
这篇文章已被ECCV 2020收录。主要做的是透明物体的分割。
前言
个人之前接触的一个分割项目中,遇到了一项需求,就是要处理白色或者黑色背景上单个透明目标的分割。这里的透明程度简直和没有一样,目标和背景基本上已经被混合到了一起,很难区分。另外由于提供的数据也不够清晰。这种情况下进行良好完整的分割,非常困难。
经过一段时间的思考,我设想过这样几种思路:
- 构造更加合适的数据集:由于深度学习方法很大程度上是数据驱动的,所以可以考虑做一个专门的数据集,来表现这个问题,从而促使深度学习网络可以更好的挖掘该任务数据的特性和习得这样的一种能力。但是制作这样的数据集有很达到困难,除非使用合成的数据。但是合成的数据效果真的好么?这一点有些存疑。
- 获取更加真实完整的边界:通过模拟物体边界的曲线来获得更加流畅和真实的边界。当前分割的难点就在于透明的边界很难被获得。简单的边缘检测算子是无法获得清晰的边界的。如果有了足够明晰的边界,对于分割而言,应该也会更加容易一些。
- 提升图像的清晰度:较低的图像质量很难准确区分目标和真实的背景。如果图像质量较高,或许可以考虑透明物体的对于光线的反射等更具有差异性的特性。但是当前而言,这样的特性似乎并没有明显到可以被用来区分。
本文就是从第一点和第二点出发的一份工作,但是他的数据和我之前想要解决的数据还是有些差异的,这个更接近于真实生活中的场景和目标。当然,这也主要是因为我们的目的不同。这里主要是为了帮助一些机器人啦什么的,更好的识别和避开透明的障碍物。
文中关于其目标任务的定位的介绍: The task of transparent object segmentation is important because it has many applications. For example, when a smart robot operates tasks in living rooms or offices, it needs to avoid fragile objects such as glasses, vases, bowls, bottles, and jars. In addition, when a robot navigates in factory, supermarket and hotel, its visual navigation system needs to recognize the glass walls and windows to avoid collision.
相关的工作
- Transparent Object Segmentation.
- TransCut [1] propose an energy function based on LF-linearity and occlusion detection from the 4D light-field image is optimized to generate the segmentation result.
- TOM-Net [2] formulate transparent object matting as a refractive ow estimation problem. This work proposed a multi-scale encoder-decoder network to generate a coarse input, and then a residual network refines it to a detailed matte. Note that TOM-Net needs a refractive flow map as label during training, which is hard to obtain from the real world, so it can only rely on synthetic training data.
Transparent Object Datasets.
- TOM-Net [2] proposed a dataset containing 876 real images and 178K synthetic images which are generated by POV-Ray. Only 4 and 14 objects are repeatedly used in the synthetic and real data. Moreover, the test set of TOM-Net do not have mask annotation, so one cannot evaluate his algorithm quantitatively on it.
- TransCut [1] is proposed for the segmentation of transparent objects. It only contains 49 images. However, only 7 objects, mainly bottles and cups, are repeatedly used. The images are capture by 5×5 camera array in 7 different scenes. So the diversity is very limited.
- Most of the background of synthetic images are chosen randomly, so the background and the objects are not semantically coordinated and reasonable. The transparent objects are usually in a unreasonable scene, e.g. a cup flying with a plane. Furthermore, the real data always lack in scale and complexity.
