循环
- 使用 for 循环 打印一个99乘法表。
—for x in range(1,10):for y in range(1,x+1):print(f"{y} * {x}",end="\t")print() # 换行

for x in range(9,0,-1):for y in range(9,x-1,-1):print(f"{y} * {x}",end="\t")print() # 换行

- 生成随机的身份证号 (1950—2020之间)。
身份证号 前6位 可以从csv文件中读取,随机获取一个。 参考实现 https://www.yuque.com/imhelloworld/bypiud/hr988g#kWgZ5
中间8位, 分别是年月日
年 四位 从 1950-2020 随机
月 两位 01- 12 注意随机的时候, 当随机值 小于10 前面补0 比如 9月 应该是 09
日 需要注意
值 小于10 前面补0 比如 9月 应该是 09
不同的月 不一样
后4位 注意最后一位 可能是 X
生成之后分别将 前6位,中间8位,最后4位 作为字符串拼接一下即可。
# 导入 csv 模块
import csv
import random
#创建一个空的列表
all_code = []
# 读取 gb2260.csv 文件
with open(file='gb2260.csv',encoding='utf8',mode='r') as f:
# 使用csv 创建读取对象
cr = csv.reader(f)
for code in cr:
# print(code, type(code),code[0])
# 每次获取一个code 将code值存放在 all_code 中
all_code.append(code[0])
# 等文件读取完成之后 all_code中存放了所有的 code值
# print(all_code)
# 使用random 随机从 all_code 中选择一个
cd = random.choice(all_code)
print(f"随机选中地区码:{cd}")
# 生成年月日
# 生成年份
y = random.randint(1950,2020)
print(f"生成的年份:{y}")
# 生成月份
m = random.randint(1,12)
if m < 10:
# 月份前面补0,将数字转换位字符串
m = "0" + str(m)
print(f"生成的月份:{m}")
# 生成天
# 根据月份和年份
# 1 当月份为 1,3,5,7,8,10,12 月,天数31天
if int(m) in [1,3,5,7,8,10,12]:
d = random.randint(1,31)
# 2,当月份为 4,6,9,11 月 天数是30天
elif int(m) in [4,6,9,11]:
d = random.randint(1,30)
# 3.2月份分为平年和闰年, 如果是闰年的29天
# 公元年分为4的倍数但非100的倍数 或者 为400的倍数
elif (y % 4 == 0 and y%100 != 0) or y%400==0:
d = random.randint(1,29)
# 以上都不符合,那就是平年的2月份
else:
d = random.randint(1,28)
# 如果d小于10 ,需要补0
if d<10:
d = "0"+str(d)
print(f"生成的日期:{d}")
# 生成后4位 最后1位可X
l3 = ""
# 循环三次
for i in range(3):
# 每次都生成一个随机数字进行拼接
l3 = l3+ str(random.randint(0,9))
# 最后一位有可能是X,也可能是数字
l1 = random.choice([0,1,2,3,4,5,6,7,8,9,"X"])
print(f"生成的最后四位: {l3}{l1}")
print(f"生成随机的身份证号: {cd}{y}{m}{d}{l3}{l1}")
- 根据如下代码, 将数字按照对应的映射关系进行转化。
```python
map_dict = {
0:”零”,
1:”一”,
2:”二”,
3:”三”,
4:”四”,
5:”五”,
6:”六”,
