
主要亮点
- 使用多任务学习与监督:显著性监督、前景轮廓监督、边缘监督
- 使用显著性检测与边缘检测任务来互相引导增强效果
- 使用了互学习策略,来使得网络参数可以收敛到更好的局部极小值提升性能
- 使用交替式的显著性目标检测和前景轮廓检测的监督,使得网络可以产生更均匀的高亮和更好的边缘。
网络结构
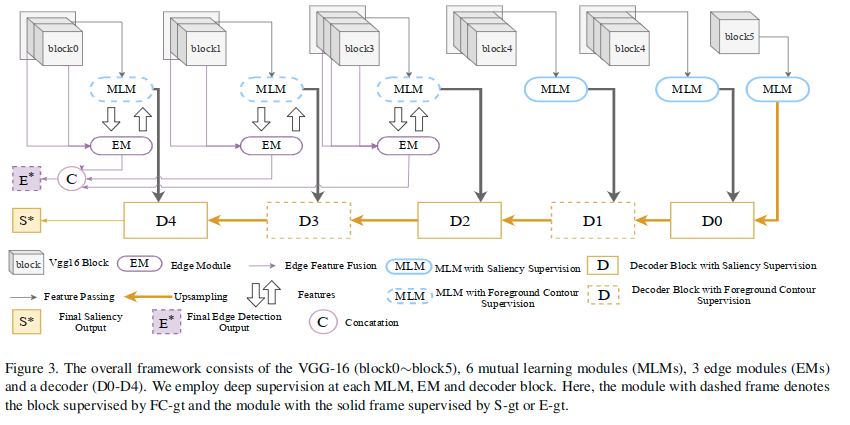
文章使用了VGG16作为基础网络,附加模块有互学习模块(MLM),边缘模块(EM)和解码模块。
- 其中上图中的block0~block5对应不同VGG16的六个不同操作阶段:conv1~conv5,pool5。
- 在此基础上构建了六个MLM模块和三个EM模块。
- 前者主要用来提取前景轮廓特征和显著性特征。
- 后者负责提取边缘特征,并且每个EM模块会连接对应的VGG的block中的所有的卷积层。
- 使用残差结构来在EM和MLM之间的转换特征。
- 对于解码器,使用深监督结构,并且使用类似UNet的结构来融合来自MLM的多尺度特征,并生成预测。
- 五个解码器模块使用了相似的结构。
- 每个解码器用来融合来自MLM和对之前模块特征上采样后的特征。
- 它融合输入特征,通过转置卷积输出上采样后的特征。
- 另外,对于深监督,会使用一个额外的卷积层来生成每个block的最终的预测结果。
主要工作
主要提出了现有工作的两个不足:
- 整个显著性目标很难均匀高亮,因为它们内部结构非常复杂
- 目标轮廓附近的预测一般是不准确的,因为大步长卷积和池化操作造成的信息缺失
文章通过同时使用三个任务训练的策略来尝试解决以上问题。主要包括显著性目标检测、前景轮廓检测和边缘检测。

如上图所示,文中使用了五种图像,分别是收集自边缘检测数据集上的数据和其对应的真值,收集自显著性检测数据集的图像和真值,以及使用canny算子处理后提取到的边缘图。各种数据分别表示的符号如上图所示。
- 首先,为了完整的生成均匀高亮的显着性图,以交织的方式使用显着目标检测和前景轮廓检测。 这两项任务高度相关,因为它们都需要精确的前景检测。 然而,在特定场景中互相是不同的,显着性检测涉及密集标记(即“填充”对象区域内部),并且更可能受到显着目标内部的复杂性的影响,无法产生均匀的前景高亮。相反,在给定前景目标的粗略位置的情况下,可以基于诸如边缘和纹理的低级线索“提取”前景轮廓。 因此,轮廓检测任务对于目标内部结构更加鲁棒,但可能被对象轮廓周围丰富的边缘信息误导。在所提出的交织策略中,两个任务在网络的不同块处交织,迫使网络学习“填充”和“提取”前景轮廓。 因此,网络可以从两个任务的优势中受益并克服它们的缺陷,从而导致更加完整高亮的显着区域。
- 其次,为了减轻预测显着性图中的模糊边界问题,提出通过边缘检测任务的辅助监督来改进前景轮廓检测。为此设计了边缘模块,并与骨干网络共同训练。 由于边缘模块将来自骨干网络的显着性特征作为输入,因此在这些特征中编码的语义信息可以有效地抑制嘈杂的局部边缘。 同时,边缘模块提取的边缘特征作为前景轮廓检测的附加输入,通过低级别提示确保更准确的检测结果。
- 第三,为了进一步提高性能,提出了一种新的互学习模块(MLM),其灵感来自深度互学习(DML)[Deep Mutual Learning]的成功。MLM建立在骨干网络的每个块之上,由多个子网络组成,这些子网络通过模拟损失(mimicry loss)在同伴教学策略中进行训练,从而产生额外的性能增益。
接下来分别介绍各个模块。
Mutual Learning Module(提升显著性检测和前景轮廓检测的性能)
该模块旨在提升显著性检测和前景轮廓检测的性能。主要受到[Deep Mutual Learning]的启发。
