
CVPR 2022 ORAL
- 原始文档链接:https://www.yuque.com/lart/papers/xu5t00
论文:https://arxiv.org/abs/2203.16755
主要内容
本文提出了一种名为随机反向传播(SBP)的内存有效的方法,用于训练视频上的DNN。这是基于这样的发现,即对于反向传播而言,不完整执行时的梯度仍然可以有效地以最小的精度损失来训练模型,这可以归因于视频的高冗余性。
SBP保持所有前向传播路径,但在每个训练步骤中随机和独立地删除每个网络层的反向传播路径。它通过消除对应于反向传播路径的缓存激活值的需求,从而降低GPU存储成本。而这个量可以通过可调节的保持率(keep-ratio)来控制。
实验表明,SBP可以应用于视频任务的各种模型,在动作识别和时间动作检测任务上,可节省高达80.0%的GPU存储,并且提升10%的训练速度,而准确率下降了不到1%。背景介绍
训练视频理解模型的普遍挑战之一是GPU内存的可用性有限。尽管视频模型,例如动作识别和时间动作检测,众所周知的,受益于视频整个跨度上捕获上下文特征的设计。然而对于端到端训练来说,它们并不总是可行的,他们需要尽可能多取输入帧(例如,通常数百个)。例如,当使用Resnet-50作为特征提取器,并以128帧作为输入、批次大小设为4时,训练时间动作检测器中,特征提取器本身就要耗费超过40 GB内存,这可能超过了大多数现代GPU的极限。
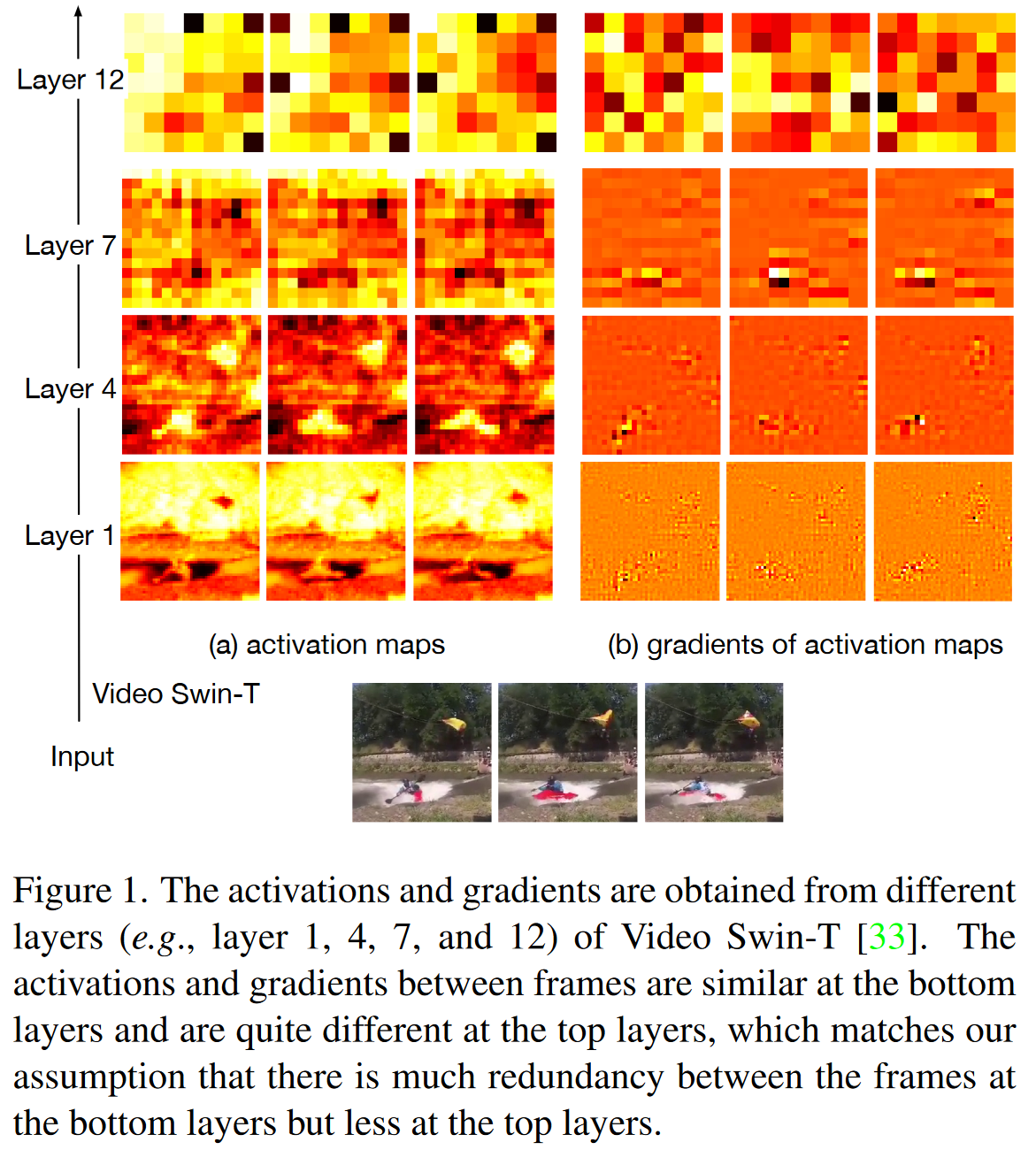
另一方面,视频数据本身是高度冗余的,这实际上暗示了一些优化的可能。我们观察到,在视频模型中,不同帧的激活图和梯度在底层位置上是相似的,但在顶层位置上就会有越来越多的不同。例如图1中所示的,在Kinetics-400上的视频Swin的示例。在模型训练期间,底层看似相似的特征(即细粒度信息)的微小差异对于生成顶层特征的差异至关重要。但是在更新这些底层的参数方面,它们可能不会有太大影响。因此,我们假设完整的激活图(前向路径中的)对于提取重要语义信息是必要的,但对于梯度(反向路径)可能是不必要的。
在本文中,我们提出了一种名为随机反向传播(SBP)的内存节省技术。与以前同时删除前向和反向路径的工作[Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text]不同,SBP随机删除一定比例的反向传播中的独立的反向路径,同时保持所有前向路径。此外,我们发现,这种随机移除反向路径的策略可以以层次化的方式进行,在此过程中,我们直接删除每一层中某些随机采样的神经元的连接路径。请注意,由于反向传播算法的链式依赖性,这将导致网络参数的不完全的梯度计算。但是,我们从经验上发现,只要保留整体计算图,梯度虽然未被完整计算,但是仍然可以有效的更新网络的参数。这使得SBP易于实现(例如文中给的示例代码就和PyTorch自带的checkpoint机制的实现非常类似),而无需考虑跨层依赖的变化。SBP的存储节省来自避免在被删除的计算路径上缓存相应的激活图。由于内存可以安全地重用,因此反向过程几乎不会使用(最多一层)额外的内存,这使得激活缓存成为了训练过程中主要内存成本的来源。因此,节省量仅取决于保持率,并且其较低时,节省内存的程度也更显著。
SBP是一种通用技术,可以被应用于多种视频任务和模型。实验结果表明,SBP训练仅使用0.2×〜0.5×GPU内存,并提升了1.1×~1.2×的训练速度,Kinetics-400和Epickitchen-55上的时间动作检测的任务中,仅有少于1%的精度损失。而在Thumos’14上的时间动作检测中,也有小于1%的mAP损失。相关工作