7:”七”,
8:”八”,
9:”九”
}
nums = [123,506,709]
写段程序 上面nums中的数字 换成汉字。进行转换输出
[“一二三”,”五零六”,”七零九”]
建立映射关联,通过循环获取每个值,进行数据转换。
```python
map_dict = {
0:"零",
1:"一",
2:"二",
3:"三",
4:"四",
5:"五",
6:"六",
7:"七",
8:"八",
9:"九"
}
nums = [123,506,709]
nums_str = []
# 循环列表
for num in nums:
print(num)
# 将列表中的数字转换为字符串 进行循环
num_str = ""
for n in str(num):
print(n,type(n)) # 字符串
# n转换为数字 根据字典添加映射
print( map_dict[int(n)])
# 字符串拼接
num_str = num_str + map_dict[int(n)]
print(num_str)
nums_str.append(num_str)
print(nums_str)
函数
将生成身份号的代码封装在三个函数中。
def get_code():
"""
主要是生成随机的前6位
"""
def get_ymd():
"""
主要是生成随机的4位年 2位月 2位 日
"""
def get_last():
"""
生成身份证号的后4位
"""
通过调用三个函数 可以组合生成一个随机的身份证号。
import csv
import random
def get_code():
"""
主要是生成随机的前6位
"""
# 创建一个空的列表
all_code = []
# 读取 gb2260.csv 文件
with open(file='gb2260.csv', encoding='utf8', mode='r') as f:
# 使用csv 创建读取对象
cr = csv.reader(f)
for code in cr:
# print(code, type(code),code[0])
# 每次获取一个code 将code值存放在 all_code 中
all_code.append(code[0])
# 等文件读取完成之后 all_code中存放了所有的 code值
# print(all_code)
# 使用random 随机从 all_code 中选择一个
cd = random.choice(all_code)
print(f"随机选中地区码:{cd}")
return cd
def get_ymd():
"""
主要是生成随机的4位年 2位月 2位 日
"""
# 生成年月日
# 生成年份
y = random.randint(1950, 2020)
print(f"生成的年份:{y}")
# 生成月份
m = random.randint(1, 12)
if m < 10:
# 月份前面补0,将数字转换位字符串
m = "0" + str(m)
print(f"生成的月份:{m}")
# 生成天
# 根据月份和年份
# 1 当月份为 1,3,5,7,8,10,12 月,天数31天
if int(m) in [1, 3, 5, 7, 8, 10, 12]:
d = random.randint(1, 31)
# 2,当月份为 4,6,9,11 月 天数是30天
elif int(m) in [4, 6, 9, 11]:
d = random.randint(1, 30)
# 3.2月份分为平年和闰年, 如果是闰年的29天
# 公元年分为4的倍数但非100的倍数 或者 为400的倍数
elif (y % 4 == 0 and y % 100 != 0) or y % 400 == 0:
d = random.randint(1, 29)
# 以上都不符合,那就是平年的2月份
else:
d = random.randint(1, 28)
# 如果d小于10 ,需要补0
if d < 10:
d = "0" + str(d)
print(f"生成的日期:{d}")
return str(y)+str(m)+str(d)
def get_last():
"""
生成身份证号的后4位
