基础练习
- 定义一个函数,生成一个随机的姓名。
fristname.txt 所有的姓
name.txt 名字、
自动化测试的应用场景: 在做接口测试时 申请贷款接口需要人名。随机生成一个姓名。
思路:
将文件中内容读取(解析)出来,放到列表中,通过随机函数随机选择一个。
# 集合数据 有去重功能with open('name.txt',mode='r',encoding='utf8') as f:data = f.readlines()# 转换为集合data = set(data)# print(data)# 循环处理strname = ""for name in data:if name != "\n":name=name.replace(',\n',',')# print(name)strname= strname+name# 字符串去掉空格strname = strname.strip()# str 转换为listnamelist = strname.split(',')# print(namelist)with open('fristname.txt', mode='r', encoding='utf8') as f:data = f.readlines()# print(data)first_names = []for firstnames in data:fnames = firstnames.strip()fn = fnames.split(',')# print(fn)first_names.extend(fn)# print(first_names)import randomf = random.choice(first_names)n = random.choice(namelist)print(f+n)
随机生成电话号码。
def generate_phone(): """ 生成一个随机的 11位手机号码 :return: """ #确定前两位手机 pre_2 =["13","15","17","18"] # 随机选择一个元素 p2 = random.choice(pre_2) # 生成9位随机数字 l9 = "" for i in range(9): # 每次循环生成一个随机数字 n = random.randint(0,9) l9 = l9+str(n) # 将数字转换为字符串之后进行拼接 return p2+l9随机生成身份证号。
def generate_id(): """ 生成一个随机的身份证号 并返回 :return: """ # 拿到项目根目录 root = get_project_root() # 拼接csv文件 file_csv = os.path.join(root,'gb2260.csv') # 通过解析csv文件获取所有的地区编码 all_code = parse_csv(file_csv) # print(all_code) # 随机选择一个列表 code = random.choice(all_code) # print(code) # 列表转换为字符串 p6 = ''.join(code) #print(p6) # 设置出生年月日 year = random.randint(1960,2020) month = random.randint(1,12) # 闰年 2月份 29天 if year%4==0 and month == 2: day=random.randint(1,29) # 31天 elif month in [1,3,5,7,8,10,12]: day = random.randint(1,31) elif month in [4,6,9,11]: day = random.randint(1,30) # 平年的2月 28天 else: day = random.randint(1,28) # month ,day 小于10 前面补0 if month<10: month = f'0{month}' if day <10: day = f'0{day}' # 合并年月日 转换为字符串 ymd = f'{year}{month}{day}' # print(ymd) # 获取最后4位 最后一位X l3 = "" for i in range(3): n = random.randint(0,9) # 数字转换字符串 拼接 l3 = l3+str(n) l1 = list(range(10)) l1.append("X") # [0,1,2,3,4,5,6,7,8,9,"X"] # print(l1) l = random.choice(l1) # 最后1位 l4 = l3 + str(l) # 最后4位 return f'{p6}{ymd}{l4}'自动化练习
