由Kaiming He及其团队在FAIR开发的Mask R-CNN于2018年发布,是实例分割最强大的算法之一。在Fractal.ai,我们使用Mask R-CNN框架来解决各种业务问题。此博客文章可帮助用户了解其工作原理

Mask R-CNN成为我们堆栈中最强大的目标识别算法之一,其分形图像团队在各种用例中广泛使用它的变体。Mask R-CNN既强大又复杂。上面的图表给出了数据如何通过Mask R-CNN算法流动的一瞥。我们认为正确理解Mask R-CNN对于调整其参数非常重要,并且确切地知道在何处使用该算法以及何处不使用它。
Mask R-CNN做什么?
Mask R-CNN是目标检测算法Faster R-CNN的扩展,带有额外的Mask head。额外的Mask head允许我们在没有任何背景情况下以像素方式对每个目标进行分段,并且还分别提取每个目标(这是通过语义分割不可能的)。
Mask R-CNN有多成功?
- Mask R-CNN很容易训练,只需很少的开销就可以以5 fps的速度加速R-CNN。
- Mask R-CNN在每项任务中都优于所有现有的单一模型条目,包括COCO 2016挑战赛获胜者。
-
历史简介
Mask R-CNN是从之前的算法演变而来的。以如下顺序演变:
R-CNN使用选择性搜索来选择图像中的提议。每个提议都通过深度学习模型发送,并提取2048向量。针对这些向量上的每个类训练独立分类器以对目标进行分类。
- Fast R-CNN删除了SVM分类器的训练,并使用了回归层和分类层。他们还在特征图而不是图像上应用了选择性搜索,因此无需在整个网络中发送每个提议。
- Faster R-CNN去除了选择性搜索并使用称为RPN(区域提议网络)的深度卷积网络来生成提议,从而允许在单个阶段中训练端到端神经网络。
- Mask R-CNN是Faster R-CNN的扩展,附加为每个图像生成高质量的分割Mask的模块 。
这篇博文的目的是对模型进行深入的解释,并研究Faster R-CNN的变化以及它如何为算法带来改进和新功能。
