
ICCV2019已经接收。
主要工作
- 一种使用伪标签进行训练的半监督视频显著性目标检测方法
- 利用视频之间的关联信息对只有部分帧标注的数据中未标记的数据进行伪标签的生成
- 使用non-local和convGRU结构来进一步利用视频帧之间的时空关联
主要结构
主要目的就是为了实现一种对于视频的半监督学习策略,并通过网路的构造,对于特征时空信息更为充分有效的利用,来实现效果的提升。
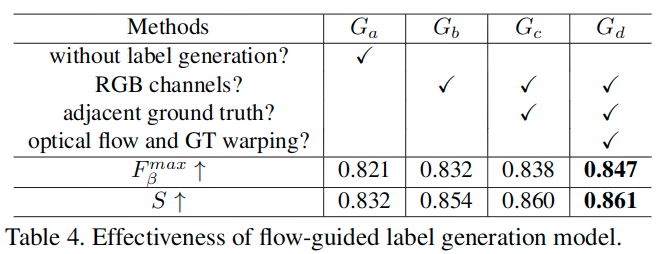
Flow-Guided Pseudo-Label Generation Model(FGPLG)
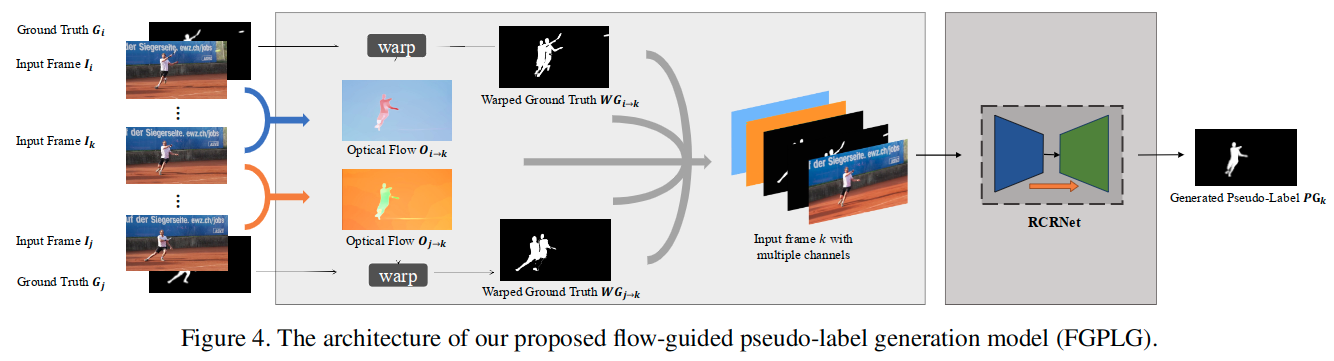
这里通过使用有真值的第i帧和第j帧来估计无真值的位于i和j中间的第k帧的伪标签(pseudo-label)。
- 利用现成的FlowNet 2.0来获得从i到k和从j到k的光流图。此时得到的光流图是二通道图像,表示x和y方向的偏移信息。
- 对第i和第j帧的真值利用光流数据进行调整,得到
warped ground truth,但是从图中可以看出来,它们噪声太多,对于监督而言还需要进行调整。- 这里没有提到
warp操作具体是如何实现的,但是这个实际上是光流计算中的一个操作(FlowNet系列中用到了),就是使用光流和某一帧数据得到的调整后的结果。参考链接1。 - 尽管光流的数值提供了关于第k帧合理的运动信息的估计,但是还是不能直接用来估计第k帧的真值,因为并不是所有的运动信息都是显著性的。
- 这里没有提到
- 为了进一步细化预测的伪真值,将前面获得的四个单通道图像(对两个光流数据需要进行归一化,使其范围变为[-1, 1],之后计算其欧式范数(和移动距离相关,是放缩后偏移矢量的模),于是获得了两个单通道图像),再加上原始的第k帧的三通道RGB图像,总共有七个通道的数据进行拼接。
- 后面送入一个修改输入为7通道的RCRNet结构进而生成最终的伪标签PG。
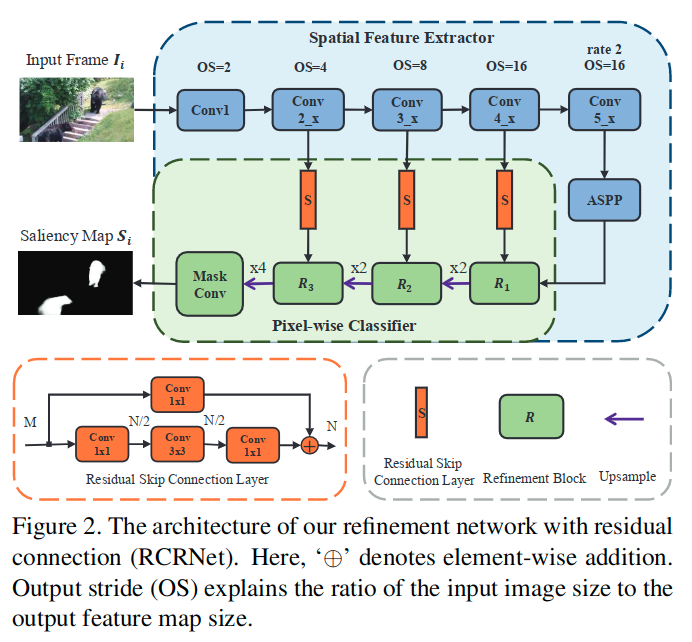
原始的RCRNet,用在这部分时对输入通道进行了修改。 注意这里的结构:
- 为了维持空间细节信息,取消了对于第5个卷积层的下采样
- 为了保证相同的感受野,在第五个卷积层中使用扩张率为2的扩张卷积
- 在第五个卷积层后附加了一个ASPP模块,来获得全图级别的全局上下文信息和多尺度的空间上下文信息
- 最终特征提取器输出为256通道数,并且是输入尺寸的1/16,即OS=16
- 这里使用残差结构连接低级与高级特征,同时对通道数进行调整,这里N均为96,为refinement block提供更多的空间信息
- 这里的refinement block首先拼接两个输入的特征图,之后在馈送到后续的3x3x128的卷积层。这里也会使用双线性插值上采样
- 训练时使用有着真实标注的视频帧中的少量帧。整个模型最终用来生成中间帧的伪标签。
- 在文章实现中,每隔l帧抽取一个样本使用原始真值,也就是这里的j和k帧之间间隔为l帧。另外,文章也提到: It can use the model trained by the triples sampled at larger interframe intervals to generate dense pseudo-labels of very high quality
