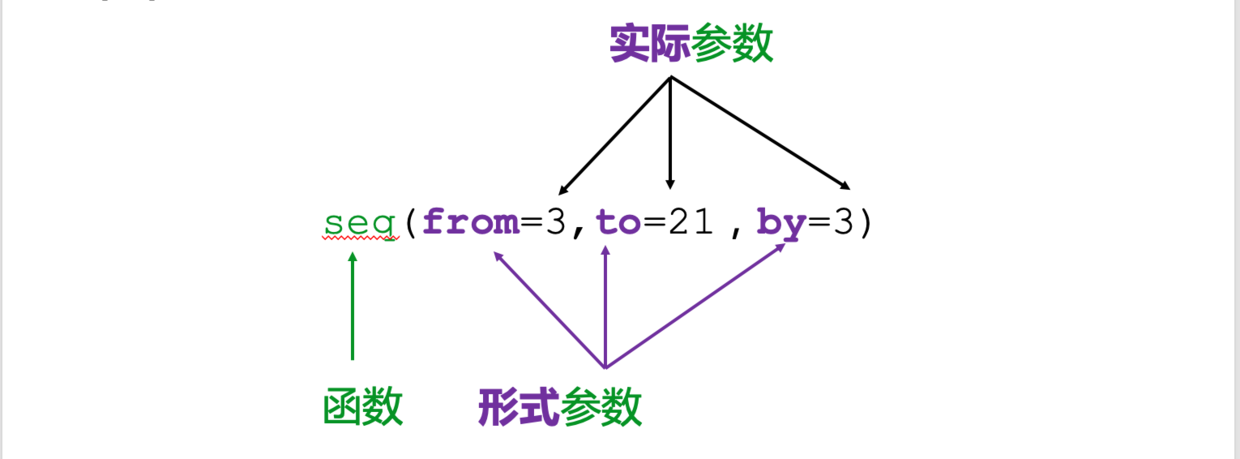
定义函数
函数定义使用function关键字,一般格式为:
函数名
<-function(形式参数表) 函数体
定义函数有一定的规范性,在定义与调用时都不能省略圆括号。
实际上, “function(参数表) 函数体”这样的结构本身也是一个表达式, 其结果是一个函数对象。 在通常的函数定义中, 函数名只不过是被赋值为某个函数对象, 或者说是“绑定”(bind)到某个函数对象上面。 同一个函数对象可以被多个函数名绑定。 函数是普通R对象, 在编程语言术语中称这样的函数为第一级函数(first class functions), 或函数是第一级对象(first class objects), 即函数在R语言中与其他普通数值型对象、字符型对象有相同的地位。
因为函数也是R对象, 也可以拥有属性。 所谓对象, 就是R的变量所指向的各种不同类型的统称。
可以将多个函数存放在一个列表中。 例如,在用随机模拟比较不同的统计模型时, 常常将要对一组数据采用的多个并行的建模函数存放在列表中, 对许多组模拟数据的每一组用循环的方法应用列表中的每一个建模函数分别得到结果。
创建与使用函数
- 函数创建可以没有参数
hello <- function(){print("Hi there!")TRUE}hello()
- R 的向量化调用
我们可以直接为某个参数传入一个向量,R 会自动的遍历整个向量并在函数中执行并返回一个新的向量:
> my_f = function(x){ x*3 }> my_f(c(1,2,3,4,5))[1] 3 6 9 12 15
- R 的默认参数
和py 一样,R 也可以指定缺省值,有缺省值的形式参数在调用时可以省略对应的实参, 省略时取缺省值。
- R 的参数顺序
R函数调用时全部或部分形参对应的实参可以用“形式参数名=实参”的格式给出, 这样格式给出的实参不用考虑次序, 不带形式参数名的则按先后位置对准。
function(x, y){c("The first one is", x, "The second one is", y)}> my_f(3,4)[1] "The first one is" "3" "The second one is"[4] "4"> my_f(y = 3, x = 4)[1] "The first one is" "4" "The second one is"[4] "3"> my_f(y = 3, 4)[1] "The first one is" "4" "The second one is"[4] "3"
作为好的程序习惯, 调用R函数时, 如果既有按位置对应的参数又有带名参数, 应仅有一个或两个是按位置对应的, 按位置对应的参数都写在前面, 带名参数写在后面, 按位置对应的参数在参数表中的位置应与定义时的位置一致。 在定义函数时,没有缺省值的参数写在前面, 有缺省值的参数写在后面。 不遵守这样的约定容易使得程序被误读, 有时会在运行时匹配错位。
- 函数的递归调用
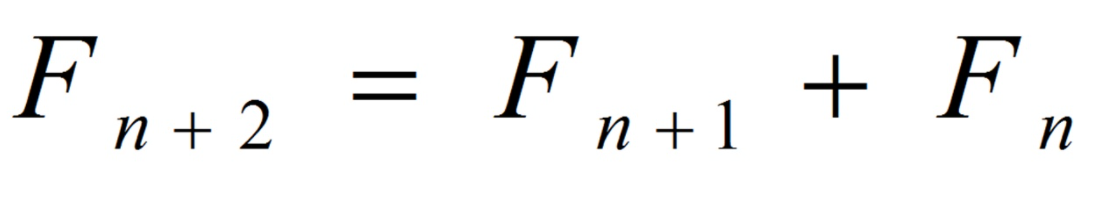
最经典的斐波那契数列,在python 中我们通过在函数中引用函数自身来表示递归调用,R 也同样可以实现:
fib1 <- function(n){if(n == 0) return(0)else if(n == 1) return(1)else if(n >=2 ) {fib1(n-1) + fib1(n-2)}}> for (i in 1:5) print(fib1(i))[1] 1[1] 1[1] 2[1] 3[1] 5
但这样定义有个问题,当我们的原先的函数改名了,使用新被定义的函数执行代码,就会发生报错了:
> tmp = fib1> fib1 = 1> tmp(3)Error in fib1(n - 1) : 没有"fib1"这个函数
