模块
python中创建了很多py文件,每个py文件我们官方说法就是 模块。
在模块可以编写一些代码。调用的时候只能在 当前模块中调用。那么能不能跨文件进行调用呢?
肯定是可以。
可以不同的代码放在不同的模块中,可以同过引用模块进行调用。
创建新项目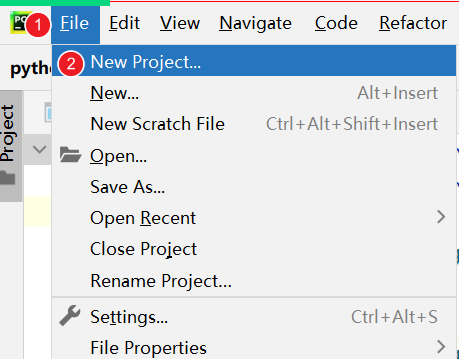

可以选择 新窗口 打开
创建模块
在项目上创建一个python文件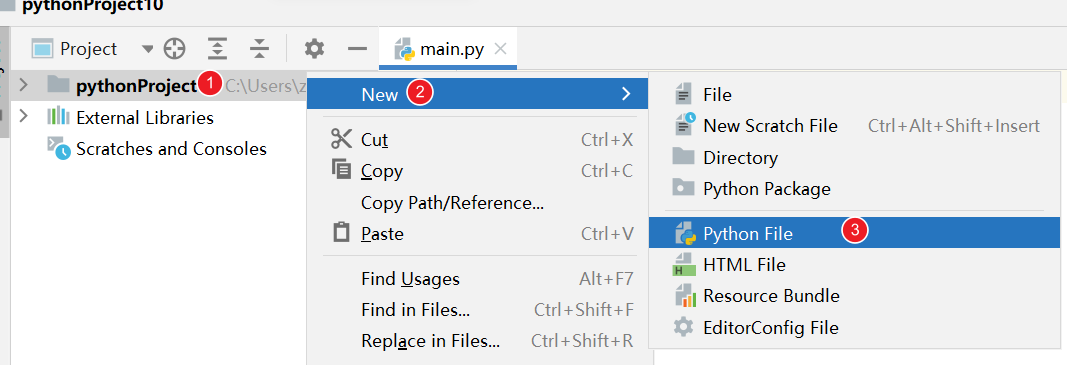
文件命名为 utils 用来存放一些自己定义的常用工具。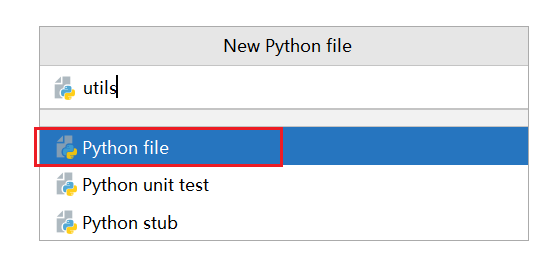
在文件中编写工具方法,将获取手机号的函数复制进来。
utils.py
# 导入python中的随机数生成模块import randomdef get_phone():"""生成一个随机的11手机号码, 手机号码中 前2位 ['13','14','15','17','18']:return:"""# 定义一个空的字符串 表示手机号phone=""# 定义手机号的支持的前两位pre_phone = ['13','14','15','17','18']# 随机从列表中选择一个 需要使用到随机函数p1 = random.choice(pre_phone) # 从列表中随机选择一个元素# print(p1)# 将随机获取的前两位放到手机号中phone=phone+p1# 生成9位随机的数字 (0,9) 循环9次for i in range(9):# 生成1位随机数n = random.randint(0,9)# print(n)# 将随机数字添加到手机号 n 位数字,数字不能直接跟字符串拼接 str(n) 将数字转换位字符串phone = phone+str(n)# 循环完成之后将电话号码返回return phonep = get_phone()print(f"生成随机电话 {p}")
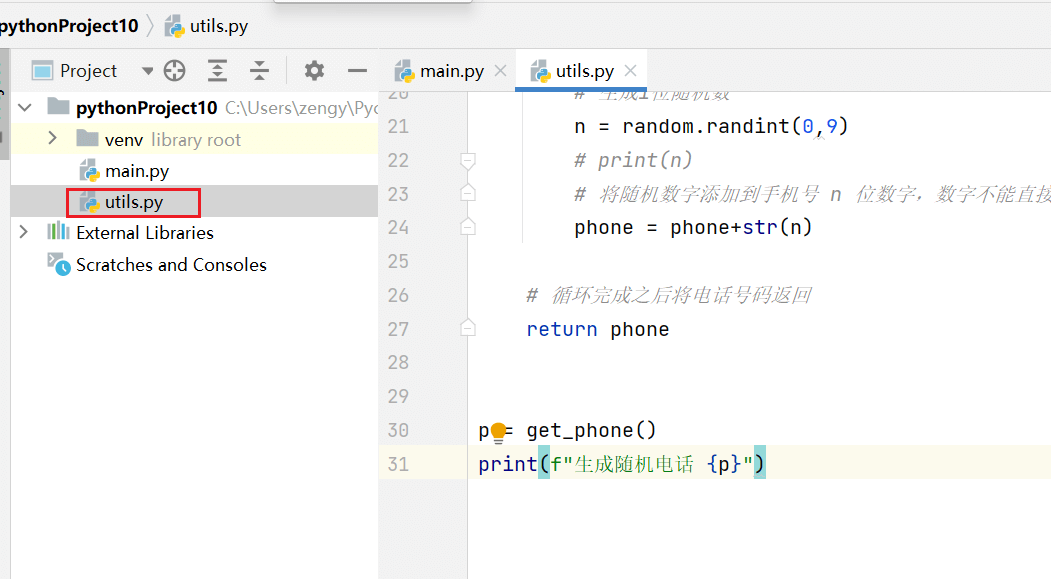

调用模块中的方法 import
下面要在 testdemo.py 文件中调用 utils.py 中写的代码
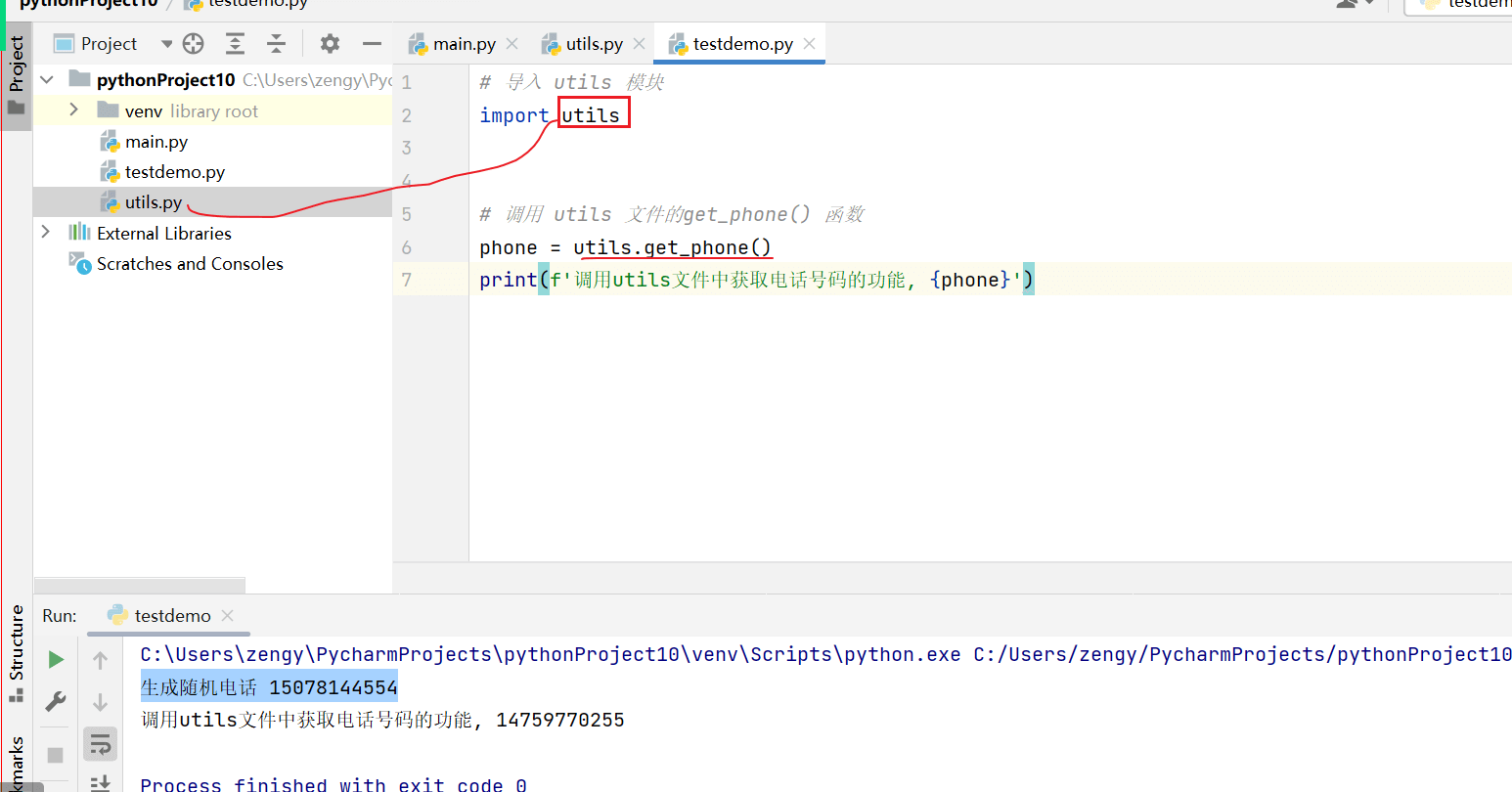
# 导入 utils 模块
import utils
# 调用 utils 文件的get_phone() 函数
phone = utils.get_phone()
print(f'调用utils文件中获取电话号码的功能, {phone}')
testdemo.py 中的代码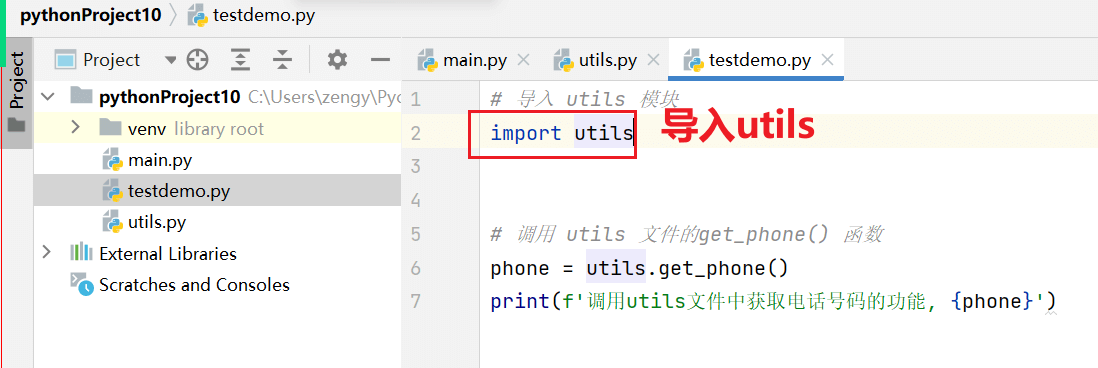
- import utils
这一句 会将 utlis.py 文件中的内容加载到 testdemo.py 文件中。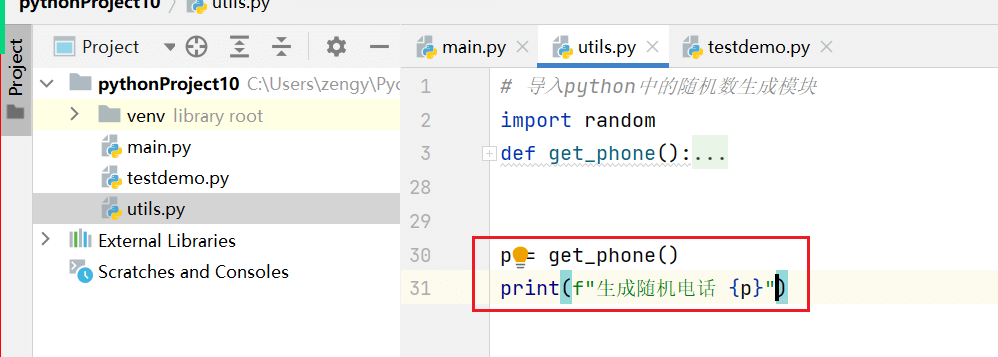
也就是说,在执行 testdemo.py 文件的时候,因为 testdemo.py 中有 import utils 导入utils.py 文件,那么执行会先执行 utils.py 文件中的代码。因为utils.py 文件中有打印,所以在执行 testdemo.py 的时候会 打印两句。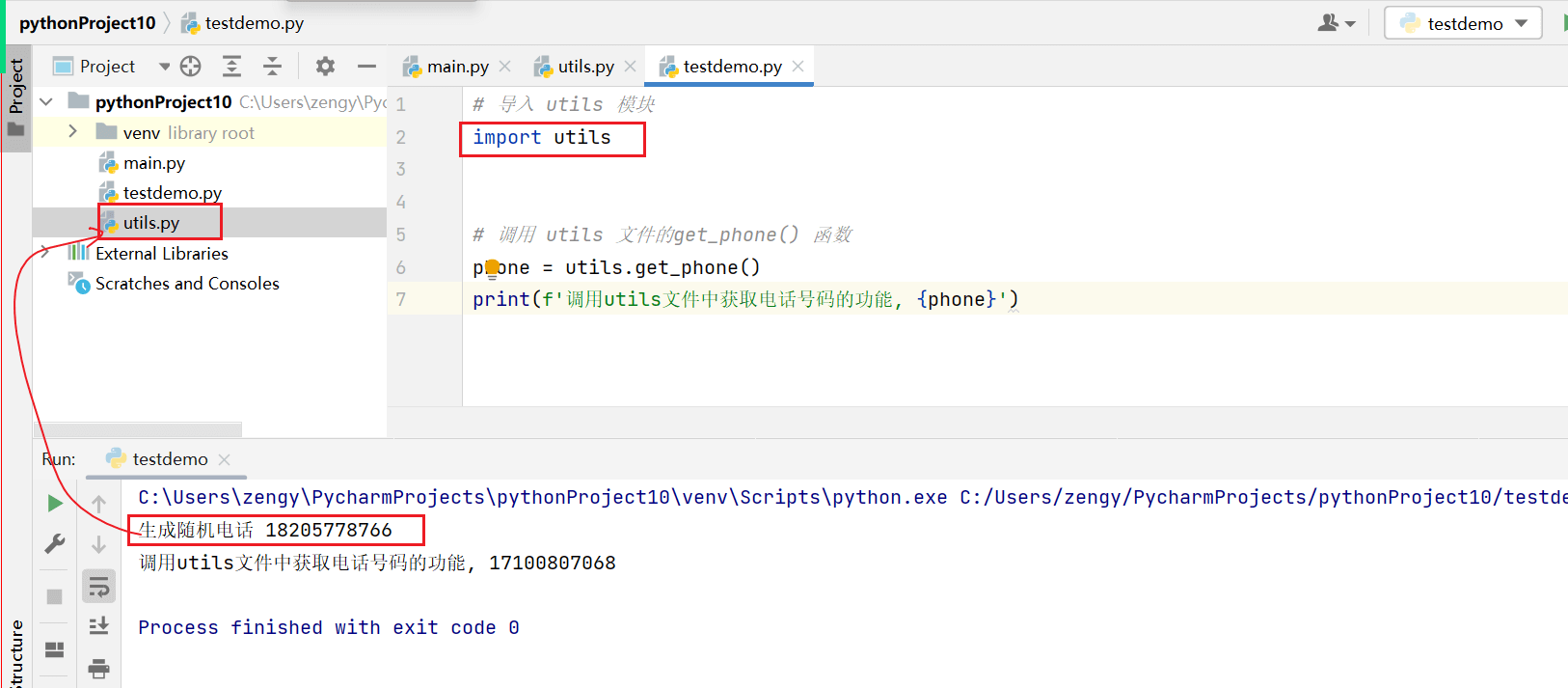
模块中的调试
在代码编辑器中输入 main 会自动提示语句
utils.py
# 导入python中的随机数生成模块
import random
def get_phone():
"""
生成一个随机的11手机号码, 手机号码中 前2位 ['13','14','15','17','18']
:return:
"""
