失衡问题。单级检测器(FPN)
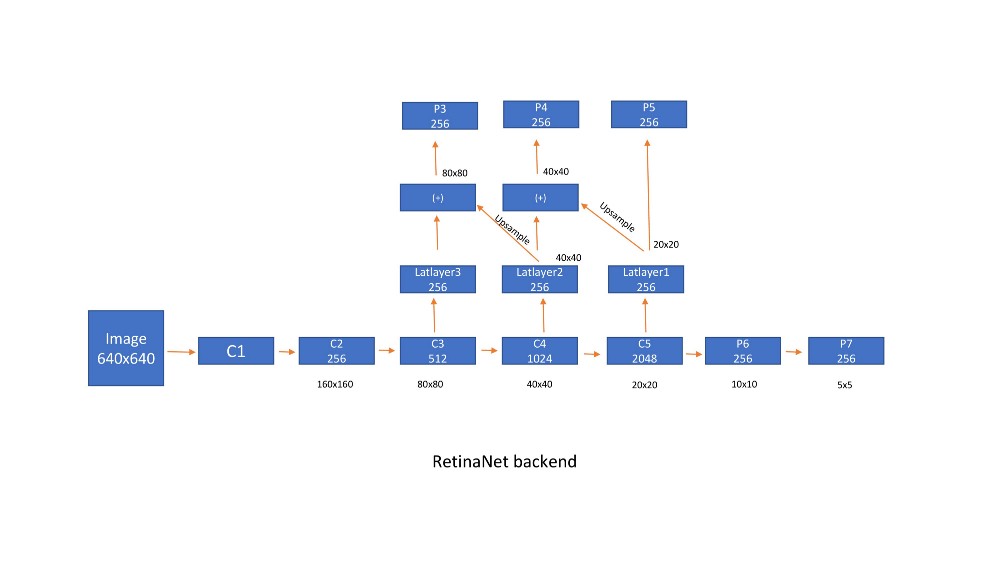
如下图P3所示,P4,P5,P6,P7是后端网络的输出。由于计算原因,我们没有使用P1和P2。
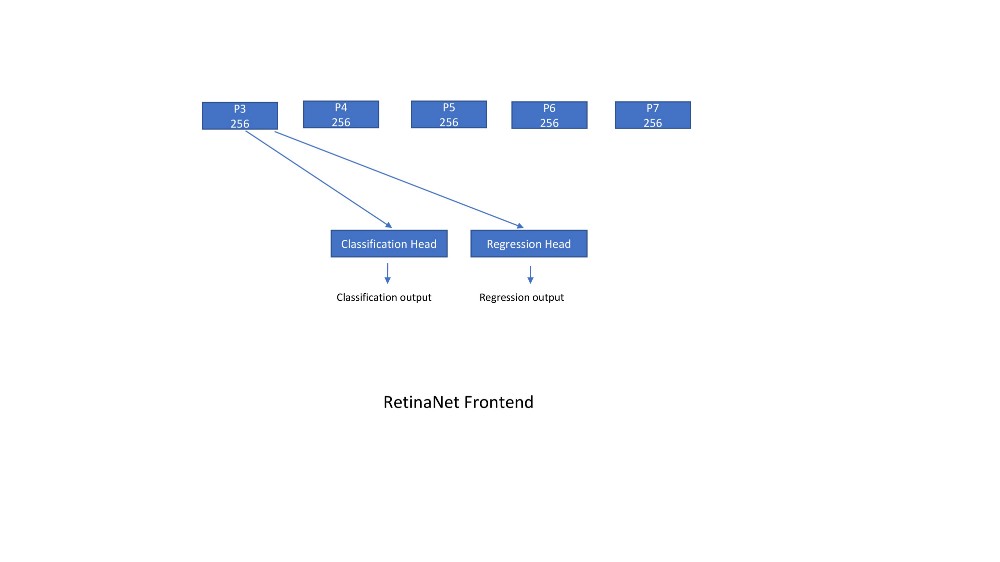
- 然后将每个输出传递到回归层和分类层,它们是一堆转换层(4)以及输出层。所有转换层都有256个输入通道和256个输出通道,并应用3x3滑动窗口。Relu介于所有层之间。回归层输出有一个线性层,分类层最后有一个sigmoid(类数作为输出)或softmax(num classes +1)激活函数
设计方式与FPN部分中的说法相同,但有一些修改。[p3,p4,p5,p6,p7]的步幅分别为[8,16,32,64,128]。虽然FPN负责比例尺,但是本文报告了在每个特征图上使用不同比例的锚框的更好结果。因此,我们在特征图的每个位置都有9个锚点,在所有比例上共有45个锚点。他们使用尺寸为[²2,2 ^(1/3),2 ^(2/3)]和纵横比为[0.5,1,2]的锚箱。sudo代码如下
aspect_ratios = [0.5,1,2]kmin,kmax =3,7 #feature scales scales_per_fe = 3anchor_scale = 4num_aspect_ratios = len(aspect_ratios)num = 0for lvl in range(k_min,k_max + 1):stride = 2. ** lvlfor fe in range(scales_per_fe):fe_scale = 2 **(fe / float(scales_per_fe))for idx in range(num_aspect_ratios):anchor_sizes = (stride * fe_scale * anchor_scale,)anchor_aspect_ratios =(aspect_ratios [idx],)num + 1 = 1print(anchor_sizes,anchor_aspect_ratios)#out1(32.0,)(0.5,)2(32.0,)(1,)3(32.0,)(2,)4(40.317,)(0.5,)5(40.317,)(1,)6(40.317,) (2,)---43(812.75,)(0.5,)44(812.75,)(1,)45(812.75,)(2,)
- 编码类似于Faster RCNN,如果锚箱的iou> 0.5,基本事实是+ ve,<0.4它是-ve,其余都被忽略。每个锚被分配给Atmost一个锚。
