描述数据整体情况的四个数据:

Skewness is a measure of how asymmetric is the distribution, kurtosis is a measure of how spiky is it.
均值与中位数
中位数是最棒的:
其不会收到数据极值的影响。
比如:
> a <- c(1, 2, 520, 660, 526, 623, 862, 753, 720, 890, 12568)> median(a)[1] 660> mean(a)[1] 1647.727
但如果是去除极值再计算均值,也是可以的:
> mean(a, trim = 0.2)[1] 666.2857
这里trim 表示:
在a的首尾各去除11*0.2 (近似为2,共4)个数据。
可见,通过去除首尾4个数据后,均值已经和原来的中位数非常接近了。
偏差
- 平均偏差
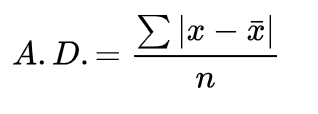
- 中位数偏差

- 四分位差inter-quartile range
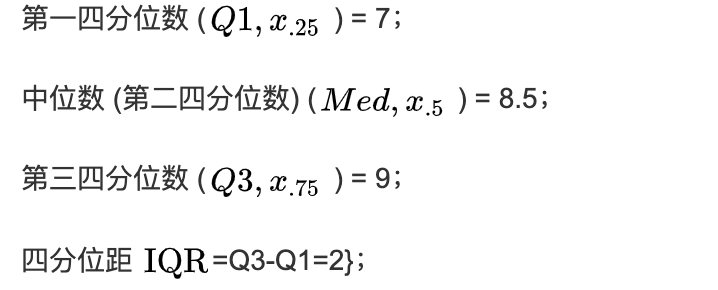
方差
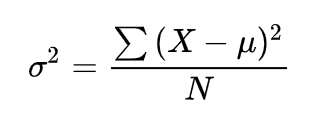
开根就是平均差。
- 变异系数

