主要的内容
数据库连接
数据库地址: rm-bp188nr95fk4l9545ao.mysql.rds.aliyuncs.com端口号:3306用户名:fanmao85密码:123@fanmao

- 查找student表中年龄最大的出生日期。 ```python
SELECT min(sbirthday) from student;
SELECT sbirthday FROM student ORDER BY sbirthday LIMIT 1;
2. 查找student表中年龄最大的同学。```pythonSELECT * from student WHERE sbirthday = (SELECT min(sbirthday) from student);SELECT * from student WHERE sbirthday = (SELECT sbirthday FROM student ORDER BY sbirthday LIMIT 1);
- 查找student表中年龄第二大的同学。 ```python — 去重 SELECT DISTINCT(sbirthday) from student ORDER BY sbirthday LIMIT 1,1
SELECT * from student WHERE sbirthday = ( SELECT DISTINCT(sbirthday) from student ORDER BY sbirthday LIMIT 1,1 )
4. 统计每个班级的学生人数;```pythonSELECT class,count(*) from studentGROUP BY class;
- 每个班级的男生人数; ```python
SELECT class,count(*) from student WHERE ssex = “男” GROUP BY class;
6. 每个班级的年龄最大的同学;```pythonselect class, min(sbirthday) FROM studentGROUP BY class;-- 根据条件找到对应的人员SELECT * from studentWHERE (class,sbirthday) in (select class, min(sbirthday) FROM studentGROUP BY class)
- 班级人数大于90的班级,人数。
SELECT class, count(*) from studentGROUP BY class HAVING COUNT(*) > 90;
多表查询
- 每门课都及格的同学 姓名 ,班级。
使用min函数, 最低分大于等于 60 表示其他科目也是 大于等于60的。
select s1.sno, s1.sname, s1.class, s2.degree from student as s1INNER JOIN score as s2ON s1.sno = s2.snoWHERE s1.sno in (select sno from scoreGROUP BY sno HAVING MIN(degree)>= 60)ORDER BY s2.degree;
- 统计每个学生的考试成绩总分,没有考试成绩的话 总分为0, 输出 学号,姓名,总分;
主要考察两个知识点:
- left join 以学生表为主,统计所有学生表的数据。没有与之对应的数据则显示为Null
- ifnull 函数,如果为空则显示 为0.
select s1.sno, s1.sname, IFNULL(sum(s2.degree), 0) from student as s1LEFT JOIN score as s2 on s1.sno = s2.snoGROUP BY s1.sno, s1.snameORDER BY sum(s2.degree)
相关的练习

- 查询学生对应的老师 (内联) ```sql
SELECT * FROM w_stu INNER JOIN w_teacher ON w_stu.t_id = w_teacher.ID;
2. 每个学生对应的老师 (左联)```sqlSELECT * FROM w_stuLEFT JOIN w_teacherON w_stu.t_id = w_teacher.ID
- 所有学生以及对应的所有老师 (union) ```sql SELECT * FROM w_stu LEFT JOIN w_teacher ON w_stu.t_id = w_teacher.ID