Video salient object detection network
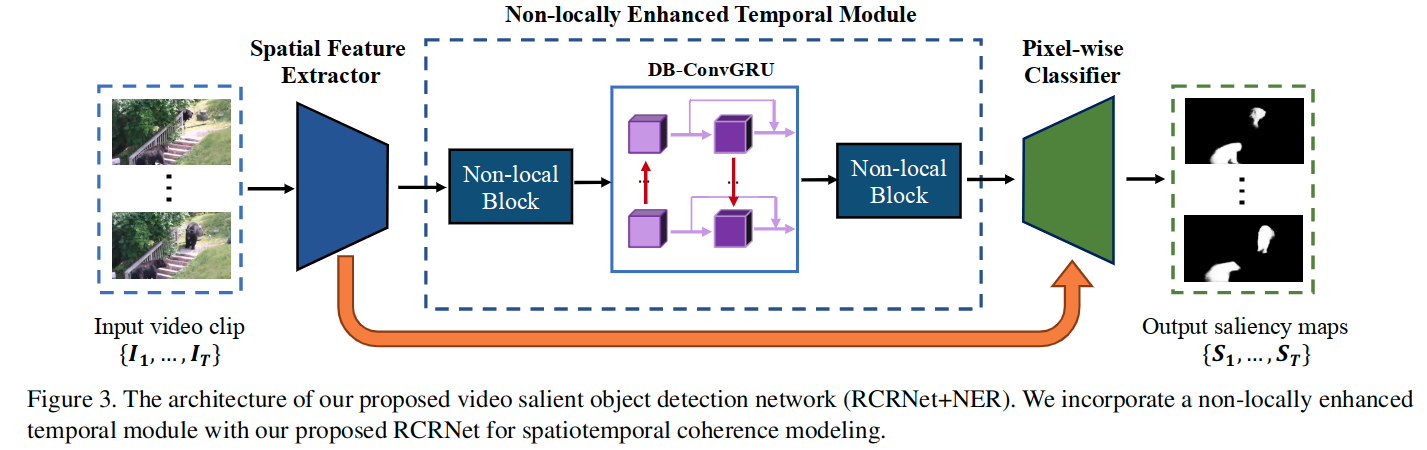
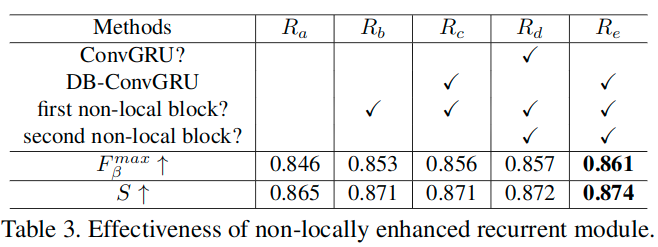
这里通过对RCRNet中插入non-local结构以及ConvGRU结构,来为模型提供足够的时空信息利用能力,提升高级特征的时空一致性(spatiotemporal coherence)。
为了使用non-local结构,这里使用了T帧作为输入,分别得到对应提取的空间特征,将这T个数据拼接后,送入non-local结构,在每个位置上,利用输入特征图的所有位置上的特征的加权和,计算得到当前位置的响应。这可以构造出输入的视频帧的时空关联信息。
RCRNet主要结构没有变化。这里没有详细介绍使用的non-local结构,主要介绍了下提出的DB-ConvGRU结构。
DB-ConvGRU
由于一个视频序列是按照时间顺序包含一系列场景,所以还需要在时间域内描述外观对比信息的顺序演化。这里使用了ConvGRU模块来模拟序列特征的演变。这里使用卷积结构对传统的全连接GRU进行了改进。关于ConvGRU的基本运算如下,这里的 表示卷积操作,
表示卷积操作, 表示哈达马乘积,
表示哈达马乘积, 表示sigmoid函数,而这里的
表示sigmoid函数,而这里的 表示可以学习的权重。公式中简化了表达,忽略了偏置项。
表示可以学习的权重。公式中简化了表达,忽略了偏置项。
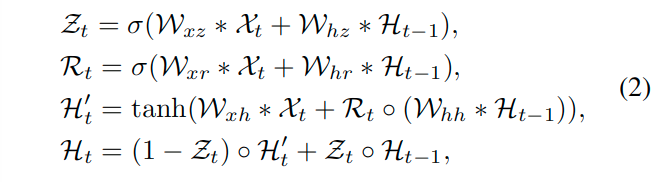
这里受到[Pyramid dilated deeper convlstm for video salient object detection]的启发,堆叠两个ConvGRU模块,分别处理前向与反向,以进一步增强两个方向的时空信息的交换。这样,更深的双向ConvGRU可以记忆过去和未来的信息。
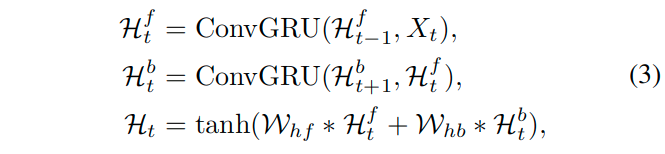
H表示最终的DB-ConvGRU的输出。而X表示non-local结构的输出特征。
这里受到Non-local neural networks]的启发,越多的non-local结构一般会获得更好的结果,所以这里在ConvGRU模块之后也加了一个non-local结构来进一步增强时空一致性。
实验细节
- We evaluate our trained RFCN+NER on the test sets of VOS, DAVIS, and FBMS for the task of video salient object detection.
- We adopt precision-recall curves (PR), maximum F-measure and S-measure for evaluation.
- 关于训练流程:
- First, we initialize the weights of the spatial feature extractor in RCR-Net with an ImageNet pretrained ResNet-50.