DML方法会设置数个“学生”网络,来针对同一个任务,并且用它们各自的预测作为一个互相的次级监督(sub-supervisions)。在互学习方法中,每个学生网络是一个完整的模型,可以独立工作。每个学生网络都是以相互的方式进行训练的完整模型,但可以独立工作。 这里对于三个学生网络之间的模仿损失(mimicry loss)使用的是L2距离损失,而不是DML原始模型中使用的KL散度。
**
在这里的学生网络都使用一个简单的包含三个连续层的子网络,这主要用来提取特征并生成预测。这里在更深的MLM中使用了更大的扩张卷积核,以捕获更为细节的全局信息。输入是各个block的输出特征图。通过MLM的各个子网络可以生成不同的预测结果,从而实现各种监督。
通过互相学习,MLM为每个子网络提供了一个更加柔和的损失,这回导致每个子网络的参数收敛到更好的局部极小值。要注意,在MLM中每个子网络都被训练,但是在测试的时候只是随机选择其中一个。
在本文的结构中,不同阶段的MLM针对的任务有差异,在更早期的三个MLM用来前景轮廓检测,这里使用FC-gt来监督(也就是显著性真值的边缘),而更深的MLM使用显著性检测真值来监督。
第i个block的预测可以表示如下: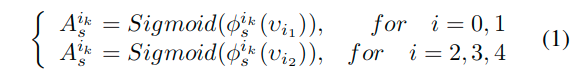
每个MLM的预测显示如下:

从上面的结果可以看出来,最终的训练会使得各个阶段的输出更加贴近于监督的状态。
Edge Module(处理边缘检测任务,帮助MLM进行前景轮廓检测)
[Deep saliency: Whatis learnt by a deep network about saliency?] 中作者可视化了预训练的VGG-19模型在针对显著性检测任务微调前后的的神经元感受野,结果显示,在针对显著性任务微调后,前三个池化层的神经元的响应几乎没有什么改变。也就是说,针对显著性检测微调网络,前三层的神经元的响应状态仍然保持着大量的相似的边缘模式。这表明,预训练的VGG网络在前三个block适合于同时捕获边界信息和显著性信息。所以这里为前三个block专门设计了一个额外的edge module,来处理边缘检测任务,帮助MLM进行前景轮廓检测。

这里展示了EM模块的细节。EM模块与MLM模块紧密联系在一起,二者信息互相流通。而且这里对于EM而言输入包含了对应的block中的所有层的特征,如图中的两层,不同层的特征合并起来生成边缘概率图。
从图中可以看出来,这里使用了两种数据作为输入,一种是显著性检测数据集,一种是边缘检测数据集:
- 对于边缘检测数据集的输入标记为E,每个EM会生成一个概率图Ae,各阶段的输出的Ae被收集起来合并到了最终的边缘预测E*上。
- 对于显著性检测数据集的输入标记为S,EM只会为MLM生成一个边缘特征图ae。
- 两个模块使用残差方式连接,这设计来对前景轮廓检测减少噪声。
对于第i个block,产生预测的过程可以表示如下: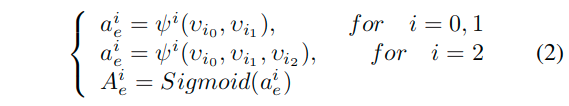
使用来自EM的信息,MLM可以生成准确的轮廓。同时共享的基本block提供来自前景轮廓检测的语义信息,从而帮助边缘检测忽略无用的局部边界。
In the meanwhile, the shared basic blocks provide semantic information from foreground contour detection and thereby helping the edge detection to ignore the useless local edges.