这里写出了对进化的详细分析。
Faster R-CNN
Faster R-CNN是两级检测器。在第一阶段,它生成一组具有存在较高概率的目标的提议。然后,这些提议通过检测网络,在该检测网络上预测类和边界框回归偏移。本博客假设读者理解Faster R-CNN。如果情况并非如此,请仔细阅读以下博客,如果您不清楚Faster R-CNN的概念。
- 在PyTorch中构建Faster RCNN的指南
_从head开始理解和实现Faster RCNN。_medium.com - 使用R-CNN进行目标检测和分类
_在这篇文章中,我将详细描述R-CNN(具有CNN功能的区域),最近推出的深度学习…_www.telesens.coMask R-CNN
根据其研究报告,与其前身Faster R-CNN类似,它是一个两阶段框架:第一阶段负责生成目标提议,而第二阶段则分类提议以生成边界框和Mask 。检测分支(分类和边界框偏移)和Mask 分支彼此并行运行。对特定类的分类不依赖于Mask 预测。然而,我们认为它是一个三阶段框架,生成箱体和Mask 是两个不同的阶段,因为我们不会在RPN的所有提议上生成Mask ,但仅限于我们从箱体Mask部获得的检测。
从Faster R-CNN到MaskR-CNN的三大变化:
- 使用的是FPN
- 更换ROIPool与ROIAlign
- 介绍增加产生Mask的分支
特征金字塔网络已经成为非常有效的骨干,并且已经提高了许多目标检测框架(例如:Retinanet)的准确性。这些已集成在Mask R-CNN中以产生ROI(感兴趣区域)特征。
Faster-R-CNN的另一个重大变化是用ROI Align取代ROI Pool。在目标检测的情况下,ROI池确实工作得很好,它涉及粗略的量化步骤,但这在生成Mask 预测的情况下将变成灾难。
我们将在本博客中进一步讨论FPN和ROI的详细内容。首先,让我们了解图像在发送到网络之前是如何预处理的。
图像预处理
在将图像发送到网络之前,将一些预处理步骤应用于图像。
