关于在Spark上运行Python有无数文章和论坛帖子,但大多数人认为要提交的工作包含在一个.py文件中:spark-submit wordcount.py - 完成!
如果你的Python程序不仅仅是一个脚本怎么办?也许它为Spark生成动态SQL来执行,或使用Spark的输出刷新模型。随着您的Python代码变得更像一个应用程序(具有目录结构,配置文件和库依赖项),将其提交给Spark需要更多考虑。
以下是我最近考虑使用Spark 2.3将一个这样的Python应用程序用于生产时的替代方案。第一篇文章重点介绍Spark独立集群。另一篇文章介绍了EMR Spark(YARN)。
我远不是Spark的权威,更不用说Python了。我的决定试图平衡正确性和易于部署,以及应用程序对群集的限制。让我知道你的想法。
趋势AI文章:
1.使用机器学习预测购买行为> 2.理解和构建生成对抗网络(GAN)> 3.使用OpenCV和Haar Cascades构建Django POST面部检测API> 4.通过Hindsight Experience Replay从错误中学习
示例Python应用程序
为了模拟完整的应用程序,下面的场景假定Python 3应用程序具有以下结构:
project.pydata /data_source.pydata_source.ini
data_source.ini包含各种配置参数:
[spark]app_name =myPySpark Appmaster_url = spark:// sparkmaster:7077
data_source.py是一个模块,负责在Spark中获取和处理数据,使用NumPy进行数学转换,并将Pandas数据帧返回给客户端。依赖关系:
from pyspark import SparkConf, SparkContextfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StructField, FloatTypeimport pandas as pdimport numpy as npimport configparser
它定义了一个创建和初始化的DataSource类……SparkContext``SparkSession
class DataSource:def __init__(self):config = configparser.ConfigParser()config.read('./data/data_source.ini')master_url = config['spark']['master_url']app_name = config['spark']['app_name']conf = SparkConf().setAppName(app_name) \.setMaster(master_url)self.sc = SparkContext(conf=conf)self.spark = SparkSession.builder \.config(conf=conf) \.getOrCreate()
…和一个get_data()方法:
- 从NumPy正态分布创建RDD。
- 应用函数将每个元素的值加倍。
- 将RDD转换为Spark数据帧并在顶部定义临时视图。
- 应用Python UDF,使用SQL对每个dataframe元素的内容进行平方。
- 将结果作为Pandas数据帧返回给客户端。
