
度量学习
很多的算法越来越依赖于在输入空间给定的好的度量。例如K-means、K近邻方法、SVM等算法需要给定好的度量来反映数据间存在的一些重要关系。这一问题在无监督的方法(如聚类)中尤为明显。
举一个实际的例子,假设我们需要计算这些图像之间的相似度(或距离,下同)(例如用于聚类或近邻分类)。面临的一个基本的问题是如何获取图像之间的相似度,例如如果我们的目标是识别人脸,那么就需要构建一个距离函数去强化合适的特征(如发色,脸型等);而如果我们的目标是识别姿势,那么就需要构建一个捕获姿势相似度的距离函数。
为了处理各种各样的特征相似度,我们可以在特定的任务通过选择合适的特征并手动构建距离函数。然而这种方法会需要很大的人工投入,也可能对数据的改变非常不鲁棒。度量学习作为一个理想的替代,可以根据不同的任务来自主学习出针对某个特定任务的度量距离函数。
结构
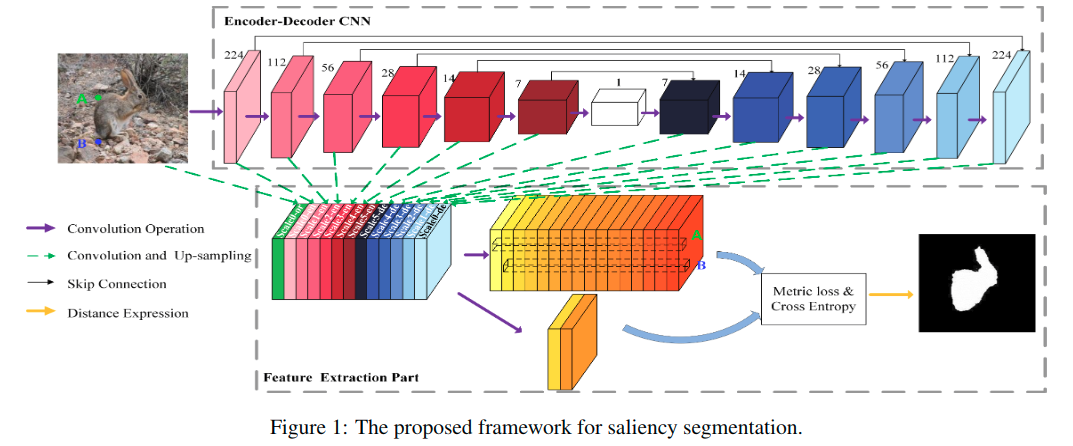
其中的编码和解码的基础模块有所改动,如下:
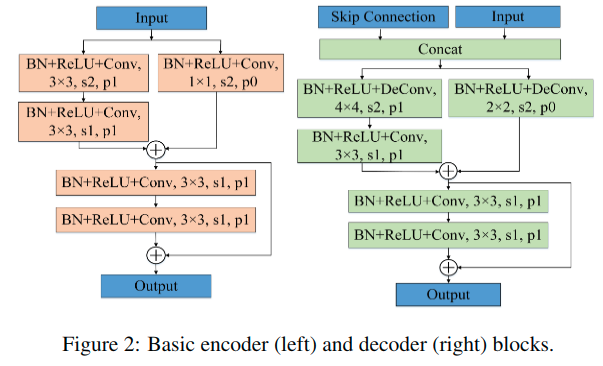
这里的模块里没有使用池化操作,都是用的是步长为2的卷积,并对应使用反卷积。
We use a 4 convolutional layer block in the upsample and downsample operations. Therefore the depth of our MEnet is 52 layers.
