存储过程
如何往数据库中插入1w条数据?
创建表
student_0000
| id 自增主键 int(10) | name varchar(50) not null |
|---|---|
CREATE TABLE `project60`.`student_0000` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(50) NOT NULL,PRIMARY KEY (`id`));
添加数据
当表创建好之后,插入数据可以使用insert into 语句进行数据插入
INSERT INTO `project60`.`student_0000`(`name`) VALUES ('张三');
上面语句只能插入一条数据。
如果一条一条手动去添加数据,效率会非常的慢。
数据库支持 存储过程。 使用存储过程可以进行批量的添加操作
存储过程的基本语法
delimiter $$ -- 将语句结束符临时设置为 $$CREATE PROCEDURE add_data_0000() -- 创建存储过程, add_data 可以随意命名BEGIN -- begin end 固定写法-- 设置初始变量i 初始值为0DECLARE i INT DEFAULT 1;WHILE i < 10000 DO -- 当i的值小于10000的时候 做下面的事情 substring(MD5(RAND()),1,20) 随机生成字符串INSERT INTO student_0000 (name) VALUES (CONCAT("王",substring(MD5(RAND()),1,20))); -- 执行sql语句SET i = i+1; -- 每次执行 i的值增加1END WHILE;END$$ -- 存储过程创建结束delimiter ; -- 语句结束符再次改为 ;
10000 改为自己需要批量添加的数字INSERT INTO student_0000 (name) VALUES (CONCAT("王",substring(MD5(RAND()),1,20)));
改为插入自己库的语句。
SELECT * FROM student_0000 ORDER BY id DESC LIMIT 10;-- 调用存储过程CALL add_data_0000();
使用参数
delimiter $$ -- 将语句结束符临时设置为 $$ -- in 表示调用存储过程的传值, num 变量 int 表示类型 传入一个num 数字CREATE PROCEDURE add_data_0000(IN num INT ) -- 创建存储过程, add_data 可以随意命名BEGIN -- begin end 固定写法-- 设置初始变量i 初始值为0DECLARE i INT DEFAULT 0;WHILE i < num DO -- 当i的值小于10000的时候 做下面的事情 substring(MD5(RAND()),1,20) 随机生成字符串INSERT INTO student_0000 (name) VALUES (CONCAT("王",substring(MD5(RAND()),1,20))); -- 执行sql语句SET i = i+1; -- 每次执行 i的值增加1END WHILE;END$$ -- 存储过程创建结束delimiter ; -- 语句结束符再次改为 ;-- 添加100条数据CALL add_data_0000(100);-- 添加100000条数据CALL add_data_0000(100000);select count(*) from student_0000;
索引
在网络正常的情况下,在前端进行搜索,搜索之后要等30秒才看到结果。
创建数据库
导入test.sql 文件
test.sql
数据库中有三张表
执行sql语句
select count(*) from (selectschedule_id, schedule_code ,resource_code, schedule_type, schedule.oper_id, schedule.oper_time,start_date, end_date, start_time, end_time, img_id, video_id, display_time,schedule_color, terrace_code, stb_types, district_codes, user_group_codes,igroup_code, schedule_status, schedule_description, step_id, owner_id, aud.description, so.oper_namefrom schedule_record as scheduleleft join auditing_desc_record as audon schedule.schedule_code = aud.codeand aud.is_last_auditing = 1left join system_oper as soon owner_id = so.oper_idwhere 1=1 and schedule_status = 7order by schedule.schedule_code desc) myCount ;
发现执行时间 使用时间为 23s。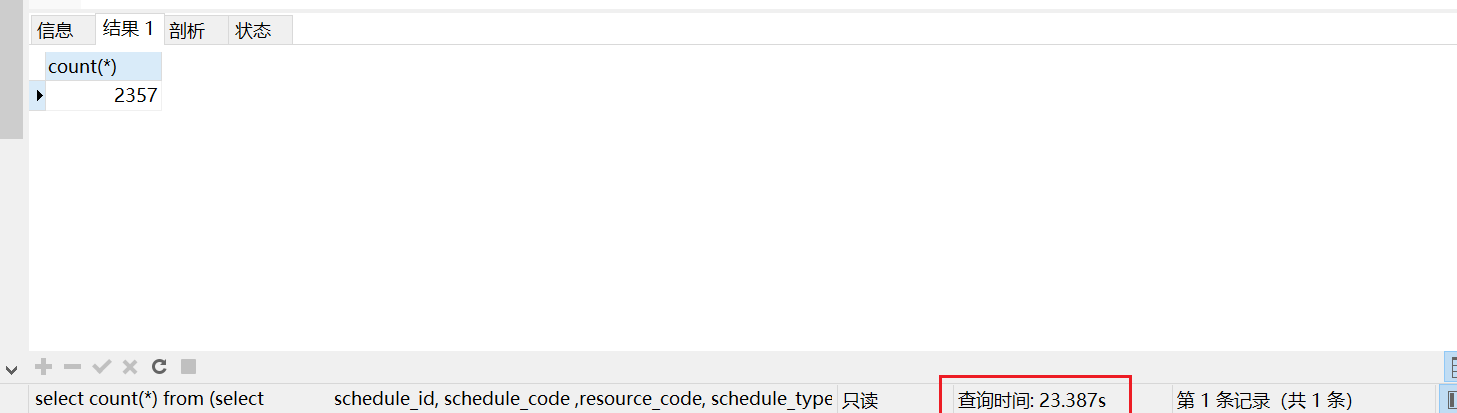
explain 分析sql语句
explainselect count(*) from (selectschedule_id, schedule_code ,resource_code, schedule_type, schedule.oper_id, schedule.oper_time,start_date, end_date, start_time, end_time, img_id, video_id, display_time,schedule_color, terrace_code, stb_types, district_codes, user_group_codes,igroup_code, schedule_status, schedule_description, step_id, owner_id, aud.description, so.oper_namefrom schedule_record as scheduleleft join auditing_desc_record as audon schedule.schedule_code = aud.codeand aud.is_last_auditing = 1left join system_oper as soon owner_id = so.oper_idwhere 1=1 and schedule_status = 7order by schedule.schedule_code desc) myCount ;