# 定义一个空的字符串 表示手机号
phone=""
# 定义手机号的支持的前两位
pre_phone = ['13','14','15','17','18']
# 随机从列表中选择一个 需要使用到随机函数
p1 = random.choice(pre_phone) # 从列表中随机选择一个元素
# print(p1)
# 将随机获取的前两位放到手机号中
phone=phone+p1
# 生成9位随机的数字 (0,9) 循环9次
for i in range(9):
# 生成1位随机数
n = random.randint(0,9)
# print(n)
# 将随机数字添加到手机号 n 位数字,数字不能直接跟字符串拼接 str(n) 将数字转换位字符串
phone = phone+str(n)
# 循环完成之后将电话号码返回
return phone
if __name__ == '__main__':
p = get_phone()
print(f"生成随机电话 {p}")
testdemo.py
# 导入 utils 模块
import utils
if __name__ == '__main__':
# 调用 utils 文件的get_phone() 函数
phone = utils.get_phone()
print(f'调用utils文件中获取电话号码的功能, {phone}')
再次执行 testdemo.py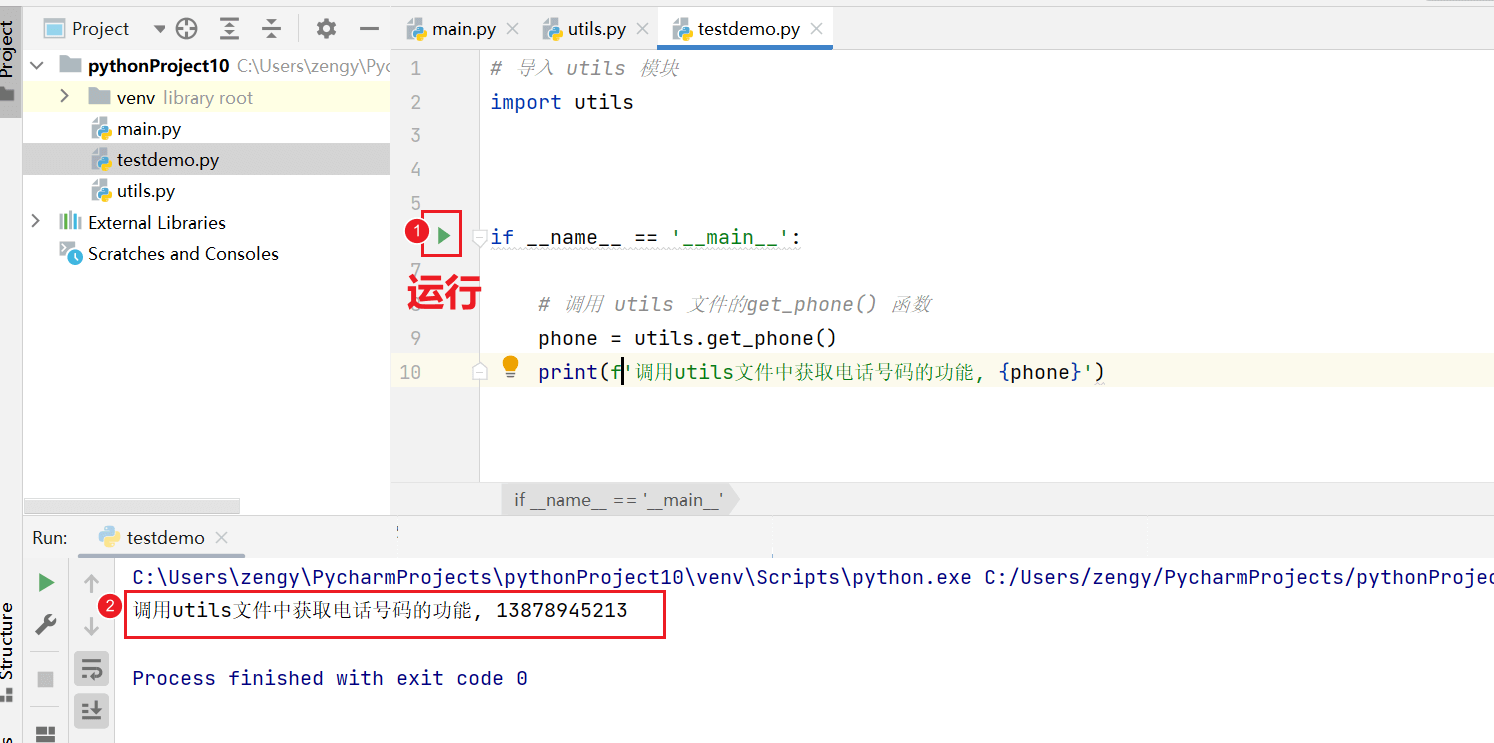
完善代码
utils.py
# 导入python中的随机数生成模块
import random
import csv
def get_phone():
"""
生成一个随机的11手机号码, 手机号码中 前2位 ['13','14','15','17','18']
:return:
"""
# 定义一个空的字符串 表示手机号
phone=""
# 定义手机号的支持的前两位
pre_phone = ['13','14','15','17','18']
# 随机从列表中选择一个 需要使用到随机函数
p1 = random.choice(pre_phone) # 从列表中随机选择一个元素
# print(p1)
# 将随机获取的前两位放到手机号中
phone=phone+p1
# 生成9位随机的数字 (0,9) 循环9次
for i in range(9):
# 生成1位随机数
n = random.randint(0,9)
# print(n)
# 将随机数字添加到手机号 n 位数字,数字不能直接跟字符串拼接 str(n) 将数字转换位字符串
phone = phone+str(n)
# 循环完成之后将电话号码返回
return phone
def get_area():
"""
生成随机的6位地区信息
:return: 6个数字字符串
"""
# 从csv文件中读取所有的地区码,随机选择一个
# 定义空的list 用来存放地区码
area_code=[]
with open('gb2260.csv',mode='r',encoding='utf8') as file:
lines = csv.reader(file)
for line in lines:
# 每个地区码 都放在list 中
area_code.append(line)
# 随机从 所有地区码中选择一个
code = random.choice(area_code)
# code 值选择出来是 一个list 需要将list 转换位字符串
code_str = ''.join(code) # ''.join(code) 将list 转换位字符串
# 将随机选择的code 返回
return code_str