图1中所示,从13个位置获得对应的特征图,拼接到一起,得到特征提取部分的输入特征。之后分成两部分,一个是使用16核的卷积层处理,另一个则是使用2核的卷积层处理。
损失函数
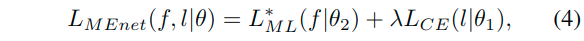
其中第一项是度量损失,第二项是交叉熵,分别介绍:
交叉熵
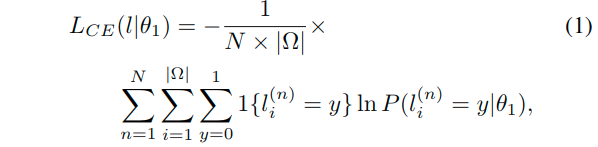
N是训练数据的数量,而Omega是图像上的像素集合。这里用于计算交叉熵的预测输出有两个通道,两个通道上预测的概率值(softmax之后),也就分别对应了第i个位置上的似然概率P的两个概率值: P(li=0|theta1)和P(li=1|theta1)。theta1是可学习的参数。
度量损失(亮点)
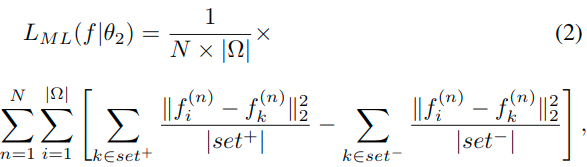
其中fi表示对应于第n个样本的第i个像素的特征矢量。这里的set+表示该样本中的显著性区域集合,而set-表示该样本中的非显著性区域集合。实际上最终就是要做到:encourages an encoder-decoder network that enlarges the distance between any pair of feature vectors having different saliency, and reduces the distance for those with the same saliency.
等价于:

这里的f+表示之前set+集合的中心,f-表示之前set-集合的中心,从原来的对于集合中的每个元素计算距离,到了现在直接计算到中心的距离。两个含义相近,但是具体计算还是有略有差异(一个平方再均值,一个先均值再平方)。
Intuitively, Equation 3 enforces that the feature vectors extracted from the same region be close to the center of that region while keeping away from the center of the other region in salient feature space.
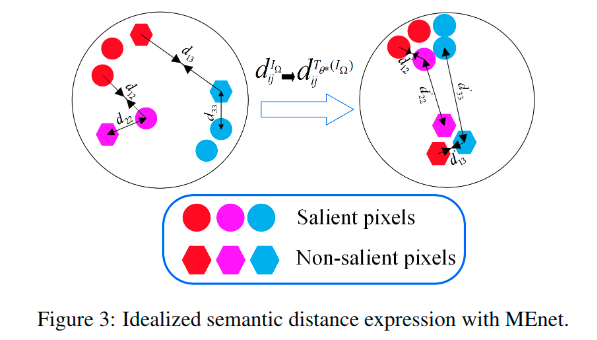
语义距离表达
对于一个给定的观测样本来进行测试,这里可以定义像素域为Omega,也就是所有的像素组成了这个集合,对于其中的任一个像素i而言,其亮度可以表示为Ii,横跨所有通道。但是对其而言,通过Ii和Ij之间的距离关系(例如欧式距离)很难定义真正的语义距离。然而这个收敛后的网络可以得到对应的特征向量集合{fi},i in Omega。用这些特征向量来计算距离,最终可以很好的表示所谓的“语义距离”。最终的显著性图S可以表示为:
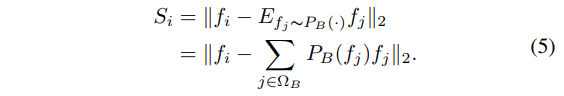
上式中的PB表示预测的输入特征为背景的概率,这里的OmegaB表示前面的交叉熵损失中使用的背景区域,也就是这里的计算使对应于结构图中通道数为2的那部分特征。这里计算了特征矢量与背景中心的距离,越大则越显著。
Thteta*表示最终的收敛网络。但是要注意,这里的OmegaB和OmegaS并不是一个准确的分割(OmeagB +(并集) OmegaS = Omega),会进一步研究。
As illustrated in Figure 4, we anticipate that through this space transformation, the intra-class distance will be smaller than the inter-class distance.
