本文仍然使用贝叶斯框架, 但是这里提到了所谓的”低级”与”中级”线索, 如何理解?
mid-level 线索考虑方向,对比度,差距,颜色,空间频率的局部测量, 来推断图像结构。人们提出了许多算法来利用视觉任务的mid-level 线索. 文中使用的是超像素技术.
- 本文先给出了一种基于凸包的显著性区域粗估计方法,该方法包含所有从低水平线索中检测到的兴趣点。
- 然后,基于一种新的基于超像素和粗显著区域表示的中层线索聚类算法估计先验分布
- 提出了一种拉普拉斯稀疏子空间聚类方法对具有局部特征的超像素进行聚类,并对结果进行粗显著性区域分析,计算先验显著性图
- 最后使用超像素和粗糙显著区域(基于凸包的低阶视觉线索), 从而促进对每个像素的贝叶斯显著性的推断, 根据
center-surround原理计算观测似然,得到图像的贝叶斯视觉显著性映射
论文内容
显著性度量与我们如何感知和处理视觉刺激密切相关,通常会产生一个映射,其中每个值描述像素如何在图像中从周围环境中脱颖而出。
Viewed from the information processing perspective, these algorithms can be categorized into bottom-up (stimuli-driven) or top-down (goal-oriented) approaches. 自上而下的显著性检测被认为是一个特殊的目标分类, 结果图指示这目标实例在场景中出现的位置. 特定类别的显著性视觉信息从大量的包含目标实例的图像数据中以一种有监督的方法进行学习. 相反的, 自下而上的显著性图主要基于低级的视觉刺激.
虽然现有的自底向上显著性模型已经取得了令人印象深刻的结果,但仍有几个问题需要解决。
- 其中一个主要的问题是,自底向上的方法通常相对于杂乱背景中的感兴趣目标来说, 对于大量不相关的低级视觉刺激反应更强烈
- 另一个问题是它们无法统一地高亮显著性目标,因为
center-surround的方法往往高亮目标的边界,infomax approaches models往往集中于注视点(eye fixation points) - 最后,一些自底向上的算法在计算上是昂贵的,因为它们通常需要在多个尺度和邻域进行穷举搜索(exhaustive search)来计算每个像素的显著性度量
在本文中,使用贝叶斯显著性模型来解决这些问题,基于 center-surround 原则, 利用低和中水平的线索来产生显著性图。
现有的基于中心包围原理的方法通常使用低水平的线索。也就是说,相对于一个像素的邻域的对比度被计算为它的显著性值。这种方法可能在计算上很昂贵,并且不使用包含在中级线索中的结构信息. 由于只有在低水平线索的基础上,沿轮廓线的高对比度像素才能被确定,因此通常无法统一识别显著目标。此外,由于显著性度量仅基于低水平线索计算,因此常常引入假阳性像素(猜测为真, 实际为假).
基础
首先, 还是基于贝叶斯框架:

接着, 计算兴趣点的凸包,用于显著性目标的粗略区域估计. 这里使用了一个感兴趣点监测器来定位显著性点.
这里使用 color boosted Harris point operator 来检测彩色图像中显著区域的角点或轮廓点. 显著性点提供了关于场景中感兴趣目标的有用空间信息。我们消除了图像边界附近的这些点,并计算一个凸包来包围所有剩余的显著性点.
由于检测到的感兴趣点通常围绕着显著性目标,该方法提供了一个粗略的区域估计。从凸包中提取有用的信息来计算先验分布和观测似然.
先验分布
基于粗糙显著性区域和拉普拉斯稀疏子空间聚类方法计算了贝叶斯显著性模型的先验映射。

基于超像素聚类(图2d)和粗显著性区域的结果,计算出提出的先验图。这里提出了一种基于稀疏子空间聚类的超像素聚类方法。
我们的聚类方法(LSSC, Laplacian sparse subspace clustering method)扩展了稀疏子空间聚类,在超像素级引入了一个带有拉普拉斯矩阵的正则化项。这个正则化术语进一步强制将类似的超级像素聚集到同一个组中.
谱聚类的一个主要问题是如何构造一个有效的邻接矩阵来准确描述每对像素之间的相似性。考虑完全连通图通常是冗余和低效的,现有的方法使用局部邻域信息(如高斯核)来计算矩阵。然而,这些方法通常会遇到尺度问题,几乎总是忽略空间距离较大的成对点之间的相似性。(数学部分跳过)
我们的聚类方法可以很好地将图像聚类到n个分区中,从中可以很好地分割出显著性目标. 然而,聚类算法是在不知道目标对象的情况下以无监督的方式进行的. 这里用凸包来解决这个问题. 根据先前检测到的显著性点,找到一个凸包来包围它们. 根据凸包的像素数来度量簇(分割)的显著性。

用来计算先验概率, 当两个区域没有重叠重叠的时候, 先验概率为0. 这里是把二者都看作一个集合, 主要研究其中的元素(这里以像素作为基础单元, 虽然这里聚类时候的基础是以超像素为基础单元).
观测似然