"""
l3 = ""
# 循环三次
for i in range(3):
# 每次都生成一个随机数字进行拼接
l3 = l3 + str(random.randint(0, 9))
# 最后一位有可能是X,也可能是数字
l1 = random.choice([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, "X"])
print(f"生成的最后四位: {l3}{l1}")
return str(l3)+str(l1)
if __name__ == '__main__':
userId = get_code()+get_ymd()+get_last()
print(f"生成随机的的身份证号: {userId}")
使用requests库参考 注册接口编写 登录接口。要求能够登录成功。
# 导入 requests 模块
import requests
# 接口的文档地址:http://49.233.108.117:28019/swagger-ui.html#/
def test_regiseter():
# 定义注册用户的地址
url = "http://49.233.108.117:28019/api/v1/user/register"
# 定义请求数据
bodydata= {
"loginName": "13212312312",
"password": "123456"
}
# 发送请求 url= 表示请求地址, json= 请求数据为json格式
r = requests.post(url=url,json=bodydata)
# r 是整个服务器返回的结果
print("状态码:", r.status_code)
# 服务器返回结果
print("结果:", r.json())
def test_login():
pass
# 导入 requests 模块
import requests
# 接口的文档地址:http://49.233.108.117:28019/swagger-ui.html#/
def test_regiseter():
# 定义注册用户的地址
url = "http://49.233.108.117:28019/api/v1/user/register"
# 定义请求数据
bodydata= {
"loginName": "13212312312",
"password": "123456"
}
# 发送请求 url= 表示请求地址, json= 请求数据为json格式
r = requests.post(url=url,json=bodydata)
# r 是整个服务器返回的结果
print("状态码:", r.status_code)
# 服务器返回结果
print("结果:", r.json())
def test_login():
url = "http://49.233.108.117:28019/api/v1/user/login"
bodydata = {
"loginName": "13212312312",
"passwordMd5": "E10ADC3949BA59ABBE56E057F20F883E"
}
r = requests.post(url,json=bodydata)
print(r.status_code)
print(r.json())
自动化作业
- 给接口添加对应的断言。 ```python
import requests import random
随机生成手机号码
phone = random.randint(13000000000,13999999999) jsondata = { “token”:None, “goodsid”:None, }
def test_register():
# 定义注册用户的地址
url = "http://49.233.108.117:28019/api/v1/user/register"
# 定义请求数据
bodydata = {
"loginName": str(phone),
"password": "123456"
}
print(bodydata)