主要工作
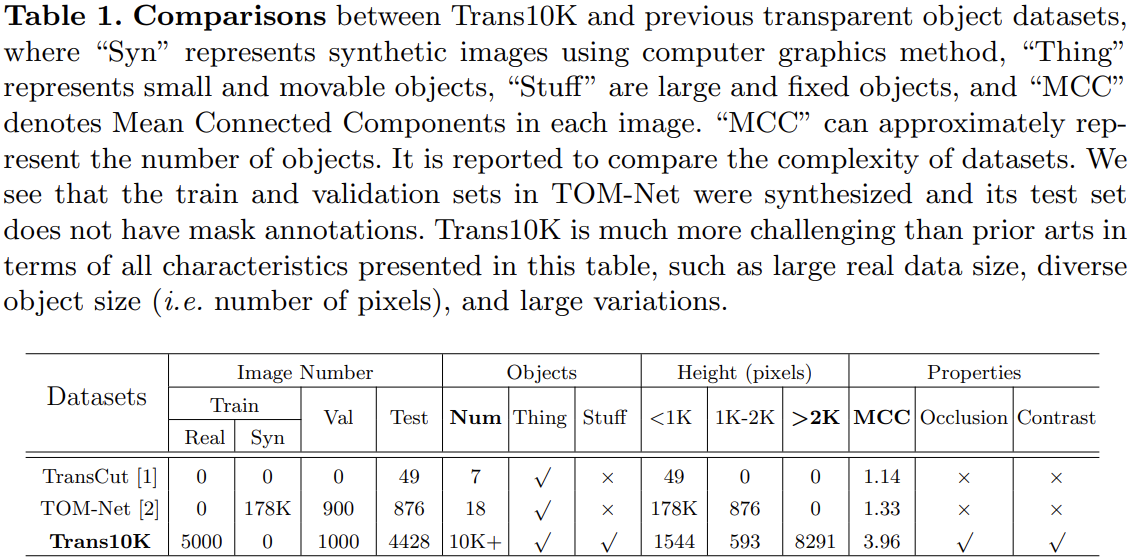
现有数据集与提出的数据集之间的信息比较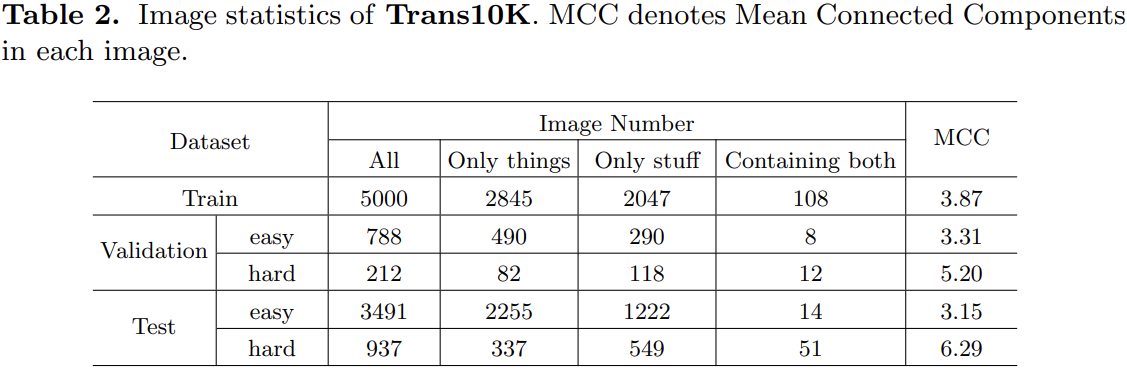
提出的数据集更详细的信息
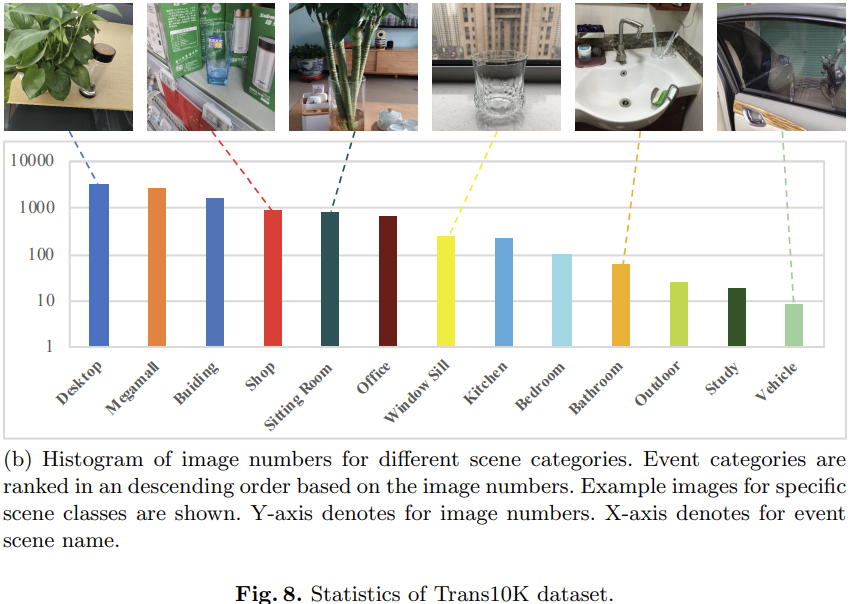
一个新的数据集:Trans10K
- To tackle the transparent object segmentation problem, we build the first largescale dataset, named Trans10K. It contains more than 10k pairs of images with transparent objects and their corresponding manually annotated masks, which is over 10× larger than existing real transparent object datasets.
- The Trans10K dataset contains 10,428 images, with two categories of transparent objects:
- Transparent things such as cups, bottles and glass.
- Transparent stuff such as windows, glass walls and glass doors.
- The images are manually harvested from the internet, image library like google OpenImage [21] and our own data captured by phone cameras. As a result, the distribution of the images is various, containing different scales, born-digital, perspective distortion glass, crowded and so on.
