1. 因为向量化,我选择R

我们的所有操作,都可以对向量的每一个元素执行。
同样的操作也可以用来取子集:

- 一些使用的注意事项
一般来说,c() 是创建向量的语法,但R 也提供了一些例外:
可不要因为它们养成坏习惯了哦。

2. 尽可能的向量化
我觉得下面的内容讲的更全:
https://www.yuque.com/mugpeng/rr/01r-de-bian-cheng-xiao-lu
这里提一下Vectorize函数,可以将标量(接受单一参数的)函数转换为向量化形式:
if_else_statement <- function(vec_element) {if(vec_element == "Fire") {vec_element = "hot"} else {vec_element = "cold"}return(vec_element)}vectorized_if_else <- base::Vectorize(if_else_statement)test001 <- c(rep("Fire", 100000), rep("Ice", 200000))system.time(sapply(test001, if_else_statement))system.time(vectorized_if_else(test001))system.time(ifelse(test001 == "Fire", "hot", "cold"))
这里顺便再比较了另外两种向量化操作的方式:
> system.time(sapply(test001, if_else_statement))用户 系统 流逝0.471 0.036 0.669> system.time(vectorized_if_else(test001))用户 系统 流逝0.434 0.020 0.572> system.time(ifelse(test001 == "Fire", "hot", "cold"))用户 系统 流逝0.070 0.005 0.086
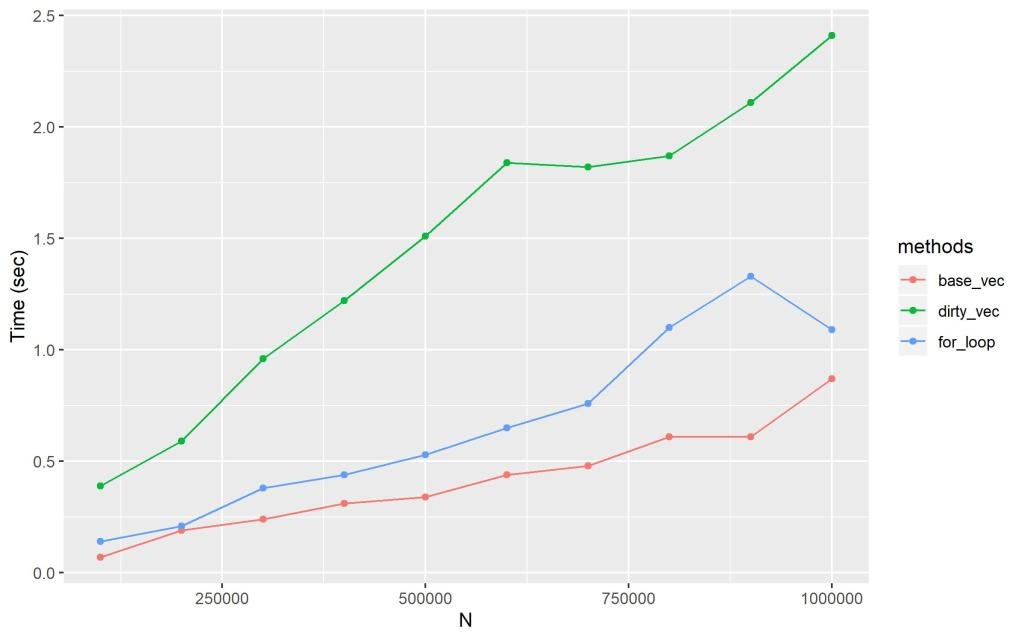
可见还是尽量不要用Vectorize 做向量化操作呀。
3. 非向量化的情况
- 输入为上一次输出
但其实有的如cumsum cumprod 等也考虑到了一些基本的运算。
- 应对策略
尽量避免循环和嵌套次数。
4. 过度向量化问题
- apply 的本质
我竟然一直喜爱的apply 其实是:
A common reflex is to use a function in the apply family. This is not vectorization, it is loop-hiding. The apply function has a for loop in its definition.

- 内存的消耗

所以本质还是空间与时间的tradeoff。
- 是否需要优化我的代码
当然了。
但如果,花两小时时间将lapply 修改为doLapply 就为了提高脚本0.1s 的速度,我劝你还不如打两把游戏。
5. 记住这句话

若有收获,就点个赞吧
0 人点赞