def get_birth():
"""
生成随机的 出生年月日 1960-2022出生
:return:
"""
# 年份
year = random.randint(1960,2022)
# 月份
month = random.randint(1,12)
# 日
# 考虑闰年,月份
# 如果年份是闰年,并且月份2月, 有29天
if year%4 == 0 and month == 2:
day = random.randint(1,29)
# 在 1,3,5,7,8,10,12 月中 有31天
elif month in [1,3,5,7,8,10,12]:
day = random.randint(1,31)
elif month in [4,6,9,11]:
day = random.randint(1,30)
# 如果以上都不是 就是 平年的2月份
else:
day = random.randint(1,28)
# 如果天为个位数 前面添加0
if day<10:
day = "0"+str(day)
# 月份前 01, 02
if month < 10:
month = "0" + str(month)
# 返回年月日
return f'{year}{month}{day}'
def get_last():
"""
最后4位
:return:
"""
pre_3=""
for i in range(3):
n = random.randint(0,9)
pre_3 = pre_3+str(n)
last = random.choice(['0','1','2','3','4','5','6','7','8','9','X'])
# 返回
return f'{pre_3}{last}'
if __name__ == '__main__':
p = get_phone()
print(f"生成随机电话 {p}")
在testdemo.py 中引用
# 导入 utils 模块
import utils
def get_id():
"""
生成身份证id
:return:
"""
# 调用 utils 中定义函数
area_code = utils.get_area()
ymd_code = utils.get_birth()
last_code = utils.get_last()
return area_code+ymd_code+last_code
if __name__ == '__main__':
# 调用 utils 文件的get_phone() 函数
phone = utils.get_phone()
print(f'调用utils文件中获取电话号码的功能, {phone}')
user_id = get_id()
print(f'生成的身份证id {user_id}')
运行testdemo.py代码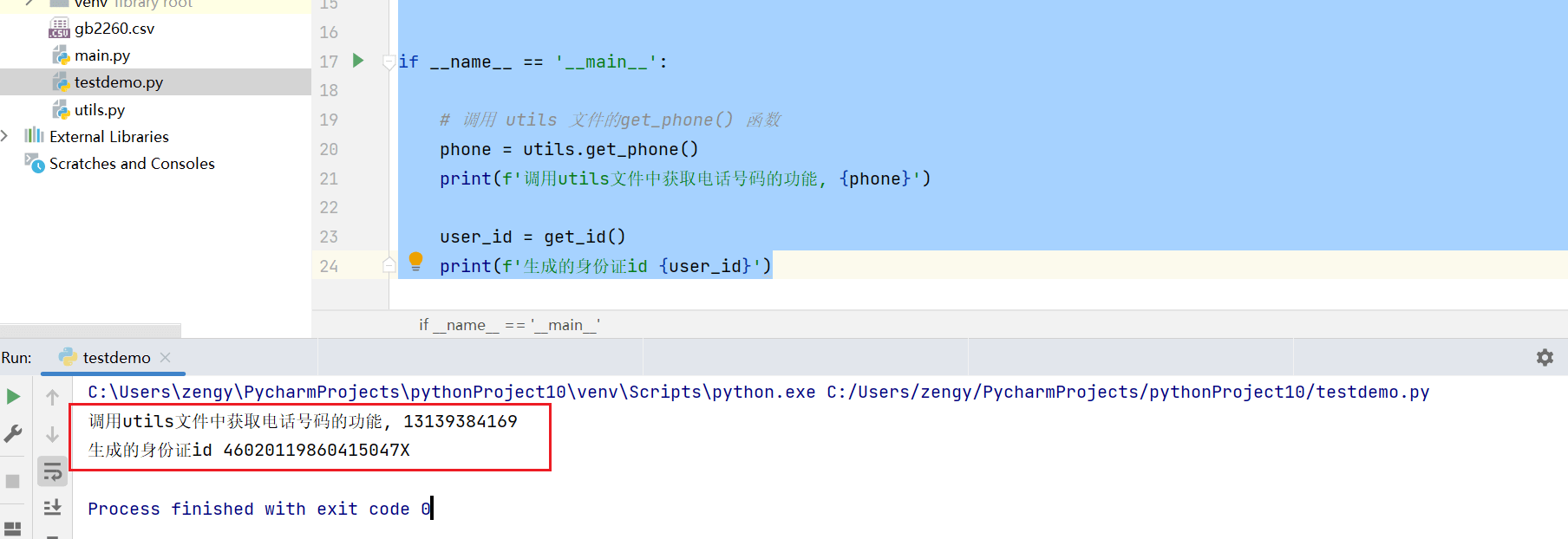
所有的代码
main.zip
导入模块的两种方式
使用import 导入
创建python 文件
demo.py
def f1():
print('demo文件中的f1 函数')
if __name__ == '__main__':
f1()
在main.py 文件引用 demo.py 中定义的f1函数。
main.py
import demo
if __name__ == '__main__':
demo.f1()

使用from…import…导入
也可以使用 from … import… 方式来进行导入。
demo.py
def f1():
print('demo文件中的f1 函数')
def f2():
print('demo文件中的f2 函数')
if __name__ == '__main__':
