Linux中 grep, awk, sed 三个命令在进行日志处理的时候使用的比较多。被称为 Linux 三剑客
grep 过滤文本
- 查看 /etc/passwd 文件。
过滤出包含 nologin
grep "nologin" /etc/passwd

- 过滤出所有的数字并高亮
[0-9] 表示所有的数字
grep '[0-9]' /etc/passwd
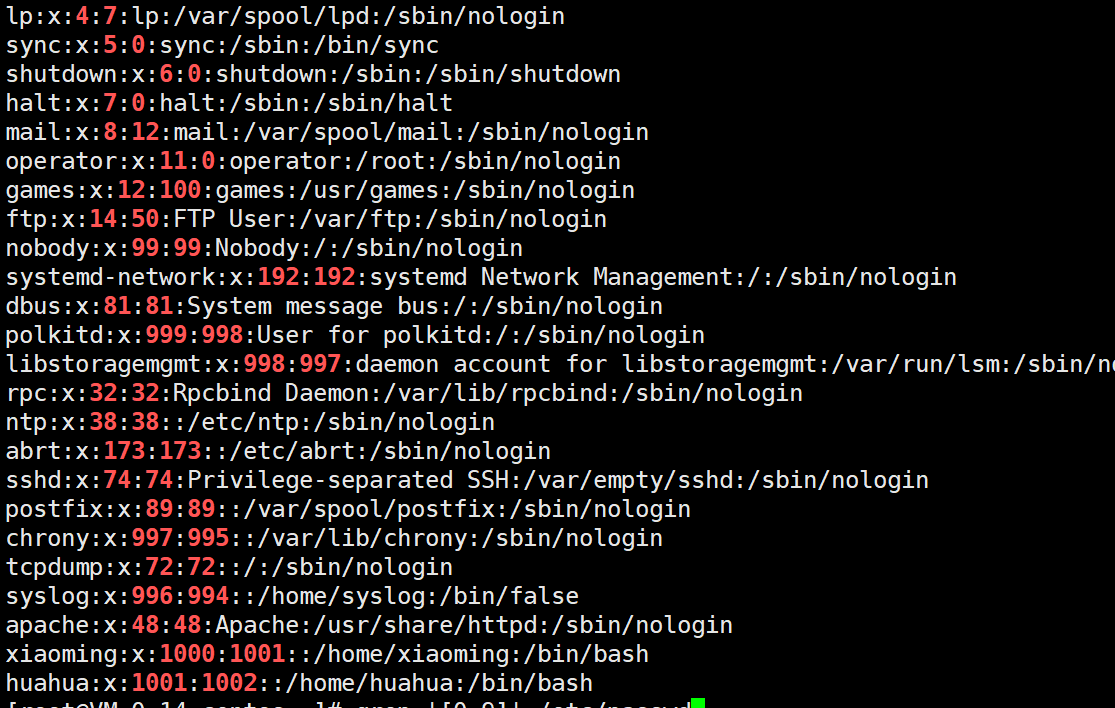
[a-z] 表示小写的 26个英文字符
grep '[a-z]' /etc/passwd
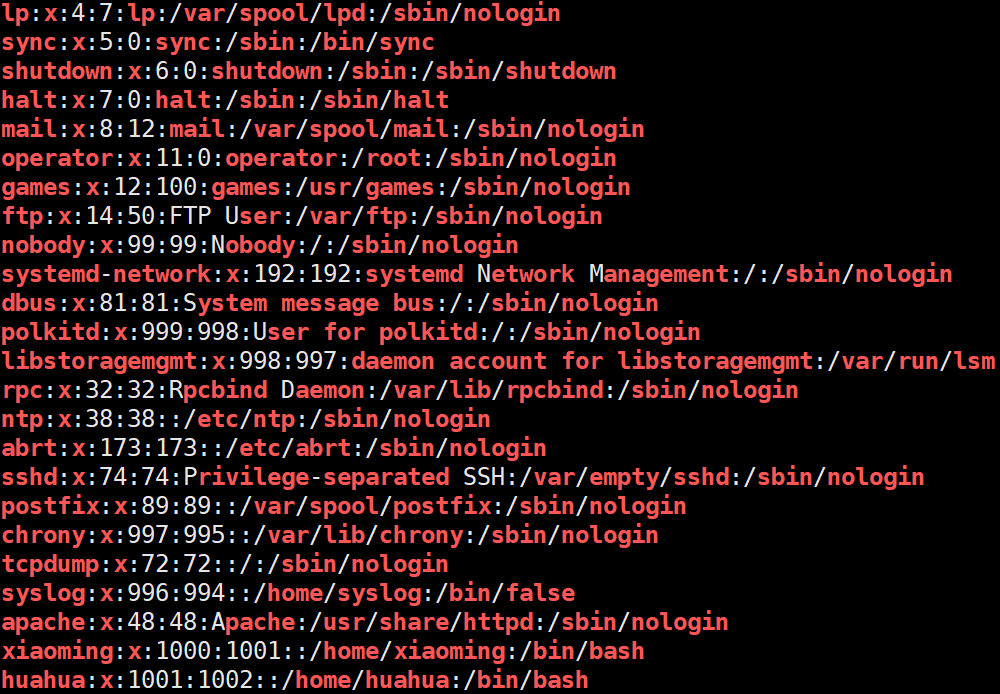
[0-9A-Za-z] 表示数字和英文
grep '[a-zA-Z0-9]' /etc/passwd
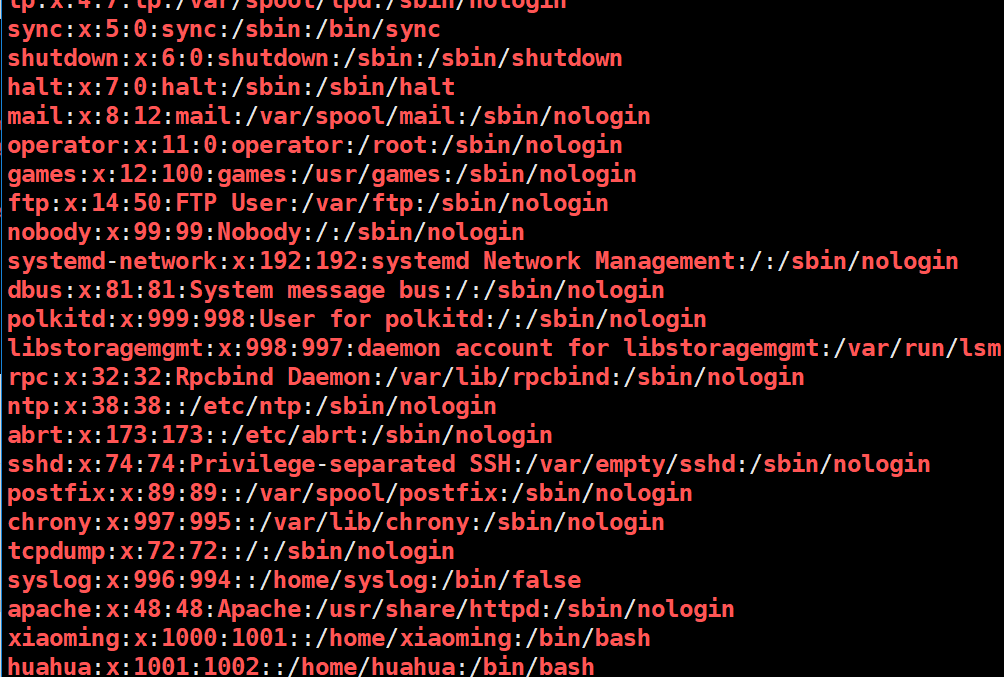
附件
https://www.bilibili.com/video/BV1Xh411U78D/
点击查看【bilibili】
awk 处理文本
查看文件 cat /opt/zbox/logs/apache_access.log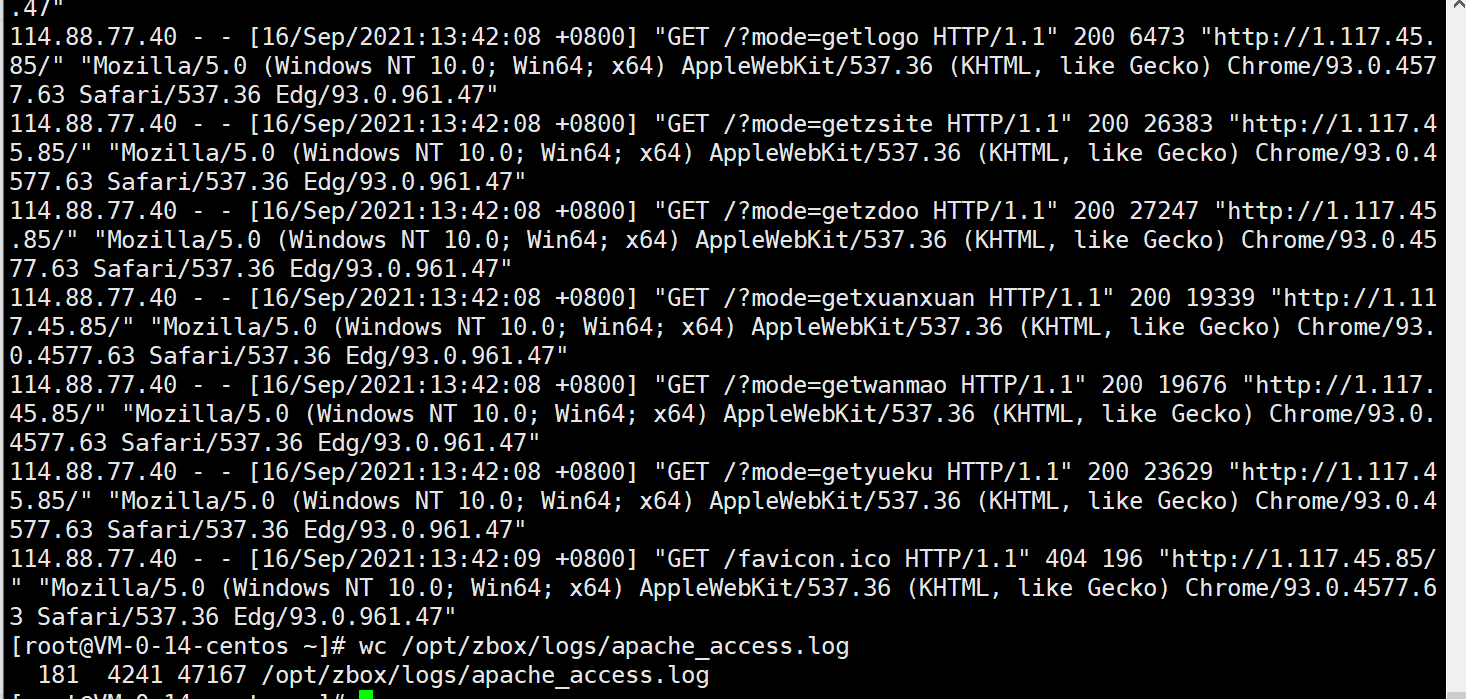