当需要比较两组数据离散程度大小的时候,如果两组数据的测量尺度相差太大,或者数据量纲的不同,直接使用标准差来进行比较不合适,此时就应当消除测量尺度和量纲的影响。
其实也可以直接归一化处理。
中心化与归一化
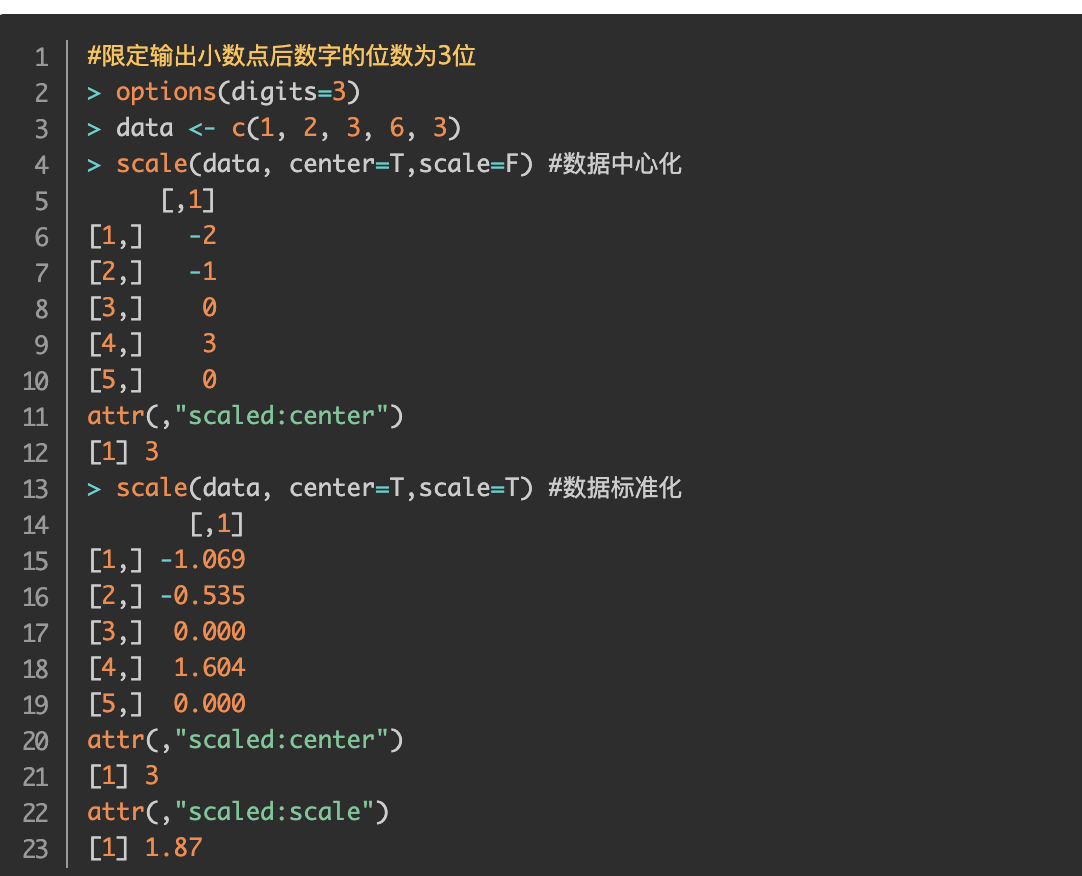
https://www.jianshu.com/p/fc82ae05feb9
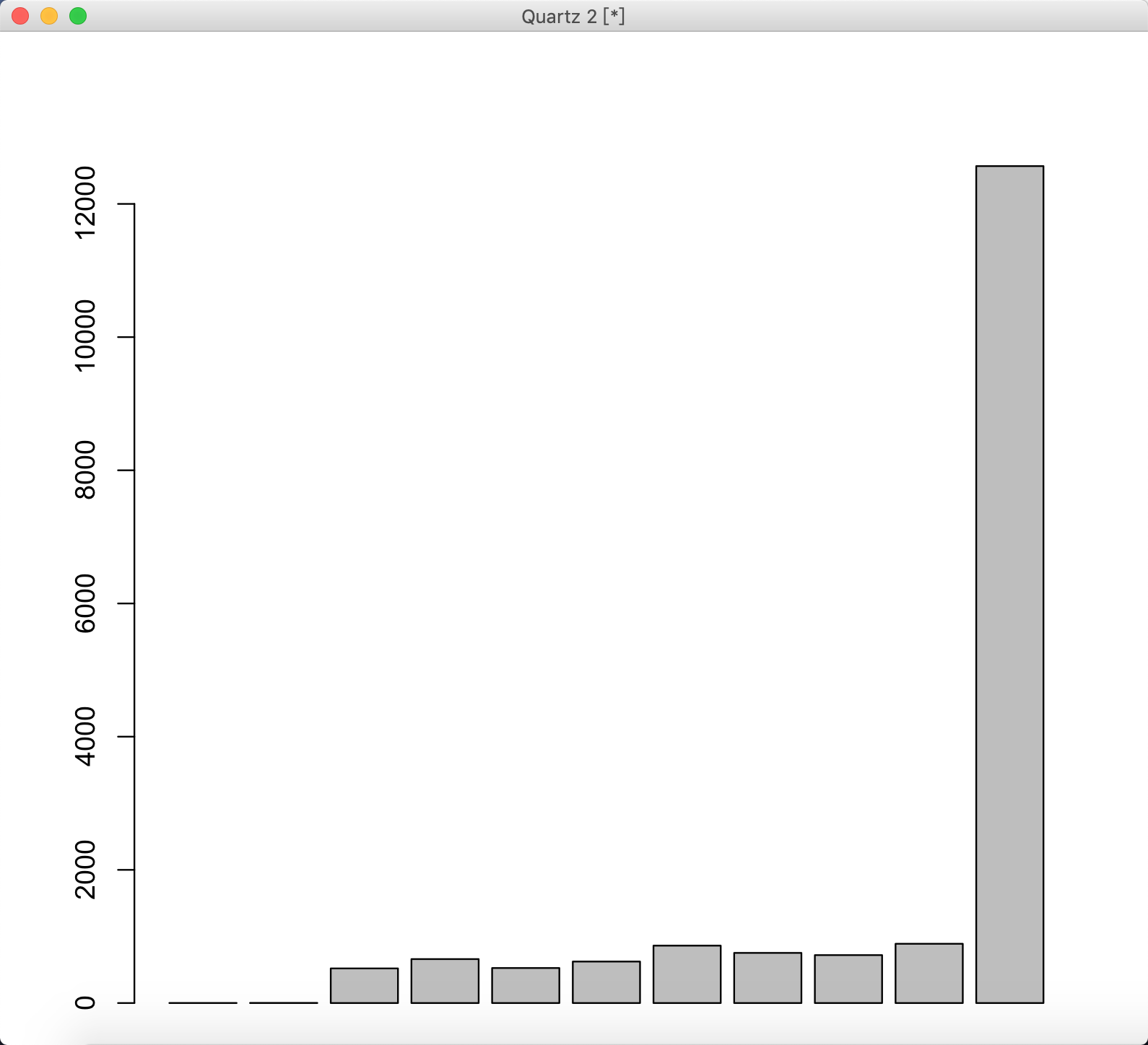
描述数据分布


描述数据分布的图
- 箱线图
- 茎叶图

- 直方图/条带图

若有收获,就点个赞吧
0 人点赞