对于640x640的输入尺寸,我们获得8525(8080)+(4040)+(2020)+(1010)+(5*5)位置。由于每个位置有9个锚,我们总共得到76725(8525x9)个锚。
损失函数
回归使用平滑的L1损失,这对异常值不太敏感。这与迄今为止在所有框架中使用的损失相同。
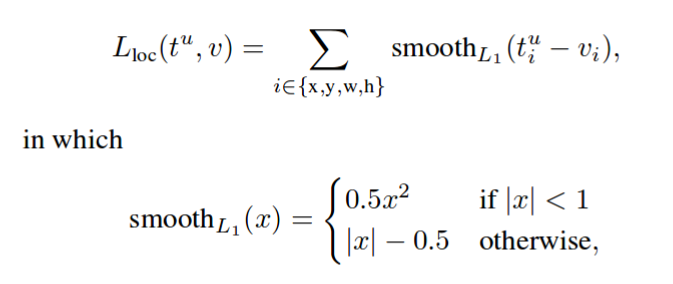
分类损失称为局部损失,这是交叉熵损失的重新形成版本,本文对此进行了大量讨论。焦点损失是交叉熵损失的重塑,因此它会降低分配给分类良好的例子的损失。新颖的焦点损失集中在一组稀疏的例子上进行训练,并防止大量的轻微负面因素在训练期间压倒探测器。
让我们看一下这种焦点损失是如何设计的。我们将首先研究单个目标分类的二元交叉熵损失
交叉熵损失: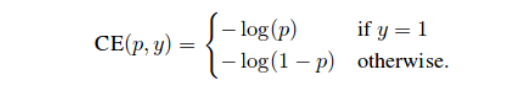
**焦点损失: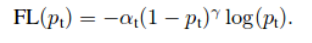
- 其中,如果y = 1则p_ {t}为p,否则为1-p。让我们清楚地看一下焦点损失方程。这里alpha称为平衡参数,gamma称为聚焦参数。
- 平衡参数通常是特定类的实例数的倒数。它给具有更多样本数量的类减轻了重量。这里是负面的建议。
聚焦参数为分类良好的示例增加了较少的权重,并且增加了权重较大/错过的分类示例。让我们看看如何使用4种方案实现这一目标。我已经在我的其他博客中解释了这一点,并且为了完整起见
场景-1:简单正确分类的例子
假设我们有一个容易分类的前景目标,p = 0.9。现在通常这个例子的交叉熵损失是
CE(前景)=-log(0.9)= 0.1053
现在,考虑容易分类的背景目标,p = 0.1。现在,这个例子的通常的交叉熵损失也是一样的
CE(背景)= -log(1-0.1)= 0.1053
现在,考虑上述两种情况的焦点损失。我们将使用alpha = 0.25和gamma = 2
FL(前景)= -1×0.25×(1-0.9) 2log(0.9)= 0.00026
FL(背景)= -1×0.25×(1-(1-0.1) 2log(1-0.1)= 0.00026。场景-2:错误分类的例子
假设我们有一个错误分类的前景目标,p = 0.1。现在通常这个例子的交叉熵损失是
CE(前景)=-log(0.1)= 2.3025
现在,考虑错误分类的背景目标,p = 0.9。现在,这个例子的通常的交叉熵损失也是一样的
CE(背景)= -log(1-0.9)= 2.3025
现在,考虑上述两种情况的焦点损失。我们将使用alpha = 0.25和gamma = 2
FL(前景)= -1×0.25×(1-0.1) 2log(0.1)= 0.4667