- Next, we pretrain the RCRNet using two image saliency datasets, i.e., MSRA-B and HKU-IS, for spatial saliency learning.
- For semi-supervised video salient object detection, we combine the training sets of VOS, DAVIS, and FBMS as our training set.
- The RCRNet pretrained on image saliency datasets is used as the backbone of the pseudo-label generator.
- Then the FGPLG fine-tuned with a subset of the video training set is used to generate pseudo-labels.
- By utilizing the pseudo-labels together with the subset, we jointly train the RCRNet+NER, which takes a video clip of length T as input, to generate saliency maps to all input frames. Due to the limitation of machine memory, the default value of T is set to 4 in our experiments.
- During the training process, we adopt Adam as the optimizer.
- The learning rate is initially set to 1e-4 when training RCRNet, and is set to 1e-5 when fine-tuning RCR-Net+NER and FGPLG.
- The input images or video frames are resized to 448x448 before being fed into the network in both training and inference phases.
- We use sigmoid cross-entropy loss as the loss function and compute the loss between each input image/frame and its corresponding label, even if it is a pseudo-label.
- We compare our video saliency model (RCRNet+NER) against 16 state-of-the-art image/video saliency methods. For a fair comparison, we use the implementations provided by the authors and fine-tune all the deep learning-based methods using the same training set.