视频理解
行动识别旨在将一个或多个agents在各种类型和应用的视频中的活动进行分类,从隐私敏感性和监视摄像机,到egocentric videos。
- 给定一个未修剪的视频,时间动作定位估计每个动作实例起止时间。一种常见的做法是首先生成动作提案,然后确定其动作类别和时间界限。另一方面,“bottom-up” fashion的工作中首先做出帧级密集预测,并将其分组为动作实例。
- 在线动作检测中则要随着视频帧达到即时识别动作,而不访问任何未来帧的信息,就会识别动作。
由于GPU存储成本很高,因此大多数离线和在线方法无法以端到端方式进行训练,因此主要是基于从原始视频提取的特征而构建的。
Transformer最近在视频任务中取得了令人信服的结果,例如动作识别和检测。但是,高昂的计算成本和内存需求也限制了其中大多数工作仅仅在短视频片段上训练模型。一些方法也着重于设计Transformer来建模更长形式的输入,但主要用于文本。
内存节省技术
内存和准确性之间的权衡是深度学习研究中的一个恒久的话题。
- 梯度检查点技术[Training deep nets with sublinear memory cost]和梯度累加技术可以节省大量内存(约50%),但可能会减慢训练过程。
- 稀疏网络[Sparse networks from scratch: Faster training without losing performance]应用于图像识别模型,但只能在理论上节省内存。
- Sideways[Sideways: Depth-parallel training of video models, Gradient forward-propagation for large-scale temporal video modelling]中,每当有新激活可用时,就会覆盖原始激活,但这只能应用于因果模型。这也可以降低内存消耗。
关于视频特定的方法,一种用于训练时间动作检测器的流行范式,是在预提取的特征上构建模型,进行时间建模和推理(即图2中的“Freeze Backbone”)。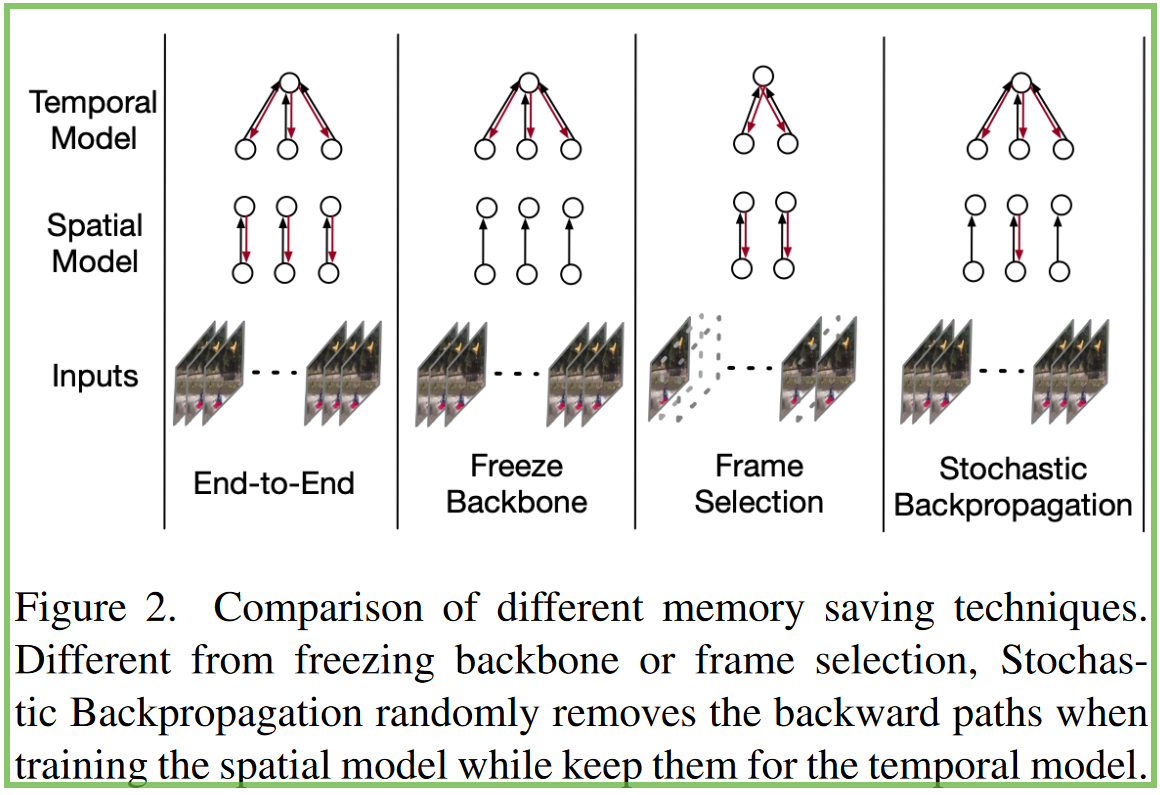
最近的两种方法AFSD和Daotad,经过端到端训练(DaoTAD还冻结了其backbone的前两个阶段),但是它们需要减少空间分辨率(即,在AFSD中使用96×96,在DaoTAD中使用112×112)。但是,冻结backbone或减小输入大小都会降低准确性,而不是最佳解决方案。由于视频通常在相邻帧之间包含高度的冗余,因此不少工作也尝试减少输入帧数量,包括frame dropout[Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text],early pool[No frame left behind: Full video action recognition]和frame selections[Smart frame selection for action recognition](图2中的“Frame Selection”) 。但是,对输入帧的主动降采样将不可避免地会失去时间域中的精细尺度信息,从而对最终准确性产生负面影响[Long-term feature banks for detailed video understanding, Long short-term transformer for online action detection]。此外,这些方法不能应用于需要逐帧预测(例如在线动作检测)或涉及高速移动(例如唇读)的任务。