FL(背景)= -1×0.25×(1-(1-0.9) 2log(1-0.9)= 0.4667场景-3:非常容易分类的例子
假设我们有一个容易分类的前景目标,p = 0.99。现在通常这个例子的交叉熵损失是
CE(前景)=-log(0.99)= 0.01
现在,考虑容易分类的背景目标,p = 0.01。现在,这个例子的通常的交叉熵损失也是一样的
CE(背景)= -log(1-0.01)= 0.1053
现在,考虑上述两种情况的焦点损失。我们将使用alpha = 0.25和gamma = 2
FL(前景)= -1 x 0.25 x(1-0.99) 2 log(0.99)= 2.5*10 ^(-7)
FL(背景)= -1 x 0.25 x(1-(1-0.01) 2 log(1-0.01)= 2.5*10 ^(-7)结论:
场景-1:0.1/0.00026 = 384倍的数字
场景-2:2.3/0.4667 =数量减少5倍
scenario-3:0.01/0.00000025 = 40,000倍的数字。
这三种情景清楚地表明,焦点损失对于分类良好的例子增加了非常少的权重,而对于错误分类或硬分类的例子来说增加了很大的权重关于RetinaNet的推论
这是设计焦点损失背后的基本直觉。作者测试了不同的α和γ值,最终用上述值确定。
在将检测器置信度阈值设置为0.05后,获得来自每个特征量表的1000个提议。合并所有级别的最高预测,并应用阈值为0.5的非最大抑制以产生最终检测。
注意:使用随机权重初始化网络时请小心。作者建议使用(-1)x math.log(1-0.01)/0.01)作为最后一层偏差。如果没有完成,我们在第一次迭代中得到巨大的损失值,并且梯度溢出,最终导致NaN。
结果
- 在COCO数据集上,Retinanet实现了40.8的coco样式mAP和61.1 mAP的VOC样式mAP。小物体上的可可样式AP为24.1,中等目标为44.2,大目标为51.2。
使用600x600输入尺寸和resnet101作为后端,每张图像的推断需要122ms。
Yolo(你只看一次)
YOLO是一个重要的框架,可以提高目标检测任务的速度和准确性。Yolo已经发展了一段时间,迄今已发表了3篇论文。虽然大多数想法与我们上面讨论过的想法类似,但YOLO提供了尖锐的增强功能,尤其可以解决Faster 处理时间问题。
Yolo有三篇论文,Yolo1,yolo2,Yolo3在准确性方面有所改进。
Yolo1是独立出版的,据我所知是第一篇论述单阶段检测的论文。RetinaNet从Yolo和SSD获取创意。
网格单元格
