这里强调的还是纯文本,如果是csv, 或tsv 可以使用下面的一些命令:
几个常用的导入字符串数据的函数
输入
- readLines()
从文件中导入,默认按照换行符分隔每行,参数如下:
cona connection object or a character string.ninteger. The (maximal) number of lines to read. Negative values indicate that one should read up to the end of input on the connection.oklogical. Is it OK to reach the end of the connection before n > 0 lines are read? If not, an error will be generated.warnlogical. Warn if a text file is missing a final EOL or if there are embedded nuls in the file.encodingencoding to be assumed for input strings. It is used to mark character strings as known to be in Latin-1 or UTF-8: it is not used to re-encode the input. To do the latter, specify the encoding as part of the connection con or via options(encoding=): see the examples.skipNullogical: should nuls be skipped?
- readline()
可以从终端中获得文本。
输出
输出到文件
- 各种的write 函数
什么write.table…
- writeLines函数将字符串向量输出到文件中
类似readLines,对向量文本操作,也可以指定输出文本的分隔符: writeLines(a,con="D:/test.txt",sep="\t")
- pdf,png…
用来将图片结果输出到文件:
pdf("..")plot(..)dev.off()
相当于将本来输出到屏幕/画板的内容,重输出到文件。
- sink
类似pdf 这些图片重输出函数,sink 用于将打印到屏幕的文本重输出:
sink("hello.txt") # 将输出重定向到hello.txtcat("hello")sink() # 结束重定向
- cat
其不仅可以实现类似print 的打印功能,还可以实现追加的效果:
sink("hello.txt") # 将输出重定向到hello.txtcat("1st")sink()cat("hello")hellocat("hello",file="test.txt",append=T)> c <- readr::read_file("test.txt")> c[1] "[1] \"1st\"\nhello"
append 参数表示将内容追加,否则会覆盖。
输出到屏幕
- print()
输出文本,会带有标注:
> print(1:5)[1] 1 2 3 4 5> 1:5[1] 1 2 3 4 5
默认下直接输入对象,会自动调用print 方法输出。
这个小知识点在循环中还是很不同的,比如参考:
在循环中想要输出对象到屏幕,需要使用print 的。
- cat()
> cat(1:5)1 2 3 4 5
cat 的输出结果并不会带编号。
# cat默认以空格分割,如果不想用,可通过sep参数自定义设置。> xx = c(2,1,34,12,24,34)> cat(xx,sep=c(",",".","/","?","\n"))2,1.34/12?2434
scan 的使用
一看scan 的参数选项,就知道它有多强了:
scan(file = "", what = double(), nmax = -1, n = -1, sep = "",quote = if(identical(sep, "\n")) "" else "'\"", dec = ".",skip = 0, nlines = 0, na.strings = "NA",flush = FALSE, fill = FALSE, strip.white = FALSE,quiet = FALSE, blank.lines.skip = TRUE, multi.line = TRUE,comment.char = "", allowEscapes = FALSE,fileEncoding = "", encoding = "unknown", text, skipNul = FALSE)
参见:https://baijiahao.baidu.com/s?id=1609781727359063276&wfr=spider&for=pc
https://my.oschina.net/stephenyng/blog/537399
我们先尝试使用最简单的scan 命令,读取下下面的文本内容:
test <- scan("test.txt", what = "c")# what 表示用何种类型数据,本例中表示用向量读取
一些参数如下:
1) what:声明读入为字符类型数据,可能指定读入的精度/类型,例如:what=integer(0);what=numeric(0);what=character(0);另外what 还可以指定list,c 等# 也可以进一步简化,如0 表示数字,"" 表示字符串2) SEP:指定各个读入的数据之间的分隔符;默认情况下分隔符:空格、tab;如果不是其它分隔符,例如“:/”通过SEP来指定;3) 可以通过list指定读入变量的变量名,同时生成的对象为列表,则可以同时读入字符与数字;4) Skip 从第几行开始读入数据;5) Nlines 指定最大读入行数;6) 如果通过键盘输入的时候,不希望出现下标提示,则可以使用:quiet=TRUE;7) encoding =””指定的编码格式,有时候读入的中文可能会出现乱码的时候,可能通过这个参数来指定:Latin-1 或者 UTF-8;
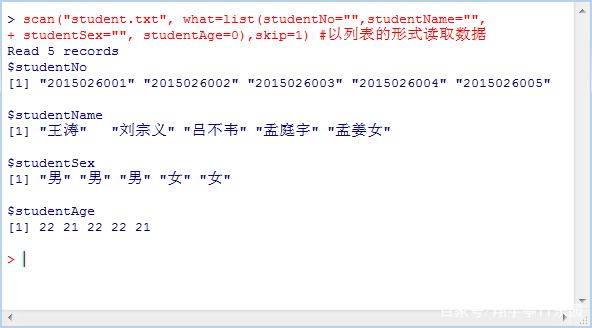
再比如以列表形式读如数据:
scan("student.txt", what = list(studentNo="", studentName="", studentSex="", studentAge=0), skip=1)
scan 还可以实现readline 这样从屏幕读取文本的效果 :
其实scan 通过分隔符的指定,也可以实现read.csv 这般高级函数:

若有收获,就点个赞吧
0 人点赞
