
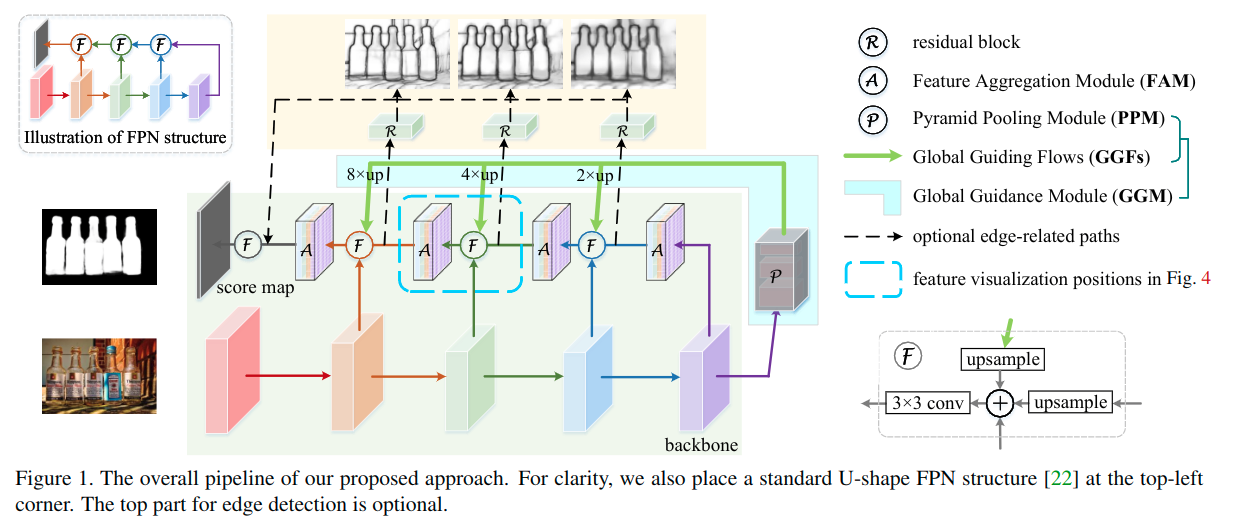
网络结构
主要亮点
大量的池化操作(FAM、GGM)
途中的FAM和GGM部分,在最后的评估中起到了很大的助益。
通过对于当前工作的分析,文章指出:
尽管这种方法(U型结构)取得了良好的性能,但仍有很大的改进空间。
- 首先,在U形结构中,高级语义信息逐渐传输到较浅层,因此由较深层捕获的位置信息会逐渐稀释。
- 其次,如[Pyramid scene parsing network]所指出的,CNN的感受野大小与其层深度不成比例。现有方法通过将注意机制引入U形结构,以循环方式细化特征图,结合多尺度特征信息来解决上述问题,或者在显着性图中添加额外约束,如[Non-local deep features for salient object detection]中的边界损失项。
这里首先分析了原始的FPN结构,这种U形结构的由上而下是建立在由下而上的骨干网络之上的。这随着由上而下(由深到浅)的过程中,来自深层的信息会逐渐被丢弃,并且被来自浅层的信息所淹没。在[Object detectors emerge in deep scene cnns,Pyramid scene parsing network]中显示,CNN的经验感受野远小于理论上的感受野,特别是对于更深的层,因此整个网络的感受野不足以捕获输入图像的全局信息。
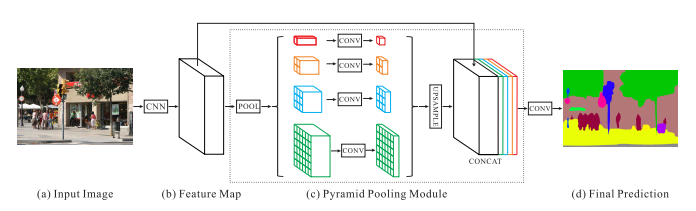
PSPNet中的PPM
为了弥补由上而下的路径中的高层语义信息的缺失,这里引入了一个全局引导模块(global guidance module),从前面的结构图可以看出来,主要包含两个部分,一个是修改版本的金字塔池化模块(PPM),另一个是一些列的全局引导信息流(GGF),以使得在各个层级上更为明确显著性目标的位置。
- PPM:这里包含了四个子分支,包括恒等映射分支、全局平均池化分支,以及两个输出为3x3和5x5的自适应平均池化分支。
- GGM:这里的GGM是一个独立与U型结构的支路。通过引入一些列全局引导信息流(恒等映射),高层级的信息可以被送到各个层级。具体如结构图中的绿色箭头。通过这种方式增加了自上而下路径的每个部分中的全局引导信息的权重,以确保在构建FPN时不会稀释来自高层的位置信息。
然而,一个新的问题是如何使GGM的粗略特征映射与金字塔的不同尺度的特征映射无缝地合并?
