参见:https://docs.ropensci.org/RSelenium/articles/basics.html
关于基本的配置,参见:
除了自行下载java 文件外,也可以通过docker 容器安装:
docker run -d -p 4445:4444 selenium/standalone-firefox:2.53.1
总的来说,就把RSelenium 的操作想像成真实人类的操作。只不过,它比我们更有耐心,也更灵巧(你让它访问一千个网页,也是洒洒水啦~)。
先启动一下:
library(RSelenium)remDr <- remoteDriver(remoteServerAddr = "localhost",port = 4444L,browserName = "chrome")
1. 基本浏览
有以下函数:
- remDr$open() 打开浏览器
- remDr$getStatus() 查看状态
- remDr$navigate(“http://www.google.com/ncr”)) 打开选定网页
- remDr$goBack()/goForward() 上一页/下一页
- remDr$getCurrentUrl() 返回当前网址
- remDr$refresh() 刷新页面
2. 选择页面中的元素
以HTML 界面为例,网页信息存储的格式,一般是HTML、XHTML、XML…
<!DOCTYPE html><html><body><h1>My First Heading</h1><p>My first paragraph.</p></body></html>
其实我们并不需要掌握具体的语法逻辑,现在的浏览器检查功能,可以帮助我们非常好的获取相关的内容信息:
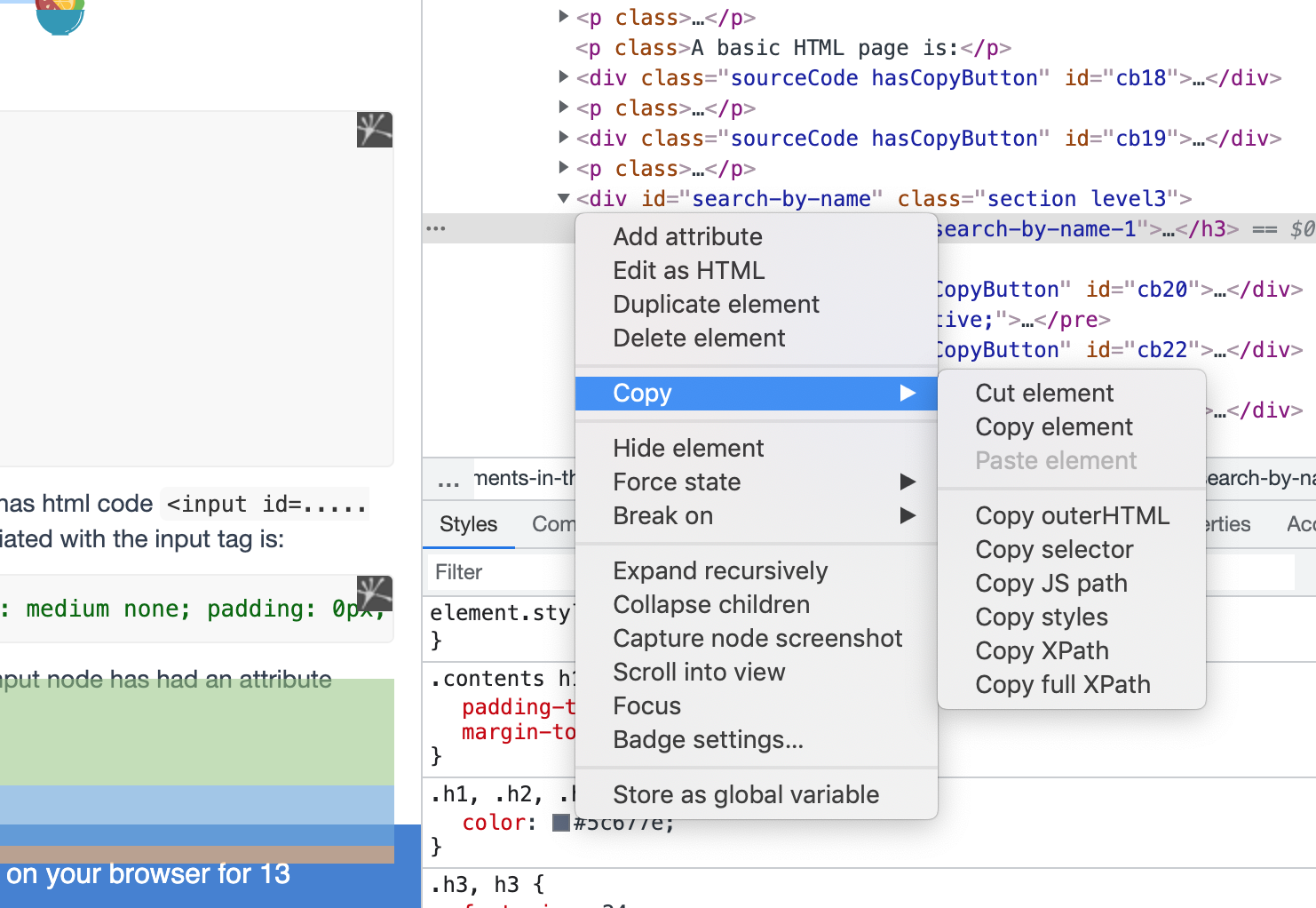
对应的参数选项:

比如下面这段标签:
<input spellcheck="false" dir="ltr" style="border: medium none; padding: 0px; margin: 0px; height: auto; width: 100%; background: transparent url("data:image/gif;base64,R0lGODlhAQABAID/AMDAwAAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw%3D%3D") repeat scroll 0% 0%; position: absolute; z-index: 6; left: 0px; outline: medium none;" aria-autocomplete="both" role="combobox" aria-haspopup="false" class="gsfi" id="lst-ib" maxlength="2048" name="q" autocomplete="off" title="Search" value="" aria-label="Search" type="text">
以XPath 为例:
webElem <- remDr$findElement(using = "xpath", "//input[@id = 'lst-ib']")
接下来,我们可以通过该标签,获得其其他的属性:
webElem$getElementAttribute("name")## [[1]]## [1] "q"
- webElem$compareElements(webElem2)
比较两个标签元素是否相同。
- webElems$getElementText()
3. 与界面交互
输入文本
比如我们通过findElement 函数获得了搜索框元素,接着就可以通过sendKeysToElement 函数以列表的格式向其输入内容:
remDr$navigate("http://www.baidu.com/")remDr$getCurrentUrl()webElem <- remDr$findElement(using = "xpath", '//*[@id="kw"]')webElem$highlightElement("sad")webElem$sendKeysToElement(list("R Cran"))
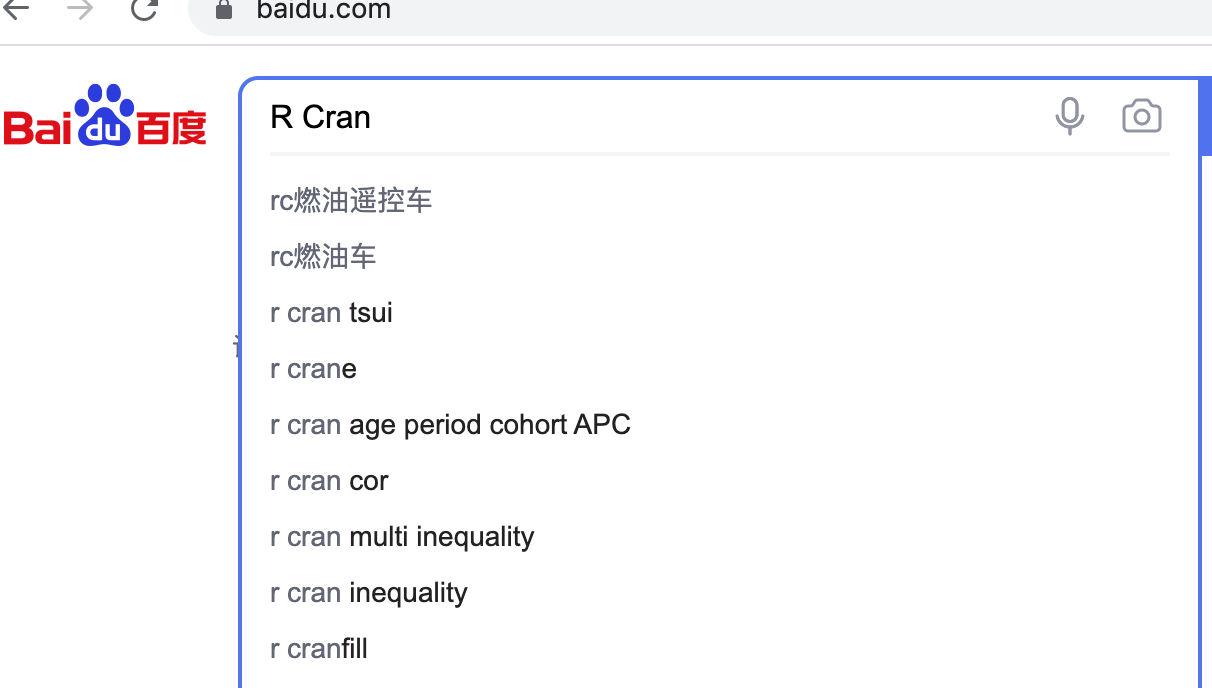
如果我们需要确认搜索内容的话:
# utf-8 formatwebElem$sendKeysToElement(list("R Cran", "\uE007"))# human word formatwebElem$sendKeysToElement(list("R Cran", key = "enter"))
鼠标点击
- sebElem$clickElement
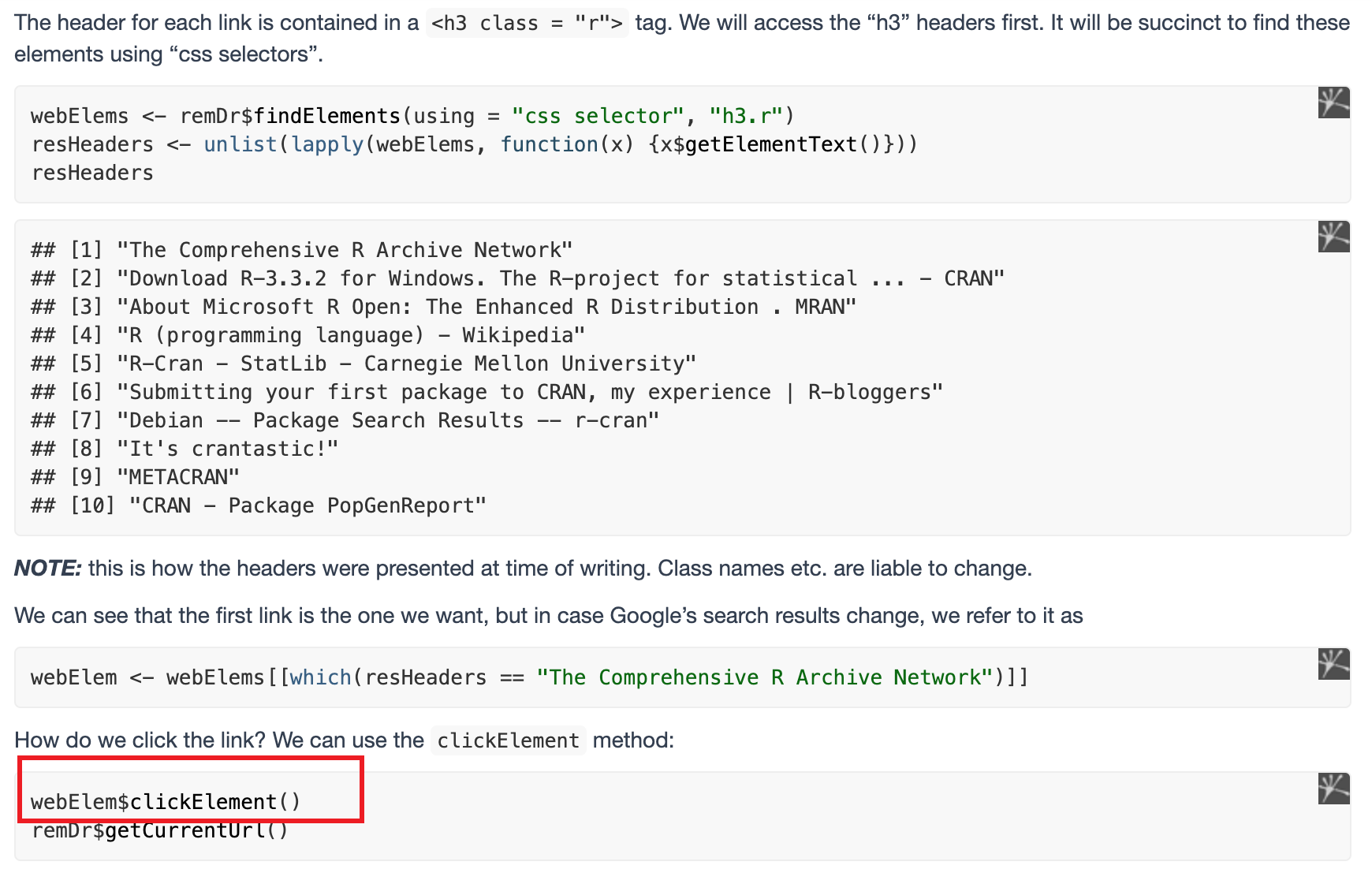
获得坐标与移动鼠标
- getElementLocation 获得元素所在坐标:
> webElem[[1]]$getElementLocation()[c("x","y")]$x[1] 402.2656$y[1] 535
- 移动+点击
remDr$mouseMoveToLocation(webElement = webElems[[1]]) # move mouse to the element we selectedremDr$click(2) # 2 indicates click the right mouse button
获得浏览器窗口信息
- 获得浏览器handle 信息:

- 获得标题remDr$getTitle()
4. 批量操作
- findElements 批量获取全部的元素
webElem <- remDr$findElements(using = "partial link text", '京')
其返回一个列表,列表中的每一个元素,就是findElement 所有匹配的标签对象。
我们可以使用循环函数处理它们,比如高亮:
sapply(webElem, function(x){x$highlightElement(1)})
5. 高级技巧:使用javascript
y1s1,如果真的要花式玩转网页,还真得要点JS 功夫。
主要是通过remDr$executeScript 执行。
作者举了两个栗子。
- 隐藏图片
首先检查goople 主图标有无隐藏。
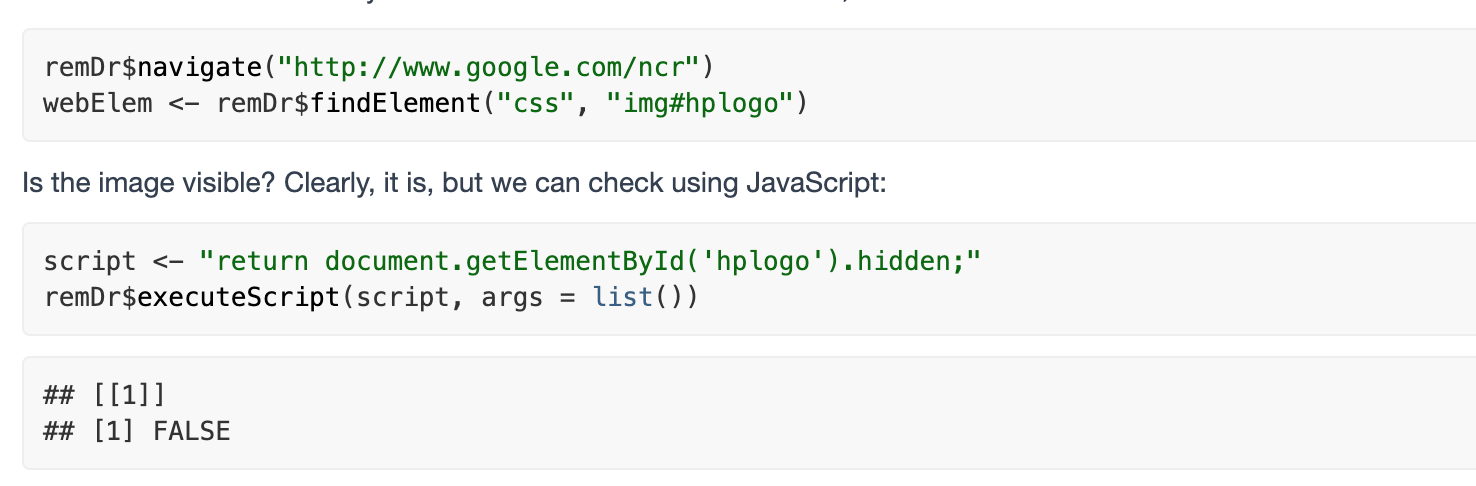
接着是隐藏它:
script <- "document.getElementById('hplogo').hidden = true;return document.getElementById('hplogo').hidden;"remDr$executeScript(script, args = list())## [[1]]## [1] TRUE
