参见:https://blog.csdn.net/weixin_38008864/article/details/108138494
https://www.jianshu.com/p/6abaf3167cfe
直接安装即可。还有一本专门介绍的书:
https://www.tidytextmining.com/
简单尝试
我们这里先创建一个简单的数据框,两列,一列是记录,一列是具体的文本:
poem <- c("Roses are red,", "Violets are blue,","Sugar is sweet,", "And so are you.")poem_df <- tibble(line = 1:4, text = poem)> poem_df# A tibble: 4 x 2line text<int> <chr>1 1 Roses are red,2 2 Violets are blue,3 3 Sugar is sweet,4 4 And so are you.
我们可以使用函数unnest_tokens:
该函数可以将指定数据框中的列中的文本进行全部拆分:
- tbl 数据框
- output 输出内容列名
- input 输入内容列名
> unnest_tokens(tbl = poem_df,output = word,input = text)# A tibble: 13 x 2line word<int> <chr>1 1 roses2 1 are3 1 red4 2 violets5 2 are6 2 blue7 3 sugar8 3 is9 3 sweet10 4 and11 4 so12 4 are13 4 you
接着我们可以删去一些常见的词,例如英语中的“the”,“of”,“to”等等。我们可以用一个删除停用词(保存在tidytext数据集中stop_words):
> stop_words# A tibble: 1,149 x 2word lexicon<chr> <chr>1 a SMART2 a's SMART3 able SMART4 about SMART5 above SMART6 according SMART7 accordingly SMART8 across SMART9 actually SMART10 after SMART# ... with 1,139 more rows> anti_join(result, stop_words)Joining, by = "word"# A tibble: 6 x 2line word<int> <chr>1 1 roses2 1 red3 2 violets4 2 blue5 3 sugar6 3 sweet
接着就是简单的计数统计:
> table(h$word)blue red roses sugar sweet violets1 1 1 1 1 1
开始实战
我本来打算用简奥斯汀的小说来挖掘,刚好有个包:
library(janeaustenr)> original_books <- austen_books()> head(original_books)# A tibble: 6 x 2text book<chr> <fct>1 "SENSE AND SENSIBILITY" Sense & Sensibility2 "" Sense & Sensibility3 "by Jane Austen" Sense & Sensibility4 "" Sense & Sensibility5 "(1811)" Sense & Sensibility6 "" Sense & Sensibility> table(original_books$book)Sense & Sensibility Pride & Prejudice Mansfield Park12624 13030 15349Emma Northanger Abbey Persuasion16235 7856 8328
然而觉得这样就索然无味了,就是需要原生的txt 文本从数据清洗开始处理才有意思:
http://www.qcenglish.com/ebook/239.html
这里以《简爱》为例子:

简单的看看排名靠前的非常见词文本:
p_load(rvest, pengToolkit, wordcloud2, jiebaR, tidytext, dplyr, janeaustenr); beepr::beep(sound = "coin")# 读取全部文本lines <- readLines("Jane Eyre - Charlotte Bronte.txt")# 将向量转为tibbletext_df <- tibble(line = 1:length(lines), text = lines)# 拆分所有语句,获得文字内容result <- unnest_tokens(tbl = text_df,output = word,input = text)# 删除常见词result <- anti_join(result, stop_words)# 统计词频率table(result$word)door reed time day bessie miss54 65 66 67 86 149
还可以画个云图:
# 云图可视化结果top_gene_freq_db <- as.data.frame(sort(table(result$word), decreasing = T))wordcloud2(subset(top_gene_freq_db, Freq >= 20))
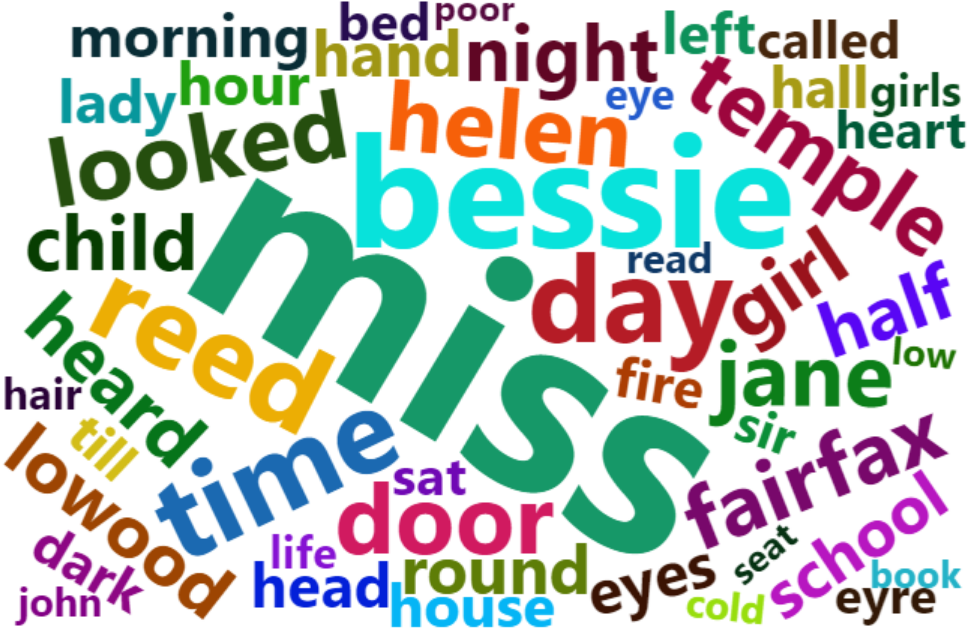
还是非常简单的!

若有收获,就点个赞吧
0 人点赞