实验细节
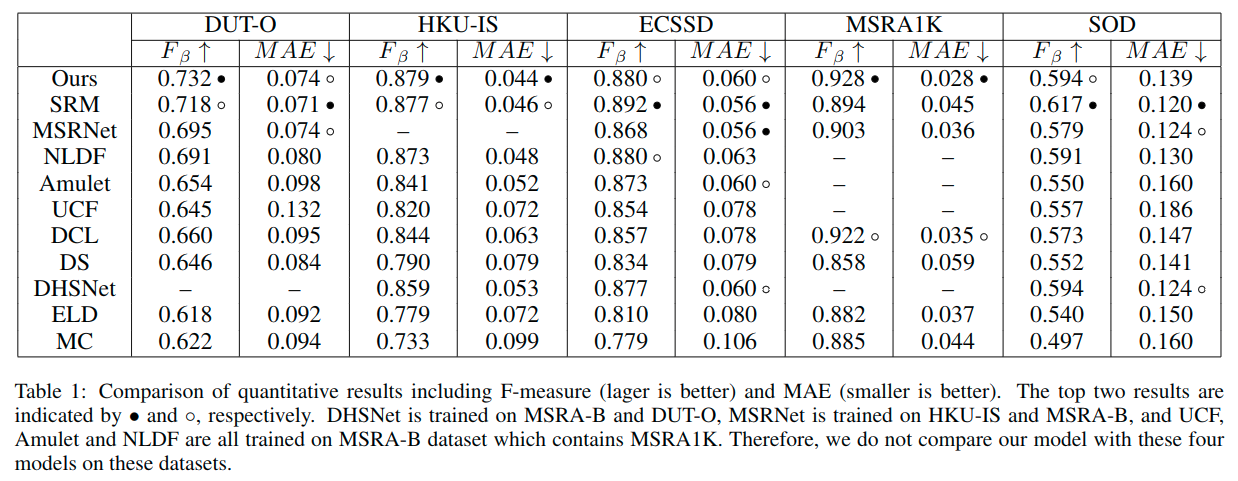
- 数据集:MSRA10K [Cheng et al., 2015], DUT-OMRON (DUT-O) [Yang et al., 2013], HKU-IS [Li and Yu, 2015], ECSSD [Yan et al., 2013], MSRA1K [Liu et al., 2011] and SOD [Martin et al., 2001].
- 参数:
- SGD
- learning rate to 0.1 with weight decay of 1e-8
- a momentum of 0.9
- a mini-batch size of 5
- 110,000 iterations.
- the MSRA10K and HKU-IS are selected for training.
- For MSRA10K, 8500 images for training, 500 images for validation
- the MSRA1K for testing;
- HKU-IS was divided into approximately 80/5/15 training-validation-testing splits.
- use cropping and flipping images randomly as data augmentation.
- We use batch normalization [Ioffe and Szegedy, 2015] to speed up convergence.
- Since salient pixels and non-salient pixels are very imbalanced, network convergence to a good local optimum is challenging. Inspired by object detection methods such as SSD [Liu et al., 2016], we adopt hard negative mining to address this problem. This sampling scheme ensures salient and non-salient sample ratio equal to 1, eliminating label bias. 这里使用了SSD的难样本挖掘策略。
- MEnet从头开始训练,不需要进行前/后处理。MEnet is trained from scratch and does not require pre/post-processing.
- Since the saliency maps generated by metric loss prediction tend to be binary, it is difficult to draw PR curves which need continuous salient values. Therefore, we select saliency maps generated by CE prediction to draw PR curves.
