视图 View
视图是数据库并不存在的一张表,数据库中的表相关的查询结果在其他地方用到,那就可以考虑将这个结果保存到视图中。
基本语法
create view viewname as-- 查询语句
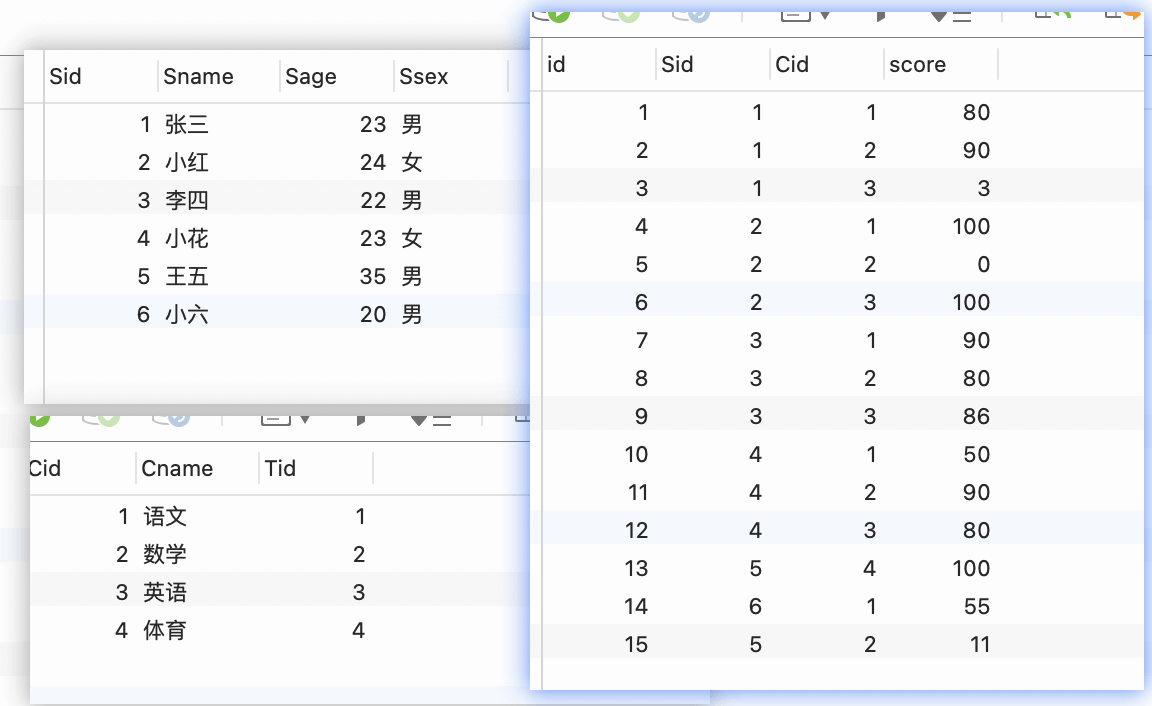
根据上面三张表,可以查询每个同学的相关成绩信息;
select scholar.sid,sname,sage,ssex,cname,score from scholarinner join scon scholar.sid = sc.sidinner join courseon sc.cid = course.cid;
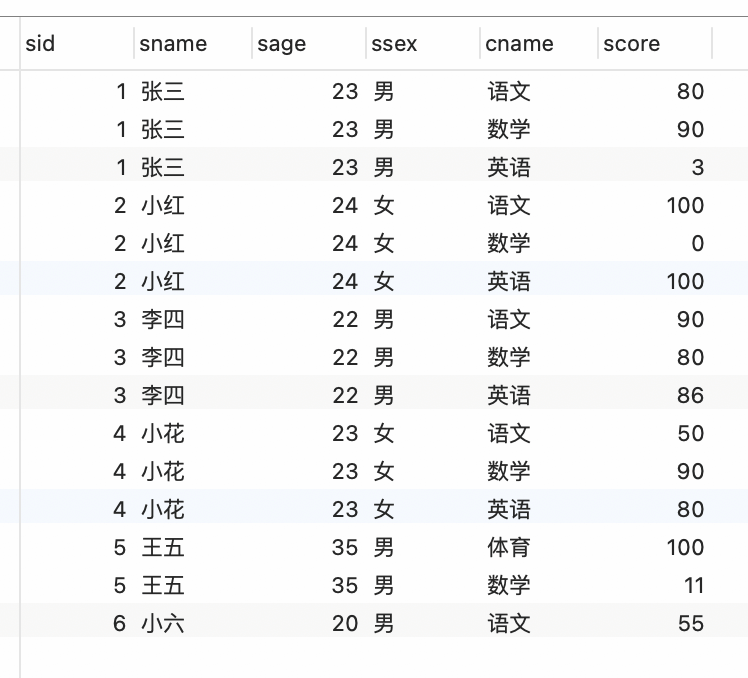
如果要将查询出来的结果保存起来; 可以创建视图;
将上面查询出来的结果保存为视图 students_score;
create view students_score as-- 查询语句select scholar.sid,sname,sage,ssex,cname,score from scholarinner join scon scholar.sid = sc.sidinner join courseon sc.cid = course.cid;