f1()
在main.py 文件中导入
# 使用 from 方式来导入 demo 文件中的 f2
from demo import f2
if __name__ == '__main__':
# 可以直接使用
f2()
使用 import 和 from … import 功能都是一样的。
from… import * 导入所有
main.py 中引入 demo.py 文件中所有的函数
main.py
# * 导入demo 文件中所有的函数
from demo import *
if __name__ == '__main__':
f2()
f1()
使用 import 导入可以,使用from … import … 的方式也行。两种方法都可以使用。使用的时候根据自己的使用习惯即可。
比如生成随机数,你可以这样写
import random
print(random.randomint(1,10))
也可以使用from的方式
from random import randint
print(randint(1,10))
包

目前来说,项目文件都在根目录下,当编写的代码越来越多的时候,需要将代码按照不同的功能放在不同的文件夹。这些不同文件夹在Python中称为 包
创建Python包
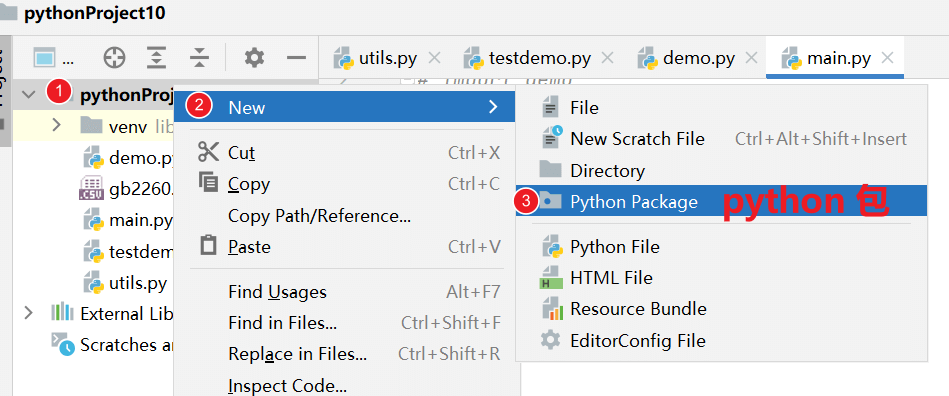
开发过程中,一些常用的函数都会放在 common 包,所以为这个包 命名为 common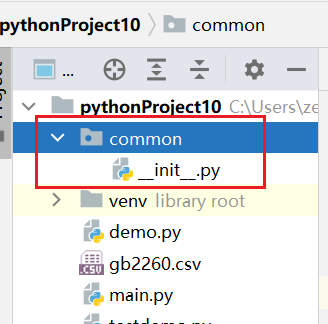
在common包中创建 file.py 文件,这个文件后面主要用来解析一些数据文件。
在files.py 文件中 编写代码。
common/files.py
def parse_csv():
print("files中解析csv文件的函数")
if __name__ == '__main__':
parse_csv()
引入包中的文件
引入包中的文件原理跟引入模块中函数原理一样,通过import 或者 from方式来引用。
import导入
在main.py 中导入
# import导入。需要跟上包的路径 common.files as 给路径起别名(别名可以随意)
import common.files as f
if __name__ == '__main__':
# 调用包中文件的函数
f.parse_csv()
from 导入
也可以通过from 的方式来导入包
# from 包.文件的路径 导入
from common.files import parse_csv
if __name__ == '__main__':
# 调用包中文件的函数
parse_csv()
不同的包中引用
创建 一个 testcases 的包,在testcase 包中创建 test_demo.py 文件。
在test_demo.py 文件中 引用 common包下 files.py 文件中定义的函数。
testcases/test_demo.py
import common.files as f
from common.files import parse_csv
if __name__ == '__main__':
f.parse_csv()
parse_csv()
运行都可以引用到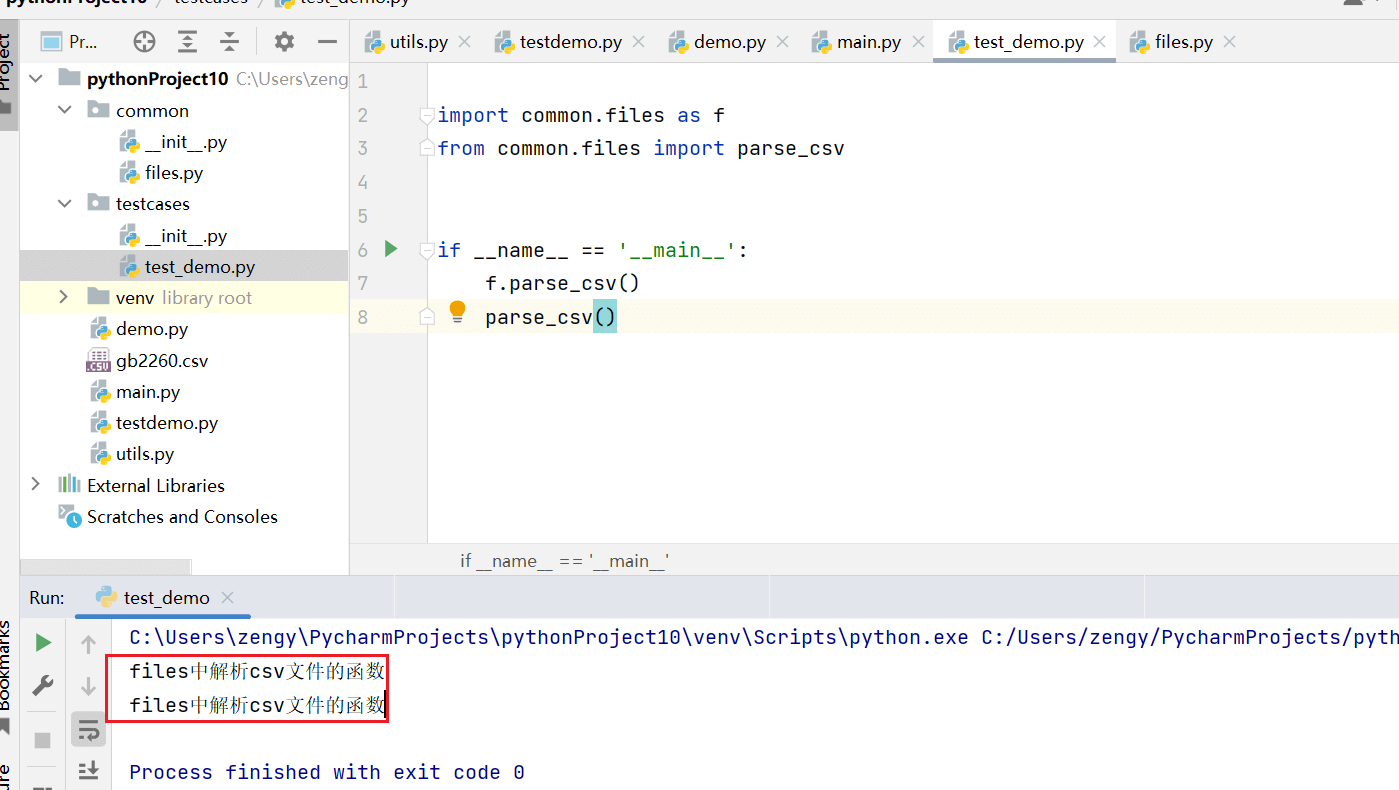
加强练习
定义解析csv文件
common/files.py
import csv
def parse_csv(filename):
"""
通过传入一个csv文件,将csv文件中的内容解析出来存放到列表中返回。
:param filename: 传入的文件路径
:return:
"""
# 定义空的列表存放csv文件中的数据
data = []
with open(filename,mode='r',encoding='utf8') as f:
lines = csv.reader(f)
for line in lines:
# 将读取出来的数据放到data中
data.append(line)
# 数据读取完成之后
return data
files.py 文件中 传入csv文件来测试 上面编写的函数是否正常。
import csv
def parse_csv(filename):
"""
通过传入一个csv文件,将csv文件中的内容解析出来存放到列表中返回。
:param filename: 传入的文件路径
:return:
"""
# 定义空的列表存放csv文件中的数据
data = []
with open(filename,mode='r',encoding='utf8') as f:
lines = csv.reader(f)
for line in lines:
# 将读取出来的数据放到data中
data.append(line)
# 数据读取完成之后
return data
if __name__ == '__main__':
# 检查一下 parse_csv 函数是否正常运行 使用绝对路径 可以解析出这个文件的内容。
# data = parse_csv(r'C:\Users\zengy\PycharmProjects\pythonProject10\gb2260.csv')
import os
# 获取当前文件所在的目录 获取目录名
dir = os.path.dirname(__file__)
print(dir)
# 找到项目的根目录 获取目录名
project_root = os.path.dirname(dir)
print('项目根目录',project_root)
# csv文件路径 join 方法可以将两个路径拼接到一起
csvfile = os.path.join(project_root,'gb2260.csv')
print(f'csv 文件路径: {csvfile}')
data = parse_csv(csvfile)
print(data)

common/files.py
import csv
import os
def get_project_root():
"""
在解析文件的时候,需要拼接文件的路径,这个函数 返回项目的根目录
:return:
"""
# 获取当前文件所在的目录
dir = os.path.dirname(__file__) # 找common 目录
print(dir) # C:\Users\zengy\PycharmProjects\pythonProject10\common
# 找到项目的根目录
project_root = os.path.dirname(dir) # common的上级目录 当前项目的根目录
print(project_root) # C:\Users\zengy\PycharmProjects\pythonProject10
return project_root
def parse_csv(filename):
"""
通过传入一个csv文件,将csv文件中的内容解析出来存放到列表中返回。
:param filename: 传入的文件路径
:return:
"""
# 定义空的列表存放csv文件中的数据
data = []
with open(filename,mode='r',encoding='utf8') as f:
lines = csv.reader(f)
for line in lines:
# 将读取出来的数据放到data中
data.append(line)