Intertwined Supervision Method(显著性检测真值和其轮廓的交替监督)
在前面的MLM的监督中,前三个使用了显著性检测数据集真值边缘来进行监督,后三个时候显著性检测真值进行监督。进一步,这里在不同的解码器模块使用了两种任务的交替监督。使用显著性检测真值监督D0/D2/D4,而对D1/D3使用了真值边缘进行监督。每个解码器都用来来自前层和对应的MLM的特征,然后转换到下一个块的输入。
如图3所示:
- D1接收高级语义信息并在显著性检测真值边缘的监督下将其传输到前景轮廓特征中,其中目标内部噪声被丢弃并且提取的轮廓特征变得更清晰。
- D2则是“填充”。接收轮廓特征,然后将它们传输到显着性特征中。它需要根据轮廓特征恢复内部信息,这迫使D2为轮廓内的每个像素产生统一的预测分数,就像是一个“填充”的过程。
- 来自D2的恢复的干净的语义信息、来自浅层MLM的低级轮廓信息被送入D3。D3在边缘监督下,保留准确的前景轮廓并且使用高级语义知识来忽略低级轮廓信息中的噪声。
- D4和D2的工作过程相似,处于边缘的监督之下,尝试填充信息。
- 在显著性检测真值和其轮廓的交替监督之下,最终能够准确的生成预测,整体高亮更为均匀,并且保持着良好的前景轮廓。
损失函数
在深监督之下,缩放三种真值到对应的尺度。总体的损失包含两部分,一部分是编码器上的,一部分是解码器上。
编码器损失
这里主要计算的结构图中除解码器监督之外的部分的监督损失: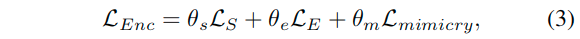
这里的LS、LE、Lmimicry是针对于显著性、边缘检测、以及互学习的损失,权重分别为0.7、0.2、0.1。
对于LS和LE使用二值交叉熵: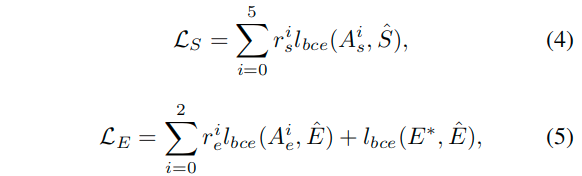
这里计算了各个阶段下的输出与对应的真值的损失计算(其中hatE表示边缘检测数据集的真值,而hatS则表示针对于显著性检测数据集的真值与边缘监督真值)。这里的r系数表示各阶段的权重,试验中,rsi都设置为0.2,除了rs5设置为0.5。关于rei如何设置,这里没有提。
对于MLM中的模仿损失,这里设置为: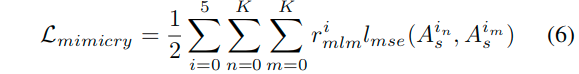
这里的K表示MLM模块中学生网络的数量。这里使用的是MSE损失,也就是差值的平方。这里的rmlmi都设置为1。
解码器损失
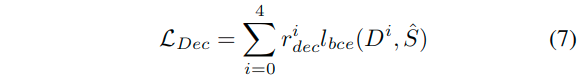
这里的系数rdec4设置为1,其余设置为0.5。
训练步骤
使用交替训练的方式来训练编码器和解码器网络:
- 首先训练编码器网络,也就是训练带有MLM和EM模块backbone网络,此时损失使用LEnc。
- 固定编码器,馈送MLM的特征到解码器网络来训练解码器网络,此时损失使用LDec。
- 在训练了解码器之后,固定解码器,微调编码器,使用解码器的监督来训练。此时损失使用的是LDec,进一步优化编码器。
实际中迭代重复以上步骤,在训练中,每10个epoch便切换到下一个步骤。
实验细节
- 数据集:
- 显著性检测任务:使用DUTS的训练集训练,测试在DUTS的测试集和其他的显著性检测的数据集
- 边缘检测任务:使用BSD500数据集来训练和测试
- A pretrained VGG-16 model is used to initialize the convolution layers in the backbone network. The parameters in other convolution layers are randomly initialized.