- 平均值的减法: 平均矢量(3×1,对应于每个颜色通道)是所有训练中的像素值的平均值,并且从输入图像中减去测试图像。
- 重新缩放:采用两个参数(目标大小和最大大小)。将较短的一侧调整到目标尺寸,并且相应地调整较长边的尺寸,从而保持纵横比。但是,如果较长边的新值超过最大尺寸,则较长边调整为最大值,较短边的调整值参照较长边改变,保持纵横比。目标大小和最大大小的默认值分别为800和1333。
- 填充:当涉及特征金字塔网络(FPN)时,这是必要的(在下一节中解释)。所有填充仅对最右边和最底边进行,因此目标坐标不需要更改,因为坐标系基于最左上角。如果我们不使用FPN,则不需要此步骤。
让我们通过一个例子来理解这个: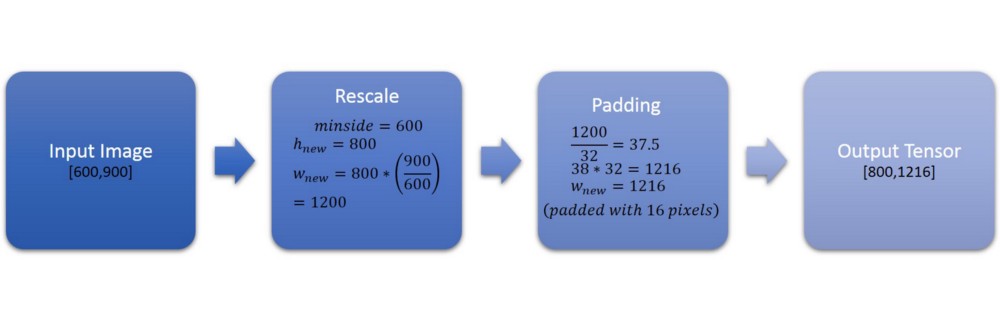
这里将两侧(600)的最小值重新缩放为800,并且以相同的比例调整另一个尺寸的大小。由于新缩放的边(1200)不是32的倍数,因此将其填充使得所得尺寸是其倍数(1216/32 = 38)。
注意:锚点生成和过滤步骤的图像高度和宽度将被视为已调整大小的图像的图像高度和宽度,而不是填充后的图像高度和宽度。
特征金字塔网络(FPN)骨干
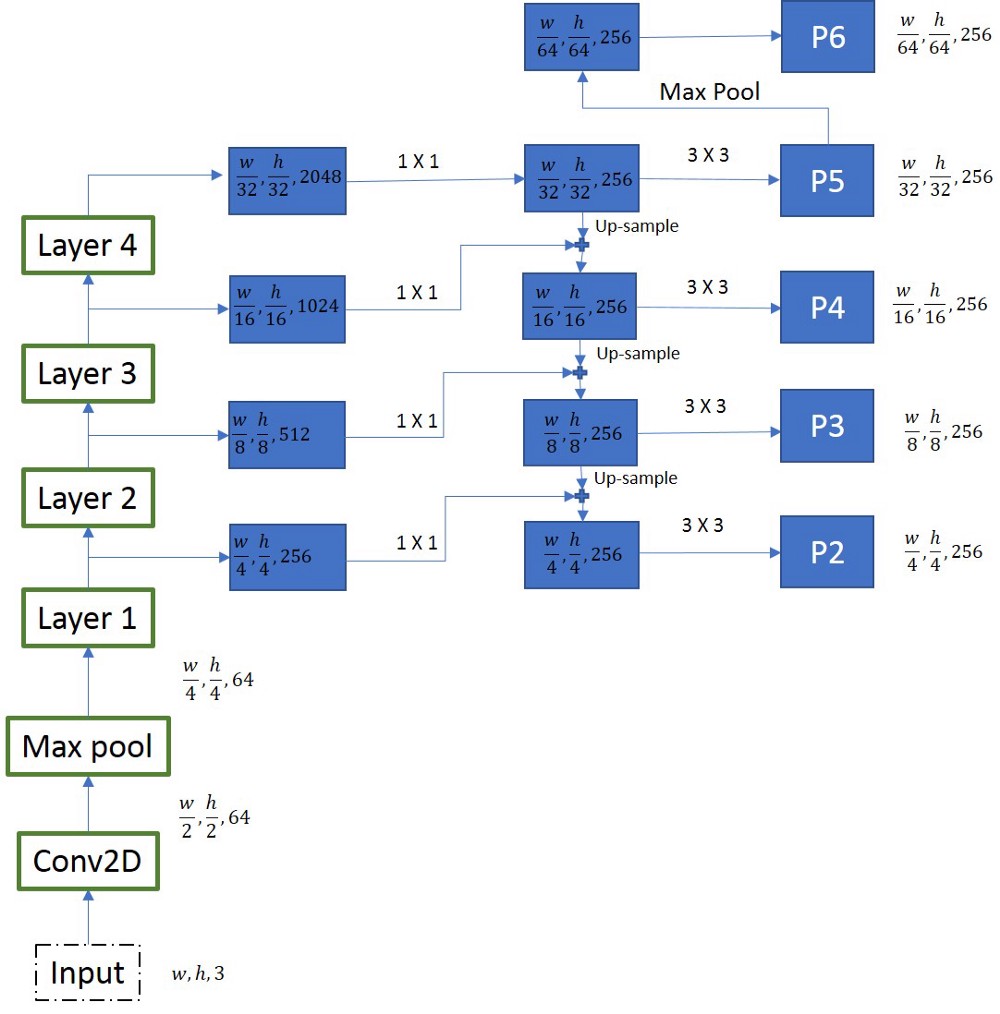
Faster R-CNN使用标准的Resnet类型的架构来编码图像。在每一层,特征图的大小减少一半,特征图的数量增加一倍。我们从resnet-50架构(第1层,第2层,第3层,第4层输出)中的4个特征映射中提取特征,如图所示。为了生成最终的特征图,我们使用一种称为上下通道的方法。我们从最小的特征映射开始,通过高级操作逐步向下工作。在图中我们可以看到,第2层生成的特征映射首先经过1×1卷积以降低通道数量然后,将其逐个元素地添加到前一次迭代的上采样输出中。该过程的所有输出都经过3×3卷积层以创建最终的4个特征图(P2,P3,P4,P5,P6)。第5个特征图(P6)是从P5的最大合并操作生成的。
