pytest 官网说明文档: https://docs.pytest.org/en/7.1.x/
公司中,做接口测试,优先考虑接口的正常场景能够跑通,也就是先做接口串联,因为在实际的公司业务场景中,用户的操作大多数都是正常场景。优先保证正常场景的业务流是ok的。
单接口也是需要考虑。一些主要的接口 要考虑异常场景。
异常场景中接口是同一个,测试数据不一样。可以考虑将不同数据组合在一起进行测试。
单接口测试

以新建主题接口为例,这个接口在整个网站业务场景 使用最多。 需要考虑异常场景。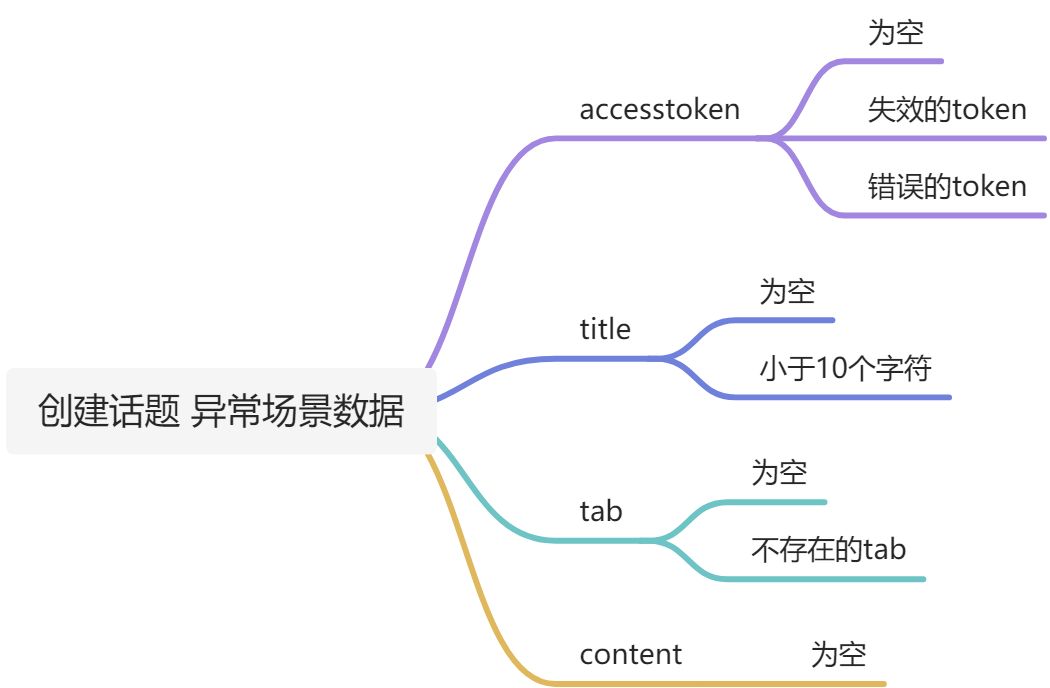
需要将这些数据进行不同的排列组合, 每个场景都进行覆盖。
pytest 的参数化功能
pytest 我们是用来做用例管理的,在做单接口测试的时候,不同的数据中,一条数据就是一个测试用例。 有多少条数据 生成多少个测试用例。
pytest 提供内置功能可以快速进行参数化。
pytest 官网提供了参数功能的代码样例。https://docs.pytest.org/en/7.1.x/how-to/parametrize.html
基本使用
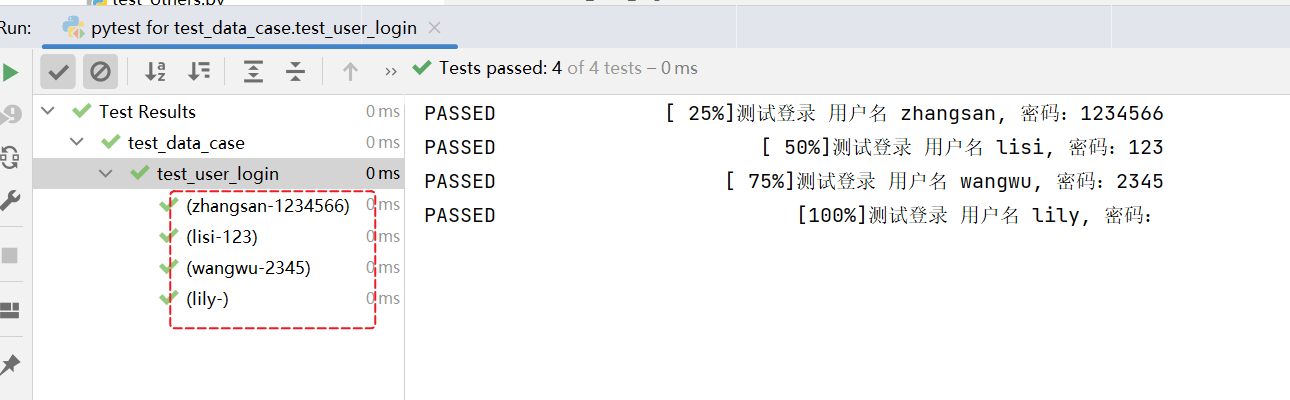
# 导入pytest 模块import pytest@pytest.mark.parametrize("username,passwd",[("zhangsan","1234566"),("lisi","123"),("wangwu","2345"),("lily","")])def test_user_login(username,passwd):print(f"测试登录 用户名 {username}, 密码:{passwd}")
- @pytest.mark.parametrize 这个是固定,固定放在测试用例上面。
"username,passwd"参数名称,这里有 “” 表示字符串,里面可以随意命名- 但是要跟后面数据个数保持一致。
- test_user_login(username,passwd) 测试用例中
username,passwd保持一致。

创建话题的异常场景
可以借助使用pytest参数化功能来进行参数化。
基本操作
import requests
testdata = [
("","123456","ask",""),
("e18de36f-d9ce-47e6-a2aa-1cf6508ec10b",'',"ask","xxxxx")