SBP与其他内存节省技术之间的比较如图2所示。
核心方法——随机反向传播
本文提出了一个内存有效的策略,随机反向传播(SBP),用于训练视频模型。由于浅层的高冗余性,反向传播中,SBP会随机去掉一部分梯度计算。这可以节省内存是因为我们不再需要跟踪用于计算梯度的某些激活。
这部分内容首先介绍SBP在树和图模型中工作的一般思想,这些概念被广泛用于视频任务,然后解释这两种模型的具体实现。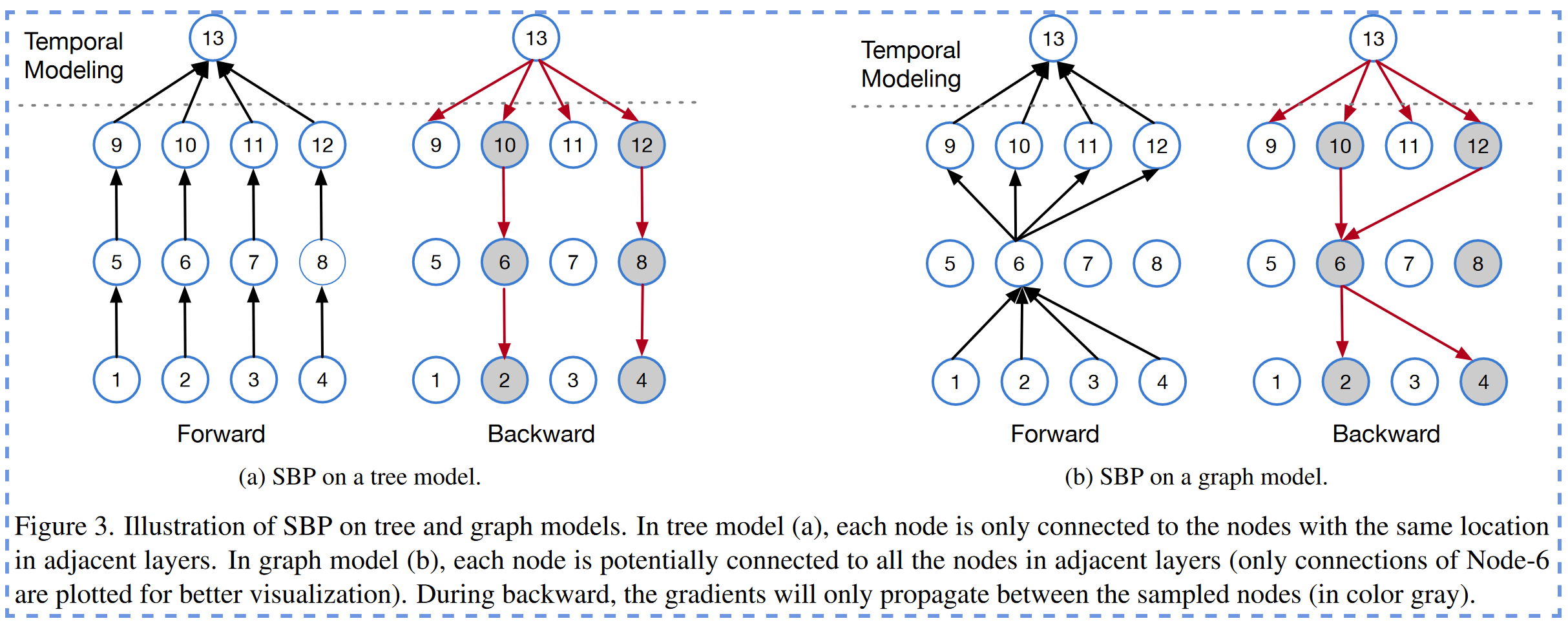
当模型定义时,其反向传播可以看做一个有向无环图(Directed Acyclic Graph (DAG)),表示为G(V,E),其中顶点V对应着为梯度计算缓存的激活,而边E则是用于计算梯度的各个操作。因为模型可以看做不同层的堆叠,所以也可以按照层的方式来组织V中的元素,即V中元素按照对应层序号li来划分成多个Vli。这里的Vli表示层li的输出,而Vl0表示模型输入。每个Vli可以看做是一系列特征向量,例如,如果Vli是一个CxDxHxW的量,就可以把它看做是DxHxW个顶点的集合。这里每个顶点(论文中称为“node”),是一个C维的特征向量。
如图3所示,我们通常将整个模型分为两个部分:1)空间模型(虚线以下)和2)时间模型(虚线上方)。
- 模型的前几层可以看作是时间模型,因为这些层主要从所有帧中学习全局语义信息。
- 所有其他下面的结构通常被视为主要学习空间和局部上下文信息的空间模型。SBP仅应用于空间模型。
树模型是一种具有树状DAG的特殊类型,其孩子节点通常仅与一个父节点相连。它是最简单的模型结构之一,但在长期视频任务中被广泛采用。为了更好地说明SBP,我们首先在树模型上引入SBP,然后将其扩展到更多的一般图模型。
树模型上的SBP
在树模型中的树模型上的SBP,每个节点仅连接到相邻层相同位置的节点(如图3A所示)。在长视频任务中,大多数方法使用一个空间backbone(例如Resnet)来提取帧特征。这样的模型可以看作是树模型,因为帧的处理是彼此的。
图3a显示了在树模型上如何完成SBP。几个顶层用于进行时间建模,从多个帧中捕获时间信息。由于底层的冗余比顶层更大,因此我们仅在底层梯度上执行移除,并保持顶层中的梯度。在正常的端到端训练期间,由于下面结构中特征尺寸要比顶层结构中的高得多,所以大多数内存都在底层消耗。SBP在底层中移除梯度,消除了跟踪相应中间节点的必要性,从而可以节省大量内存。
图模型上的SBP
在更通用的图模型中,每个节点都可能连接到相邻层处的所有节点(如图3b所示)。Vision Transformer是一种全连接的图模型。图3B显示了在图模型上如何完成SBP。
- 前向传播中,每个节点将从上一层中的所有节点汇总数据(这里仅绘制Node-6的连接以更好地可视化)。
- 反向传播中,类似于树模型,仅在被采样的节点之间传播梯度。
在树模型中,采样节点的梯度与使用所有节点训练的梯度完全相同。例如,在图3a中,我们为节点6计算的梯度始终是相同的,无关于Node-9,11,5,7是否被采样。而图模型中,因为所有顶层节点将传播梯度到底层节点,采样节点的梯度计算将会随着从上到下越来越不精确。然而,由于从上到下冗余性越来越多,所以这也不是什么大问题。跨层维持采样节点不变也将可以缓解这一问题。我们为所有层设置一个均匀均匀的保持率,以简化参数的识别。但是我们确实注意到,可以制定一种系统的策略来设置层特定的保持率。
为什么可以仅用部分梯度来有效的学习?
