参考:
https://blog.csdn.net/weixin_38008864/article/details/107572648#:~:text=purrr%E5%8C%85%E6%98%AFR%E8%AF%AD%E8%A8%80%E4%B8%AD%E6%8F%90%E9%AB%98%E4%BB%A3%E7%A0%81%E6%95%88%E7%8E%87%E7%9A%84%E5%8C%85%EF%BC%8C%E5%B8%B8%E8%A7%81%E7%9A%84%E5%87%BD%E6%95%B0%E6%9C%89%20purrr%3A%3Amap%20%28.x%2C.f%29%20%E5%AF%B9x%E5%AE%9E%E8%A1%8Cf%E6%93%8D%E4%BD%9C%20purrr%3A%3Amap2,%28.x%2C%20y%2C.f%29%20%E5%AF%B9x%E5%92%8Cy%E5%AE%9E%E8%A1%8Cf%E6%93%8D%E4%BD%9C%20purrr%3A%3Apmap%20%28.l%2C.f%29%20%E5%AF%B9%E5%A4%9A%E7%BB%B4%E5%88%97%E8%A1%A8l%E5%AE%9E%E8%A1%8Cf%E6%93%8D%E4%BD%9C
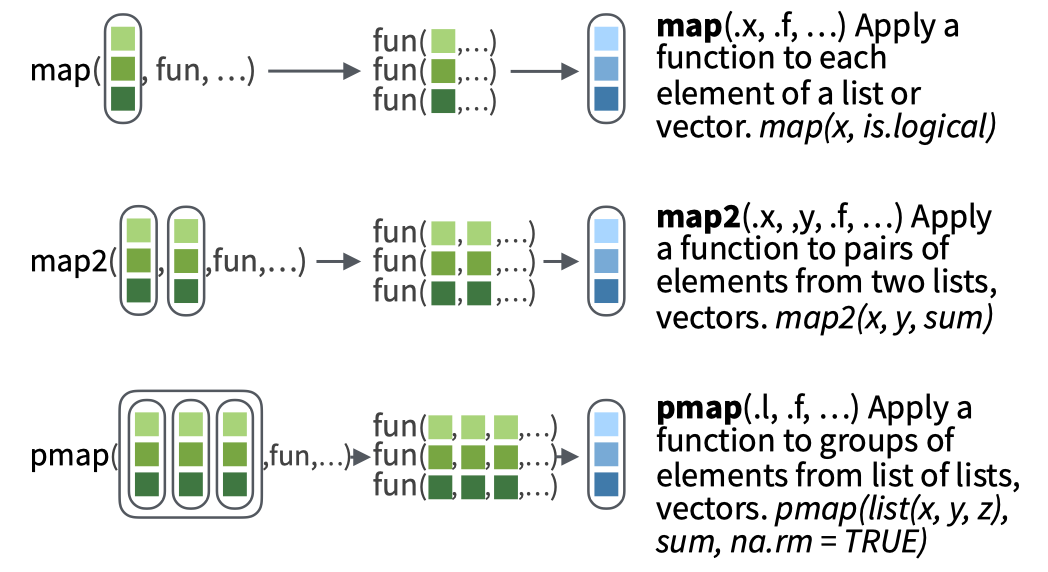
R语言tidyverse中的purrr包含三个向量化操作函数。
其实这个函数跟lapply 函数挺像的。不过用起来比较直观。
purrr::map(.x, .f) 对x实行f操作purrr::map2(.x, y, .f) 对x和y实行f操作purrr::pmap(.l, .f) 对多维列表l实行f操作
比如map 就是对向量操作,而map2 可以对两个向量,如果需要对多个向量,可以用pmap。
比如:
infos <- tibble(family=c("张", "李", "王", "赵"),name=c("三", "四", "五", "六"),born=c(1990, 1992, 2000, 1985))
我们可以用map2 拼接姓名:
> unlist(purrr::map2(infos$family, infos$name, paste0))[1] "张三" "李四" "王五" "赵六"
但其实这个包,和直接的向量化处理也没多大差别啊:
> paste0(tmp$family, tmp$name)[1] "张三" "李四" "王五" "赵六"
但感觉处理其列表,性能可能更强一些吧。

若有收获,就点个赞吧
0 人点赞