]
@pytest.mark.parametrize("token,title,tab,content",testdata)
def test_create_topic(token,title,tab,content):
url = "http://47.100.175.62:3000/api/v1/topics"
bodydata = {
"accesstoken":token,
"title":title,
"tab":tab,
"content":content
}
r = requests.post(url=url,json=bodydata)
print(r.json())
添加断言结果
不同的请求参数,服务器返回的结果也是不一样的。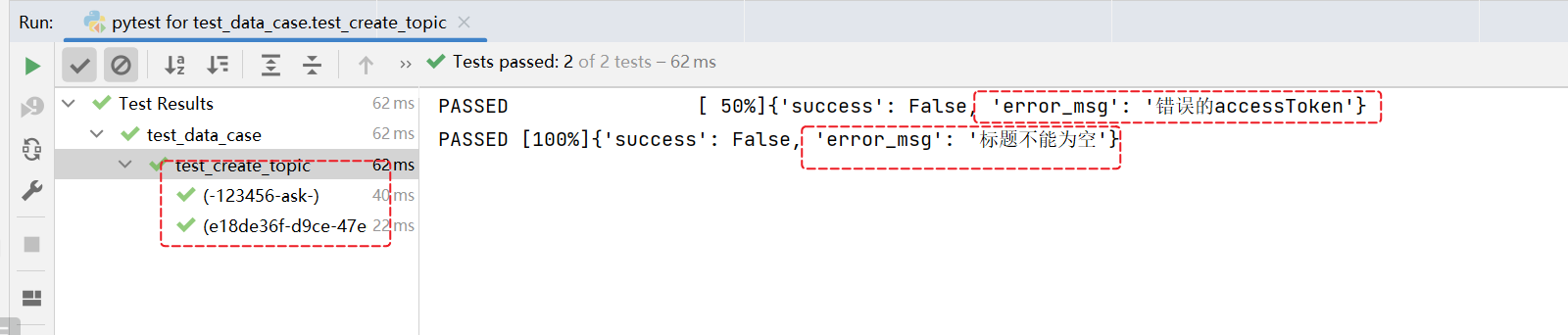
也可以将请求数据对应的断言结果添加到数据中。
添加断言,就是再加一个数据进来即可。
import requests
testdata = [
("","123456","ask","","错误的accessToken"),
("e18de36f-d9ce-47e6-a2aa-1cf6508ec10b",'',"ask","xxxxx","标题不能为空")
]
@pytest.mark.parametrize("token,title,tab,content,errmsg",testdata)
def test_create_topic(token,title,tab,content,errmsg):
url = "http://47.100.175.62:3000/api/v1/topics"
bodydata = {
"accesstoken":token,
"title":title,
"tab":tab,
"content":content
}
r = requests.post(url=url,json=bodydata)
print(r.json())
# 添加断言
assert r.json()["error_msg"] == errmsg
循环生成测试数据
先提供可能的场景数据,使用for 循环来生成测试数据。
tokens =["","e18de36f-d9ce-47e6-a2aa-1cf6508ec10","e18de36f-d9ce-47e6-a2aa-1cf6508ec10b","240d17fe-9a54-4d78-b73d-7600af599174"]