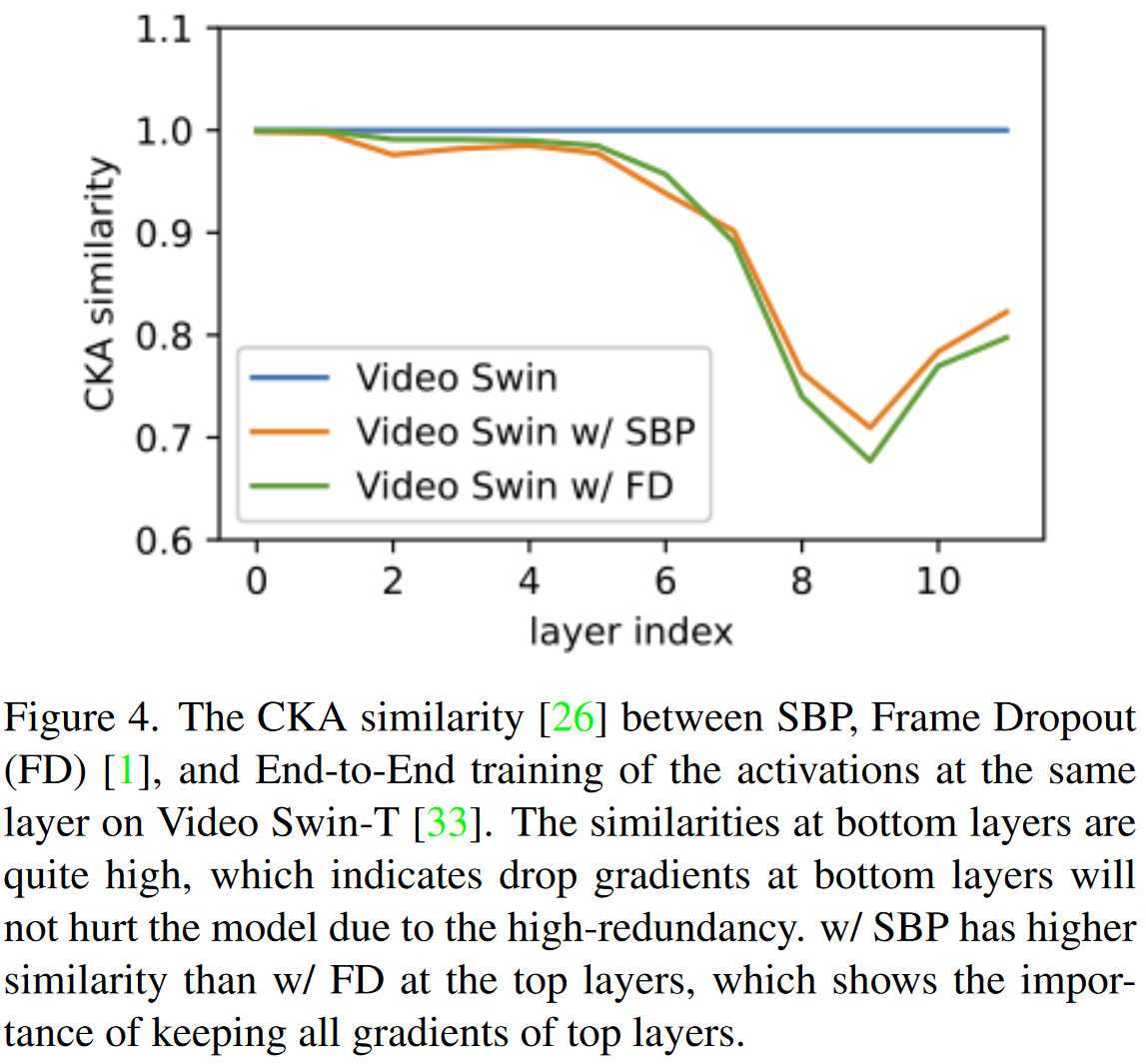
我们认为这是因为我们删除了帧之间的冗余,但保留了所有重要的信息。如图1所示,因为帧之间,底层上的激活图和这些激活图的梯度非常相似,因此去掉某些帧的梯度不会过度伤害模型。图4也支持了这一点。 范围在0到1支之间的CKA相似性[Similarity of neural network representations revisited]用于测量两个神经网络之间表征的相似性。
帧丢弃(FD)[Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text]仅使用基线所使用的帧的数量的1/4进行训练,这相当于在所有层中去掉3/4的梯度。
FD的曲线是使用1/4数量帧训练的模型与使用所有帧训练的模型(即基线)之间的CKA相似性。前6层相似性非常高(>0.9),这意味着丢弃一部分梯度并不会显着降低模型的性能。
与帧选择模型的比较
帧选择方法[Smart frame selection for action recognition, Scsampler: Sampling salient clips from video for efficient action recognition]使用轻量级网络从视频中采样帧,然后将采样帧送到目标模型。
假设我们使用相同的帧采样器,SBP和帧选择方法之间的差异在于是否保留未采样帧的前向传播路径。
我们强调保持所有帧的前向传播路径是重要的。进行时间建模的顶层从所有框架中学习全局时间信息,因此,学到的特征中包含较小的冗余,如图1所示。删除前向路径,如帧选择方法,将影响时间建模。因为更不冗余的时间模型只能从一组采样的帧中学习。如图4所示,在顶层使用SBP保持梯度保持CKA相似性高于使用FD直接丢弃梯度。
与梯度丢弃[Regularizing metalearning via gradient dropout]的比较
SBP和梯度丢弃都是在反向传播中丢弃梯度。我们的SBP旨在通过丢弃大量(即75%)的反向路径来节省内存,而梯度丢弃策略的旨在通过随机置零(zero out)较小比例(10%~20%)的梯度来正则化训练过程。我们探索了梯度丢弃在新方向上的应用,并且设计了一种策略以删除反向路径,这可以实现节省内存的目的。
使用
树模型常被用在长期视频任务中,这需要使用数以百计的帧作为输入。对于短期视频人物而言,例如动作识别,全连接图模型,例如Video Transformer实现了最佳性能。这部分将会介绍他们。