# 数据读取完成之后
return data
if __name__ == '__main__':
# 检查一下 parse_csv 函数是否正常运行 使用绝对路径 可以解析出这个文件的内容。
# data = parse_csv(r'C:\Users\zengy\PycharmProjects\pythonProject10\gb2260.csv')
# 获取到项目的根目录
project_root = get_project_root()
# csv文件路径 join 方法可以将两个路径拼接到一起
csvfile = os.path.join(project_root,'gb2260.csv')
print(f'csv 文件路径: {csvfile}')
data = parse_csv(csvfile)
print(data)
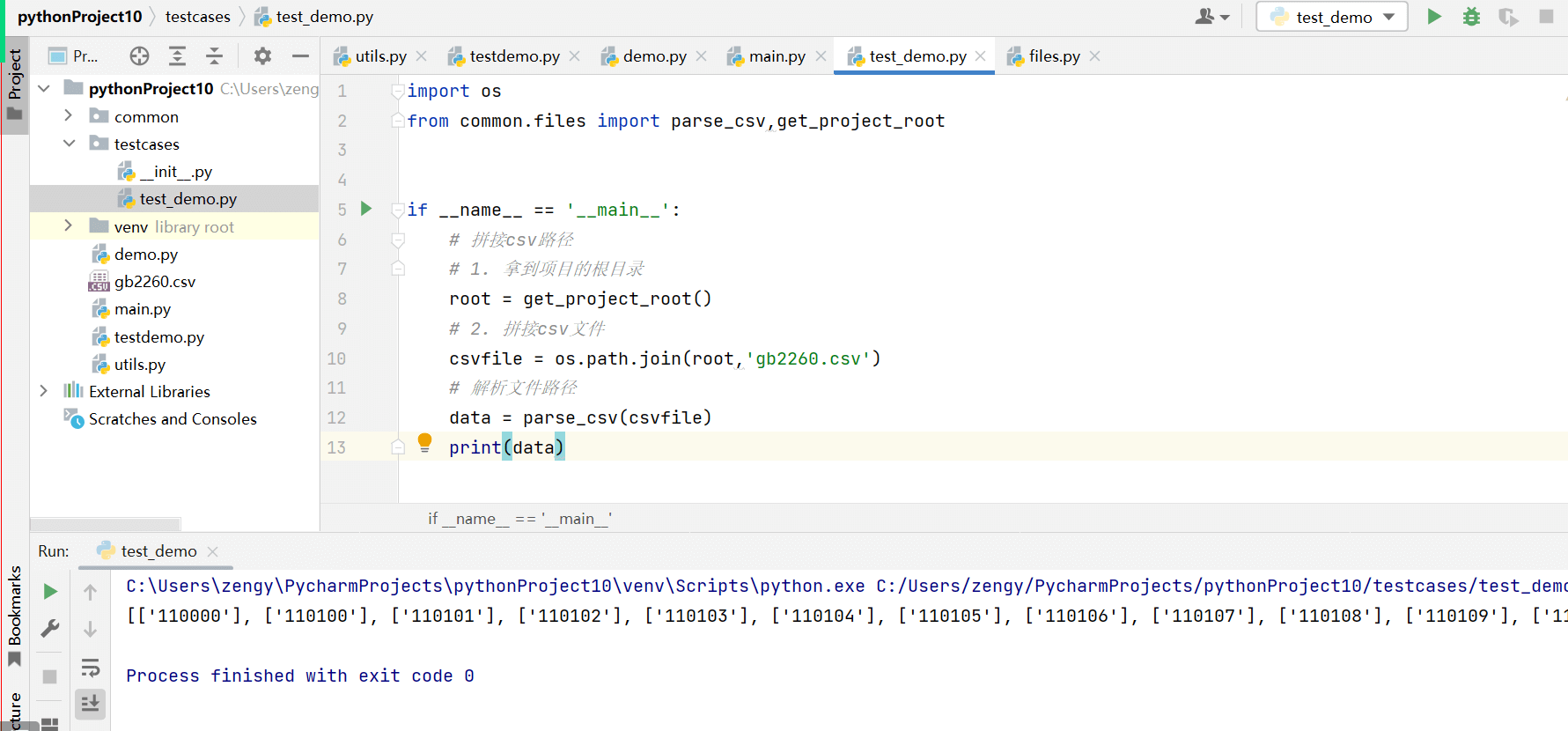
现在在test_demo.py 文件解析 gb2260.csv 文件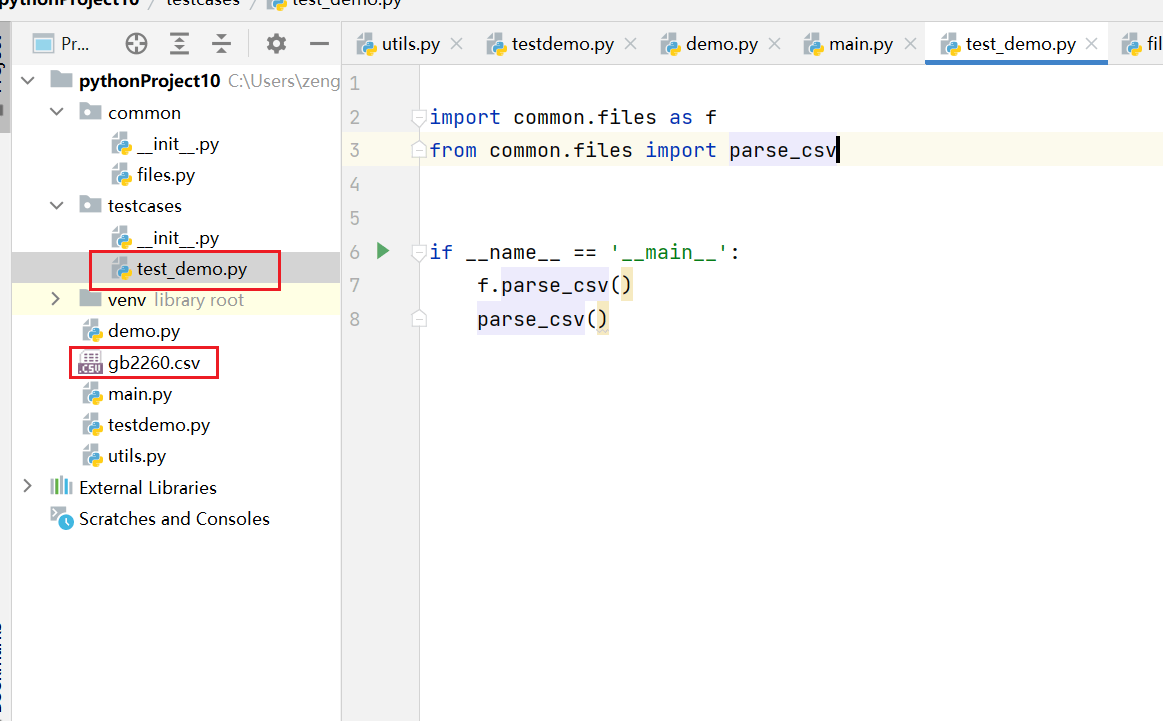
通过获取项目的根目录来拼接路径 进行操作。
testcases/test_demo.py
import os
from common.files import parse_csv,get_project_root
if __name__ == '__main__':
# 拼接csv路径
# 1. 拿到项目的根目录
root = get_project_root()
# 2. 拼接csv文件
csvfile = os.path.join(root,'gb2260.csv')
# 解析文件路径
data = parse_csv(csvfile)
print(data)
多层目录引用文件

testcases/test_csv/test_file.py
import os
from common.files import parse_csv,get_project_root
if __name__ == '__main__':
# 拼接csv路径
# 1. 拿到项目的根目录
root = get_project_root()
# 2. 拼接csv文件
csvfile = os.path.join(root,'gb2260.csv')
# 解析文件路径
data = parse_csv(csvfile)
print(data)
在这个文件,通过调用封装好的 获取项目根目录路径的方法 在任何地方调用,都可以取到项目的根目录,再进行路径拼接。就可以调用里面的方法。
项目数据文件解析
在做一个项目的时候,需要对单接口做csv数据参数化,每个接口需要准备对应的csv文件。如果有很多csv文件,需要将csv文件放在对应目录中。
在项目中 创建 testdata 目录,这个目录用来存放测试数据。
创建目录
目录名称为 testdata
在testdata 目录中放入 csv文件
解析testdata 目录中的csv文件
testcases/test_demo.py
import os
from common.files import parse_csv,get_project_root
if __name__ == '__main__':
# 拼接csv路径
# 1. 拿到项目的根目录
# root = get_project_root()
# # 2. 拼接csv文件
# csvfile = os.path.join(root,'gb2260.csv')
# # 解析文件路径
# data = parse_csv(csvfile)
# print(data)
# 1. 获取系统的根目录
root = get_project_root()