def get_data(self, num_elements=1000) -> pd.DataFrame:mu, sigma = 2, 0.5v = np.random.normal(mu, sigma, num_elements)rdd1 = self.sc.parallelize(v)def mult(x): return x * np.array([2])rdd2 = rdd1.map(mult).map(lambda x: (float(x),))schema = StructType([StructField("value", FloatType(), True)])df1 = self.spark.createDataFrame(rdd2, schema)df1.registerTempTable("test")def square(x): return x ** 2self.spark.udf.register("squared", square)df2 = self.spark.sql("SELECT squared(value) squared FROM test")return df2.toPandas()
project.py是我们的主程序,充当上述模块的客户端:
from data.data_source import DataSourcedef main():src = DataSource()df = src.get_data(num_elements=100000)print(f"Got Pandas dataframe with {df.size} elements")print(df.head(10))main()
克隆回购:https://bitbucket.org/calidoteam/pyspark.git
在开始之前,让我们回顾一下向Spark提交工作时可用的选项。
spark-submit,客户端和集群模式
- Spark支持各种集群管理器:独立(即内置于Spark),Hadoop的YARN,Mesos,Kubernetes,所有这些都控制着工作负载在一组资源上的运行方式。
spark-submit是唯一与所有集群管理器一致的接口。对于Python应用程序,spark-submit可以在需要时上载和暂存您提供的所有依赖项,如.py,.zip或.egg文件。- 在客户端模式下驱动程序_)将在运行的同一主机上
spark-submit运行。确保此类主机靠近工作节点以减少网络延迟符合您的最佳利益。 - 在集群模式下驱动程序某个工作节点并从其运行。从远程主机提交作业时,这很有用。从Spark 2.4独立开始,Spark 2.4.0集群模式不是一个选项。
- 或者,可以
spark-submit通过SparkSession在Python应用程序中配置连接到群集来绕过。这需要正确的配置和匹配的PySpark二进制文件。您的Python应用程序将在客户端模式下有效运行:它将从您启动它的主机上运行。
以下部分描述了几种部署方案,以及每种方案中需要的配置。
#1:直接连接到Spark(客户端模式,无spark-submit)
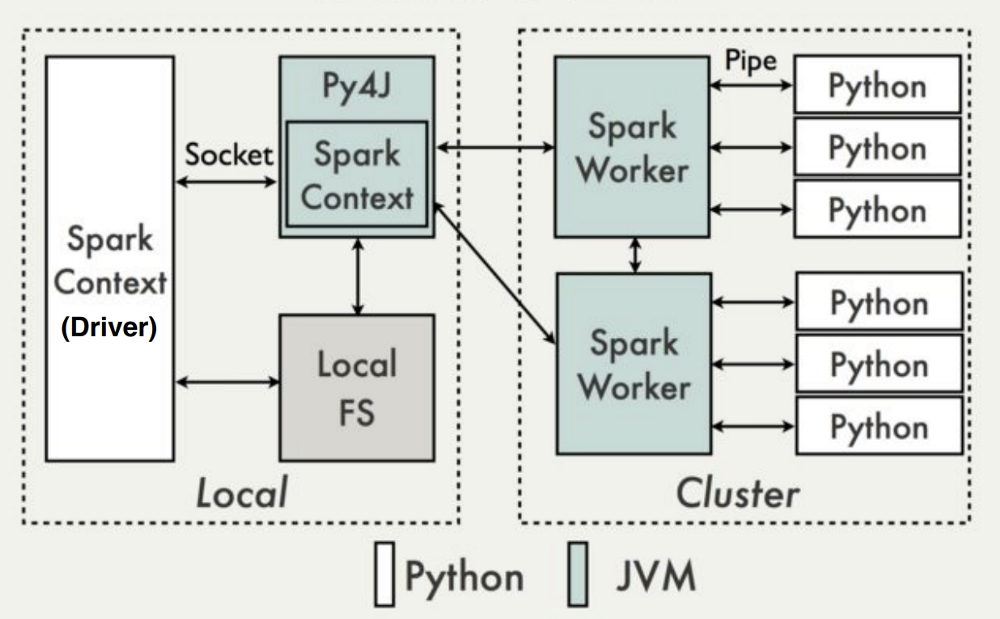
针对Spark独立的客户端模式的Python应用程序
这是最简单的部署方案:Python应用程序通过指向Spark主URL直接建立spark上下文,并使用它来提交工作:
conf = SparkConf().setAppName("My PySpark App") \.setMaster("spark://192.168.1.10:7077")sc = SparkContext(conf=conf)spark = SparkSession.builder \.config(conf=conf) \.getOrCreate()
在独立群集中,资源在作业持续时间内分配,默认配置为客户端应用程序提供所有可用资源,因此需要对多租户环境进行微调。执行程序进程(JVM或python)由每个节点本地的工作进程启动。