# 发送请求 url= 表示请求地址, json= 请求数据为json格式
r = requests.post(url=url, json=bodydata)
# r 是整个服务器返回的结果
print("状态码:", r.status_code)
# 服务器返回结果
print("结果:", r.json())
def test_login(): url = “http://49.233.108.117:28019/api/v1/user/login“ bodydata = { “loginName”: str(phone), “passwordMd5”: “E10ADC3949BA59ABBE56E057F20F883E” } print(bodydata) r = requests.post(url, json=bodydata) print(r.status_code) print(r.json())
# 将token提取出来 放在 字典格式数据中 - 上游传参
jsondata["token"] = r.json()["data"]
def test_search(): url = “http://49.233.108.117:28019/api/v1/search“
# 信息头数据 下游接口中使用到这个值
headerdata = {
"token": jsondata["token"]
}
# 请求参数
querydata = {
"keyword": "iphone"
}
# 发送get 请求 params get请求的参数, headers 请求头数据
r = requests.get(url=url,params=querydata,headers=headerdata)
print(r.status_code)
print(r.json())
# 所有的商品 存放在一个列表中
all_goods = r.json()['data']['list']
# 创建空的列表
gids = []
# 循环列表 拿到每一个商品
for goods in all_goods:
# 从商品中访问 goodsId
gid = goods["goodsId"]
print(gid)
# 将商品id 放在列表中
gids.append(gid)
# 循环结束 可以看到所有的商品id
print(gids)
# 随机选择一个 作为参数
jsondata["goodsid"] = random.choice(gids)
def test_add_cart(): url = “http://49.233.108.117:28019/api/v1/shop-cart“
# 信息头数据 下游接口中使用到这个值
headerdata = {
"token": jsondata["token"]
}
bodydata = {
"goodsCount": random.randint(1,5),
"goodsId": jsondata["goodsid"]
}
r = requests.post(url,json=bodydata,headers=headerdata)
print(r.status_code)
print(r.json())
---
```python
import requests
import random
# 随机生成手机号码
phone = random.randint(13000000000,13999999999)
jsondata = {
"token":None,
"goodsid":None,
}
def test_register():
# 定义注册用户的地址
url = "http://49.233.108.117:28019/api/v1/user/register"
# 定义请求数据
bodydata = {
"loginName": str(phone),
"password": "123456"
}
print(bodydata)
# 发送请求 url= 表示请求地址, json= 请求数据为json格式
r = requests.post(url=url, json=bodydata)
# r 是整个服务器返回的结果
print("状态码:", r.status_code)
# 服务器返回结果
print("结果:", r.json())