注意这里的尺寸,上采样操作中涉及的尺寸最小的特征图是(w/32,h/32)。这使得我们确保输入张量具有可被32整除的维度非常重要。让我们举一个例子,让w = 800和h = 1080。w/32 = 25,h/32 = 33.75,这意味着特征图的大小(25,33)。在上采样时,尺寸将是(50,66),这应该是元素方式添加到另一个尺寸的特征图(50,67)。这会引发错误。因此,如果我们使用FPN,则输入张量在这种情况下必须是32的倍数。
区域提议网络(RPN)
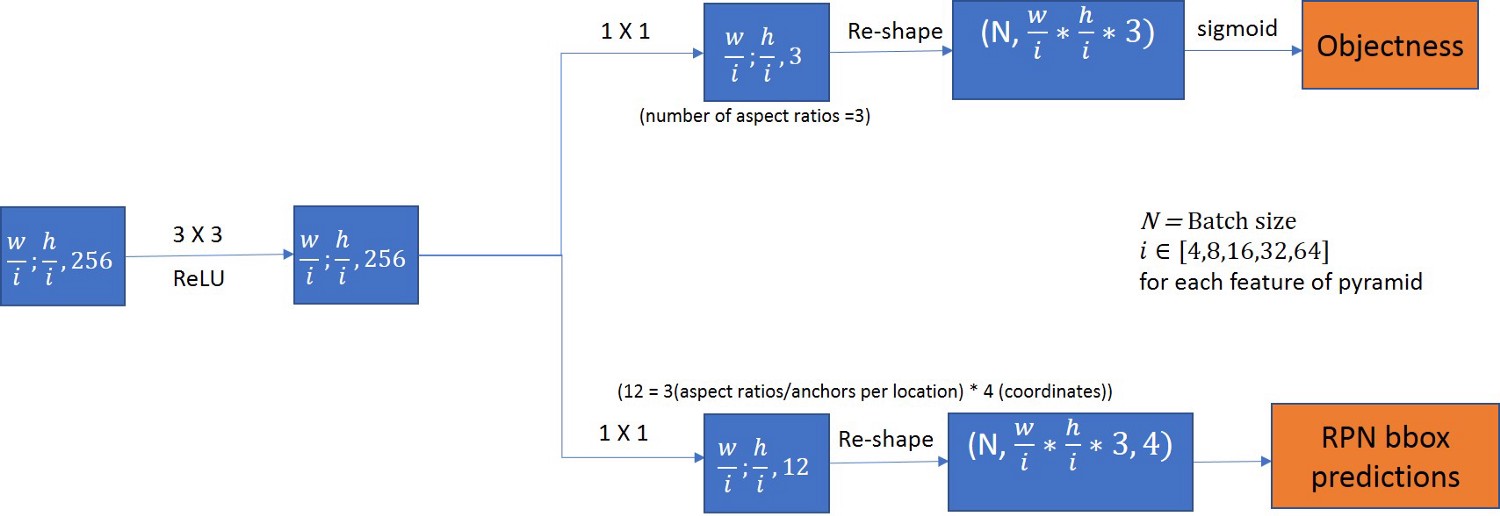
生成的每个特征图都通过3×3卷积层。结果输出传递给两个分支,一个分支与目标分数相关,另一个与边界框回归分类相关。我们这里仅使用一个锚定步幅用于特征金字塔(因为我们已经在金字塔中具有不同尺寸的特征以照顾不同尺寸的物体)和3个锚定比率。因此,目标性中的3个通道和边界框回归中的3 * 4个通道。
请注意,对于训练和测试,所有锚定比率,步幅等必须完全相同,因为目标性得分和边界框回归量通道对应于训练期间使用的锚定比率。
RPN边界框预测的值与特征图的尺寸无关,并且在解码步骤期间将需要乘以图像的图像高度和宽度。
提出提议
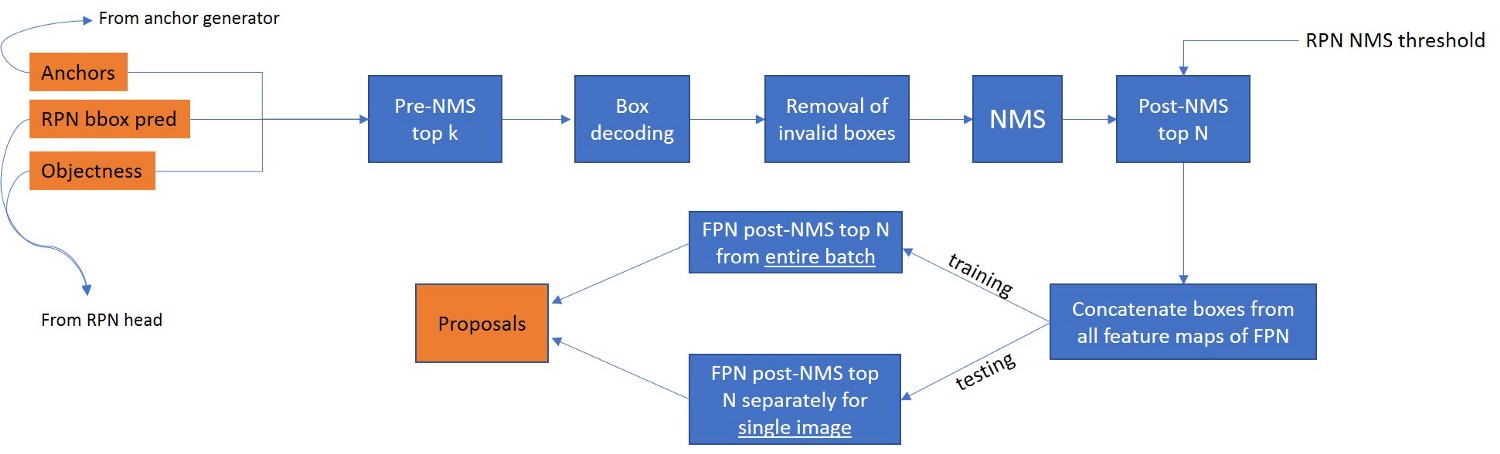
- 前k: 基于其对应的目标得分选择前k(对于训练的默认k = 12000,测试= 6000)锚点。
- 框解码:根据从RPNhead获得的rpn_bbox_pred值修改锚框的坐标。在此图中,宽度和高度是调整大小的图像的尺寸(图像预处理部分中的读取注释)
- 删除无效框: 删除坐标位于图像外部的边界框或具有负高度和宽度的图像。
- NMS:应用 非最大抑制来移除重叠超过阈值的框(RPN NMS阈值,默认值= 0.7)。
- 连接:对于FPN骨干生成的金字塔的每个特征,分别执行了步骤1-4。在此步骤中,所有锚框(已在原始尺寸调整图像的坐标系中)被分组在一起。我们不存储哪个ROI来自哪个FPN层的信息。