这类似于传统的客户端 - 服务器应用程序,因为客户端只是“连接”到“远程”集群。建议:
确保驱动程序和群集之间有足够的带宽。大多数网络活动发生在驱动程序和它的执行程序之间,因此这个“远程”集群实际上必须在近距离(LAN)内。
通过启用Apache Arrow改进Java-Python序列化: Python工作负载(NumPy,Pandas和其他应用于Spark RDD,数据帧和数据集的转换)默认需要大量的Java和Python进程的序列化和反序列化,并且会迅速降低性能。从Spark 2.3开始,启用Apache Arrow(包含在下面列出的步骤中)使这些传输更加高效。
跨所有群集节点和驱动程序主机部署依赖关系。这包括下载和安装Python 3,pip安装PySpark(必须与目标集群的版本匹配),PyArrow以及其他库依赖项:
sudo yum install python36pip install pyspark==2.3.1pip install pyspark[sql]pip install numpy pandas msgpack sklearn
注意:在安装像PySpark这样的大型库(~200MB)时,可能会遇到以“ MemoryError” 结尾的错误。如果是这样,请尝试:
pip install --no-cache-dir pyspark==2.3.1
配置和环境变量:在客户端,$SPARK_HOME必须指向pip安装PySpark的位置:
$ pip show pysparkName: pysparkVersion: 2.3.1Summary: Apache Spark Python APIHome-page: https://github.com/apache/spark/tree/master/pythonAuthor: Spark DevelopersAuthor-email: dev@spark.apache.orgLicense: http://www.apache.org/licenses/LICENSE-2.0Location: /opt/anaconda/lib/python3.6/site-packagesRequires: py4j$ export SPARK_HOME=/opt/anaconda/lib/python3.6/site-packages
在每个群集节点上,设置其他默认参数和环境变量。特别是对于Python应用程序:$SPARK_HOME/conf/spark-defaults.sh
spark.sql.execution.arrow.enabled true
$SPARK_HOME/conf/spark-env.sh
export PYSPARK_PYTHON=/usr/bin/python3:Python可执行文件,所有节点。export PYSPARK_DRIVER_PYTHON=/usr/bin/python3:驱动程序的Python可执行文件,如果与执行程序节点不同。
注:环境变量是从哪里读spark-submit的推出,不一定是从群集主机内。
运行它
将工作负载提交到集群只需运行Python应用程序(例如spark-submit,不需要):
$ cd my-project-dir/$ python3 project.py
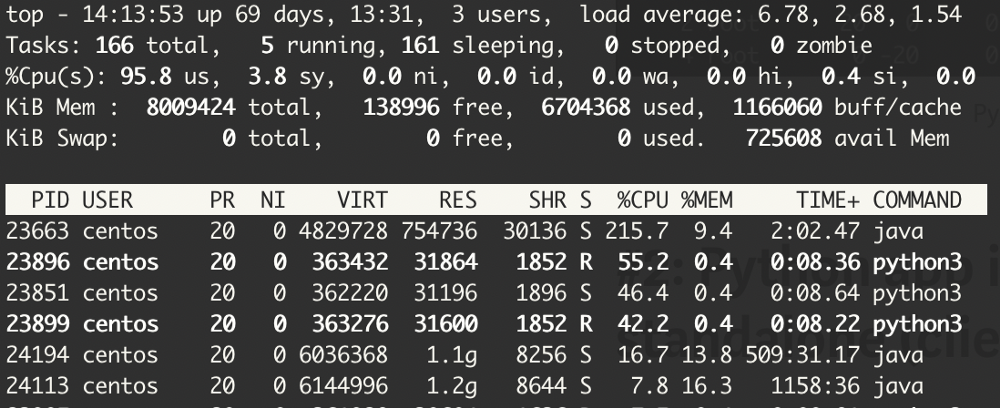
在运行时,可以看到运行多个python3进程的从属节点在作业上运行:
#2:集装箱式应用(客户端模式,无火花提交)
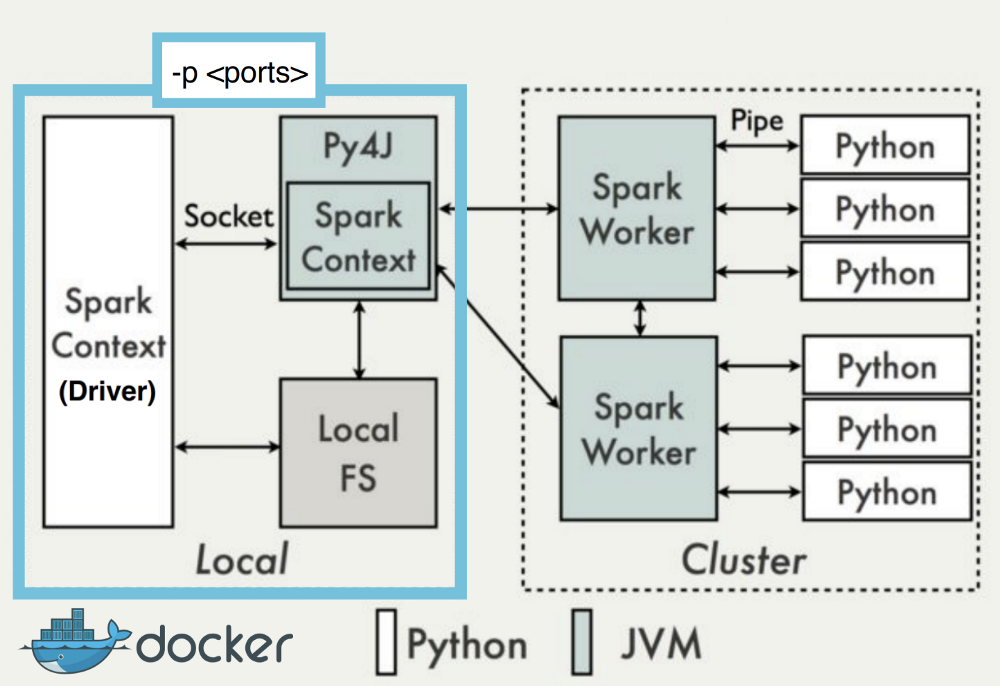