assert r.status_code == 200
assert r.json() == {'resultCode': 200, 'message': 'SUCCESS', 'data': None}
def test_login():
url = "http://49.233.108.117:28019/api/v1/user/login"
bodydata = {
"loginName": str(phone),
"passwordMd5": "E10ADC3949BA59ABBE56E057F20F883E"
}
print(bodydata)
r = requests.post(url, json=bodydata)
print(r.status_code)
print(r.json())
# 将token提取出来 放在 字典格式数据中 - 上游传参
jsondata["token"] = r.json()["data"]
assert r.status_code == 200
assert r.json()["resultCode"] ==200
assert r.json()["message"] == "SUCCESS"
assert r.json()["data"] is not None
def test_search():
url = "http://49.233.108.117:28019/api/v1/search"
# 信息头数据 下游接口中使用到这个值
headerdata = {
"token": jsondata["token"]
}
# 请求参数
querydata = {
"keyword": "iphone"
}
# 发送get 请求 params get请求的参数, headers 请求头数据
r = requests.get(url=url,params=querydata,headers=headerdata)
print(r.status_code)
print(r.json())
# 所有的商品 存放在一个列表中
all_goods = r.json()['data']['list']
# 创建空的列表
gids = []
# 循环列表 拿到每一个商品
for goods in all_goods:
# 从商品中访问 goodsId
gid = goods["goodsId"]
print(gid)
# 将商品id 放在列表中
gids.append(gid)
# 商品的goodsName中 包含 iphone
# name:str 表示name变量的类型是字符串类型,主要为了下面写代码的有代码提示。 :str 这个可以去掉
name:str = goods["goodsName"]
#因为不区分大小写, name.lower()转换为小写 Apple iPhone 11 (A2223) =》 appple iphone 11 (a2223)
# in 在 ... 里面
assert 'iphone' in name.lower()
# 循环结束 可以看到所有的商品id
print(gids)
# 随机选择一个 作为参数
jsondata["goodsid"] = random.choice(gids)
def test_add_cart():
url = "http://49.233.108.117:28019/api/v1/shop-cart"
# 信息头数据 下游接口中使用到这个值
headerdata = {
"token": jsondata["token"]
}
bodydata = {
"goodsCount": random.randint(1,5),
"goodsId": jsondata["goodsid"]
}
r = requests.post(url,json=bodydata,headers=headerdata)
print(r.status_code)
print(r.json())
assert r.json() == {'resultCode': 200, 'message': 'SUCCESS', 'data': None}
- 抓包批量下载图片。
在这个网站上抓包: https://movie.douban.com/