在原始FPN中,粗略特征图被上采样两倍,然后添加一个有着3x3核大小的卷积用在合并操作之后,以降低上采样带来的混叠效应。但是GGF需要更大的上采样率(例如8)。有效并高效地弥合GGF与不同尺度的特征图之间的巨大差距是至关重要的。最终文章使用了FAM结构。具体如下。
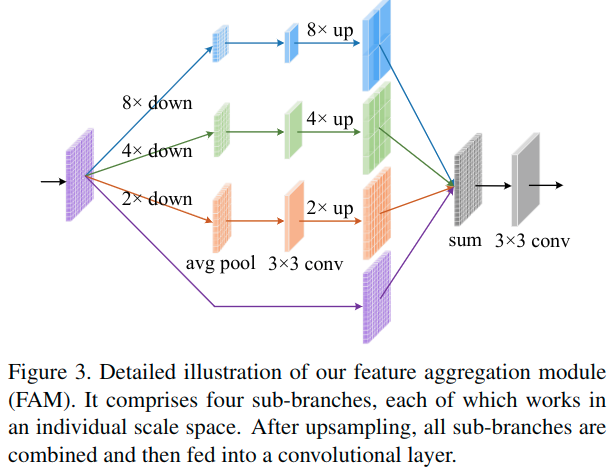
一般来说,FAM有两个优势:
- 首先,它有助于模型减少上采样的混叠效应,特别是当上采样率很大时(例如8)。
- 此外,它允许每个空间位置在不同尺度空间查看局部环境,进一步扩大整个网络的感受野。
作者说,这是第一个揭示FAM有助于减少上采样混叠效应的工作。下面是一个可视化。

可以看出来,引入FAM可以很好的锐化显著对象的细节。
使用边缘检测联合训练
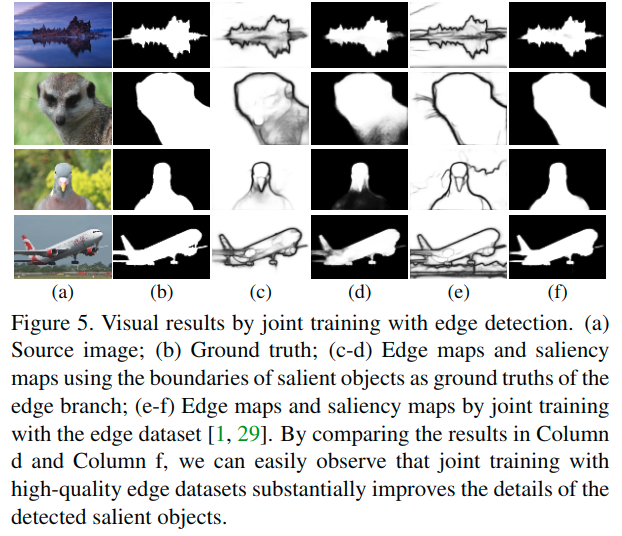
前面的设计已经使得网络的性能非常好了,但是这里进一步观察结果,发现大多数不准确的预测主要是因为不清晰的目标边界。
这里尝试了两种方式来进行改进。
- 在前面小结介绍的模块结构之上添加一个额外的预测分支来预测显著性目标的边缘。
- 如结构图中所示。在三个特征层级的FAM之后使用了三个残差块,用于信息的转换。通道数分别为128,256,512。每个残差块后接一个3x3x16的卷基层来压缩特征,并配合一个1x1x1的卷积层来进行特征提取。
- 同时也拼接这三个16通道的特征图,得到一个48通道的特征图,来将捕获的边缘信息转换到显著性目标检测分支,继而强化细节信息。
- 相似于[Instance-level salient object segmentation],训练阶段使用显著性目标的边缘作为联合训练的真值。
- 然而,效果一般。整图图5中展示的,对于前景和背景之间对比度低的场景,得到的显着图和边界图仍然不明确。对此的理解可能是,从显着物体中获得的真实边缘图仍然缺少显着物体的大部分详细信息。它们只是告诉显着对象的最外边界在哪里,特别是对于显着对象之间存在重叠的情况。
- 考虑到上述分析,最终尝试使用与[Richer convolutional features for edge detection]中相同的边缘检测数据集进行边缘检测任务的联合训练。在训练期间,交替输入来自显着对象检测数据集和边缘检测数据集的图像。从图5中可以看出,利用边缘检测任务的联合训练极大地改善了检测到的显着性对象的细节。
关于联合边缘检测训练任务的合理性
文章使用的边缘检测数据集包含BSDS500和PASCAL VOC Context数据集:
- 这里的PASCAL VOC Context来自Pascal VOC 2012。实际测试用的Pascal-S也来自Pascal VOC数据集,二者一起使用,是否有些不妥?最终的结果中,Pascal-S的结果在使用边缘数据之后,提升非常大。
- 另外,这里的ECSSD中的数据部分与BSDS相同,这样的话会不会也在一定程度造成了效果的提升?
