先前介绍了用py 的bs4 和requests 库爬虫获取静态网站数据的方法:
这里通过李东风的书进行简单的学习。
首先进入网站:
http://www.sse.com.cn/market/sseindex/indexlist/s/i000001/const_list.shtml

接着选择检查,通过检查找到<table class="tablestyle"> 处:
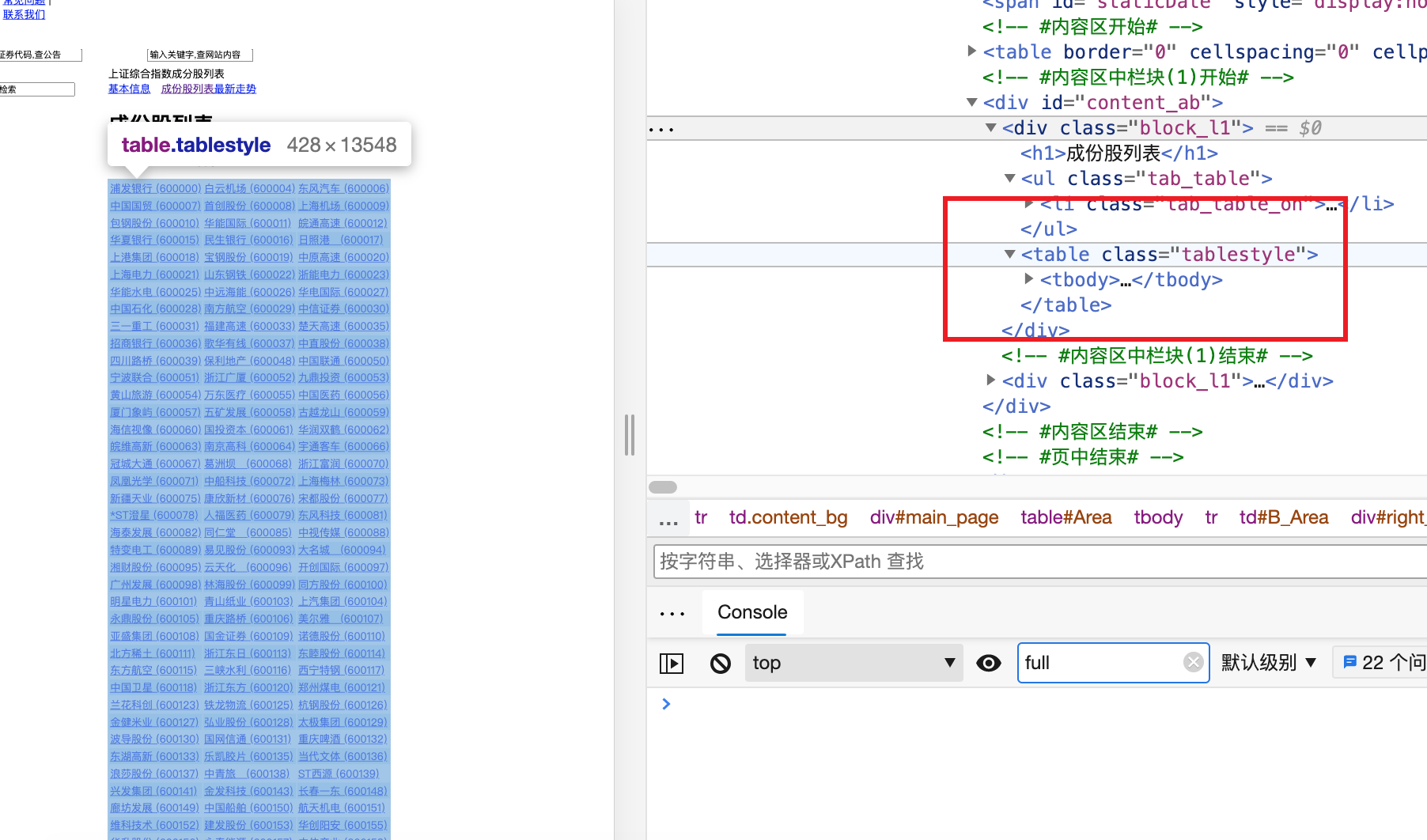
选择复制XPath:
接着就能获得下面的字符串信息:
## 得到如下的 xpath 地址//*[@id="content_ab"]/div[1]/table
接着用 rvest 的 html_nodes() 函数提取页面中用 xpath 指定的成分:
> library(rvest)> nodes <- html_nodes(read_html(urlb), xpath=xpath)
简单探索了一下html_nodes 获得的对象:
> nodes{xml_nodeset (1)}[1] <table class="tablestyle">\n<tr bgcolor="white">\n<td class="table3"><a h ...> class(nodes)[1] "xml_nodeset"
用 html_table() 函数将 HTML 表格转换为数据框,结果是一个数据框列表,因为仅有一个,所以取列表第一项即可。程序如下:
tables <- html_table(nodes)restab <- tables[[1]]
可见返回的是一个列表,列表的每个元素都是一个tibble 类型数据框:
> tables <- html_table(nodes)> tables[[1]]# A tibble: 521 x 3X1 X2 X3<chr> <chr> <chr>1 "浦发银行\r\n (60… "白云机场\r\n (60… "东风汽车\r\n (60…2 "中国国贸\r\n (60… "首创股份\r\n (60… "上海机场\r\n (60…3 "包钢股份\r\n (60… "华能国际\r\n (60… "皖通高速\r\n (60…4 "华夏银行\r\n (60… "民生银行\r\n (60… "日照港 \r\n (6…5 "上港集团\r\n (60… "宝钢股份\r\n (60… "中原高速\r\n (60…6 "上海电力\r\n (60… "山东钢铁\r\n (60… "浙能电力\r\n (60…7 "华能水电\r\n (60… "中远海能\r\n (60… "华电国际\r\n (60…8 "中国石化\r\n (60… "南方航空\r\n (60… "中信证券\r\n (60…9 "三一重工\r\n (60… "福建高速\r\n (60… "楚天高速\r\n (60…10 "招商银行\r\n (60… "歌华有线\r\n (60… "中直股份\r\n (60…# … with 511 more rows> typeof(tables)[1] "list"> class(tables[[1]])[1] "tbl_df" "tbl" "data.frame"
接下来,批量对数据框处理,删除\r\n 字符。

若有收获,就点个赞吧
0 人点赞