titles = ["","1234","1234567890"]
tabs=["ask","share","dev","job","","jk"]
contents = ["","xxxx"]
#存放所有的数据
all_case_data = []
for token in tokens:
for title in titles:
for tab in tabs:
for content in contents:
# 每次循环,生成一条数据
casedata = (token,title,tab,content)
# 将生成的数据放在all_case_data中
all_case_data.append(casedata)
print(all_case_data)
@pytest.mark.parametrize("token,title,tab,content",all_case_data)
def test_create_topic(token,title,tab,content):
url = "http://47.100.175.62:3000/api/v1/topics"
bodydata = {
"accesstoken":token,
"title":title,
"tab":tab,
"content":content
}
r = requests.post(url=url,json=bodydata)
print(r.json())
# 添加断言
# assert r.json()["error_msg"] == errmsg
- 这个例子中只是把接口参数数据可能场景 数据生成,还没添加断言,所以先把断言注释掉。下一步再添加断言。
执行,可以看到执行效果,可以看到生成很多测试数据,只有3秒就执行完了。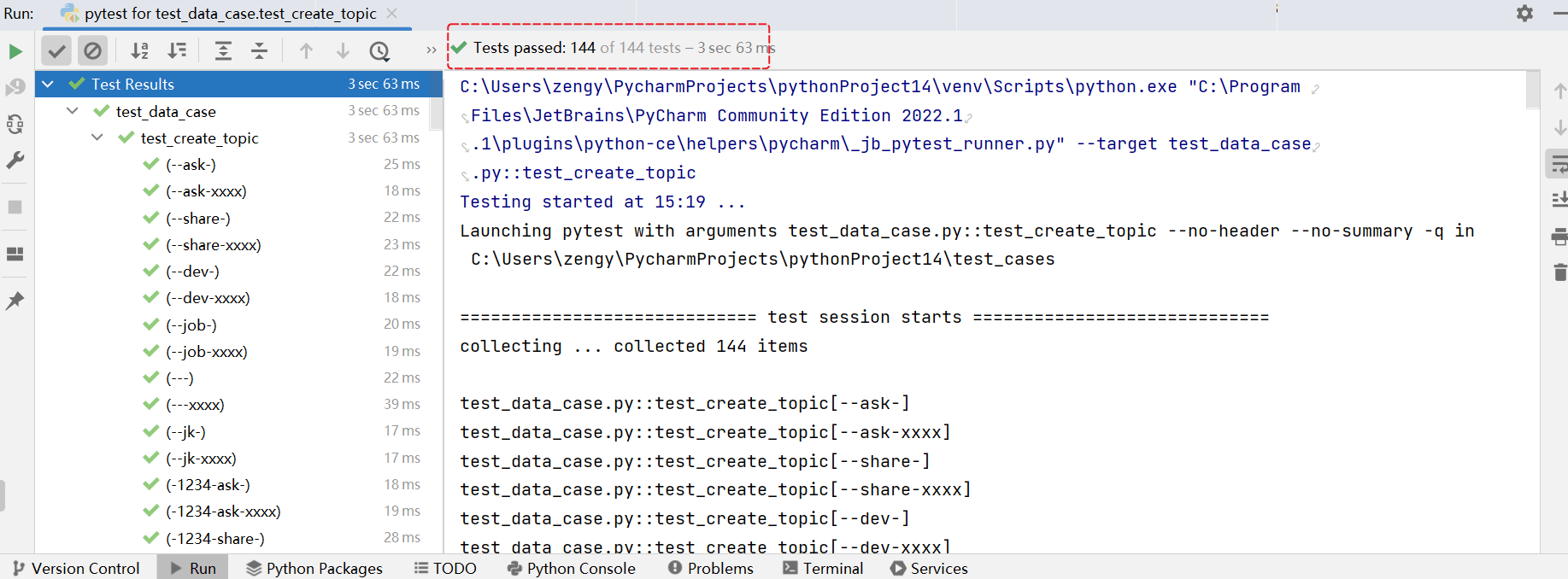
添加对应的断言
在生成测试数据的时候需要考虑到断言结果。这个接口的验证逻辑是这样
- 先验证token值,token值错误, 后面的所有的字段都不管, 直接返回
错误的accessToken - 当token 正确的情况下, 验证title, 标题小于10个字符。
- 如果为空 返回 标题不能为空
- 不为空 小于10个字符 标题字数太多或太少
- 当title正常的时候, 验证tab 字段, 不是 “ask”,”share”,”dev”,”job” 返回 必须选择一个版块
- 当前面都正常,验证 content 字段,为空,返回 内容不可为空
根据这些条件生成对应的测试数据 断言。