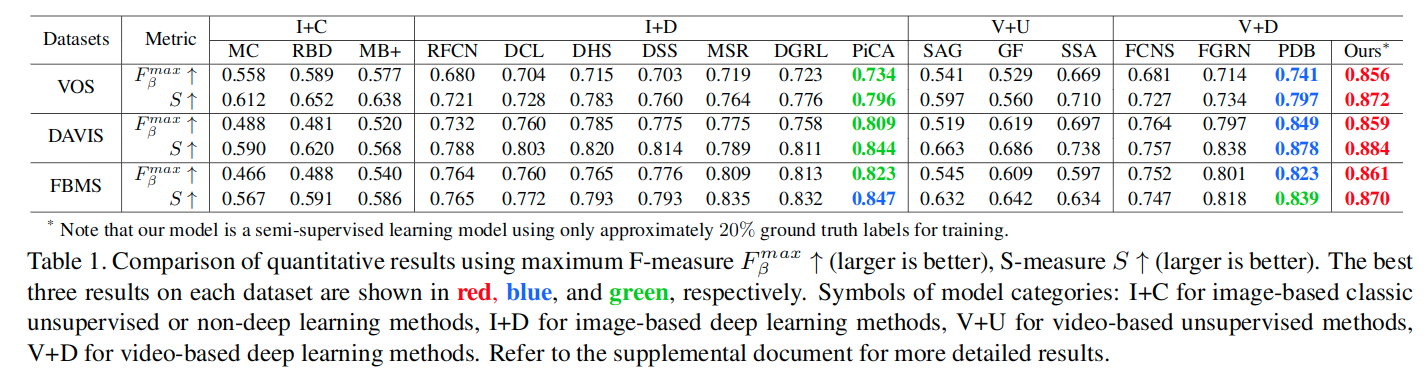
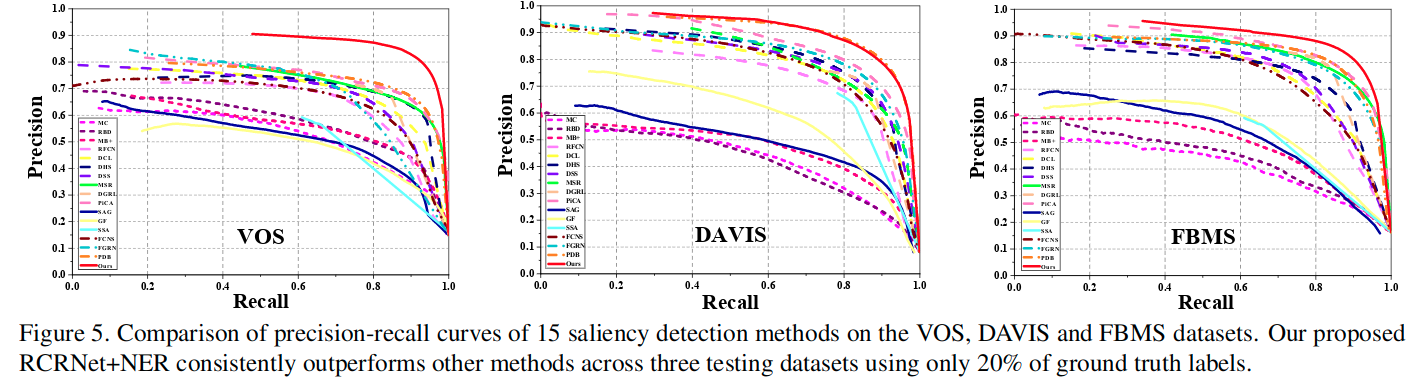
It is worth noting that our proposed method uses only approximately 20% ground truth maps in the training process to outperform the best-performing fully supervised video-based method (PDB), even though both models are based on the same backbone network (ResNet-50).
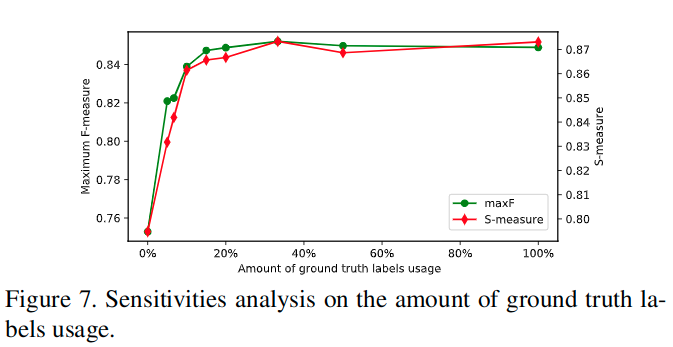
这里对于使用的真实标记的比例进行了测试。
To demonstrate the effectiveness of our proposed semi-supervised framework, we explore the sensitivities to different amount of GT and pseudo-labels usage on the VOS dataset.