UNION
SELECT * FROM w_stu RIGHT JOIN w_teacher ON w_stu.t_id = w_teacher.ID;
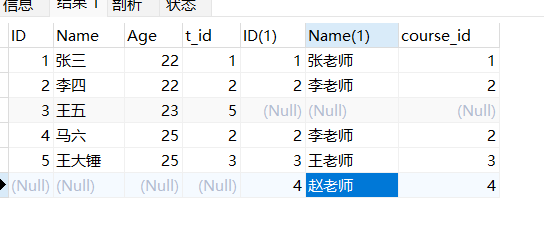<br />使用union all 进行拼接,不会去重。```sqlSELECT * FROM w_stuLEFT JOIN w_teacherON w_stu.t_id = w_teacher.IDUNION ALLSELECT * FROM w_stuRIGHT JOIN w_teacherON w_stu.t_id = w_teacher.ID;
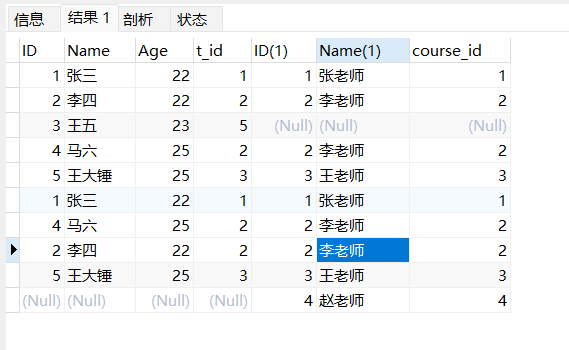
时间,日期相关🎈
查询最近3天的订单信息。
SELECT * from orders WHERE DATEDIFF(NOW(),create_time) >3SELECT DATE_SUB(NOW(),INTERVAL 3 DAY); -- 最近1个月的订单 SELECT * from orders WHERE create_time > DATE_SUB(NOW(),INTERVAL 3 DAY)查询最近1周的订单信息。 ```sql — 一周之前的今天
SELECT DATE_SUB(NOW(),INTERVAL 1 WEEK); — 最近1个月的订单 SELECT * from orders WHERE create_time > DATE_SUB(NOW(),INTERVAL 1 WEEK)
3. 查询最近1个月的订单信息。
```sql
-- 上个月的今天
SELECT DATE_SUB(NOW(),INTERVAL 1 MONTH);
-- 最近1个月的订单
SELECT * from orders
WHERE create_time > DATE_SUB(NOW(),INTERVAL 1 MONTH)
- 查询最近1年的订单信息。 ```sql — 1年前的今天 select date_sub(now(),interval 1 year)
— 最近1年的订单
SELECT * from orders where create_time > date_sub(now(),interval 1 year)
<a name="G9bEk"></a>
## case .. when .. then.. else
1. 给你一个这样的数据库表数据
| Y | M | Amount |
| --- | --- | --- |
| 2020 | 1 | 101 |
| 2020 | 2 | 102 |
| 2020 | 3 | 103 |
| 2021 | 1 | 201 |
| 2021 | 2 | 202 |
| 2021 | 3 | 203 |
请写一个SQL,得出如下结果:
| Y | M1 | M2 | M3 |
| --- | --- | --- | --- |
| 2020 | 101 | 102 | 103 |
| 2021 | 201 | 202 | 203 |
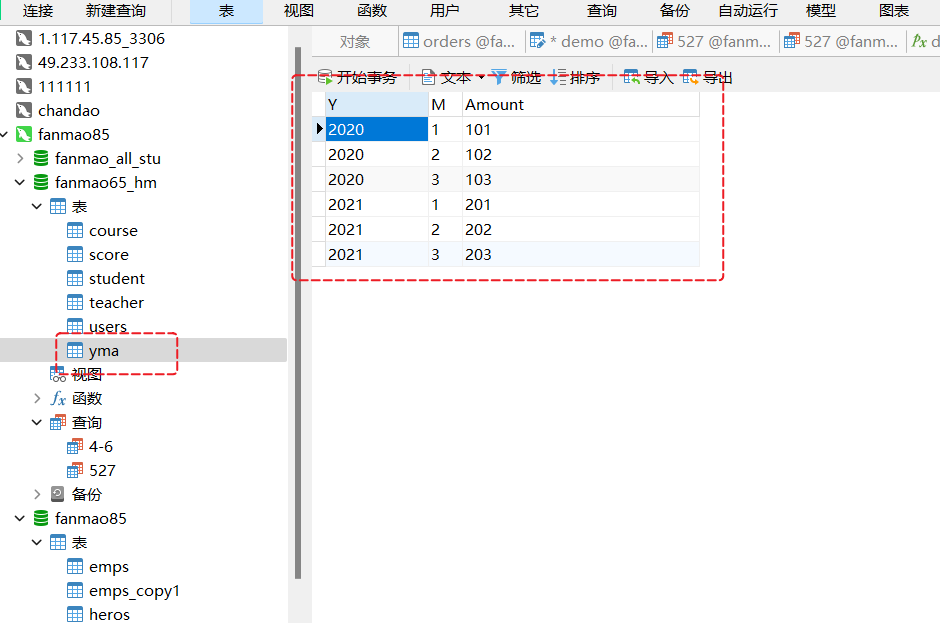
1. 使用case when then 语法 分别创建 M1 M2 M3
```sql
SELECT Y,
case WHEN m=1 THEN Amount else 0 end as M1,
case when m=2 THEN Amount else 0 end as M2,
case when m=3 THEN Amount else 0 end as M3
FROM yma

要将数据分组 根据 Y 分组 ,配置使用 Max 最大值获取数据。
SELECT Y,
max(case WHEN m=1 THEN Amount else 0 end )as M1,
max(case when m=2 THEN Amount else 0 end )as M2,
max(case when m=3 THEN Amount else 0 end ) as M3
FROM yma
GROUP BY Y;
面试的问题
- 表中某一列的数据有很多重复的,如何去重?
- 使用distinct 可以进行去重。
- 使用group by 进行分组去重。
- count(*), count(1), count(列名) 之间的区别?