Spatial-then-Temporal (StT) Models
对于诸如在线动作检测和离线动作检测等长期任务而言,大多数现有方法都是StT的模型。StT模型是树模型的实例(图3a)。他们首先使用空间模型(使用滑动窗口的2D或3D-CNN)来提取每个帧/或片段的空间特征,然后将提取的特征馈送到时间模型(RNN,Transformer等)中进行时间建模。
将空间模型表示为fs,时间模型表示为ft,输入的视频x看做是一个CxDxHxW大小的包含着D帧大小为HxW图像的clip,我们忽略了batch维度。空间模型取大小为CxKxHxW的输入,这里K是输入的视频chunk中的帧数。例如2D-CNN取单帧作为输入,此时K=1,而3D-CNN则是多帧一起送入。此类模型的前向传播就是每次对空间模型送入一段K帧图像获取中间特征,所有特征汇聚后由时间模型得到最终结果。
该模型中,空间模型主要提取空间和局部时间信息。而时间模型则用于从空间模型的输出中聚合全局时间语义特征。由于时间模型包含着更少的冗余性,SBP因此仅用于空间模型中。
SBP可以通过使用预定义的采样函数,划分输入帧到两个集合来实现:集合1保持梯度,集合2丢弃梯度。前向传播期间,跟踪集合1中帧对应的所有激活,而只跟踪集合2中帧对应的特征。然后可以拼接提取的特征在时间模型ft上做一个完整的前向传播和反向传播。
Video Transformer
对于短期视频任务,例如行为识别,Video Transformer例如TimeSformer和Video Swin Transformer实现了卓越的性能。这里基于这类工作来实例化SBP。
在树模型中,一个时间位置的输入节点独立于空间模型中其他时间位置的节点,因此我们可以轻松地在其上应用SBP。但是,在Video Transformer中,由于注意力层的点积运算,不同时间位置的节点相互依赖。我们通过在层级别应用SBP,而非树模型中的模型级别,从而解决此问题。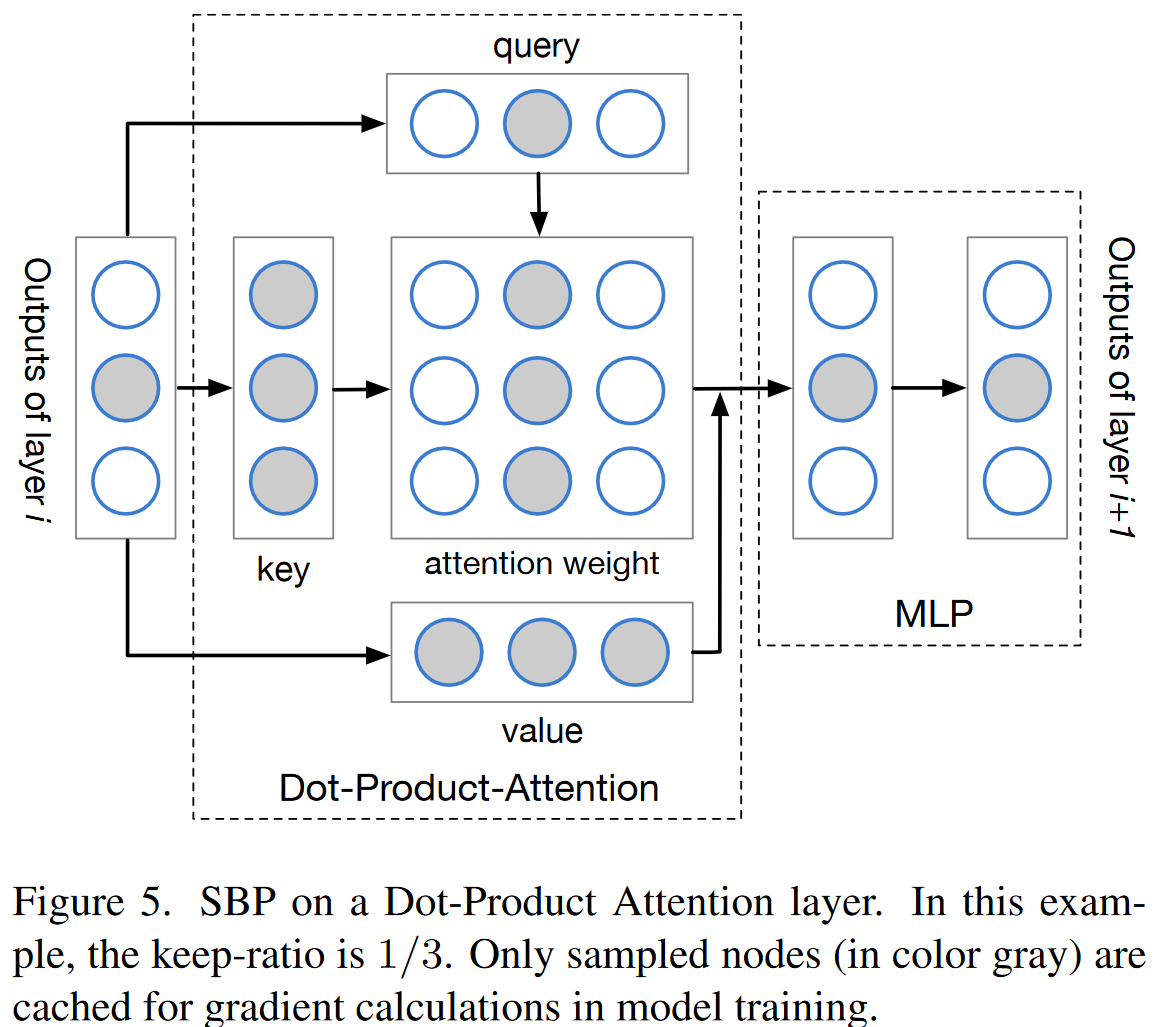
图5显示了如何将SBP应用于Transformer层。对所有层进行采样相同的节点(图5中的灰色节点)。在点积注意力中,所有key和value节点都与每个query节点有关。给定输出中采样节点的梯度,为了准确计算query中相应节点的梯度,对所有key和value节点进行采样。对所有key和value节点进行采样只会稍微增加内存消耗,因为注意力重量构成了注意力操作中GPU存储消耗的大头。假设query、key和value都是(hxd)xn大小的,并且注意力权重的形状是hxnxn,这里的h、d和n是头的数量,每个头的维度,和token的数量。Video Transformer中,n通常远大于头的维度,例如在Video Swin中,n=392,而d=32。因此注意力权重是内存占用的大头。
