参见:李东风的R 教程
这里处理的小说是猫腻的《庆余年》(虽然我本人认为其写的相当糟糕),但正好看到了:http://download.fltxt.com/txt/yuqingnian.txt
小说文本如下:

先前处理过英文小说的简单文本挖掘,这次来处理一下中文的,因为中文文章编码分词和英文不同,比如虽然unnest_tokens 可以非常厉害的识别大多数词,可还是对于庆余年这样的名称无法识别:
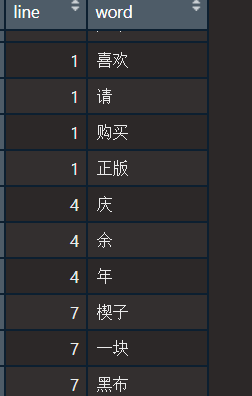
这次使用jiebaR 包处理。
首先是汉字编码,选择GB18030 :
如果需要处理中文停用词,这里有个网站:
https://github.com/elephantnose/characters/blob/master/stop_words
处理起来还是稍有不同,不过眼前一亮的是,发现readr 包似乎是个不错的替代基础包读文本的工具,read_file 读10M 左右文本,瞬间就读取了:
p_load(rvest, readr, pengToolkit, wordcloud2, jiebaR, tidytext, dplyr, janeaustenr); beepr::beep(sound = "coin")wk <- worker()mytxt <- readr::read_file("yuqingnian.txt", locale = locale(encoding = "GB18030")) # 按汉字编码,读取文本words <- segment(mytxt, wk) # 读取文字,获得字符串类型tail(sort(table(words)))tab <- sort(table(words), decreasing = T) # 倒序排tab2 <- tab[nchar(names(tab)) > 1] # 去掉单个字内容
看看排名靠前的内容:
> knitr::kable(head(tab2))|words | Freq||:-----|-----:||范闲 | 19735||自己 | 12398||没有 | 11307||说道 | 10247||知道 | 7998||什么 | 6964|# 当然还有少不了的云图wordcloud2(head(tab2, 500))

果然,范闲才是老大啊!
详细学习jiebaR
参见:https://zhuanlan.zhihu.com/p/35846130
此外,再来康康worker() 函数的详细用法:
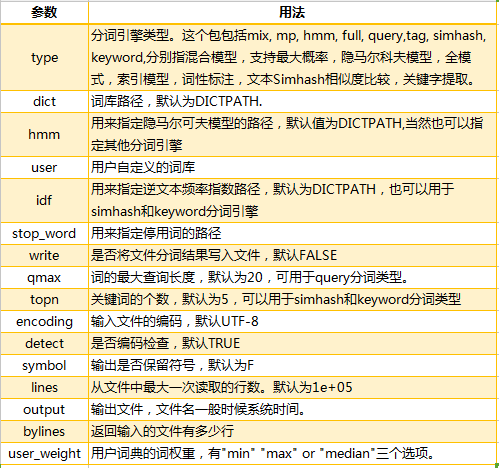
segment 函数:

自定义词库
- 手动设置自定义词句

- 借助外部txt 文件
搜狗提供了大量的专业领域词汇,其词库具有专门的.scel格式,词库导出与导入非常麻烦,这时,需要用到搜狗细胞词库转化包cidian,它不仅能够在R中将搜狗词库的scel格式转化为可读的词库,并且还能直接被分词包jiebaR调用!但需要注意的是:cidian包没有发布在CRAN,而是发布在github中,所以需要先获得开发者工具Rtools才能进行安装,也要用到install_github()函数。第一次安装cidian包的时候,果然又有遇到问题,哎,还好又被我各种探索给解决了,直接上干货吧!
#安装cidian包,时间会有点点长~install.packages("devtools") #R的开发者工具install.packages("stringi") #强大的字符处理包install.packages("pbapply") #能够为*apply族函数增加进度条install.packages("Rcpp")install.packages("RcppProgress")#Rcpp和RcppProgress让R直接调用外部的C++程序,增加运算速度library(devtools)install_github("qinwf/cidian") #用来从github上安装R包的函数,“qinwf”应该是cidian的作者library(cidian)# ps:貌似cidian 包暂时用不了了
搜狗词库:https://pinyin.sogou.com/dict/
这里有个在线词库转换网站:https://cidian.shinyapps.io/shiny-cidian/
> decode_scel(scel = "./杭州市城市信息精选.scel",cpp = TRUE)output file: ./杭州市城市信息精选.scel_2018-04-19_00_57_55.dict# 重点来了,把搜狗词典文件改名,从杭州市城市信息精选.scel_2018-04-19_00_57_55.dict到user.dict.utf8,然后替换D:/R/R-3.4.4/library/jiebaRD/dict目录下面的user.dict.utf8。这样默认的用户词典,就是搜狗词典了,可以检验下新的user.dict.utf8:
jiebaR 自带图库含义:
jieba.dict.utf8, 系统词典文件,最大概率法,utf8编码的hmm_model.utf8, 系统词典文件,隐式马尔科夫模型,utf8编码的user.dict.utf8, 用户词典文件,utf8编码的stop_words.utf8,停止词文件,utf8编码的idf.utf8,IDF语料库,utf8编码的jieba.dict.zip,jieba.dict.utf8的压缩包hmm_model.zip,hmm_model.utf8的压缩包idf.zip,idf.utf8的压缩包backup.rda,无注释model.rda,无注释README.md,说明文件
设置停止词
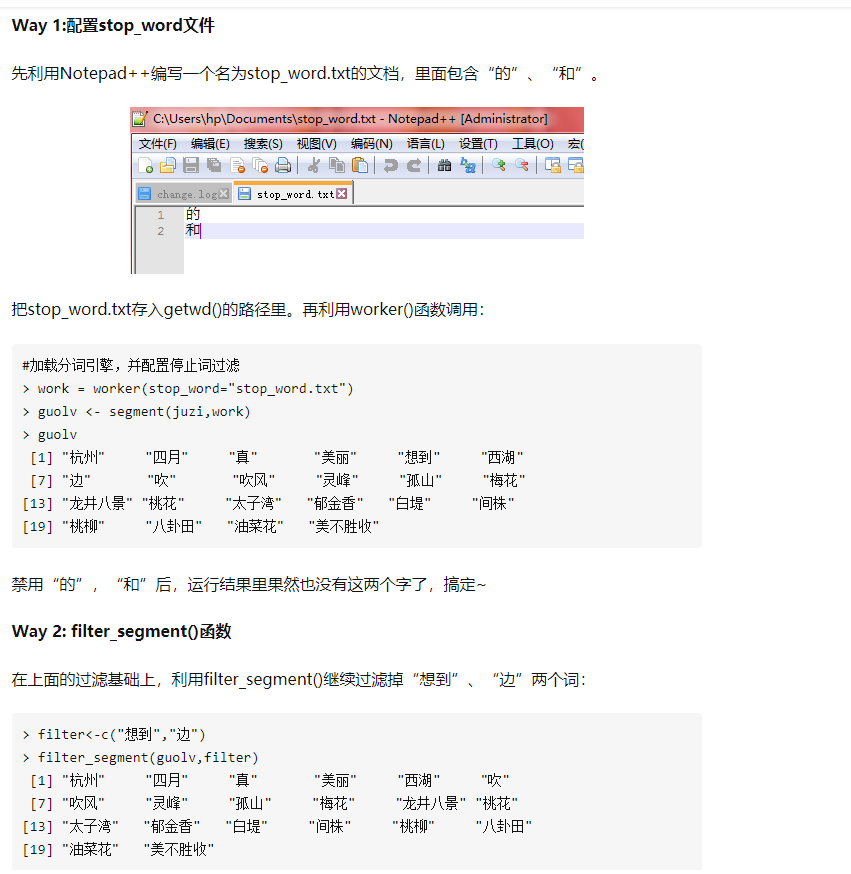
获得词条中的关键词

主要使用函数vector_keywords :
> keys <- worker("keywords",topn=5)> vector_keywords(guolv,keys)11.8212 11.7392 11.7392 11.7392 11.7392"灵峰" "太子湾" "桃柳" "间株" "八卦田"
如果感兴趣,未来能不能开发属于自己的文本分词算法呢?

若有收获,就点个赞吧
0 人点赞