tokens =["","e18de36f-d9ce-47e6-a2aa-1cf6508ec10","e18de36f-d9ce-47e6-a2aa-1cf6508ec10b","240d17fe-9a54-4d78-b73d-7600af599174"]
titles = ["","1234","1234567890"]
tabs=["ask","share","dev","job","","jk"]
contents = ["","xxxx"]
#存放所有的数据
all_case_data = []
for token in tokens:
for title in titles:
for tab in tabs:
for content in contents:
# 根据条件来生成对应的断言结果
if token != "e18de36f-d9ce-47e6-a2aa-1cf6508ec10b":
errmsg = "错误的accessToken"
elif len(title) == 0:
errmsg = "标题不能为空"
elif len(title) < 10:
errmsg = "标题字数太多或太少"
elif tab not in ['ask','share','dev','job']:
errmsg = '必须选择一个版块'
elif len(content) == 0:
errmsg = '内容不可为空'
# 如果数据都是正常的数据 发帖成功
else:
errmsg = None
# 每次循环,生成一条数据
casedata = (token,title,tab,content,errmsg)
# 将生成的数据放在all_case_data中
all_case_data.append(casedata)
print(all_case_data)
@pytest.mark.parametrize("token,title,tab,content,errmsg",all_case_data)
def test_create_topic(token,title,tab,content,errmsg):
url = "http://47.100.175.62:3000/api/v1/topics"
bodydata = {
"accesstoken":token,
"title":title,
"tab":tab,
"content":content
}
r = requests.post(url=url,json=bodydata)