FPN发布NMS前N: 此步骤与培训和测试不同。在培训的情况下,我们根据整个批次中所有图像的所有提议的相应目标得分,选择前N(默认= 2000)提议。在测试的情况下,为批次中的每个图像选择N(默认= 2000)提议并单独保存。
Box head
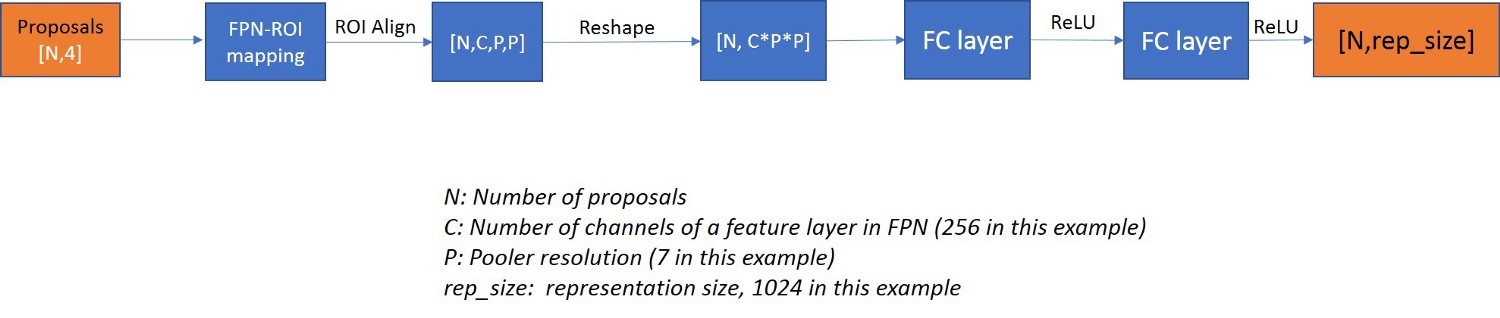
FPN-ROI映射:FPN-ROI映射的目的是根据其区域将FPN的适当特征映射关联到特定ROI。通过提及较小的尺度,如果在所有特征图上使用ROI对齐不符合我们的目的,我们可以使用较少数量的较小尺度。
resnet-50-FPN示例(也是facebook_maskrcnn_benchmark上resnet-50-fpn的官方实现)生成5个特征映射,其中所有5个都在RPN中用于生成提议,但是,只有4个(P2,P3,P4,P5) )在与ROI关联时使用。

从等式1(取自特征金字塔网络研究论文),我们得到对应于该特定ROI的整数等级。在此示例中,lvl_min为2,lvl_max为5.如果target_lvl值为3,那么它将与P3关联。如果target_lvl值小于2或大于5,则将其分别钳位到2和5。
2. ROI对齐:来自fast-r-cnn的最重要变化之一是用ROI对齐替换ROI池。这两个操作都为所有ROI生成统一的PXP矩阵。ROI Pool在目标检测的情况下工作良好,但在实例分割的情况下非常失败,因为我们有太多量化步骤影响Mask 的生成,其中像素到像素的对应很重要。有关详细说明,请参阅附录。现在,让我们考虑ROI Align/ Pool提供PXP的恒定输出,无论提议大小如何。
3.完全连接的层:每个ROI的输出被重新整形以通过完全连接的层,其中输出通道的数量是称为表示大小的超参数(默认值:1024)。这通过具有相同数量的输入和输出通道的另一个FC层传递。我们为所有ROI获得不同的1024长度向量。
我们在此处提取的功能是针对Resnet-50 FPN。如果使用一些不同的主干,这将改变,但总体而言,所有使用ROI对齐并为每个ROI生成相同大小的输出向量。