- The transparent objects are manually labeled by ourselves with our labeling tool. The way of annotation is the same with semantic segmentation datasets such as ADE20K. We set the background with 0, transparent things with 1 and transparent stuff with 2. Here are some principles:
- Only highly transparent objects are annotated, other semi-transparent objects are ignored. Although most transparent objects are made of glass in our dataset, we also annotate those made of other materials such as plastic if they satisfy the attribute of transparent.
- If there are things in front of the transparent objects, we will not annotate the region of the things. Otherwise, if things are behind transparent objects, we will annotate the whole region of transparent objects.
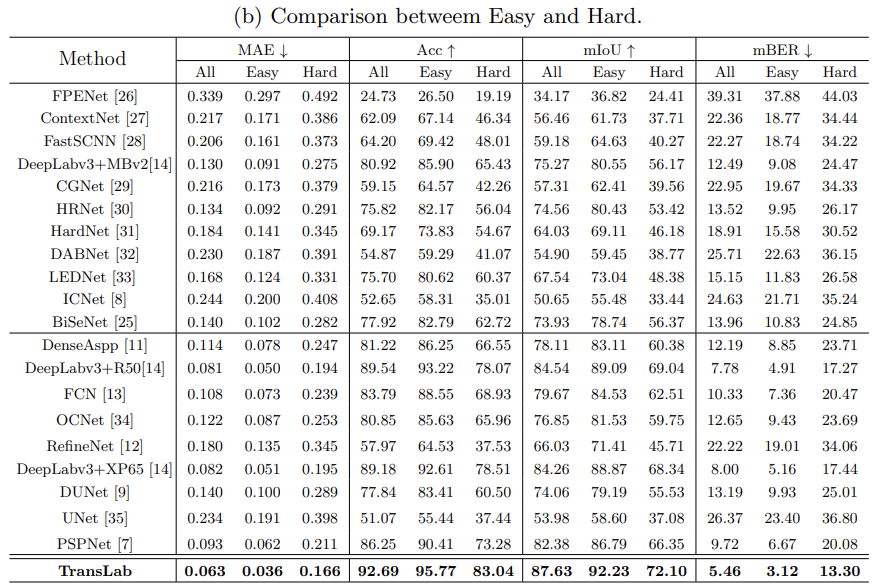
- We further divide the validation set and test set into two parts, easy and hard according to the difficulty.
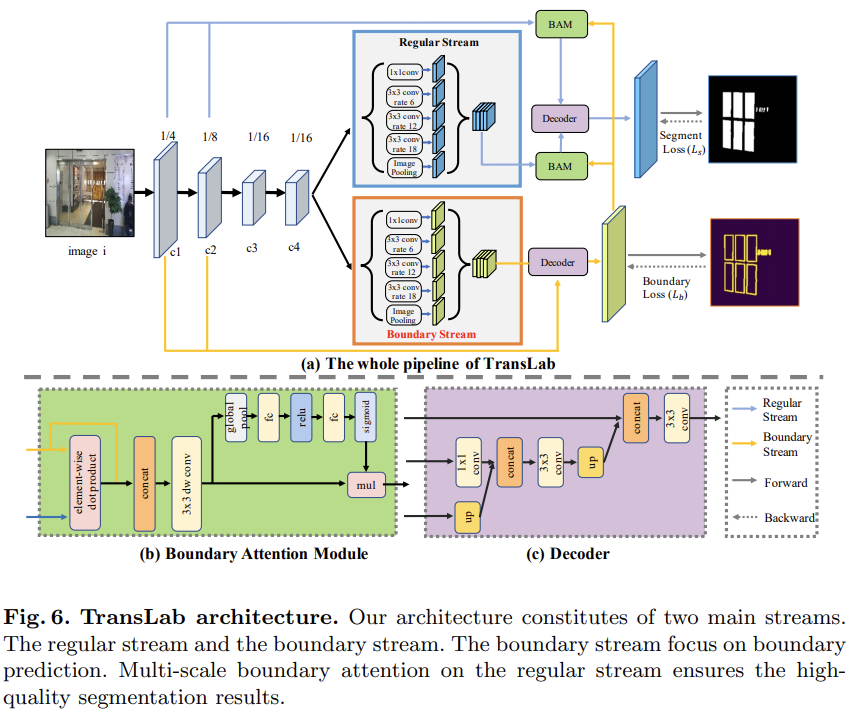
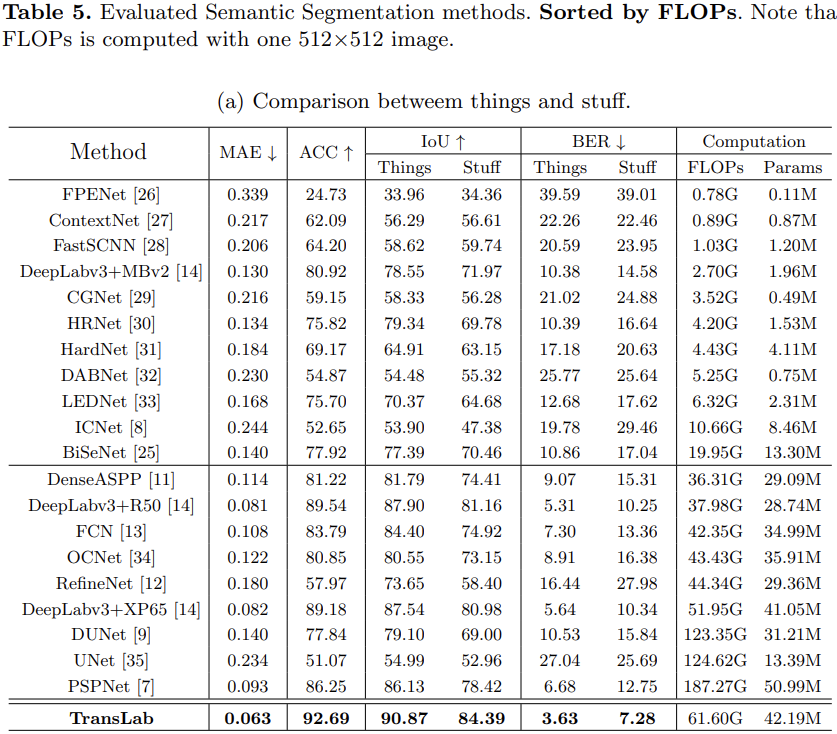
Fig. 6 (a) shows the overall architecture of TransLab, which is composed of two parallel stream: regular stream and boundary stream. ResNet50 with dilation is used as the backbone network. The regular stream is for transparent object segmentation while the boundary stream is for boundary prediction.
- 一个结合边缘监督信息进行分割的网络TransLab
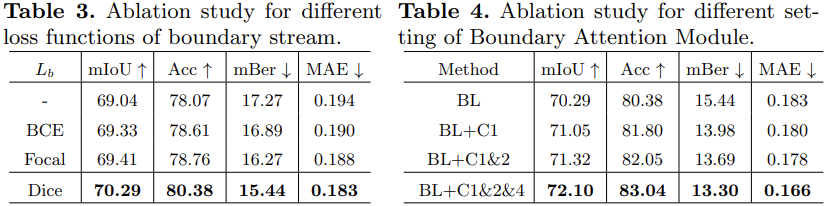
损失函数:对于分割任务,使用交叉熵损失,对于边缘检测任务而言,使用的是DiceLoss。
实验细节
Metrics
- Intersection over union (IoU) and pixel accuracy metrics (Acc) are used from the semantic segmentation field as our first and second metrics.
- Mean absolute error (MAE) metrics are used from the salient object detection field.