print(r.json())
# 添加断言 因为生成的数据包含正常场景,当errmsg 不为空的时候添加对错误场景断言
if errmsg is not None:
assert r.json()["error_msg"] == errmsg
执行,可以看到效果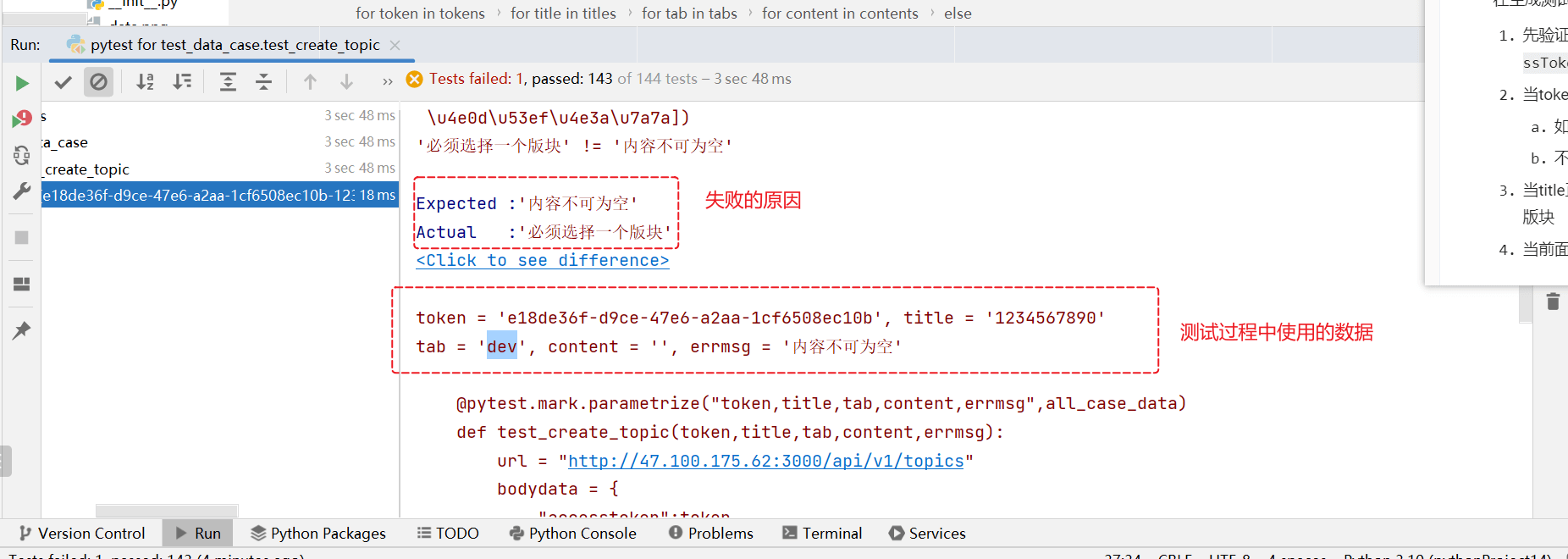
有个断言失败,经过分析,这个是一个系统bug。
执行数据保存
执行单接口测试的时候,生成数据比较多,也可以将生成数据保存到文件中,生成数据以及执行运行的结果保存到csv文件中。
import requests
testdata = [
("","123456","ask","","错误的accessToken"),
("e18de36f-d9ce-47e6-a2aa-1cf6508ec10b",'',"ask","xxxxx","标题不能为空")
]
tokens =["","e18de36f-d9ce-47e6-a2aa-1cf6508ec10","e18de36f-d9ce-47e6-a2aa-1cf6508ec10b","240d17fe-9a54-4d78-b73d-7600af599174"]
titles = ["","1234","1234567890"]
tabs=["ask","share","dev","job","","jk"]
contents = ["","xxxx"]
#存放所有的数据
all_case_data = []
for token in tokens:
for title in titles:
for tab in tabs:
for content in contents:
# 根据条件来生成对应的断言结果
if token != "e18de36f-d9ce-47e6-a2aa-1cf6508ec10b":
errmsg = "错误的accessToken"
elif len(title) == 0:
errmsg = "标题不能为空"
elif len(title) < 10:
errmsg = "标题字数太多或太少"
elif tab not in ['ask','share','dev','job']:
errmsg = '必须选择一个版块'
elif len(content) == 0:
errmsg = '内容不可为空'
# 如果数据都是正常的数据 发帖成功
else:
errmsg = None