ROI向量通过预测器,包含2个分支,每个分支具有FC层。一个用于预测目标类,另一个用于边界框回归值。我们还可以选择在此处选择类不可知边界框回归,其中num_bbox_classes = 2,即前景和背景,否则num_bbox_classes将与分类分支中的类数相同。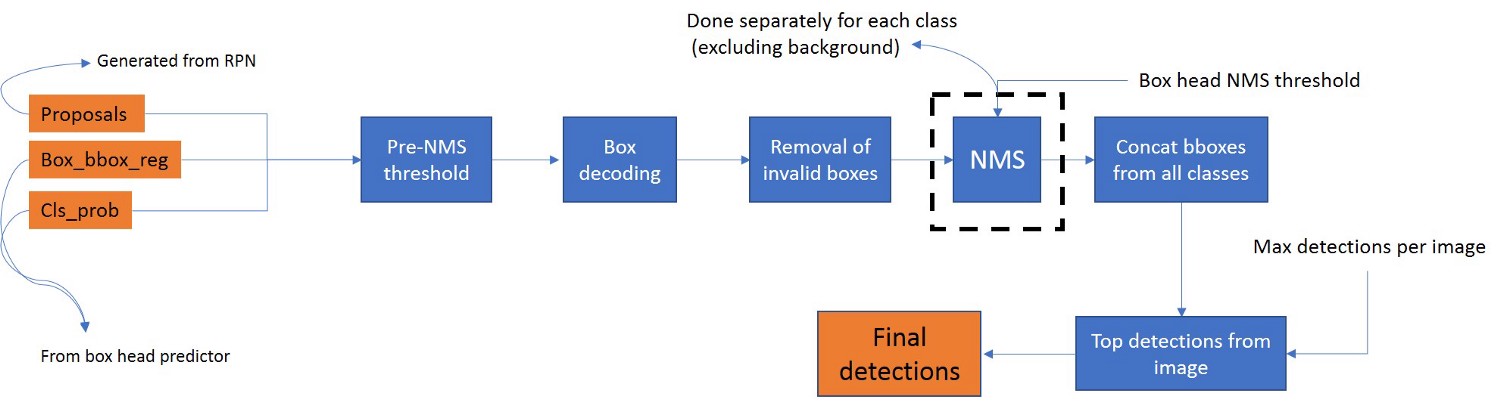
- NMS前阈值:根据类概率分数过滤NMS之前的检测(默认值= 0.5)
- 解码:类似于RPN的情况。请注意,我们为每个提议分别为每个类设置了box_bbox_reg值(例如:提议大小= [1000,4],box_bbox_reg大小= [100,81(类别)* 4])。在本例中,我们将对提议应用解码步骤81次。
- 删除无效框:与RPN相同。
- NMS:我们定义NMS阈值(默认值= 0.5)。对于每个类将所得的提议被分离和NMS完成单独为每个类。
- 过滤顶部检测:对图像中的所有类组合的最大检测,即,图像中不会有超过此数字的检测。对于COCO数据集,该值设置为100。
Head head

Mask 的特征提取过程类似于框。一个关键的区别是在完全连接的层丢失生成Mask 所需的空间结构信息之前,没有完全连接的层作为重新整形存在于Box head中。就像我们使用ROI提议作为Box head特征提取器的输入一样,我们在这里使用检测到的边界框作为输入。FPN ROI映射再次类似于box head。
ROI对齐输出通过一系列3 X 3卷积层,然后是ReLU,每层的输出通道数和层数是超参数(对于Resnet-50-FPN,它设置为(256,256,256,256) )。对于每次检测,我们得到与ROI对齐输出相同尺寸的输出张量。
提取的特征通过预测器传递,该预测器涉及deconv操作。这经受1×1卷积层,对于每次检测,输出通道的数量等于类的数量,每个类别一个Mask 。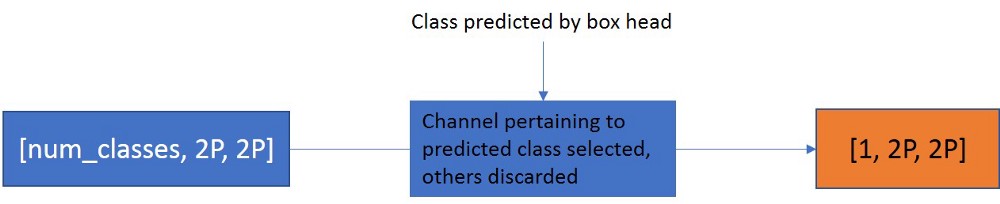