Video Transformer中,我们认为最顶层的数层,本文中使用3层,作为时间模型,这些部分有着完整的反向传播路径,而SBP仅用于剩下的那些层中,这可以看作是空间模型。
有效的实现

算法1中给出了对于任意操作f的实现,这包括StT模型中的空间模型,和Video Transformer中的点乘注意力以及多层感知机。只有被采样的需要计算梯度的输入会被保存用于反向传播。反向传播期间,SBP会对采样输入重新前向传播和回传梯度。这可以充分利用现代深度学习框架中的自动微分引擎,所以效率很高,几乎没有开销。
空间和时间复杂度
对于StT模型,Ms是空间模型需要的内存,而Mc时间模型需要的内存。因此最终的空间占用率是(rMs+Mc)/(Ms+Mc),这接近于r,因为Ms通常大于Mc的5倍到10倍。
对于Video Transformer模型,d和n是多头注意力的头的维度和token的数量。其中需要计算梯度的激活图包括多个部分,2倍的输入(2hdn)、qkv向量(hdn),softmax前后总共2hnn大小的注意力权重,以及10hdn大小的mlp的参数。因此总共需要15hdn+2hdn的内存。SBP缩减query到hdnr,注意力权重是2hnnr,MLP到10hdnr。因此空间比例几乎正比于采样率r。因此内存小号的降低是显著的,如果r够小的话,例如0.25。这是因为训练阶段,大部分的内存占用是用于缓存梯度计算所需要的激活值,但是用SBP,我们只需要缓存部分采样的激活即可。
关于时间压缩比例,假设前向传播和反向传播的时间是相等的,那么完整的比例就是(1+2r)/2,因为实际上我们执行了1+r倍的前向传播和r倍的反向传播。
实验
行为识别
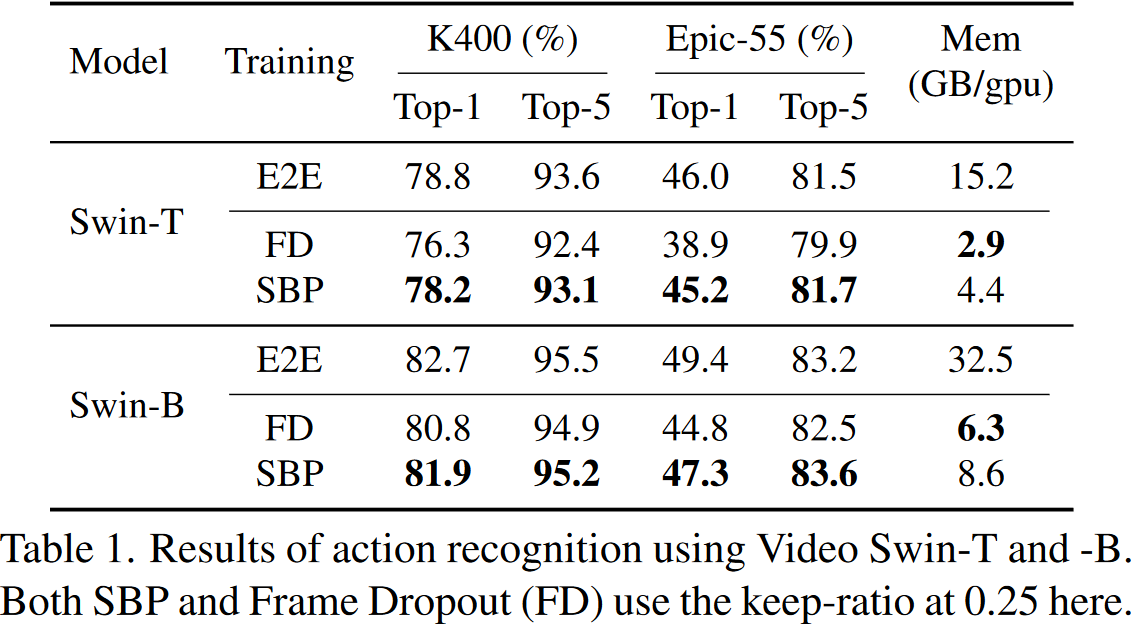
SBP被应用到最新的行为识别模型,Video Swin,并且在Kinetics-400和EPIC-Kitchens-55上构造实验。这里汇报动词分类的Top-1和Top-5准确率。
对于SBP,我们沿时间维度使用均匀随机采样器,以使与一帧相对应的节点要么都被采样或被丢弃。在所有层中,采样节点保持一致。SBP应用于带有{2,2,6,2}层设定的视频Swin-T的前8层,并应用于带有{2,2,18,2}层设定的视频Swin-B的前18层。