创建好之后,可以在视图中查看;
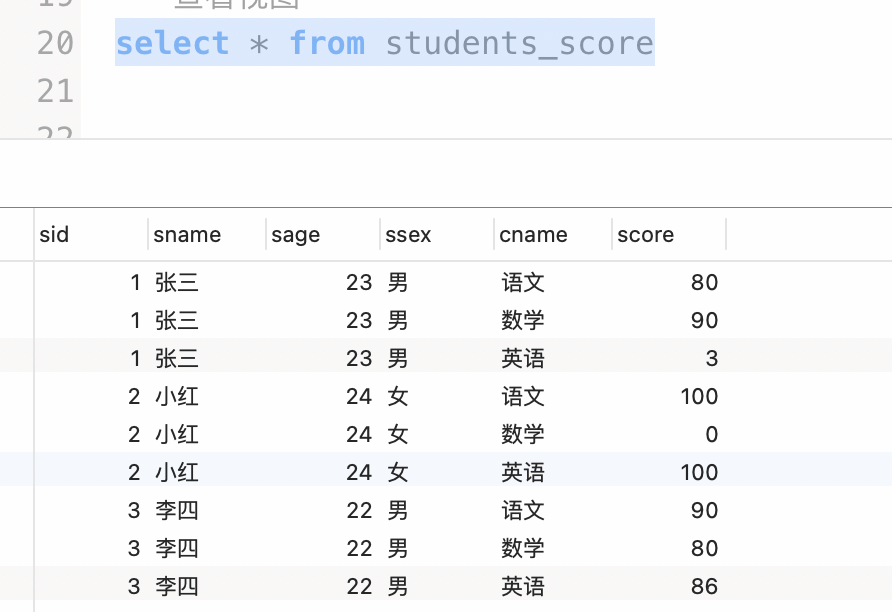
查看视图中的内容
select * from students_score;
练习
创建表 users_xxxx; | id | name | job | | —- | —- | —- | | 1 | 王大锤 | 总经理 | | 2 | 张大发 | 经理 | | 3 | 小明 | 员工 | | 4 | 小王 | 员工 | | 5 | 小花 | 员工 | | 6 | 小红 | 员工 |
创建视图 emps_view_xxxx; 视图中只保存员工信息
- 创建视图 manager_view_xxx; 视图中只保存员工,经理信息
- 修改视图 emps_view_xxxx中数据, 将Name字段前添加 “张”, 比如原来是小明, 改完后就变为 张小明
- 删除manager_view_xxx 中 name 为
小明的数据, 请问可以删除吗?