- Finally, Balance error rate (BER) is used from the shadow detection field. It considers the unbalanced areas of transparent and non-transparent regions. BER is used to evaluate binary predictions, here we change it to mean balance error rate (mBER) to evaluate the two fine-grained transparent categories.
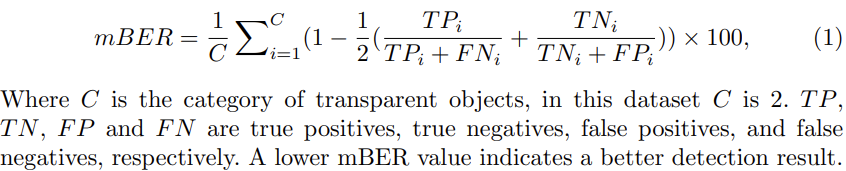
- We argue that the boundary is easier than content to observe because it tends to have high contrast in the edge of transparent objects, which is consistent with human visual perception.
- So we first make the network predict the boundary, then we utilize the predicted boundary map as a clue to attend the regular stream. It is implemented by Boundary Attention Module (BAM).
- In each stream, we use Atrous Spatial Pyramid Pooling module (ASPP) to enlarge the receive field. Finally, we design a simple decoder to utilize both high-level feature (C4) and low-level feature (C1 and C2).
- We have implemented TransLab with PyTorch [24].
- For training, input images are resized to a resolution of 512×512. We use the pre-trained ResNet50 as the feature extraction network. In the final stage, we use the dilation convolution to keep the resolution as 1/16. The remaining parts of our network are randomly initialized.
- For loss optimization, we use the stochastic gradient descent (SGD) optimizer with momentum of 0.9 and a weight decay of 0.0005.
- Batch size is set to 8 per GPU.
- The learning rate is initialized to 0.02 and decayed by the poly strategy [25] with the power of 0.9 for 16 epochs.
- We use one V100 GPU for all experiments. During inference, images are also resized to a resolution of 512×512.
相关链接

若有收获,就点个赞吧
0 人点赞