在和完整训练以及FD策略的对比中,SBP展现出了良好的表现。尽管FD的消耗最少,但它会导致准确性的显着降低,尤其是在重度依赖时间信息的数据集(Epic-55)上。这表明了在训练和推理过程中保持所有前向传播道路的重要性。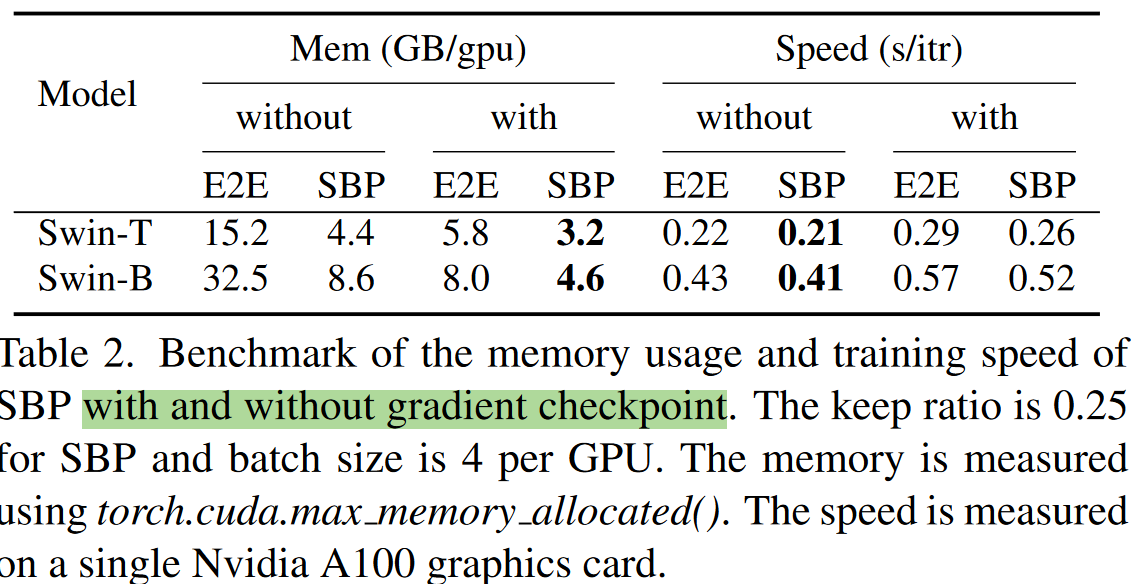
并且在实验中,作者也测试了和梯度检查点技术和混合精度的搭配与对比。相较于单纯的梯度检查点,二者内存消耗接近,但是SBP可以快约30%,而一起使用时,相较于单独使用SBP,可以额外节省约40%的内存占用。更进一步也测试了SBP和O1级别的混合精度训练的搭配效果,发现这可以节省Swin-T超过约50%的内存,而没有性能的下降。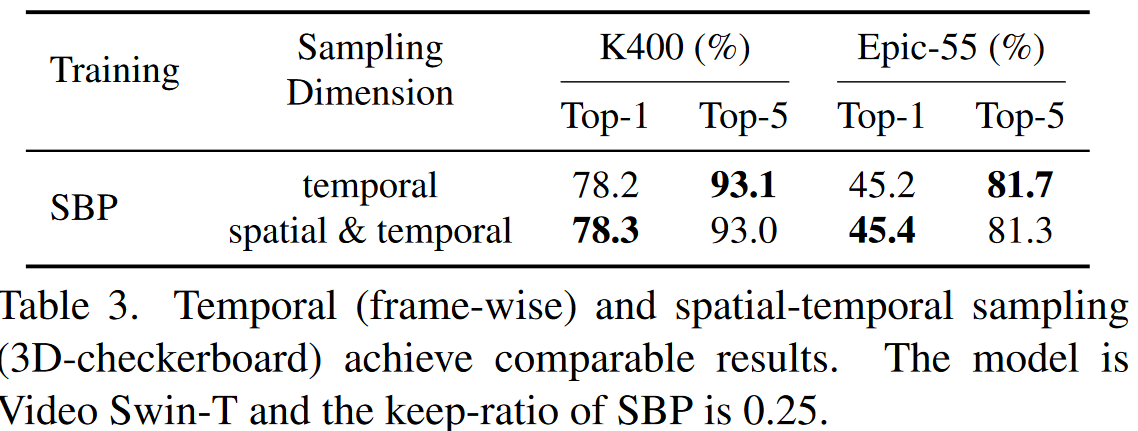
前面的实验都是在时间维度,即对应于一帧的节点要么被全部保留,要没被全部丢弃,所以值得考虑的是,是否可以在时间和空间上全部丢弃梯度呢?为了验证这一点,作者们通过使用3D棋盘模式的时空梯度丢弃策略,记性了实验。在对比中,时间采样(即帧级别的处理)和时空采样(即3D棋盘形式)实现了相近的性能。这也反映出了SBP可以用于空间采样。这也反映出了所提方法迁移到图像域的潜力。
时间行为检测
为了验证在长时间视频任务中的表现,作者们也在多个时间行为检测的先进方法上进行了验证。这杯构建在THUMOS’14数据集上。由于其训练集都是被裁剪的视频,这并不能用于蓄念时间动作检测模型,我们使用参考工作的策略,在验证集上训练,测试集上评估。
针对在线动作检测任务而言,给定实时视频流,其尝试检测正在发生在每一帧的动作,而不能看未来的信息。现存方法延续StT范式,这里空间模型被预训练来提取视频帧的特征,并且时间模型在特征序列上操作捕获长期上下文。这里使用TRN和LSTR构建在RGB输入上(这里要注意,原始论文中,他们使用集成RGB和光流来作为输入,这里不失一般性,仅仅使用RGB输入)。另外,TRN使用循环网络处理时间建模,而LSTR则使用多个级联的Transformer来捕获长短期依赖关系。而且本文的实现中,使用K400数据集上预训练的ResNet50作为空间模型。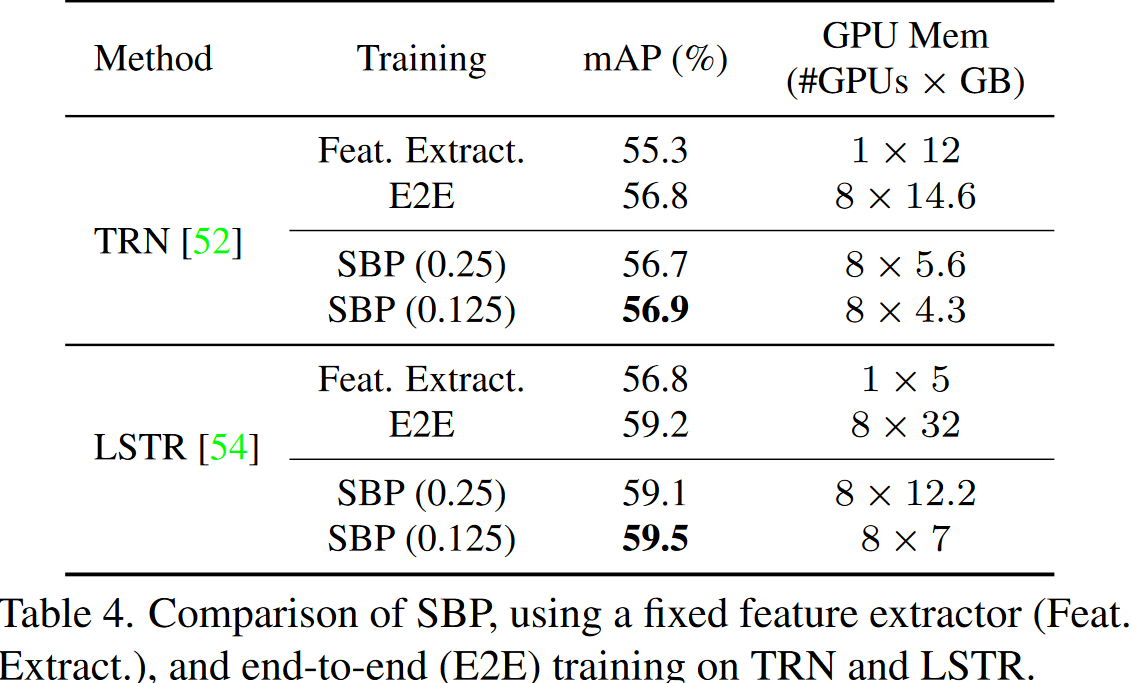
在实验中可以看到:
- 端到端训练性能上要优于冻结backbone的策略。
- 一个有趣的观察是,较低的保持率r=0.125的SBP,最终性能甚至略高于端到端训练,这可能是SBP可以用于正则化以缓解过拟合的原因,Thumos数据集则相对较小。