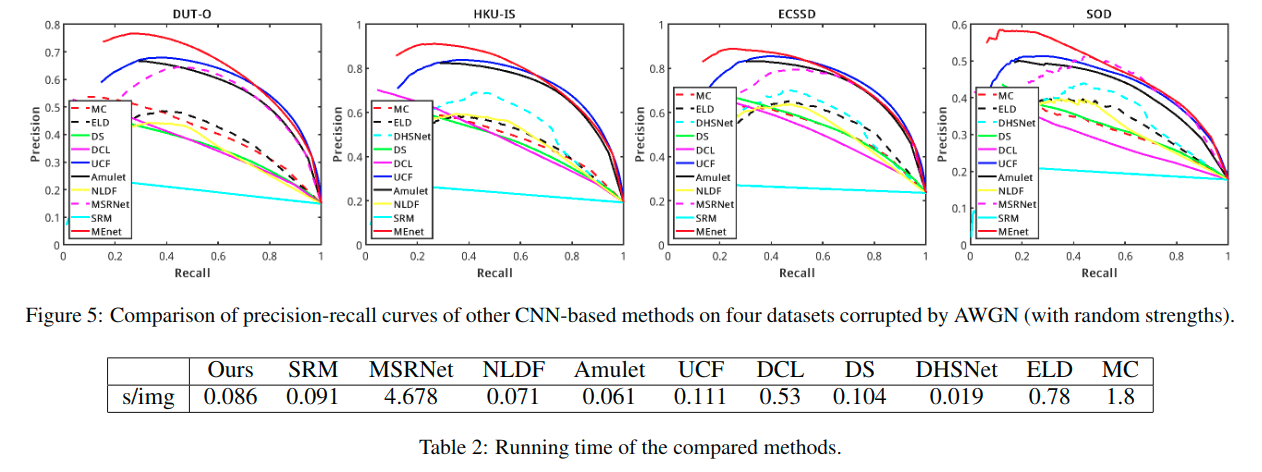
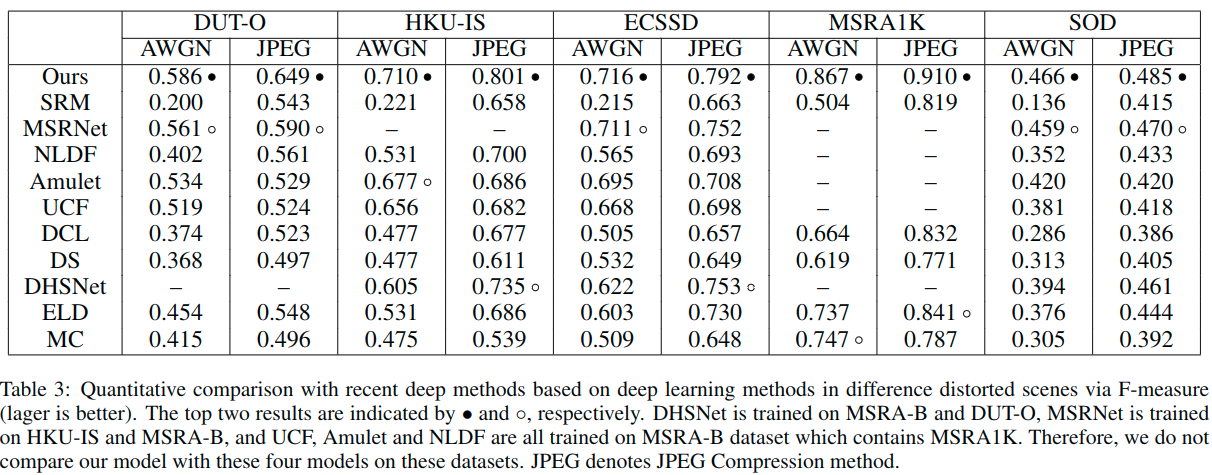
最后这个是对数据集进行了扭曲操作(distorted images),一个是加高斯白噪声,一个是使用JPEG压缩。
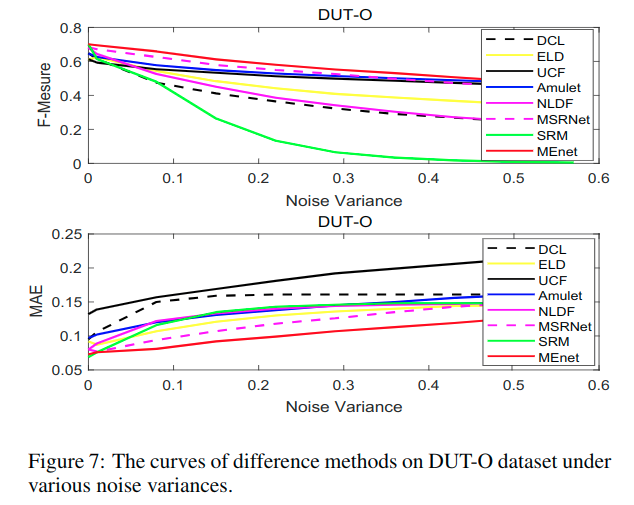
这里是比较了几种不同设定的效果:
To show the effectiveness of our proposed multi-scale features extraction and loss function, we use different strategies for semantic saliency detection/segmentation as shown in Table III. The difference between CE-only and CE-plain is that CE-plain does not utilize multi-scale information which will cause performance degradation. We also note that the performance of MEnet is improved after introducing metric loss.