我们已经预测了该检测的类别,对于每个提议,我们根据类别选择通道,将维度减小到[D,1,2P,2P]。Head 的后处理:

可以根据输入图像调整所获得的Mask 的大小。Mask 张量是填充的,原因是为了避免由于我们之前的上采样(deconv)操作引起的边界效应。根据新Mask 重新缩放边界框坐标并将其转换为最接近的整数(坐标相对于输入图像)。Mask 也根据图像尺寸重新缩放,所使用的插值方法是双线性的。Mask 阈值是超参数(默认值:0.5)。对于每个像素,如果该值大于0.5,则假定该目标存在于该像素中,否则不存在。我们最终获得了目标的[image_height,image_width]蒙版,类似于图像的所有目标。
附录 - ROI池和ROI对齐
让我们用一个例子来理解它。让我们先看看ROI池:
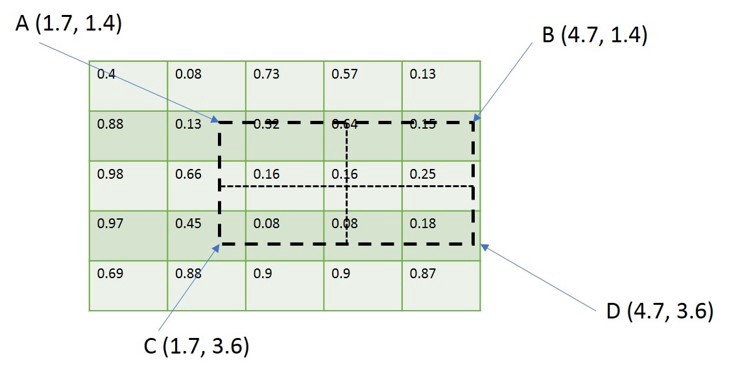
我们假设一个5 X 5的特征图,其上绘制了ROI。请注意,ROI的边界与要素图的粒度不一致(因为ROI具有与原始图像的坐标,并且要素图具有比输入图像更低的分辨率)。
为解决上述问题,将舍入ROI的边界以匹配要素图的粒度。现在,ROI的边界与特征映射的粒度一致。
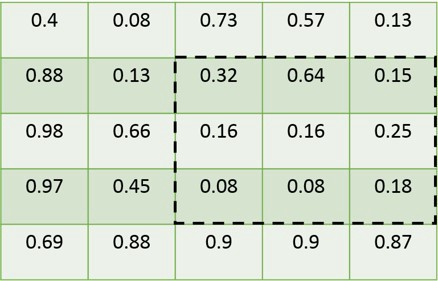
根据我们提到的输出大小(m),我们得到amxm矩阵,我们根据m的值将ROI分成bin。在这个例子中,我们采用m = 2。请注意,Box 的边界再次与要素图的边界不对齐。
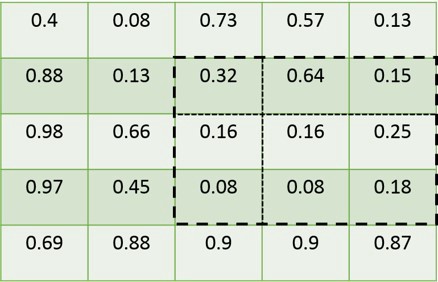
我们再次执行量化步骤,类似于步骤1.我们分别在每个bin中应用max-pool操作。因此,本例中的最后四个值为(0.32,0.64,0.16,0.25)。
我们得到了所有投资回报率的最终m X m矩阵。

这种类型的汇集方法在目标检测的情况下工作良好,但在实例分割的情况下非常失败,因为我们有太多的量化步骤影响Mask 的生成,其中像素到像素值很重要。现在让我们看看ROI与类似的例子对齐。