- 而且,LSTR的改进大于TRN的改进,这表明更强的时间模型可以从端到端训练中受益。
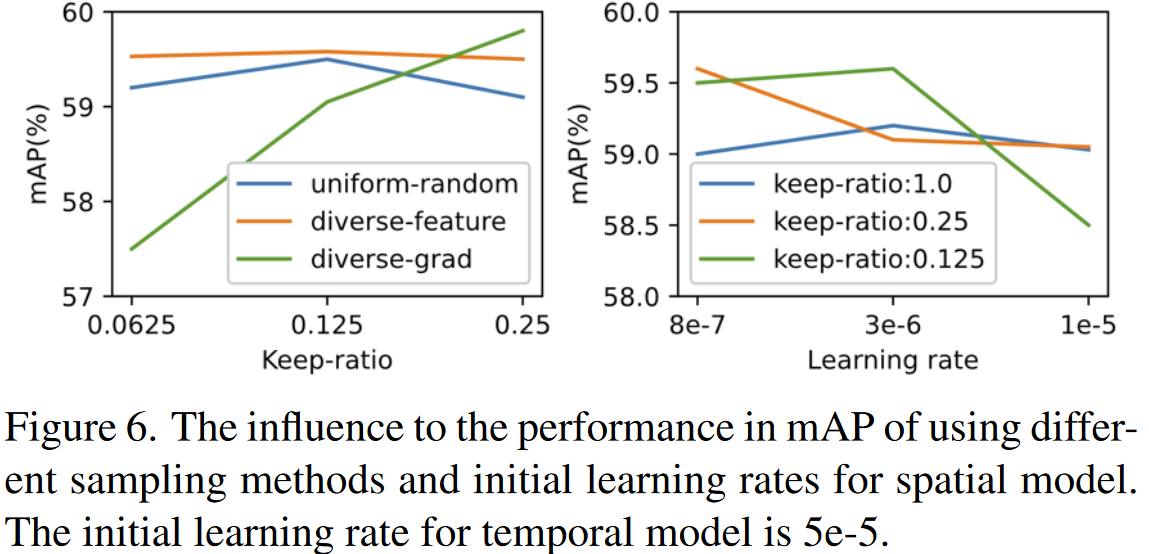
SBP中一个关键点是如何去采样顶层的输出节点。这里对比了三种策略:
- Uniform Random Sampler:沿着时间维度均匀划分候选节点到多个chunk中。每个chunk的大小为1/r。最终在每个chunk中随机采样一个节点。
- Diverse-Feature Sampler:首先根据他们的幅度,排序候选节点,然后执行均匀采样。
- Diverse-Grad Sampler:按照幅度排序候选节点的梯度,然后执行均匀随机采样。
从对比中看到:
- diverse-feature sampler实现了最好的mAP。
- 这三种采样器mAP确实相近,也反映出了方法对采样器的鲁棒性。
因为均匀采样实现了不错的mAP,而且还更加简单,于是默认被用于其他所有实验。
作者还对空间模型的学习率的设定进行了实验。对于使用SBP的StT模型:
- 对于所有的保持率,最佳的空间模型的学习率大约是时间模型的0.1倍左右。
- 使用SBP,空间模型确实对于学习率更加鲁棒一些,只要它们相对小一点。
因此,如果未声明的话,默认设置空间模型的学习率是时间模型的0.1倍。
时间动作定位
时间动作定位旨在检测未修剪视频中每个动作实例的时间边界。大多数现有方法遵循StT范式。我们将最新方法G-TAD作为基线,并在Thumos’14上进行实验。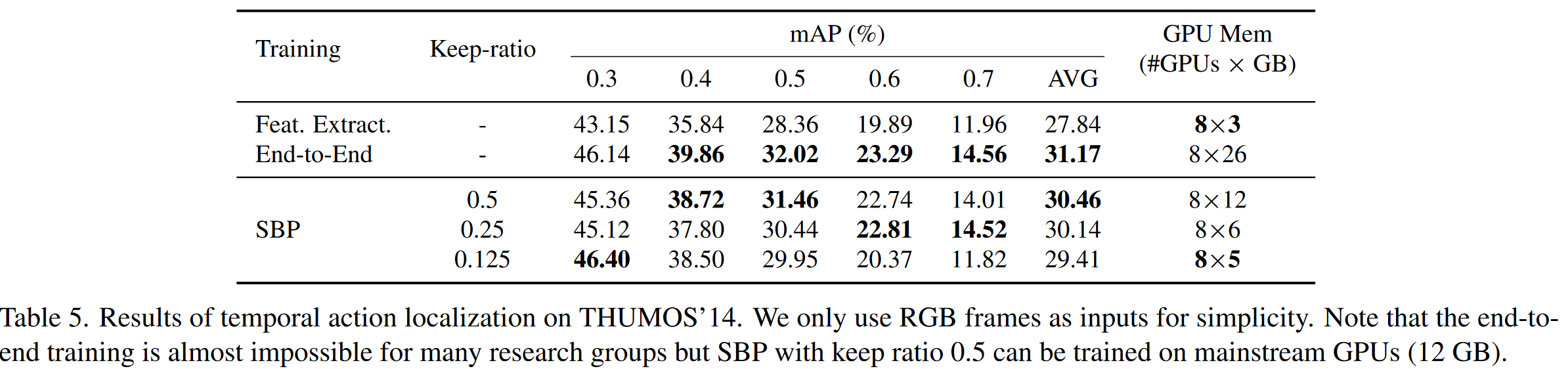
实验中,端到端训练性能优于冻结backbone的,但是显存占用也大得多。引入SBP后获得了更好的权衡。
总结
本文提出了一种简单而有效的技术,随机反向传播(SBP)。这可以大幅减少训练视频模型的GPU占用。然而,目前的工作仍然存在一些局限性。
- 首先,SBP是一个新的原型技术,这可以证明可以通过丢弃反向传播路径来节省内存,但是作为副加产品,它会导致精度稍微下降。未来的的探索可以关注于更加自适应的层保持率和采样方法,以降低准确性的损失,甚至由于梯度丢弃带来的的正则效果而提高准确性。
- 其次,SBP仅提升了少量的训练速度(~1.1×)。但是,如何将其与其他有效的模型训练策略(例如Multigrid [A multigrid method for efficiently training video models])集成,以加快训练的速度仍然有待探索。

若有收获,就点个赞吧
0 人点赞