获得元素,类似remDr$findElement:

- 以及异步(async)操作:
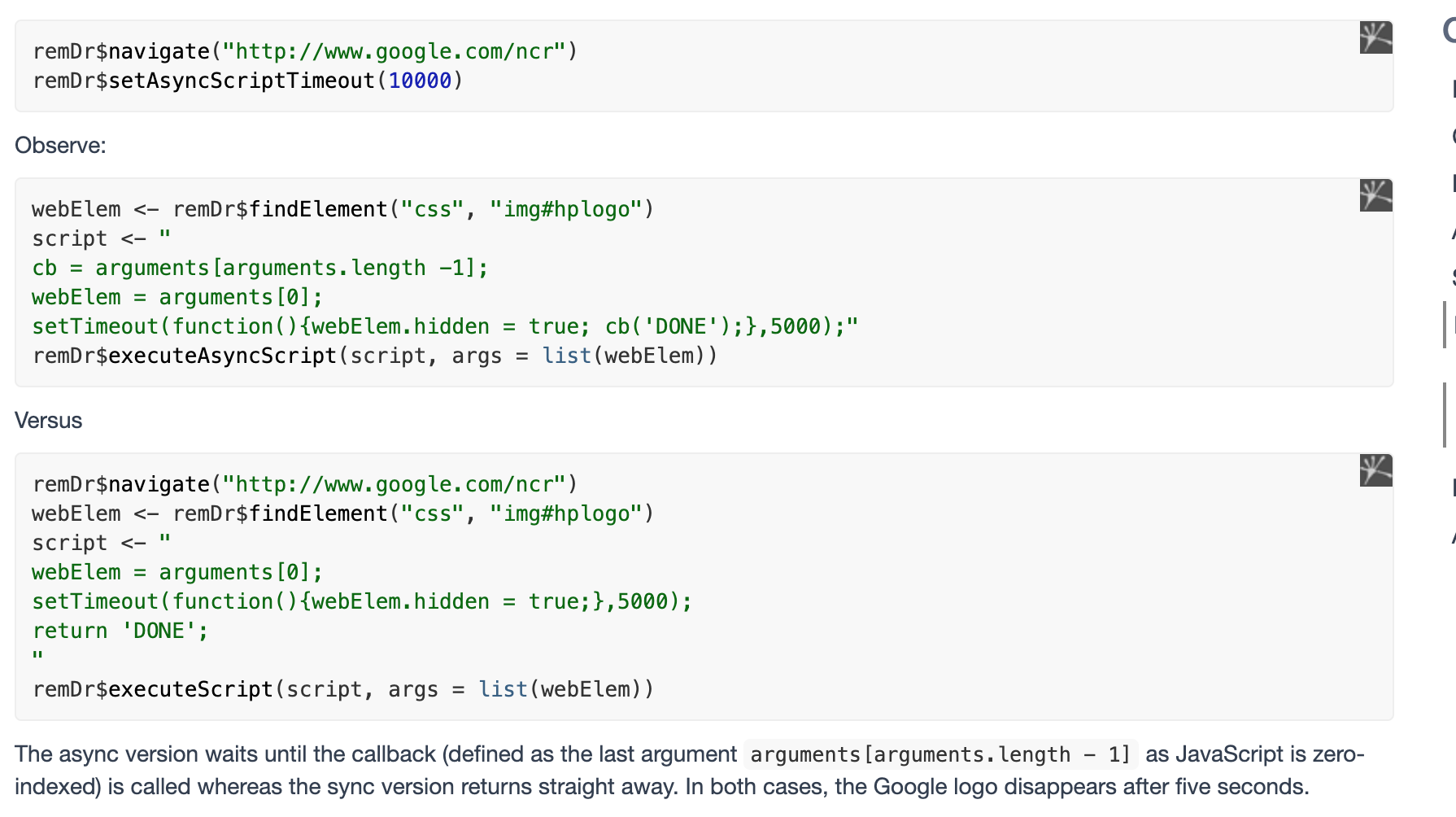
其他骚操作
- webElem$highlightElement() (通过remDr$findElement)
说明书写的是,会在网页中高亮出标签,可实际操作并未发生任何反应。
西卡西!
非常骚的是,当我在括号中随便打了串数字之后:
remDr$navigate("http://www.baidu.com/")remDr$getCurrentUrl()webElem <- remDr$findElement(using = "xpath", '//*[@id="form"]/span[1]')webElem$highlightElement("sad")

别说,还挺好看~
- 截图
设置全尺寸+ 截图:
remDr$maxWindowSize()remDr$screenshot(display = TRUE)
- 不完全匹配查找
remDr$navigate("http://www.baidu.com/")remDr$getCurrentUrl()webElem <- remDr$findElement(using = "partial link text", 'Cookie')webElem$highlightElement("sad")

这些文字匹配不就得了?这还要学html 语法干啥?

若有收获,就点个赞吧
0 人点赞