参数化练习
使用pytest+requests+csv 进行单接口的参数化测试
数据文件:home_topics.csv ```python import requests import pytest
编写代码,读取csv文件中的内容,读取成功之后将数据赋值给home_data 能够让这个测试用例跑起来
@pytest.mark.parametrize(“tab,limit,expect_tab,expect_limit”,home_data) def test_home_page(tab,limit,expect_tab,expect_limit): url = “http://47.100.175.62:3000/api/v1/topics“ querydata = { “tab”:tab, “limit”:limit } r = requests.get(url,params=querydata)
#断言tab值
for topic in r.json()["data"]:
assert topic["tab"] == expect_tab
# 断言limit
assert len(r.json()["data"]) == expect_limit
参考:[https://gitee.com/imzack/auto_aptest/blob/master/testcases/test_cnode_each_api.py](https://gitee.com/imzack/auto_aptest/blob/master/testcases/test_cnode_each_api.py)
```python
import requests
import pytest
# 编写代码,读取csv文件中的内容,读取成功之后将数据
import csv
home_data = []
# 解析csv文件中的内容
with open('home_topics.csv',mode='r',encoding='utf8') as f:
data = csv.reader(f)
# 第一行数据不需要
next(data) # 去掉第一行
# 从第二行数据开始迭代
for line in data:
print(line)
# 将数据追加到list
home_data.append(tuple(line))
print("data",home_data)
@pytest.mark.parametrize("tab,limit,expect_tab,expect_limit",home_data)
def test_home_page(tab,limit,expect_tab,expect_limit):
url = "http://47.100.175.62:3000/api/v1/topics"
querydata = {
"tab":tab,
"limit":int(limit) # csv文件中读出来的时候时 字符串,将字符串转换为int
}
r = requests.get(url,params=querydata)
#断言tab值
for topic in r.json()["data"]:
assert topic["tab"] == expect_tab
# 断言limit
assert len(r.json()["data"]) == int(expect_limit) # 从csv文件中读取出来的时候为字符串类型,转换格式为int数字。
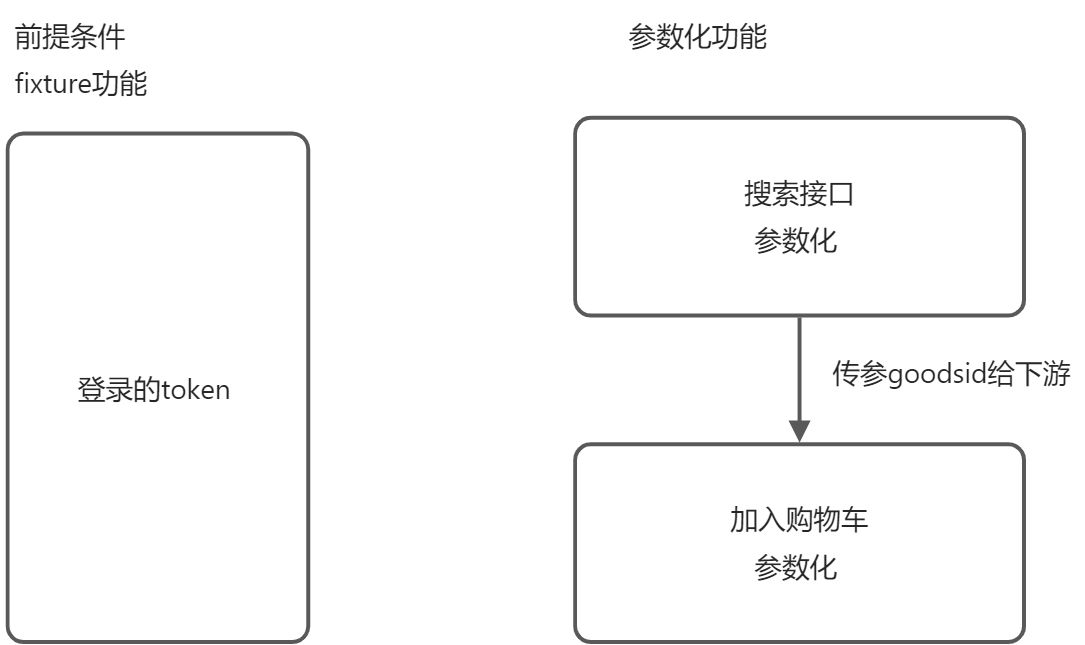
上下游传参+参数化
需要对两个接口进行参数化测试
- 搜索商品接口
- 添加购物车
做这两个接口的前提条件是 用户已经成功登录,获取到token值。
通过使用 pytest的脚手架功能 @pytest.fixture 将登录操作放进来生成token值。
'''
新丰商城 单接口测试
'''
import pytest
from common.utils import generate_phone
import requests
testdata={