# 每次循环,生成一条数据
casedata = (token,title,tab,content,errmsg)
# 将生成的数据放在all_case_data中
all_case_data.append(casedata)
print(all_case_data)
import csv
import os
p1 = os.path.abspath(__file__)
p2 = os.path.dirname(p1)
p3 = os.path.dirname(p2)
p4 = os.path.join(p3,'csvdata')
if not os.path.exists(p4):
os.mkdir(p4)
topicfile = os.path.join(p4,'topic.csv')
# 创建文件
f = open(file=topicfile, mode='w', encoding='utf8', newline="")
cw = csv.writer(f)
# 写入表头
cw.writerow(["请求地址", "请求方法", "请求头信息", "请求体", "服务器返回状态码", "服务器返回结果"])
@pytest.mark.parametrize("token,title,tab,content,errmsg",all_case_data)
def test_create_topic(token,title,tab,content,errmsg):
url = "http://47.100.175.62:3000/api/v1/topics"
bodydata = {
"accesstoken":token,
"title":title,
"tab":tab,
"content":content
}
r = requests.post(url=url,json=bodydata)
print(r.json())
# 将执行的数据,服务器返回的结果保存到文件中。
# 写入数据
cw.writerow([url,"post","",bodydata,r.status_code, r.json()])
# 添加断言 因为生成的数据包含正常场景
if errmsg is not None:
assert r.json()["error_msg"] == errmsg
执行结束,可以看到对应的数据一个已经保存到文件中。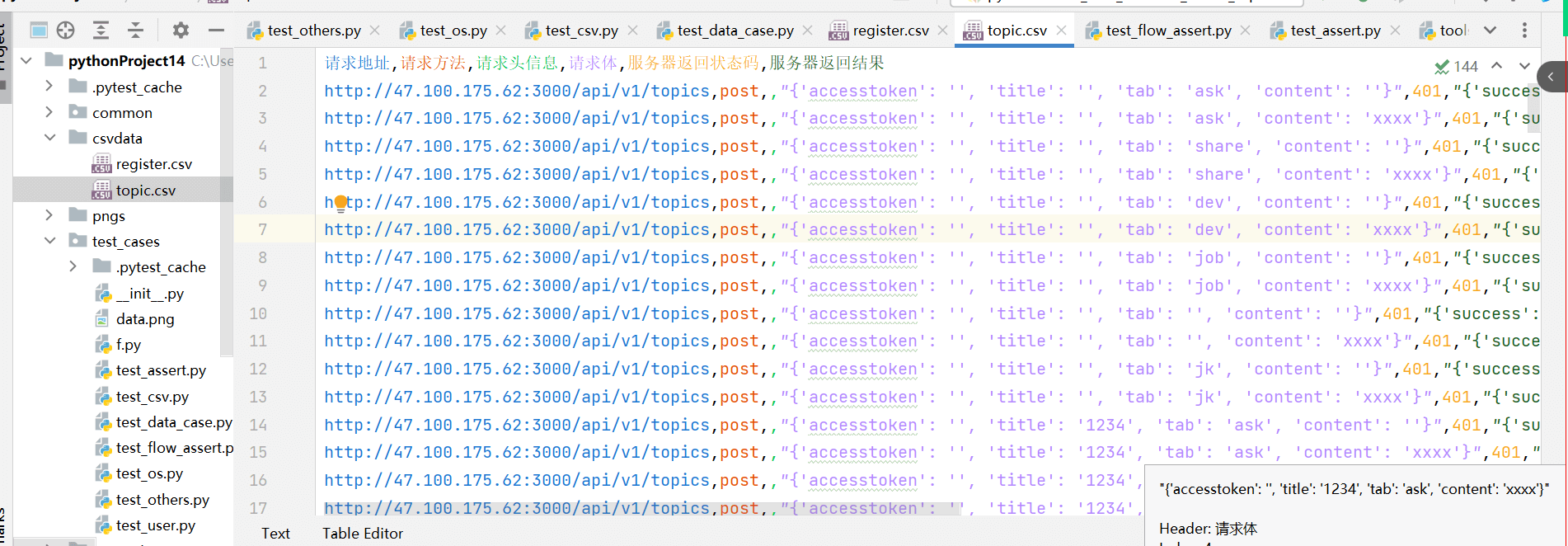

若有收获,就点个赞吧
0 人点赞
