group by 后面可以跟过滤 ,比如, 只显示 每年入职的人数超过5人的年份。
语法 是使用 having 进行过滤。
- 统计每年的入职人数。只显示 每年入职的人数超过5人的年份。
select year(join_in), count(join_in) from empsgroup by year(join_in) having count(join_in) > 5;
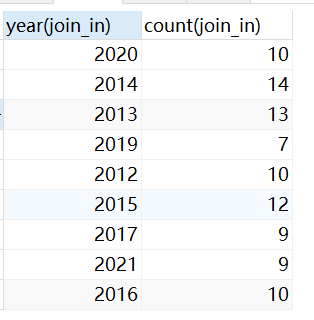
- 统计每年的入职人数。只显示 每年入职的人数 在5-10之间 并按照人数升序排序。 ```sql select year(join_in),COUNT(*) FROM EMPS
GROUP BY YEAR(JOIN_IN) — 分组 having count() BETWEEN 5 and 10 — 分组的条件 order by count() asc ; — 排序
3. 统计薪资大于15000的职员的每年的入职人数。只显示 每年入职的人数 在5-10之间 并按照人数升序排序。```sqlselect year(join_in),count(*) from empswhere salary > 15000GROUP BY year(join_in)having count(*) between 5 and 10order by count(*) asc;
思维导图

作业
- 整理这三天自己学习的内容的思维导图或者笔记大纲;

根据heros 表中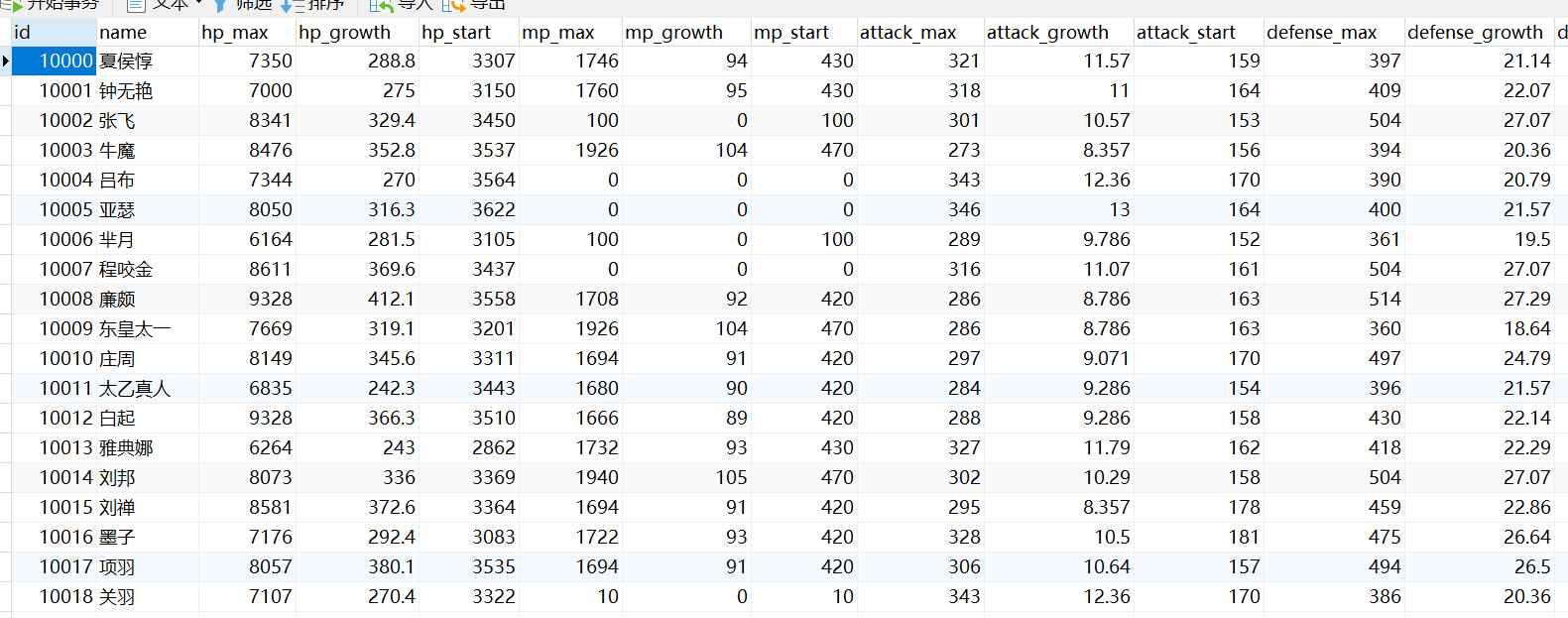
- 统计血量(hp_max)大于6000的英雄个数。
- 根据role_main(主要定位)进行分组。统计每个主要定位的人数。 ```sql — 1. 统计血量(hp_max)大于6000的英雄个数。 SELECT COUNT(*) FROM heros WHERE hp_max >6000;
— 2. 根据role_main(主要定位)进行分组。统计每个主要定位的人数。
SELECT role_main, COUNT(role_main) FROM heros GROUP BY role_main;
3. 根据birthdate(上架日期)的年份进行分组,统计每年上架的英雄人数。3. 根据role_main(主要定位)进行分组,统计统计每个定位的英雄 血量(hp_max)的平均值,血量(hp_max)的最大值, 血量(hp_max)的最小值。```sql-- 3. 根据birthdate(上架日期)的年份进行分组,统计每年上架的英雄人数。SELECT year(birthdate),COUNT(*) FROM heros WHERE not year(birthdate) is null GROUP BY year(birthdate);-- 4. 根据role_main(主要定位)进行分组,统计统计每个定位的英雄 血量(hp_max)的平均值,血量(hp_max)的最大值, 血量(hp_max)的最小值。SELECT role_main,avg(hp_max),MAX(hp_max),MIN(hp_max) FROM heros GROUP BY role_main;
emps 表
- 按照 salary 降序,join_in 升序排序。
- 统计在10月份入职的员工总人数。 ```sql — 1. 按照 salary 降序,join_in 升序排序。 select * from emps order by salary desc ,join_in;
— 2. 统计在10月份入职的员工总人数。 select count(*) from emps where month(join_in)=10 and position =”员工”;
3. 统计薪资范围在 10000-20000 之间的职员总人数。3. 统计姓名为两个字的职员个数。```sql-- 3. 统计薪资范围在 10000-20000 之间的职员总人数。SELECT count(*) from emps where salary BETWEEN 10000 and 20000;-- 4. 统计姓名为两个字的职员个数。SELECT COUNt(*) from emps WHERE name like '__';
- 上面表中salary为月薪,请计算公司1年(12个月)需要支付的总薪水。
- 查找薪水最高的职员。 ```sql — 5. 上面表中salary为月薪,请计算公司1年(12个月)需要支付的总薪水。 SELECT SUM(salary)*12 FROM emps;
— 6. 查找薪水最高的职员。
SELECT * FROM emps WHERE salary = (SELECT MAX(salary) FROM emps); ```

若有收获,就点个赞吧
0 人点赞