添加索引
-- 添加索引 , 给 auditing_desc_record 添加索引 CODE , codeindex 索引名可以随意命名ALTER TABLE auditing_desc_record add index codeindex(CODE);ALTER TABLE schedule_record add index scheduleindex (schedule_code);
再次执行上面的sql语句,会发现执行速度为0.1s
select count(*) from (selectschedule_id, schedule_code ,resource_code, schedule_type, schedule.oper_id, schedule.oper_time,start_date, end_date, start_time, end_time, img_id, video_id, display_time,schedule_color, terrace_code, stb_types, district_codes, user_group_codes,igroup_code, schedule_status, schedule_description, step_id, owner_id, aud.description, so.oper_namefrom schedule_record as scheduleleft join auditing_desc_record as audon schedule.schedule_code = aud.codeand aud.is_last_auditing = 1left join system_oper as soon owner_id = so.oper_idwhere 1=1 and schedule_status = 7order by schedule.schedule_code desc) myCount ;
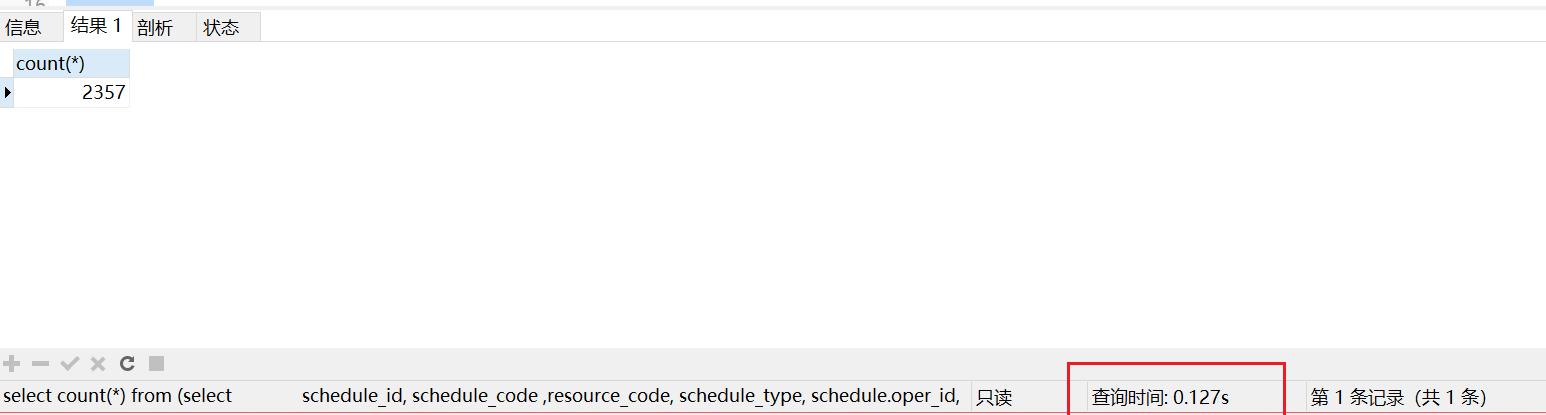
总结
添加索引,可以有效提高整个表的查询速度。
视图
下面有表
emp.sql
职员薪水表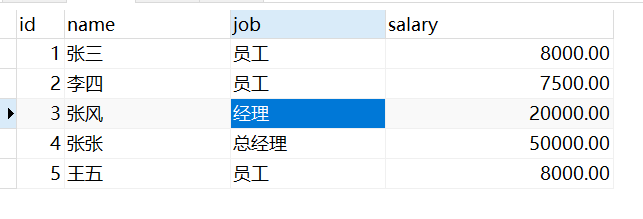
薪水表中 不同的角色的数据 在真实的业务场景中应该有对应的秘密。比如总经理的数据不应该被员工看到。但是所有的数据都在一张表中。
可以通过创建视图 将不同的数据分出来。
创建视图
-- 创建视图create VIEW emp_worker asselect * from emp -- 将所有员工的信息存放到 对应的视图中WHERE job = "员工"select * from emp_worker; -- 从视图中进行查询

-- 创建经理的视图 manager_0000 要求 经理可以看到 经理和员工的信息create view manager_0000 asSELECT * from empWHERE job in ("员工","经理");select * from manager_0000;
视图与表的区别
视图中的数据来源于表。
视图中也可以进行数据的增删改查,增加数据,删除数据,修改数据都会影响到原来的表。
表中数据做增加,修改,删除也会影响到视图。
视图的删除使用
DROP VIEW manager_0000;
将视图全部删除掉。 没有清空视图数据的操作。
表有清空和删除的操作。

若有收获,就点个赞吧
0 人点赞