里面的内容有很多
- 我只想查看日志中 ip
awk '{ print $1}' /opt/zbox/logs/apache_access.log
'{ print }'打印输出,固定写法- $1 第一列的内容
sort 排序
对上面的ip地址继续排序awk '{ print $1}' /opt/zbox/logs/apache_access.log | sort
uniq 去除重复
去除重复并排序 ```shell [root@VM-0-14-centos ~]# awk ‘{ print $1}’ /opt/zbox/logs/apache_access.log | sort | uniq 103.123.42.226 107.189.14.98 114.88.77.40 155.4.66.65 167.248.133.44 168.194.176.195 175.10.45.22 199.195.248.54 212.69.18.96 218.82.175.249 218.82.229.162 45.180.194.183 66.240.192.82awk '{ print $1}' /opt/zbox/logs/apache_access.log | uniq
去除重复并排序并统计出现的次数```shell[root@VM-0-14-centos ~]# awk '{ print $1}' /opt/zbox/logs/apache_access.log | sort | uniq -c1 103.123.42.2261 107.189.14.98155 114.88.77.401 155.4.66.652 167.248.133.441 168.194.176.1951 175.10.45.221 199.195.248.541 212.69.18.9614 218.82.175.2491 218.82.229.1621 45.180.194.1831 66.240.192.82
sed 文件
- 编辑文件 /tmp/helloworld.txt ```shell hi, what is your name? my name is hanmeimei, and you? nice to meet you.
2. 将文件中的内容 `you` 替换为 `he````shellsed -i 's/you/he/' /tmp/helloworld.txt
- -i 覆盖文件内容
- s/you/he/ 搜索you并替换he

若有收获,就点个赞吧
0 人点赞