CREATE table users_zhuyuanying(`id`int(11)not null auto_increment,`name`VARCHAR(50)not null,`job`varchar(10)not NULL,primary key(`id`));INSERT into `users_zhuyuanying`(`name`,`job`)VALUES("王大锤","总经理"),("张大发","经理"),("小明","员工"),("小王","员工"),("小花","员工"),("小红","员工");CREATE VIEW emps_view asselect * FROM users_zhuyuanyingWHERE job="员工";select * FROM viewzhuyuanying;CREATE VIEW manageview asselect * FROM users_zhuyuanyingWHERE job in ("员工","经理");select * FROM viewzhuyuanying2;UPDATE viewzhuyuanyingset NAME="张小王"WHERE id=4;UPDATE emps_viewSET name = CONCAT("张",name)WHERE job = "员工";SELECT * from emps_view;delete from manageviewwhere name="张小明";
视图和表之间的关系
- 视图中的数据来源于表;
- 视图中数据使用update或者 delete 之后 会将结果同步更新到表中; 其他保存有相同数据的视图也会被更新;
视图的应用场景
- 权限管理系统中,举个例子,管理后台中,不同权限的用户登录成功之后看到的结果不一样。可以给不同的权限人员创建不同的视图;比如 经理视图中 可以看到自己手下员工的信息;
存储过程
在批量执行某些sql语句的时候可以创建存储过程。存储过程中可以写其他sql语句。
基本语法
create procedure
将下面语句封装到存储过程中; ```sql — 声明结束符号 delimiter // — 创建存储过程 insert1w 为存储过程名 CREATE PROCEDURE query_high_score() BEGIN
SELECT sc.Sid,sname,sum(score) from scholar,scWHERE scholar.Sid=sc.SidGROUP BY sc.Sidhaving SUM(score) = (select sum(score) from scGROUP BY sidorder by sum(score) descLIMIT 1);
END // — 结束存储过程
— 声明结束符号 改为原来的 ; delimiter ;
CALL query_high_score();
<a name="n9Shh"></a>## 练习[orders.sql](https://www.yuque.com/attachments/yuque/0/2021/sql/87080/1632639809003-63eb5011-43c7-44d5-bedf-cb939a57f773.sql?_lake_card=%7B%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2021%2Fsql%2F87080%2F1632639809003-63eb5011-43c7-44d5-bedf-cb939a57f773.sql%22%2C%22name%22%3A%22orders.sql%22%2C%22size%22%3A2514%2C%22type%22%3A%22%22%2C%22ext%22%3A%22sql%22%2C%22status%22%3A%22done%22%2C%22taskId%22%3A%22u2697a829-934a-498b-98d7-d67663cbdfe%22%2C%22taskType%22%3A%22upload%22%2C%22id%22%3A%22u111582d1%22%2C%22card%22%3A%22file%22%7D)<br />1. 查询最近10天的订单信息,并将查询保存为 存储过程,存储过程名字 near10day_xxxxx;```sql-- 1. 查询最近10天的订单信息select * from orderswhere datediff(now(),create_at)<=10;-- 2. 设置存储过程-- 声明结束符号delimiter //-- 创建存储过程CREATE PROCEDURE near_10days_orders_xxxx()BEGINselect * from orderswhere datediff(now(),create_at)<=10;END// -- 结束存储过程-- 声明结束符号 改为原来的 ;delimiter ;
创建完存储过程之后,使用 关键字 call 来调用即可。
call near_10days_orders_xxxx();
- 批量插入1万条数据到数据库中; ```sql
— 声明结束符号 delimiter // — 创建存储过程 insert1w 为存储过程名 CREATE PROCEDURE insert1w() BEGIN DECLARE num int; — 声明变量 num 为int 类型 set num =1; — 设置num 的初始值为 1 WHILE num <=1000 DO insert into users_zhuyuanying (name, job) VALUES (CONCAT(“test”,num),”员工”); set num = num+1; — 更改num的值,比原来增加1
END WHILE;
END // — 结束存储过程
— 声明结束符号 改为原来的 ; delimiter ;
— 调用存储过程 CALL insert1w();
---<a name="IzNZH"></a># 索引当数据量特别大的时候,添加索引可以提高**查询**效率;<a name="cVsut"></a>## 基本语法```sqlALTER TABLE 表名ADD INDEX `索引的名称`(`字段名`);
- 给users表 name添加索引, 索引名为 name_index;
alter table usersadd index `name_index`(name);
面试问题
- 数据库中有使用过存储过程吗? 怎么用的?
使用过。
场景1:
在做性能测试过程中,需要创建一些测试账号。本质上就是数据库user表中添加多条数据,可以用存储过程来实现。
场景2:
做一些图表类的相关测试时,或者一些常用的多表查询,将这些查询语句定义在存储过程中,使用的时候通过调用存储过程来实现。
不过平时我们在测试的过程中,给我们数据库账号有权限限制,只有查询权限。这些存储过程也是开发写好,我直接去调用。不过,让我写的话。。。。。。。
- 视图有有用过吗?跟存储过程有什么区别?
有,用的不多。
view 视图 只能将select 查询结果存到视图中。
procedure 存储过程 可以存储 select,update,delete,insert 这些语句。
view中的内容可以被修改,删除,也可以添加。
存储过程只能使用 call 来调用。
- 如何快速的往数据库中添加多条数据?
- 使用存储过程。
- 使用代码的方式。
- 数据库查询速度比较慢解决方案有哪些?
- 排查sql查询编写语法是否规范,比如 count(*), count(1);
- 添加索引;
- 修改数据库配置,或者分库分表;
- 实在不行更换服务器配置;
思维导图


若有收获,就点个赞吧
0 人点赞