函数的返回值
- 函数体中最后的表达式为函数返回值
> my_f = function(x){ x+1;x*3 }> my_f(3)[1] 9
如果需要指定,可以使用return(y)的方式在函数体的任何位置退出函数并返回y的值。
> my_f = function(x){ return(x+5); print("This won't be printed")}> my_f(5)[1] 10
- invisible 可以让R命令行直接调用此函数时不自动显示返回值
> my_f = function(x){if (x > 0) x else invisible(x)}> my_f(5)[1] 5> my_f(-2)
当预期返回的结果显示无意义或者显示在命令行会产生大量的输出时可以用此方法。
函数的组成部分
一个自定义R函数由三个部分组成:
- 函数体
body(),即要函数定义内部要执行的代码; formals(),即函数的形式参数表以及可能存在的缺省值;environment(),是函数定义时所处的环境, 这会影响到参数表中缺省值与函数体中非局部变量的的查找。
> my_fn = function(x,y=100) x+y> environment(my_fn)<environment: R_GlobalEnv>> body(my_f){x * 3}> body(my_fn)x + y> formals(my_fn)$x$y[1] 100
注意,函数名并不是函数对象的必要组成部分。
R提供了一个非常方便的函数alist用来构建参数列表。我们可以像定义函数一样很简单地指定参数列表。
> f <- function(x, y=1, z=2) { x + y + z}> formals(f) <- alist(x=, y=100, z=200)> args(f)function (x, y = 100, z = 200)NULL
函数的使用技巧
- 向量化与效率
关于程序效率,请比较如下两个表达式:
n/(n-1)/(n-2)*sum( (x - xbar)^3 ) / S^3n/(n-1)/(n-2)*sum( ((x - xbar)/S)^3 )
ps:虽然能够理解这种S 表达式先后处理的差异,可是这个除了n 次还是无法理解啊。
这两个表达式的值相同。 表面上看,第二个表达式更贴近原始数学公式, 但是在编程时, 需要考虑计算效率问题, 第一个表达式关于S只需要除一次, 而第二个表达关于S除了n次, 所以第一个表达式效率更高。 一个函数如果仅仅用几次, 这些细微的效率问题不重要, 但是如果要编写一个R扩展包提供给许多人使用, 程序效率就是重要的问题。
- 部分匹配
在调用函数时, 如果以“形参名=实参值”的格式输入参数, 则“形参名”与定义时的形参名完全匹配时最优先采用; 如果“形参名”是定义时的形参名的前一部分子串, 即部分匹配, 这时调用表中如果没有其它部分匹配, 也可以输入到对应的完整形参名的参数中; 按位置匹配是最后才进行的。 有缺省值的形参在调用时可省略。
部分匹配允许我们节省一丁点儿键入工作量(狂喜),但确实实在不严谨,虽然R 默认是纵容我们这种行为的,但我们可以选择设置发出警告:
options(warnPartialMatchArgs = TRUE)> my_f = function(asd){asd}> my_f(a = 3)[1] 3Warning message:In my_f(a = 3) : 'a'部分匹配为'asd'
- do.call 与管道符号
do.call 可以对列表对象进行处理,相当于将列表中的所有元素作为参数进行处理:
> do.call(mean, list(3,4,5))[1] 3
而magrittr包中的%>% 管道符号,则可以很方便的表现出步骤执行的顺序,可以参见:
比如说对数据框类型的数据处理时使用。

若有收获,就点个赞吧
0 人点赞