"token":"",
"goodsid":0 # 商品的id
}
base_url = "http://49.233.108.117:28019"
# 注册,登录使用的是同一个手机号码 定义变量
phone = generate_phone()
#scope="module" 模块级别, 整个python文件运行之前和之后的操作 整个文件运行之前生成1个token
@pytest.fixture(scope="module",autouse=True)
def token():
# 脚手架中注册并登录一个账号
# 注册用户
url = base_url+"/api/v1/user/register"
body_data = {
"loginName": phone,
"password": "123456"
}
# 发送请求
requests.post(url,json=body_data)
# 登录用户
url = base_url + "/api/v1/user/login"
body_data = {
"loginName": phone,
"passwordMd5": "E10ADC3949BA59ABBE56E057F20F883E"
}
r = requests.post(url, json=body_data)
# 设置 token
# 提取变量值 token
testdata["token"] = r.json()["data"]
# 运行之前的所有操作
print("已经成功获取一个token值",r.json()["data"])
yield
search_data=['iphone','小米','华为']
@pytest.mark.parametrize("key",search_data)
def test_search(key):
url = base_url+'/api/v1/search'
header={
"token": testdata["token"]
}
query_data={
"keyword":key
}
# 搜索条件为 iphone
r = requests.get(url, params=query_data, headers=header)
# 断言
# 所有搜索结果中都包含iphone
# 拿到所有的商品信息
allgoods = r.json()["data"]["list"]
# 循环所有商品的时候
for good in allgoods:
print(good)
# 拿到每个商品的名称
goodname = good["goodsName"]
# print('商品的名称', goodname) # 因为返回结果中有大小写字母混合的场景。使用字符串转换大写方法
assert key.upper() in goodname.upper() # upper 将字符串转为大写
# 提取商品id 给下游接口
testdata["goodsid"] = good["goodsId"]
print("传递的参数数据",testdata["goodsid"])
#商品的id 从搜索接口中获取
cart_data = [
(0,0),
("${goodsid}",0), # ${goodsid} 表示具体的商品id
("${goodsid}",1),
("${goodsid}",10)
]
@pytest.mark.parametrize("goodsId,count",cart_data)
def test_add_cart(goodsId,count):
if goodsId =="${goodsid}":
goodsId = testdata["goodsid"] # 替换为具体的值
url = base_url+"/api/v1/shop-cart"
body_data ={
"goodsCount": count,
"goodsId": goodsId
}
header = {
"token": testdata["token"]
}
print("加入购物车数据",body_data)
r = requests.post(url,json=body_data,headers=header)
print("购物车返回结果",r.json())
运行可以看到执行的结果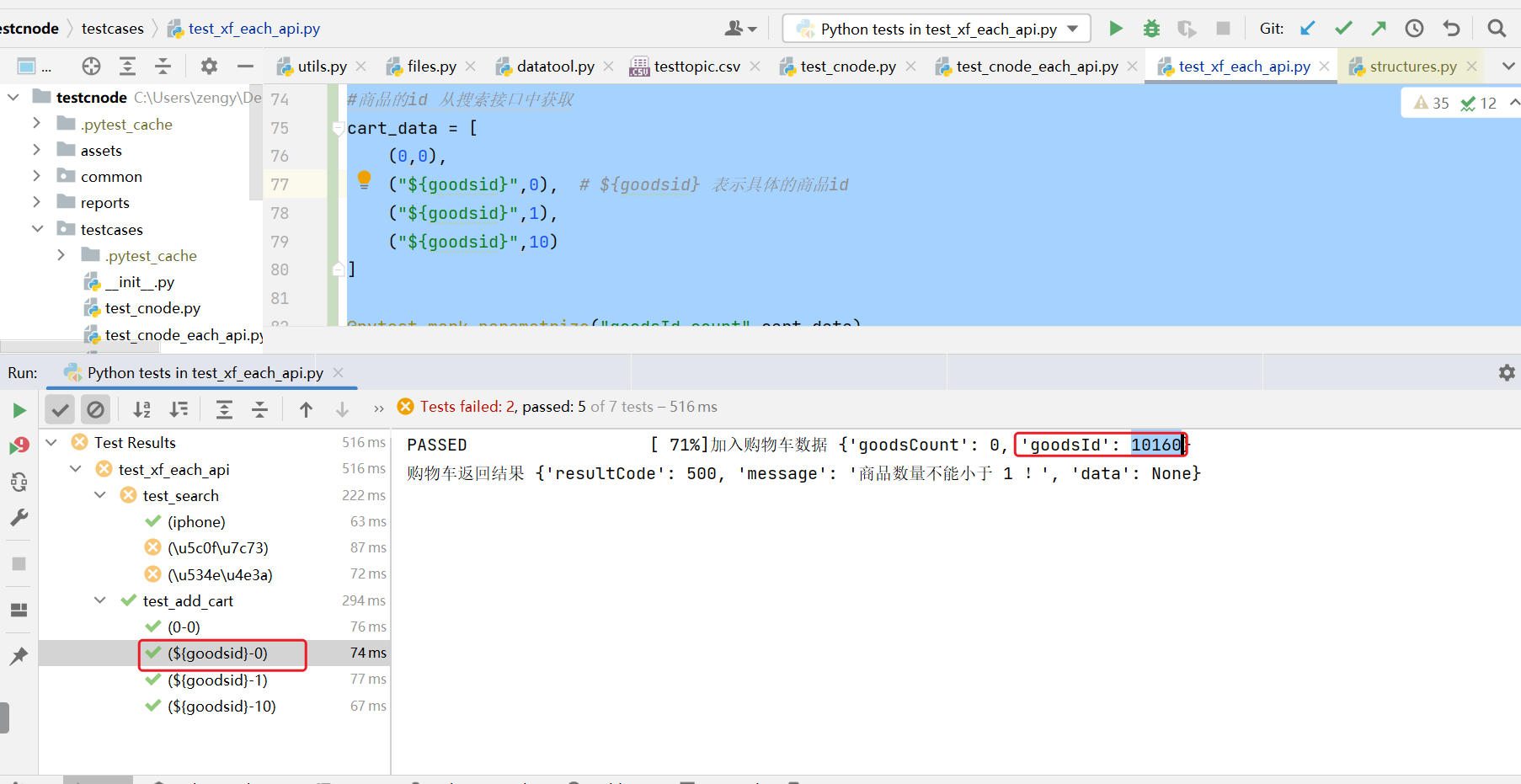

若有收获,就点个赞吧
0 人点赞