# 2. 拿到文件路径
topic_csv = os.path.join(root,'testdata/testtopic.csv')
# 解析文件
data = parse_csv(topic_csv)
print(data)

附件
所有对应的代码
demo.zip
作业
在项目的common包下创建 utils.py 文件 实现生成手机号码 和身份证id的函数
def generate_id():
"""
生成一个随机的身份证号 并返回
:return:
"""
def generate_phone():
"""
生成一个随机的 11位手机号码
:return:
"""
答案
def generate_phone():
"""
生成一个随机的 11位手机号码
:return:
"""
#确定前两位手机
pre_2 =["13","14","15","16","17","18"]
# 随机选择一个元素
p2 = random.choice(pre_2)
# 生成9位随机数字
l9 = ""
for i in range(9):
# 每次循环生成一个随机数字
n = random.randint(0,9)
l9 = l9+str(n) # 将数字转换为字符串之后进行拼接
return p2+l9
if __name__ == '__main__':
phone = generate_phone()
print(phone)
import random
from common.files import get_project_root,parse_csv
import os
def generate_id():
"""
生成一个随机的身份证号 并返回
:return:
"""
# 拿到项目根目录
root = get_project_root()
# 拼接csv文件
file_csv = os.path.join(root,'gb2260.csv')
# 通过解析csv文件获取所有的地区编码
all_code = parse_csv(file_csv)
print(all_code)
# 随机选择一个列表
code = random.choice(all_code)
print(code)
# 列表转换为字符串
p6 = ''.join(code)
print(p6)
# 设置出生年月日
year = random.randint(1960,2020)
month = random.randint(1,12)
# 闰年 2月份 29天
if year%4==0 and month == 2:
day=random.randint(1,29)
# 31天
elif month in [1,3,5,7,8,10,12]:
day = random.randint(1,31)
elif month in [4,6,9,11]:
day = random.randint(1,30)
# 平年的2月 28天
else:
day = random.randint(1,28)
# month ,day 小于10 前面补0
if month<10:
#转换为字符串
month = f'0{month}'
if day <10:
day = f'0{day}'
# 合并年月日 转换为字符串
ymd = f'{year}{month}{day}'
print(ymd)
# 获取最后4位 最后一位X
l3 = ""
for i in range(3):
n = random.randint(0,9)
# 数字转换字符串 拼接
l3 = l3+str(n)
l1 = list(range(10))
l1.append("X") # [0,1,2,3,4,5,6,7,8,9,"X"]