这是前一个场景的扩展,由于可移植性等原因,最好将Python应用程序作为Docker容器运行,作为CI / CD管道的一部分。
除了针对上一个方案推荐的配置外,还需要以下内容:
构建容器以包含所有依赖项:从包含Python 3和/或Java 8 OpenJDK的映像开始,然后pip-install PySpark,PyArrow以及应用程序所需的所有其他库。
配置Spark驱动程序主机和端口,在容器中打开它们:这是执行程序到达容器内驱动程序所必需的。可以通过编程方式设置驱动程序的Spark属性(spark.conf.set(“property”, “value”)):
spark.driver.host : host_ip_address (e.g. 192.168.1.10)spark.driver.port : static_port (e.g. 51400)spark.driver.bindAddress : container_internal_ip (e.g. 10.192.6.81)spark.driver.blockManagerPort : static_port (e.g. 51500)
在Docker中,端口可以使用-p选项从命令行公开到外部:-p 51400:51400 -p 51500:51500。其他文章建议只发布此端口范围:-p 5000–5010:5000–5010
运行它
与前一个场景一样,运行容器将启动Python驱动程序:
docker run -p 51400:51400 -p 51500:51500 <docker_image_url>
#3:通过spark-submit提供Python应用程序(客户端模式)
此方案实际上与方案#1相同,仅为了清楚起见包含在此处。唯一的区别是Python应用程序是使用该spark-submit进程启动的。除了日志文件之外,还会将群集事件发送到stdout:
$ cd my-project-dir/$ ls -lrwxrwxr-x. 3 centos centos 70 Feb 25 02:11 data-rw-rw-r--. 1 centos centos 220 Feb 25 01:09 project.py$ spark-submit project.py
笔记:
- 根据我的经验,
spark-submit只要从项目根目录(my-project-dir/)调用它就没有必要在调用时传递依赖的子目录/文件。 - 由于示例应用程序已指定主URL,因此无需将其传递给
spark-submit。否则,更完整的命令将是:
$ spark-submit --master spark://sparkcas1:7077 --deploy-mode client project.py
- 从Spark 2.3开始,无法将集群模式下的Python应用程序提交给独立的Spark集群。这样做会产生错误:
$ spark-submit --master spark://sparkcas1:7077 --deploy-mode cluster project.pyError: Cluster deploy mode is currently not supported for python applications on standalone clusters.
Takeaways- Python on Spark独立集群:
- 虽然独立群集在生产中不受欢迎(可能是因为商业支持的分发包括群集管理器),但只要不需要多租户和动态资源分配,它们的占用空间就会更小并且做得很好。
- 对于Python应用程序,部署选项仅限于客户端模式。
- 使用Docker来容纳Python应用程序具有所有预期的优势,非常适合客户端模式部署。

若有收获,就点个赞吧
0 人点赞