首先,我们将图像划分为细胞网格。说它是7x7。现在,在它们各自的网格单元中具有其目标中心的地面真实目标原来是+ ve单元。
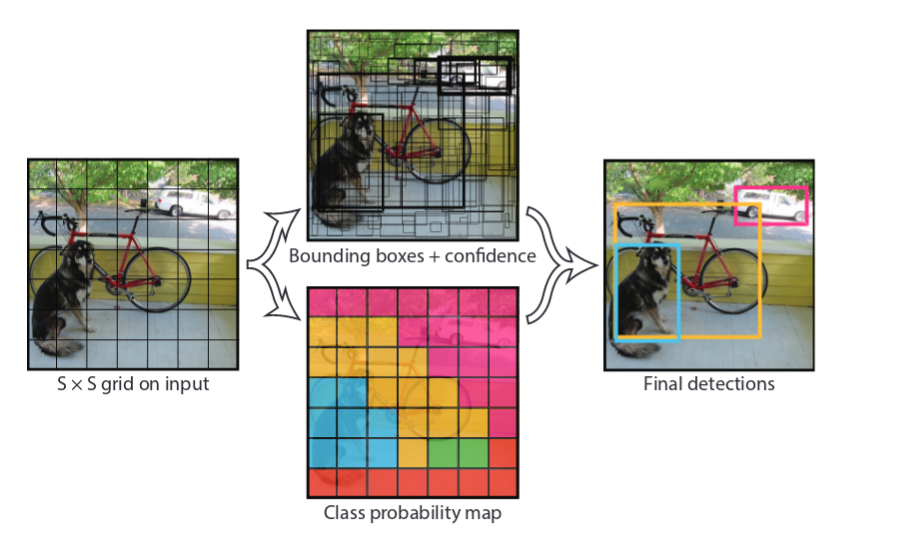
- 每个单元格预测2个边界框,每个边界框由5个预测组成:x,y,w,h和置信度。(x,y)坐标表示相对于网格单元边界的框的中心。相对于整个图像预测宽度和高度。最后,置信度预测表示预测框与任何地面实况框之间的IOU。因此对于具有20个等级的VOC,输出将是(4+1)x2+20)= 30.如果网格尺寸是7x7,我们将具有7x7x30输出。
def normal_to_yolo_format(bbox, anchor, img_size, grid_size):y, x, h, w = bbox #bounding boxy1, x1, y2, x2 = anchor # supporting cellsize_h = img_size[0]/ grid_size[0] # height of the cellsize_w = img_size[1]/grid_size[1] # width of the cellnew_x = (x - x1)/size_w # center_x wrt to cellnew_y = (y - y1)/size_h #center_y wrt to cellnew_h = h/img_size[0] # height of the object normalized with the heigth of the imagenew_w = w/img_size[1] # width of the object normalized with the width of the imagereturn [new_y, new_x, new_h, new_w]
编码边界框
For each cell,For each ground_truth_bbox:check if the cell contains bbox center or not,if yes:encode the box with respective values of bbox, label and binary encoding of object present or not[1 in this case].
编码问题:
如果网格单元包含两个目标中心会发生什么?您可以随机选择一个目标或将网格大小增加到更大的数字,如16x16。这在Yolov2中得到了很大的解决,我们将看看der。
网络
Yolo使用了一个名为DarkNet的不同网络,该网络由作者自己酿造,不像其他框架采用标准的良好执行的ImageNet架构。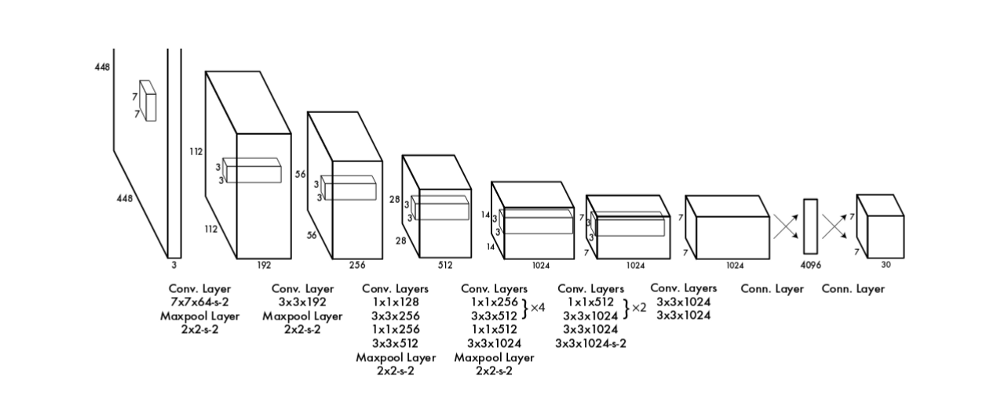