抓取热门电影
接口返回结果中有 电影海报地址,以及电影的名称
将所有的电影海拔下载下来,文件名使用电影的名字。
在做这个练习的时候,因为豆瓣 有反爬虫机制, 发送请求的信息头如果不是浏览器的信息头,就不给返回结果。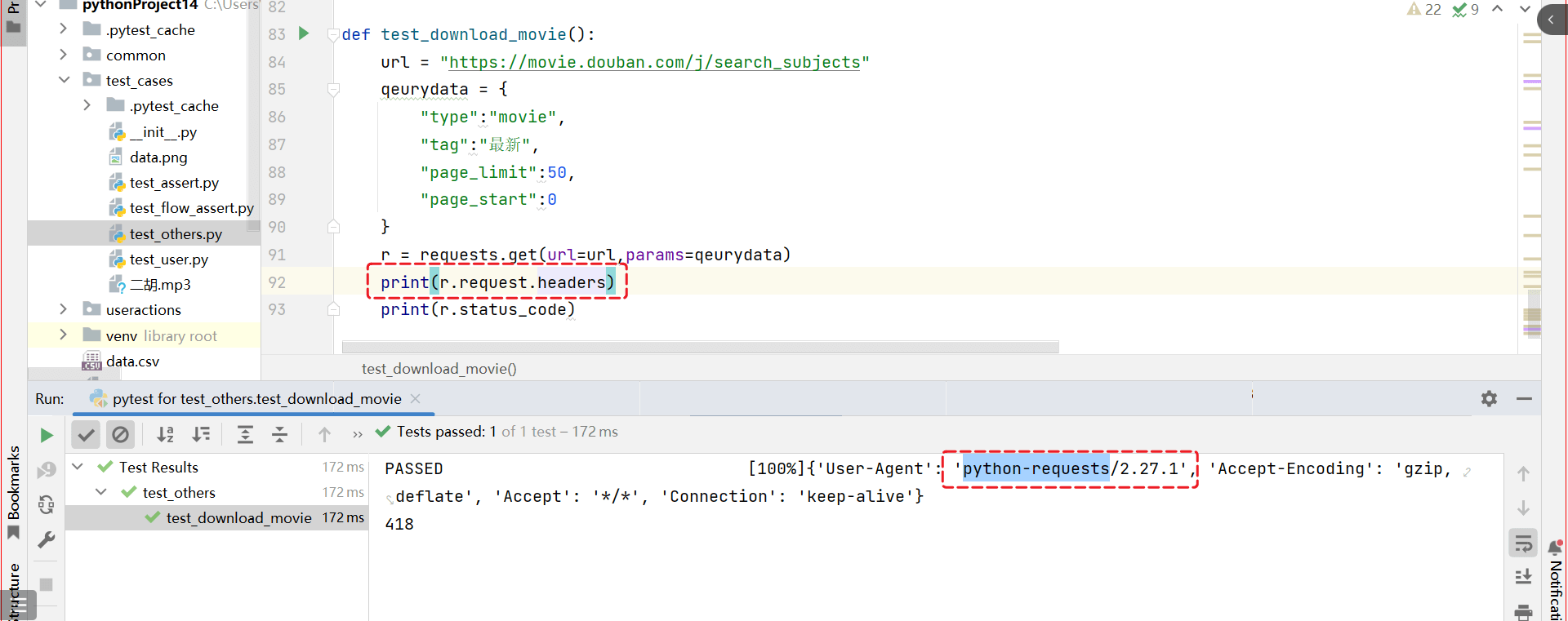
我们写的代码中 默认的信息头 信息是 Python-Requests ,requests 这个库经常被用来作为爬虫,触发了网站的发爬虫机制。
所以在发送这个请求的时候,添加信息头。
def test_download_movie():
url = "https://movie.douban.com/j/search_subjects"
qeurydata = {
"type":"movie",
"tag":"最新",
"page_limit":50,
"page_start":0
}
heardersdata ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
}
r = requests.get(url=url,params=qeurydata,headers=heardersdata)
print(r.request.headers)
print(r.status_code)
print(r.json())
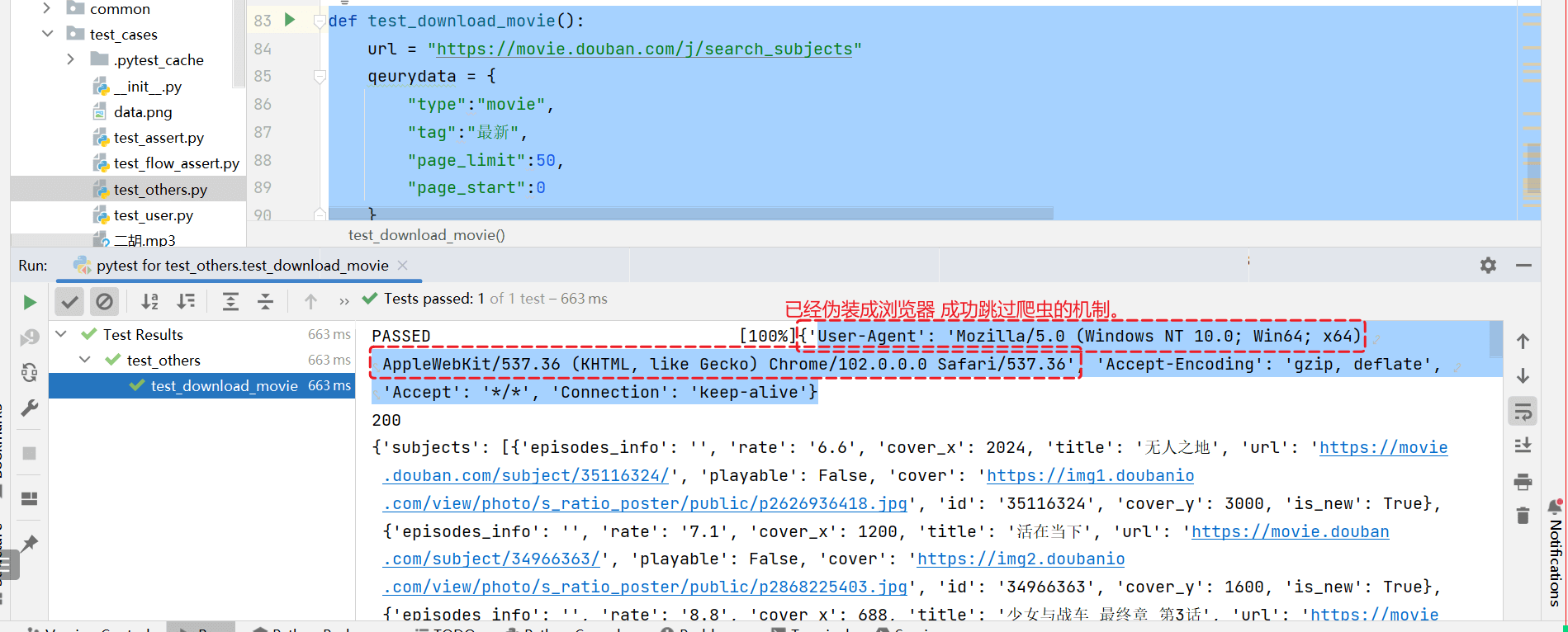
参考答案
import requests
def test_download_movie():
url = "https://movie.douban.com/j/search_subjects"
qeurydata = {
"type":"movie",
"tag":"最新",
"page_limit":50,
"page_start":0
}
heardersdata ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
}
r = requests.get(url=url,params=qeurydata,headers=heardersdata)
print(r.request.headers)
print(r.status_code)
print(r.json())
# 循环服务器返回的结果
for subject in r.json()["subjects"]:
name = subject["title"]
cover_url = subject["cover"]
print(f"下面即将下载电影海报: 电影名:{name}, 海报地址{cover_url}")
# 发送get请求 拿到服务器返回结果
res = requests.get(url=cover_url,headers=heardersdata)
# 使用open 保存文件, 使用name 电影名作为文件名
with open(file=name+".png",mode='wb') as f:
# 将图片信息保存进来
f.write(res.content)
- 使用for循环 循环接口返回的所有电影信息。
- 在循环中,拿到每个电影的 海报地址,以及对应的电影名。进行下载。
python基础
跟定一组数据。分表统计出现的次数。
nums = [10,20,10,11,11,11,11,20,22,22,22,33,33,24]
结果为
{10:2,
11:4,
20:2,
33:2,
24:1,
22:3}
主要思路: 利用集合数据类型的去重。
去统计每个元素的列表中的个数。
nums = [10,20,10,11,11,11,11,20,22,22,22,33,33,24]
# 将列表转换为集合
nums_set = set(nums)
print(nums_set)
nums_dict = {}
# 循环集合
for n in nums_set:
# 获取里面的每个元素,拿到元素,可以去列表中统计对应的个数
print(n,nums.count(n))
# 将对应值放在字典中
nums_dict[n] = nums.count(n)
# 循环完成之后 看字典
print(nums_dict)

若有收获,就点个赞吧
0 人点赞