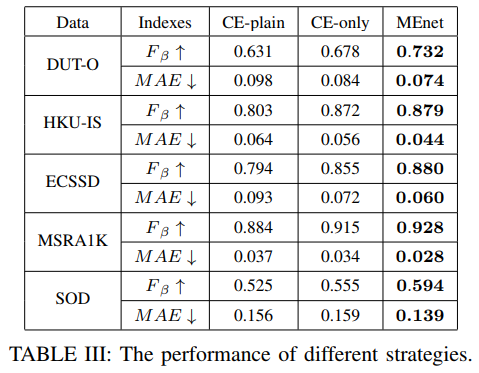
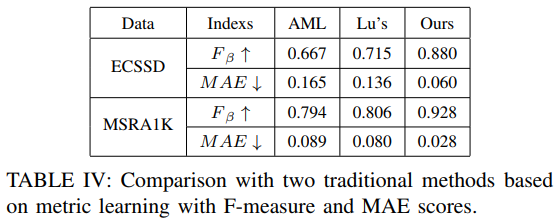
和两个传统的基于度量学习的方法比较:
We compare MEnet with two other traditional metric learning methods for saliency segmentation, AML and Lu. The results in Table IV demonstrate the potential superiority of deep metric learning method over traditional metric learning for semantic saliency detection.
一些分析
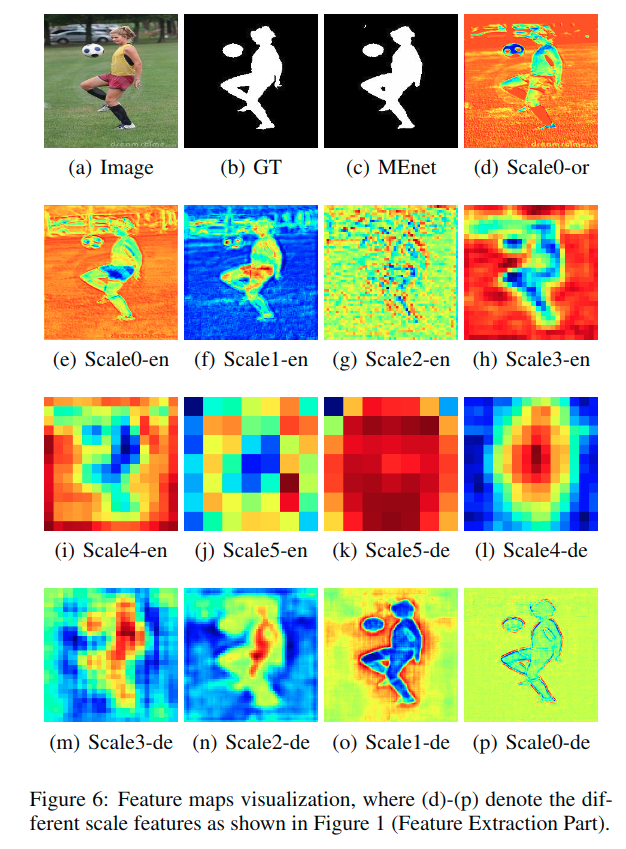
上图显示了特征提取部分的十三个特征图可视化的结果。
在[Liu and Han,2016; Zhanget al.,2017a],一个带有1个内核的卷积层用于融合多尺度特征,这可能导致感知领域受到限制。我们不是在最后一层使用1x1卷积,而是在最后一层使用一个nxn的卷积,包含更多单元来从其邻域捕获信息。
总结
在本文中提出了一个端到端深度量度学习架构,称为MEnet,用于显着对象分割。
使用多尺度特征提取来获得精确信息,并结合深度量度学习将像素映射到可以使用欧几里德距离的“显着空间”,得到的映射有效地将显着图像元素(像素)与背景区分开。
所提出的模型从头开始训练,不需要预处理/后处理。
基准数据集上的实验清楚地证明了模型的有效性,以及处理扭曲图像时的稳健性。
相关链接

若有收获,就点个赞吧
0 人点赞