损失函数。
Yolo包含三个损失函数。
- 协调错误
- 目标得分
- 分类错误。
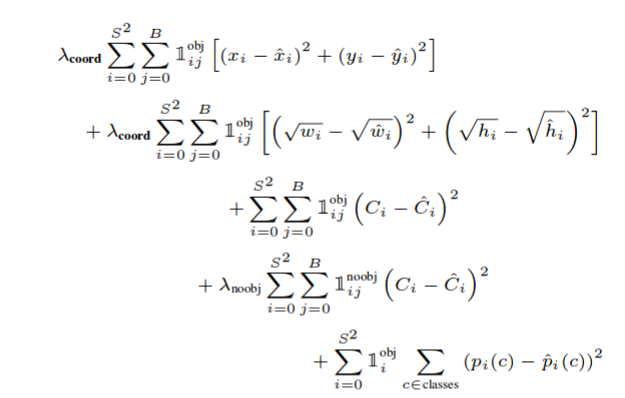
仅当目标性分数> 0.5时才评估坐标误差和分类误差,其用1 ^ obj表示。针对每个网格单元单独计算损耗,并且稍后将所有内容相加。w和h有平方根来解决以下问题
- 预测错误的小物体应该比预测错误的大物体更重。
\ lambda_coord和\ lambda_noobj分别为5和0.5。
根据我的经验,为我自己的数据集正确地获得这种损失函数成了一场噩梦。可能是这些损失函数被调整为适用于此数据集,并且可能适用于具有类似分布的数据集。当您使用其他数据集时,它可能会严重失败。我将在从头开始构建目标检测管道时,就我遇到的问题再做一篇博文。
训练
- DarkNet首先在Imagenet上进行预训练以进行分类。前5名的准确率为88%。由于检测需要细粒度信息,因此他们使用了448x448图像而不是224x224图像。他们发现初始时期的误差很高,并认为可能是因为图像尺寸的变化。所以他们在前几个时期使用448x448再次训练了imagenet上的网络,然后转移到了voc数据集。
- 该网络后来接受了关于VOC-2007和2012年数据集的135个时期的训练。在整个训练过程中,他们使用了64的batch_size,0.9的动量和0.0005的衰减。学习速率表如下:对于第一个时期,他们将学习速率从10 ^ -3缓慢提高到10 ^ -2。继续训练10 ^ -2为75个时期,然后10 ^ -3为30个时期,最后为10 ^ -4为30个时期。
- 为避免过度拟合,他们使用了丢失和大量数据扩充。在我们的例子中,我们也使用了批量标准化。
对于数据增强,他们使用了最多20%的原始图像大小的随机缩放和翻译。它们还在HSV颜色空间中随机调整图像的曝光和饱和度达1.5倍。
结果
Yolo非常快。它的工作速度为每秒45帧
- 使用DarkNet的YOLO以每秒45帧的速度实现63.4的mAP。与使用VGG-16(73.2)的Faster R-CNN相比,mAP要少得多,但是Faster R-CNN的速度是每秒7帧。Fast R-CNN框架在0.5 FPS(每秒帧数)时实现71.8%的mAP。
- Yolo对边界框预测施加了强大的空间约束,因为每个网格单元只预测两个框,并且只能有一个类。此空间约束限制了我们的模型可以预测的附近目标的数量。例如,Yolo很难预测一群动物(鸟类)。
- 由于模型预测数据的边界框,因此很难在新的或不寻常的宽高比和配置中推广到目标。