- First, we take a subset of the training set of VOS by a fixed interval
then fine-tune the RCRNet+NER with it
By repeating the above experiment with different fixed intervals, we show the performance of RCRNet+NER trained with different number of GT labels in Fig. 7.
As shown in the figure, when the number of GT labels is severely insufficient (e.g., 5% of the origin training set), RCRNet+NER can benefit substantially from the increase in GT label usage. An interesting pheomenon is that when the training set is large enough, the application of denser label data does not necessarily lead to better performance. Considering that adjacent densely annotated frames share small differences, ambiguity is usually inevitable during the manual labeling procedure, which may lead to overfitting and affect the generalization performance of the model. Then, we further use the proposed FGPLG to generate different number of pseudo-labels with different number of GT labels.
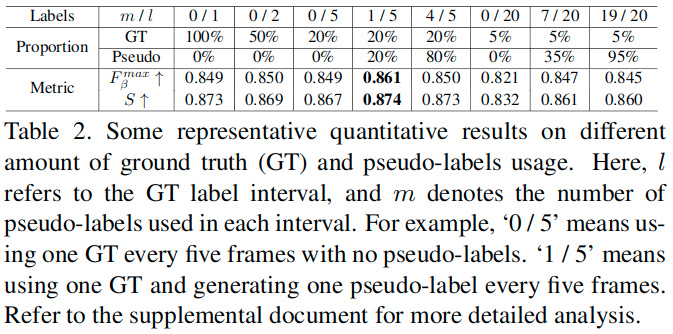
Some representative quantitative results are shown in Table 2, where we find that when there are insufficient GT labels, adding an appropriate number of generated pseudo-labels for training can effectively improve the performance.
Furthermore, when we use 20% of annotations and 20% of pseudo-labels (column ‘1/5’ in the table) to train RCRNet+NER, it reaches the maxF=0.861 and S-measure=0.874 on the test set of VOS, surpassing the one trained with all GT labels. Even if trained with 5% of annotations and 35% of pseudo-labels (column ‘7/20’ in the table), our model can produce comparable results. This interesting phenomenon demonstrates that pseudo-labels can overcome labeling ambiguity to some extent. Moreover, it also indicates that it is not necessary to densely annotate all video frames manually considering redundancies.
Under the premise of the same labeling effort, selecting the sparse labeling strategy to cover more kinds of video content, and assisting with the generated pseudo-labels for training, will bring more performance gain. 在相同标注努力的前提下,选择稀疏标注策略覆盖更多种类的视频内容,并配合生成的伪标签进行训练,将带来更多的性能收益。
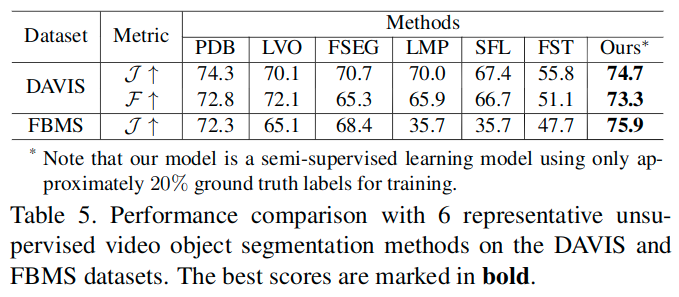
这里的表格5展示了Performance on Unsupervised Video Object Segmentation,因为对于无监督视频目标分割任务和半监督显著性目标检测任务更为相关。
Semi-supervised video object segmentation aims at tracking a target mask given from the first annotated frame in the subsequent frames, while unsupervised video object segmentation aims at detecting the primary objects through the whole video sequence automatically. It should be noted that the supervised or semi-supervised video segmentation methods mentioned here are all for the test phase, and the training process of both tasks is fully supervised. The semi-supervised video salient object detection considered in this paper is aimed at reducing the labeling dependence of training samples during the training process. Here, unsupervised video object segmentation is the most related task to ours as both tasks require no annotations during the inference phase.
Unsupervised video object segmentation aims at auto-matically separating primary objects from input video se-quences. As described, its problem setting is quite similar to video salient object detection, except that it seeks to per-form a binary classification instead of computing asaliency probability for each pixel.
表格中的J表示交并比。
相关链接
- 论文:https://arxiv.org/pdf/1908.04051.pdf
- 几分钟走进神奇的光流|FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks:https://blog.csdn.net/bea_tree/article/details/67049373
- 光流介绍以及FlowNet学习笔记:https://blog.csdn.net/u013010889/article/details/71189271

若有收获,就点个赞吧
0 人点赞