我们有相同的初始投资回报率。请注意,我们不会在ROI和垃圾Box 上执行任何量化操作。

我们在每个Box 子中取4个(2 * 2)个采样点。Mask R-CNN研究论文表示,样本点的位置和数量并不重要。下面的等式说明了他们如何根据facebook maskrcnn_benchmark repo选择样本点。
num_samples的值已被取2。X_low和X_high是bin的最低和最高x坐标。使用这个等式,我们得到4个点的坐标(S1,S2,S3,S4)
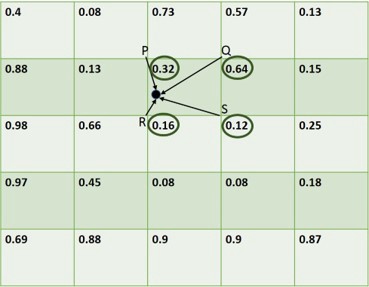
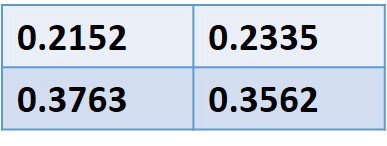
例如,我们选择S1,我们在特征图上识别出与特征图的分辨率(其坐标将是整数)匹配的4个最近点。在这种情况下,P(2,1),Q(3,1),R(2,2)和S(3,2)具有它们各自的值。使用4点和下面的等式,我们采用双线性插值来计算该特定采样点的特征值。因此,对于S1,我们得到的值为0.21778。

我们重复其他采样点的过程,我们为每个点获得不同的值。我们对垃圾Box 中的所有采样点执行平均汇集。根据研究论文,我们也可以使用max-pool而不会对结果进行任何重大更改,但是他们在官方实施中使用了平均池。
我们重复所有垃圾Box 的过程,并为所有投资回报率获得相同尺寸的最终输出。
结束笔记
就是这个。我们希望读者了解Mask R-CNN的内部工作原理。由Sarang Pande撰写。特别感谢Fractal Image Team Suraj Amonkar,Prakash Jay,Sachin Chandra,Vikash Challa,Rajneesh Kumar,thanuj raju pilli,saksham jindal,Abhishek Chopde,Sindhura K,praneeth chandra,Samreen Khan。
参考

若有收获,就点个赞吧
0 人点赞