基于中心周边原则来计算似然概率. 利用凸包内外的低水平视觉线索来计算每个像素处的观测似然, 从而计算贝叶斯显著性测度. 与之前的论文无甚区别, 使用的还是CIELab色彩空间.
最终的先验图是使用聚类好的结果和基于显著性点的封闭凸包划分后的结果, 来定义最终得先验概率.
实验测试
对于聚类的部分, 文中比较了 Sparse Subspace Clustering Algorithm (SSC)和Laplacian Sparse Subspace Clustering (LSSC)两种方法. 虽然SSC方法在聚类方面表现良好,但它只使用低水平的视觉线索。在本研究中, 作者利用超像素技术对中层视觉信息进行聚类.
实验中对二者进行了比较:
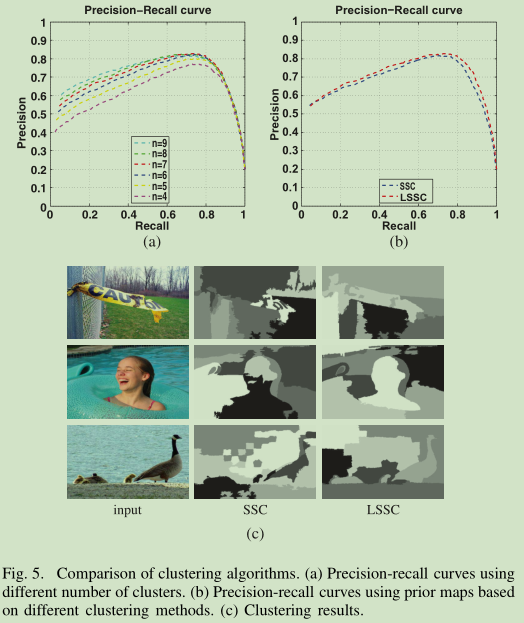


所提出的LSSC方法优于SSC方法,因为它不仅能更精确地聚类每个突出的对象(例如,符号、游泳者和鸭子),而且能更好地保持边界。
请注意 我们的LSSC方法的目标是尽可能精确地对显著性目标进行聚类, 因此, 是否对非显著区域进行良好的分组并不重要.总体而言,基于LSSC方法的先验图具有较高的准确率和召回率。
视觉注意力和图像分割的应用
常用方法:
- Ma and Zhang [54] use region growing and fuzzy theory on their saliency maps to locate objects of attention with rectangles.
- Han et al. [55] employ a Markov random field to group pixels of the prominent object based on their saliency maps and low level features such as color, texture and edge.
- Achanta et at. [25] average saliency values within segments obtained from the mean shift clustering algorithm and flexible thresholds for object segmentation.
- In [28], Cheng et at. apply the saliency map results to initialize the iterative grab cut algorithm [56] for object segmentation,
文中使用的是graph cut算法. graph cut算法能够很好地去除在显著性图中错误检测到的非显著像素,并对突出(prominent objects)目标的边界进行刻画.
不好的情况
- 之前的先验和似然都是基于封闭显著性点的凸包, 如果周围的兴趣点没有出现在显著区域周围或点分散在一个相当大的区域, 就表现很差. (依赖于凸包导致的问题)
- 此外,当聚类结果不精确时,可能会误将一些背景像素包含在提出的先验图中.

在这些情况下,最终显著性映射只会使不精确先验概率分布的影响最小化, 而不会完全去除背景像素.
此外,虽然我们的算法可以使用其他的分割方法(例如[57])来替换超像素,但是与在超像素中得到的高效的中层线索表示相比,是否可以得到额外的改进还不清楚。这种分析超出了这项工作的范围,最好是针对特定的应用程序进行考虑。
57: P. F. Felzenszwalb and D. P. Huttenlocher, “Efficient graph-based image segmentation,” Int. J. Comput. Vis., vol. 59, no. 2, pp. 167–181, 2004.
这是一种基于图表示(graph-based)的图像分割方法。(程明明的RC算法就是先使用这个算法进行的区域分割) 图像分割(Image Segmentation)的主要目的也就是将图像(image)分割成若干个特定的、具有独特性质的区域(region),然后从中提取出感兴趣的目标(object)。
而图像区域之间的边界定义是图像分割算法的关键,论文给出了一种在图表示(graph-based)下图像区域之间边界的定义的判断标准(predicate),其分割算法就是利用这个判断标准(predicate)使用贪心选择(greedy decision)来产生分割(segmentation)。
这个算法有一个非常重要的特性,它能保持低变化(low-variability)区域(region)的细节,同时能够忽略高变化(high-variability)区域(region)的细节。这个性质很特别也很重要,对图像有一个很好的分割效果(能够找出视觉上一致的区域,简单讲就是高变化区域有一个很好聚合(grouping),能够把它们分在同一个区域).
参考链接
- Efficient Graph-Based Image Segmentation: https://blog.csdn.net/surgewong/article/details/39008861

若有收获,就点个赞吧
0 人点赞