Yolo更擅长减少定位错误,因为它会查看整个图像以预测单个单元格上的目标。因此,Yolo捕获并考虑整个图像的全局特征以预测单个细胞,而Faster R-CNN则不是这种情况。对错误的调查发现,与Yolo相比,Fast R-CNN几乎造成3倍的背景错误。因此,对于Fast R-CNN预测的每个边界框,它再次由Yolo评估。这使Fast R-CNN的mAP提高了3.2%至75%。
Yolov2
我们将重点介绍他们在本文中向Yolo购买的修改
在67 FPS,YOLOv2在VOC 2007上获得76.8 mAP。在40 FPS时,YOLOv2获得78.6 mAP,优于最先进的方法,如使用ResNet和SSD的Fast R-CNN,同时仍然运行得更快。
- Yolo在每个网格单元使用锚箱。这将允许我们在相同的网格单元格中编码多个框。
- 使用数据集设置锚箱边界框的比例和宽高比。(我将在此单独写一篇文章,因为它也可以在所有其他框架中使用)。设置更好的先验并理解数据集是最重要的,并且首先在Yolov2论文中首先解决。
- 网格尺寸从7x7增加到13x13。这也应该来自数据集。如果您有极小的物体,我们可以根据需要将其增加到32x32或50x50。在考虑网格大小时我们需要进行的先验检查之一是,没有锚箱应该不止一个地面实况框。
- 对于网络,引入了批量标准化。与Network In Network类似,他们使用全球平均汇总和1x1卷积。
- x,y,w,h的编码以下列方式改变。这与Yolov3中使用的方程式相同。这样做是因为直接预测图像上的目标位置导致模型不稳定,并且它们也不受约束。
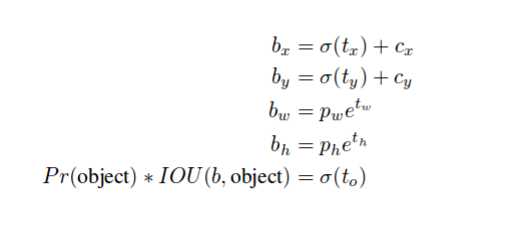
多规模训练。而不是修复输入图像大小我们每隔几次迭代就会改变网络。每10批次我们的网络随机选择一个新的图像尺寸大小。由于我们的模型下采样的因子为32,我们从以下的32的倍数中拉出:{320,352,…,608}。因此最小的选项是320×320,最大的是608×608。我们将网络调整到该维度并继续训练。
Yolov3
Yolov3论文很有趣,我们将在这里重点介绍最重要的内容。
Yolov3达到33.4 IOU@0.5:0.95 mAP和57.9 IOU@0.5 mAP。作者深入研究了为什么我们改变了指标并支持IOU@0.5(VOC风格)。使用VOC风格的mAP,Yolov3非常强大
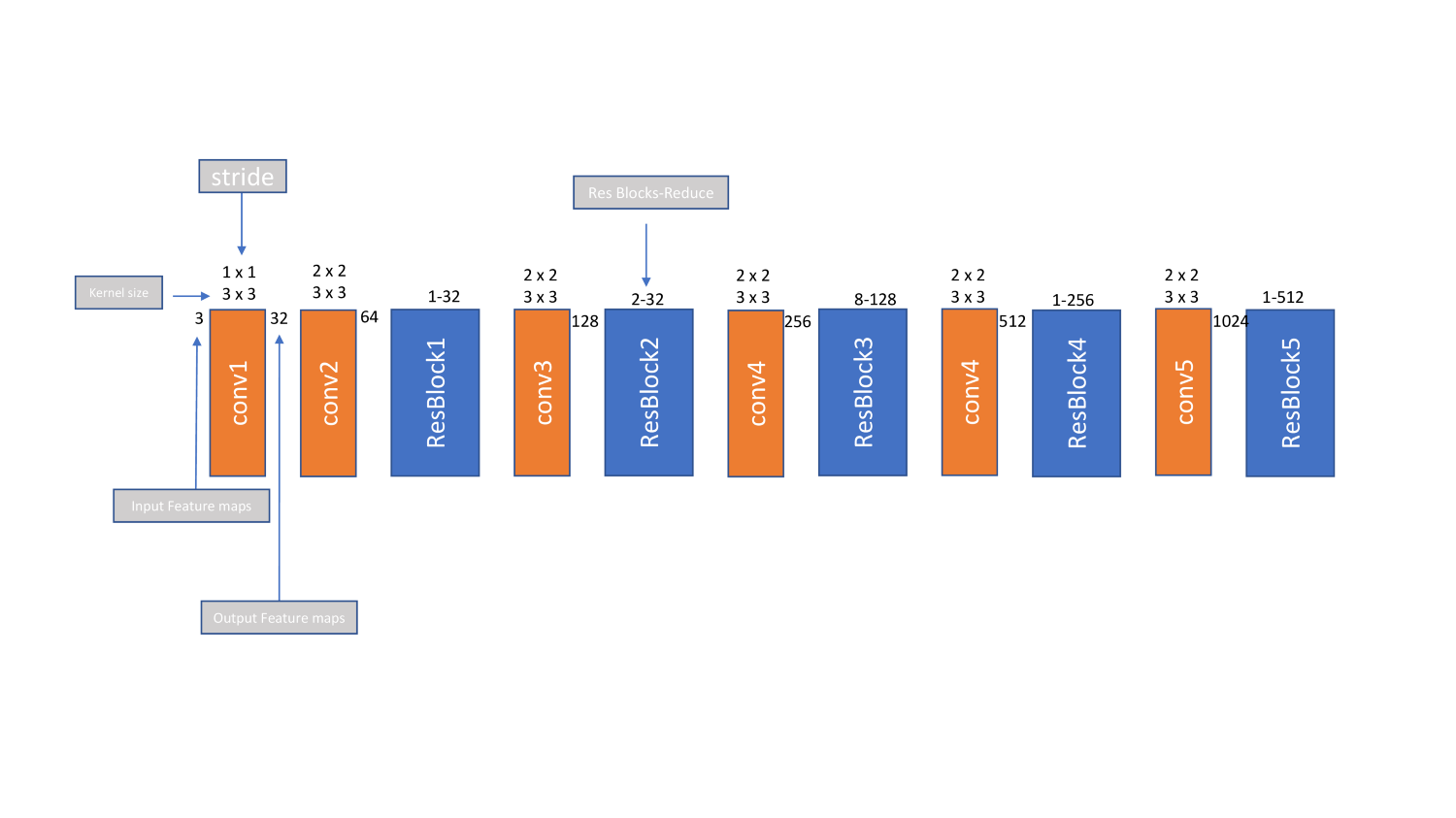
- Yolov3用darknet53替换darknet19并引入残留块。它还介绍了FPN。网络看起来如下所示