print(l1)
l = random.choice(l1) # 最后1位
l4 = l3 + str(l) # 最后4位
return f'{p6}{ymd}{l4}'
if __name__ == '__main__':
id=generate_id()
print(id)
最终文件
import random
from common.files import get_project_root,parse_csv
import os
def generate_id():
"""
生成一个随机的身份证号 并返回
:return:
"""
# 拿到项目根目录
root = get_project_root()
# 拼接csv文件
file_csv = os.path.join(root,'gb2260.csv')
# 通过解析csv文件获取所有的地区编码
all_code = parse_csv(file_csv)
# print(all_code)
# 随机选择一个列表
code = random.choice(all_code)
# print(code)
# 列表转换为字符串
p6 = ''.join(code)
#print(p6)
# 设置出生年月日
year = random.randint(1960,2020)
month = random.randint(1,12)
# 闰年 2月份 29天
if year%4==0 and month == 2:
day=random.randint(1,29)
# 31天
elif month in [1,3,5,7,8,10,12]:
day = random.randint(1,31)
elif month in [4,6,9,11]:
day = random.randint(1,30)
# 平年的2月 28天
else:
day = random.randint(1,28)
# month ,day 小于10 前面补0
if month<10:
month = f'0{month}'
if day <10:
day = f'0{day}'
# 合并年月日 转换为字符串
ymd = f'{year}{month}{day}'
# print(ymd)
# 获取最后4位 最后一位X
l3 = ""
for i in range(3):
n = random.randint(0,9)
# 数字转换字符串 拼接
l3 = l3+str(n)
l1 = list(range(10)) #生成[0,1,2,3,4,5,6,7,8,9] 列表
l1.append("X") # [0,1,2,3,4,5,6,7,8,9,"X"]
# print(l1)
l = random.choice(l1) # 随机从列表中选择一个
l4 = l3 + str(l) # 最后4位
return f'{p6}{ymd}{l4}'
def generate_phone():
"""
生成一个随机的 11位手机号码
:return:
"""
#确定前两位手机
pre_2 =["13","14","15","16","17","18"]
# 随机选择一个元素
p2 = random.choice(pre_2)
# 生成9位随机数字
l9 = ""
for i in range(9):
# 每次循环生成一个随机数字
n = random.randint(0,9)
l9 = l9+str(n) # 将数字转换为字符串之后进行拼接
return p2+l9
if __name__ == '__main__':
id = generate_id()
print(f'最终生成的id:{id}')


若有收获,就点个赞吧
0 人点赞