- All training and test images are resized to 256×256 before being fed into the network.
- We use the ‘Adam’ method with the weight decay 0.005. The learning rate is set to 0.0004 for the encoder and 0.0001 for the decoder.
- For the salient object detection task, we use four effective metrics to evaluate the performance, including the precision-recall curves, F-measure, Mean Absolute Error and S-measure. As for the edge detection task, we evaluate the edge probability map using F-measure of both Optimal Dataset Scale (ODS) and Optimal Image Scale (OIS).
实验结果
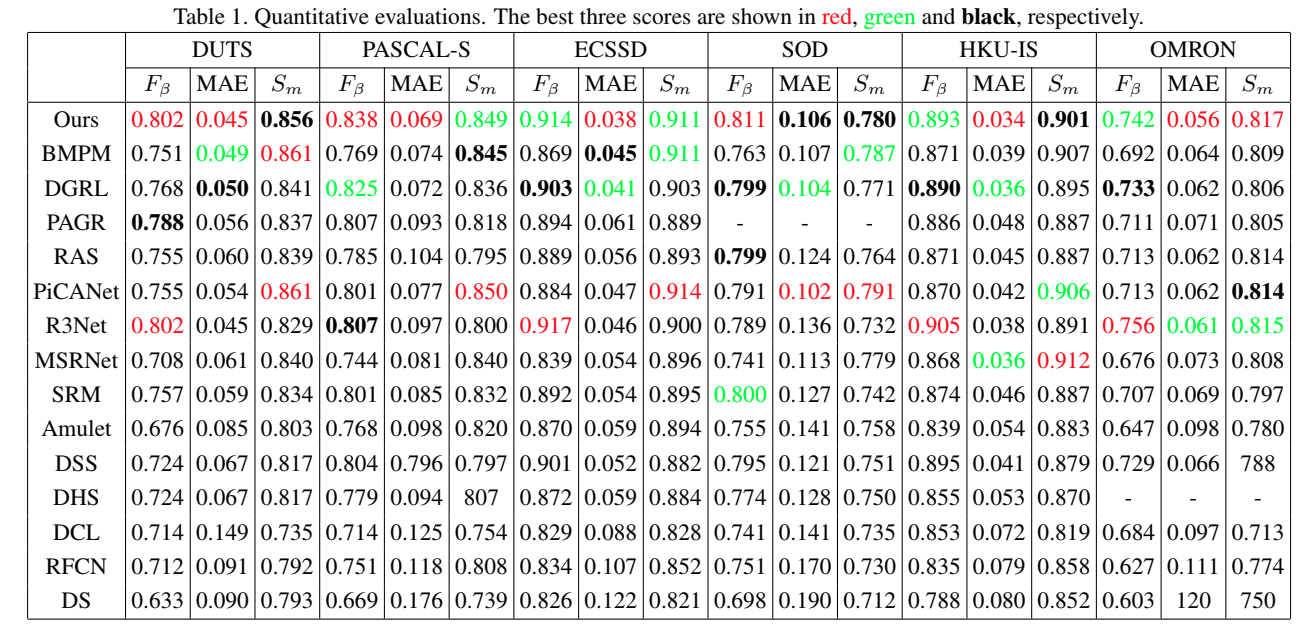

消融实验

First, to demonstrate the impact of MLMs and EMs and the power of the intertwined supervision strategy, we train four models for comparison as follows:
- baseline: a network with simple encoder-decoder architecture as proposed using only S-gt for supervision, and removes the EMs and redundant student branches in MLMs
- +MLM: adding three student branches in each MLM
- +FC: applying S-gt and FC-gt for supervision in intertwined manner
- +EM: the proposed whole network with S-gt and FC-gt for supervision in intertwined manner and employing the EM for edge detection simultaneously.