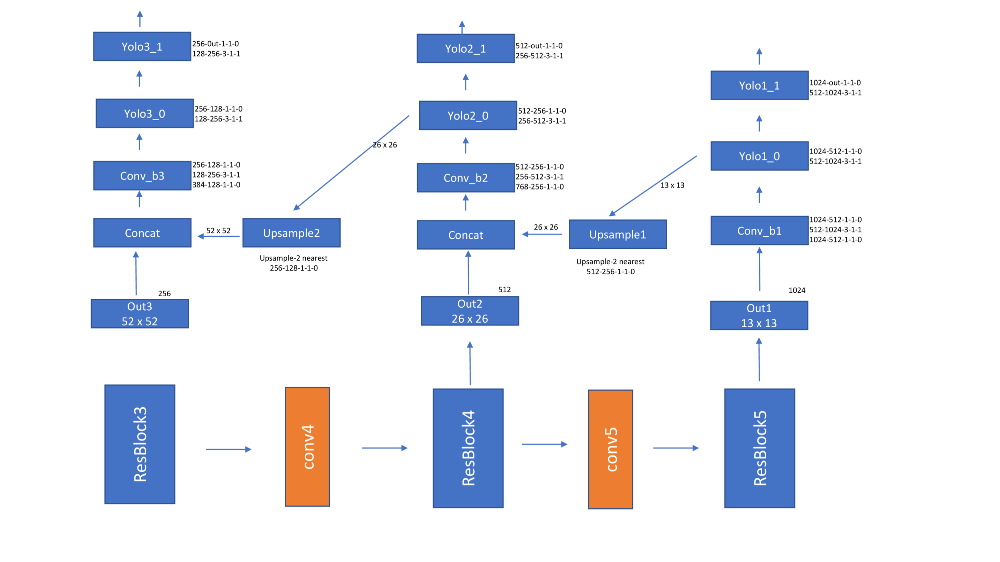
- 损失函数类似于Yolov2和Yolov1,除了它使用二进制交叉熵。在我的实验中,这不起作用,我使用了MSE损失除了正边界框的数量。
- 编码以下列方式完成。一个GT框附加到具有max_iou的锚点。只有包含gt_box中心的单元格的锚点才会被考虑用于锚点。
由于Yolov3使用3个刻度,52x52,26x26和13x13。边界框在每个比例上单独编码。单独计算每层的损耗,然后求和。
SSD-单发探测器
这是我们将在本博文中讨论的最后一个框架,本文中几乎所有的想法都已在上面讨论过了。
在YOLO和Faster RCNN之后发布,本文在300x300输入尺寸图像上以59fps实现了74.3 mAP,我们称之为网络SSD300。同样,SSD512的mAP达到76.9%,超过了Faster R-CNN结果。
网络
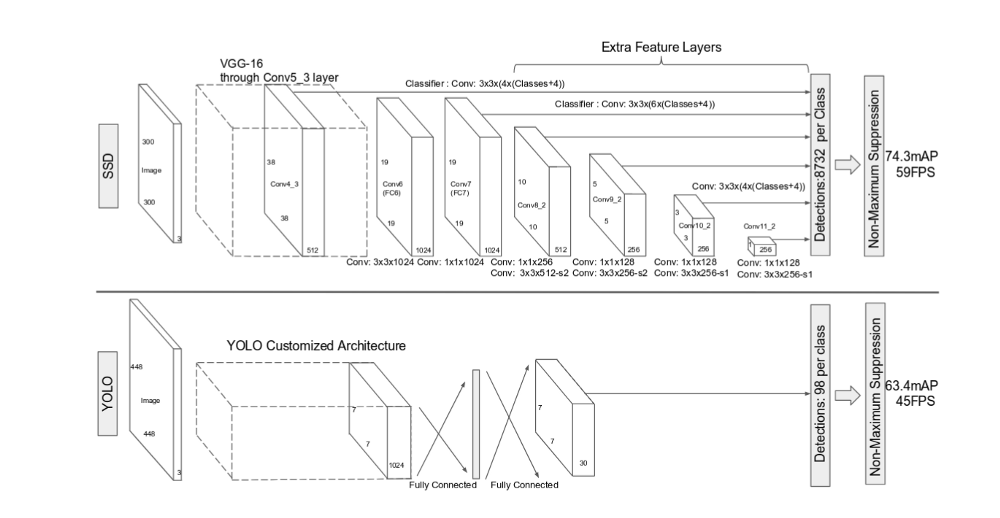
论文本身将网络与YOLO进行了比较。它使用VGG后端并从多个标度中提取特征。注意,它不使用任何横向连接,如Yolov3是FPN。锚箱设计
由于来自不同层的特征图已经捕获了比例,因此SSD每层仅使用一个比例,但是使用公式sk = smin +(smax-smin)/(m-1)*(k-1)来确定比例,其中smin是0.2,smax是0.9。
- 使用[1,2,3,1/2,1/3]的纵横比。使用ska ^(1/2)和sk/a ^(1/2)来确定每个框的w和h。他们还添加了一个(sksk+1)^(1/2)的锚箱,每个位置总共有6个锚箱
如图中conv4_3(38x38),conv7(fc7)(19x19),conv8_2(10x10),conv9_2(5x5),conv10_2(3x3)和conv11_2(1x1)所示。作者建议在每个特征尺度上使用[4,6,6,6,4,4]锚。总锚=(38x38x4)+(19x19x6)+(10x10x6)+(5x5x6)+(3x3x4)+(1x1x4)=(8732个锚点)
编码
SSD使用Jaccard重叠,并且重叠> 0.5的所有锚箱体被认为是+ ve。
损失函数
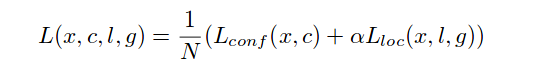
为了置信度,使用交叉熵损失。对于loc,使用平滑的L1损失。与Faster R-CNN不同,为了解决类不平衡问题,他们不仅随机抽取+ ve和-ve框。他们已经为负面样本按递减顺序排列了“目标性”得分并取得了顶部框。通过这种方式,他们获得了3:1-ve+ve样本比率,从而实现Faster 收敛。