https://github.com/backseason/PoolNet/issues/17#issue-454667982
实验细节
- The proposed framework is implemented based on the PyTorch repository.
- All the experiments are performed using the Adam optimizer with a weight decay of 5e-4 and an initial learning rate of 5e-5 which is divided by 10 after 15 epochs.
- Our network is trained for 24 epochs in total.
- The backbone parameters of our network are initialized with the corresponding models pretrained on the ImageNet dataset and the rest ones are randomly initialized.
- By default, our ablation experiments are performed based on the VGG-16 backbone and the union set of MSRA-B and HKU-IS datasets as done in [ Instance-level salient object segmentation] unless special explanations.
- We only use the simple random horizontal flipping for data augmentation.
- In both training and testing, the sizes of the input images are kept unchanged as done in [Deeply supervised salient object detection with short connections].
- We use standard binary cross entropy loss for salient object detection and balanced binary cross entropy loss [Holistically-nested edge de-tection] for edge detection.
各模块的有效性
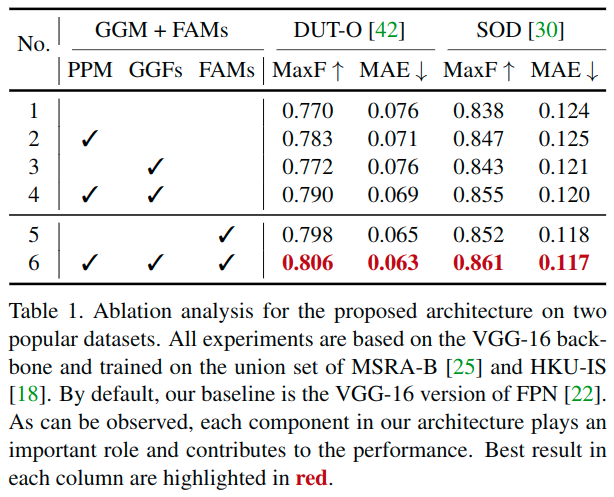

这里的比较可以看出来,添加了了GGM,使得网络能够更多地关注显着对象的完整性,从而大大提高了所得到的显着性图的质量。因此可以锐化显着对象的细节,这可能被具有有限感受野的模型错误地估计为背景(例如,图2中的最后一行)。
与基线相比,FAM的池化操作也扩大了整个网络的感知范围,一定程度上解决了上采样的混叠问题。
联合训练的有效性
关于这里使用标准边缘数据集进行联合训练的过程是有些小技巧的。具体涉及的代码可见[1][2],使用了一个梯度累积更新的方法,对边缘数据与显著性数据分别前向传播,之后将损失加和回传。
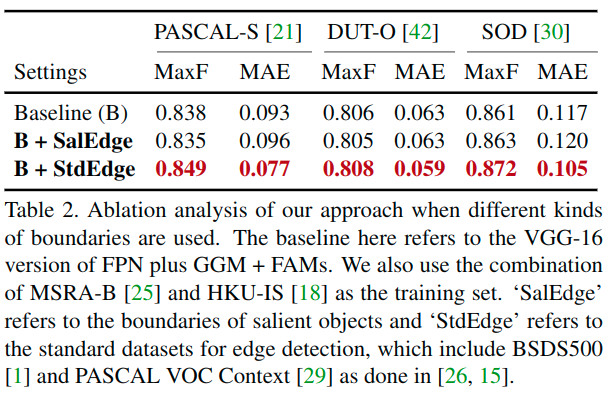
效果比较
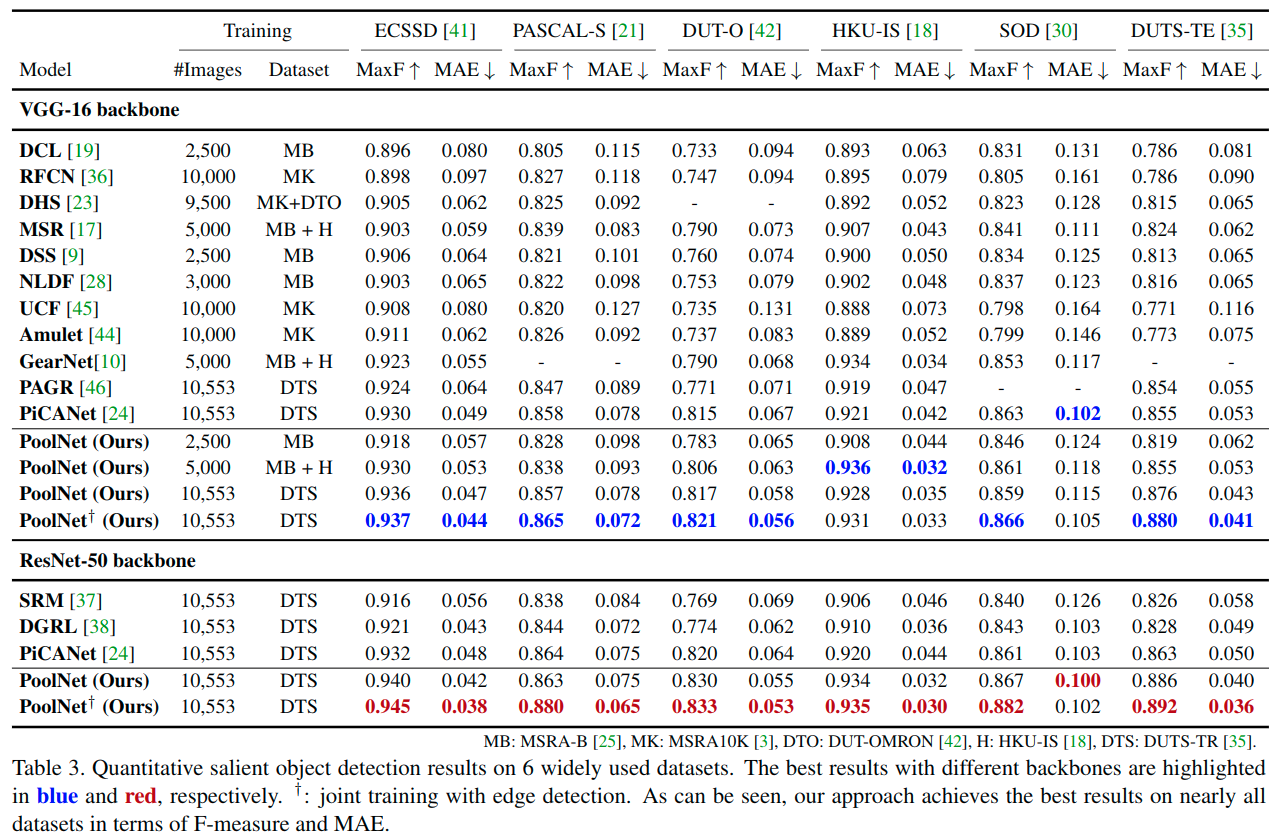
效果非常好,在DUTS上都超过了0.89!
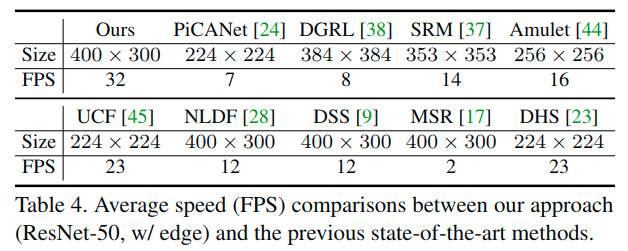
速度也很快,这一点文章提到是因为大量的使用池化操作带来的。
相关链接

若有收获,就点个赞吧
0 人点赞