The comparision is conducted across three datasets (DUTS, PASCAL-S, ECSSD) and the results are shown in Table 3. We can observe that our intertwined supervision strategy (+FC) contributes most to the overall performance. 可见交替式监督策略效果提升最大。
**
均匀高亮与轮廓效果
这里进一步计算了两个额外的指标,一个是the average score of the highlight pixel in saliency maps (ASHP),一个是the accuracy of foreground contour predictions (AFCP),二者的公式如下: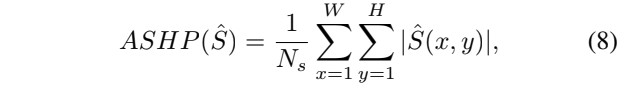
这里的式子中的hatS表示预测的显著性图,这里的Ns表示在hatS上取值大于0的像素数量。也就是计算了在预测的显著性图上的显著性区域均匀高亮的程度。
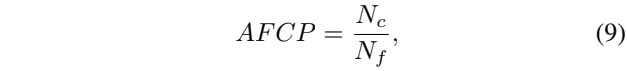
这里的式子中的Nc表示在给定的前景轮廓预测图F和显著性预测图hatS中,满足二者差距小于60的且对应的显著性图中值大于200的像素数量。而Nf表示显著性图上像素值大于200的像素数量。这里实际上衡量了对于预测的显著性图的轮廓的预测能力,一定程度上反映了预测的显著性图的边界的饱满程度。
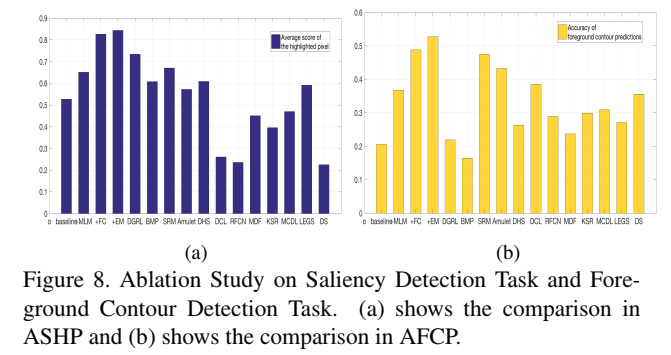
左图可以看到,交替式(+FC)的监督实现了更好的均匀高亮的效果。右图可以看到+EM生成了更好的前景轮廓。
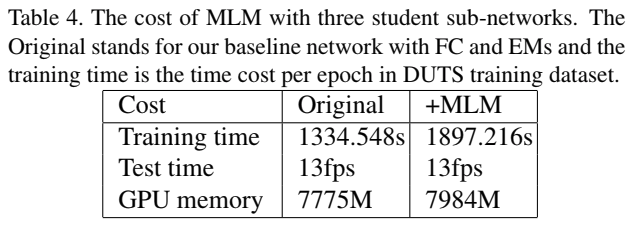
MLM的计算损耗
边缘检测

可以看出,添加了MLM,在一定程度上对于杂乱的背景边缘进行了抑制。
总结
- In this paper, we propose a multi-task algorithm for salient object detection, foreground contour detection and edge detection.
- We employ an intertwined supervision strategy for salient object detection and foreground contour detection, which encourages the network to produce high predicted score on the entire target objects.
- What’s more, we utilize edge detection and saliency detection to guide each other and both tasks gain benefits.
- In addition, we propose a mutual learning module (MLM) to allow the network parameters to converge to a better local minimal thereby improving the performance.
In this way, our model is capable to generate predictions with uniform highlighted region inside the salient objects and accurate boundaries.
The experiments demonstrate that these mechanisms can result in more accurate saliency maps over a variety of images, in the meanwhile, our model is capable of detecting the satisfactory edges much faster.
相关链接

若有收获,就点个赞吧
0 人点赞