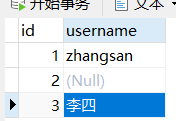
SELECT COUNT(*) from demo; -- 3
SELECT COUNT(1) from demo; -- 3
SELECT COUNT(username) from demo; -- 2
查询结果上, 当列的数据中有Null
- count(*), count(1) 统计数据结果 是一样的。只要这一行的任意列中有内容,就统计进来。
- count(username) 只统计 username 这一列的内容,统计数据中没有Null的总数。
执行效率上
- 列名为主键,count(列名)会比count(1)快
- 列名不为主键,count(1)会比count(列名)快
- 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
- 如果有主键,则 select count(主键)的执行效率是最优的
- 如果表只有一个字段,则 select count(*)最优。
- 数据中多表联查 主要的语法有哪些?
内联(inner join),左联(left join),右联(right join) 外联 (mysql中没有外联,但是可以使用 union, Oracle中使用 full join),
- 内联,左联的区别?
内联 会将两个表中共有部分显示出来。
左联 是以左表为主,显示左表中所有的数据,如果另外一张表中没有对应的数据,显示为Null。
- 全连接怎么做?
mysql 中没有全连接的语句,但是可以通过使用union 拼接两条sql语句将结果合并到一起(union 可以将结果去重,union all 不会去重)。
Oracle数据中可以使用full join 或者 full outer join。
- 数据库中函数使用的有哪些?
比较常用的像聚合函数: max ,min, avg, sum,count,也会用到一些其他的比如 ifnull,日期,时间相关的函数,比如我们在测试一些报表数据的时候,统计本月,上周,最近三个月,最近1年的时候,会使用到 now(), date_format,datediff, date_sub 相关的函数。
- 删除数据表的方法有哪些?
drop table 将整个表数据删除 表不会存在/
truncate table 清空表中的数据,但是表还存在。
delete 删除表中的某一行数据 或者某些行数据。
- 存储过程了解吗?
存储过程,在公司的数据库中 没有开放权限,但是我也知道基本的语法。比如一些复杂的sql 语句,就可以定义为存储过程,使用的时候,直接通过调用存储过程名字就可以了。会比较方便。
另外一个使用场景,批量造数据的时候,也可以使用存储过程的方式来批量添加数据,将插入数据语句放到 存储过程中,通过循环方式来做。
- 如何往数据库中添加1w条数据?
可以通过使用存储过程的方式;
使用Python代码循环连接数据库插入数据;
使用Jmeter 调用接口,设置线程组和运行次数来添加;
使用 Jmeter JDBC 连接数据库, 设置线程组 批量插入数据。
在Excel 生成数据,使用navicat 工具导入数据库。
- 事务了解吗? 举个例子说明以下。
事务主要就是有相关联的业务表能够同时进行修改或者更新数据,比如前端下订单。后台数据库中
- 订单表中会增加1条新记录;
- 库存表中改商品的库存会减少1;
这两张要求都要有对应的修改。这就是一个事务。如果其中一张表没有修改,那就是bug。
- 数据库中的数据比较多,查询速度比较慢 怎么办?
一般查询优化是由开发 运维他们做的,但是我也知道一些,常用的优化方式使用索引,给数据表添加索引,可以提高查询速度。主要公司中开发做的。
- 数据库中的锁机制有哪些?
悲观锁
当3个请求访问数据库中的资源的时候,其中一个请求会获取到锁,而其他两个请求会在外面进行等待,等第一个请求访问完之后会释放锁,然后下一个请求获取锁然后访问,然后一直循环刚刚的操作
获取锁—-访问完数据库,释放锁——下一个请求获取锁——访问完成,释放锁。。。。。一直重复循环这个步骤
乐观锁
当3个请求同时访问服务器的时候,都可以对服务器中的数据进行更改,更改完之后提交,第一个提交的请求可以成功,其他两个请求都会失败。然后那他两个请求需要重复刚刚的操作。
3个请求访问数据库——第1个修改完然后提交成功——-其他两个也提交然后显示操作失败,请重试——重复刚刚的操作
区别:
悲观锁:对数据处理持以悲观的状态,认为肯定会发生数据冲突,修改数据的时候,别人也会修改;保证数据的安全性,但是降低了性能。
乐观锁:对数据处理持以乐观的态度,认为一般不会发生数据冲突,只有提交数据的时候会检测版本号是否与当前版本号一致。提高了性能,但是会发生冲突,让用户进行重复的操作,反而会降低性能,高并发的情况下悲观锁更加实用一些。
思维导图


若有收获,就点个赞吧
0 人点赞