就是这个。我们已经讨论了目标检测中几乎所有最先进的论文。还有很多其他论文来改进mAP(Ex GroupNorm而不是BatchNorm),训练更快(Ex Use SGDR)进行讨论。但是现在我们必须在此结束。参考
[1406.4729]用于视觉识别的深度卷积网络中的空间金字塔池
_抽象:现有的深度卷积神经网络(CNN)需要固定大小(例如,224×224)的输入图像。这……_arxiv.org
[1512.02325] SSD:单次多箱体检测器
_摘要:我们提出了一种使用单个深度神经网络检测图像中物体的方法。我们的方法,名为…_arxiv.org
[1701.06659] DSSD:反卷积单发探测器
_摘要:本文的主要贡献是将其他背景引入最新技术的方法…_arxiv.org
[1504.08083]Fast R-CNN
_摘要:本文提出了一种基于Fast 区域的卷积网络方法(Fast R-CNN)用于目标检测。快……_arxiv.org
[1311.2524]用于精确目标检测和语义分割的丰富特征层次结构
_摘要:在规范的PASCAL VOC数据集上测量的目标检测性能在最近几年已经趋于稳定…_arxiv.org
[1506.01497]Faster R-CNN:利用区域提议网络实现实时目标检测
_摘要:最先进的目标检测网络依赖于区域提议算法来假设目标…_arxiv.org
[1612.03144]用于目标检测的特征金字塔网络
_摘要:特征金字塔是用于检测不同尺度的目标的识别系统中的基本组件。但是……_arxiv.org
[1708.02002]密集目标检测的焦点损失
_摘要:迄今为止最高精度的物体探测器是基于R-CNN推广的两阶段方法,其中一个…_arxiv.org
[1506.02640]你只看一次:统一的实时目标检测
_摘要:我们提出了一种新的目标检测方法YOLO。先前关于目标检测的工作将分类器重新用于…_arxiv.org
[1612.08242] YOLO9000:更好,更快,更强大
_摘要:我们推出YOLO9000,这是一种先进的实时目标检测系统,可以检测超过9000个物体…_arxiv.org
[1804.02767] YOLOv3:增量改进
_摘要:我们向YOLO提供一些更新!我们做了一些小的设计更改,以使其更好。我们还训练了……_arxiv.org
[1803.08494]群规范化
_摘要:批量规范化(BN)是深度学习发展中的里程碑技术,可以实现各种… …_arxiv.org
如果您有任何建议或意见,请在帖子上发表评论或写信给vanapalli.prakash@fractalanalytics.com或发送电子邮件至dle@fractalanalytics.com。

若有收获,就点个赞吧
0 人点赞
