
前言
显著性目标检测领域终于还是出现了做NAS的方法。
比较有意思的地方在于,文章使用自动架构搜索方法从针对多模态(RGB-D)和多尺度(不同Level)特征设计的搜索空间进行模块架构的搜索,得到了一套效果不错的结构。
提出的方法
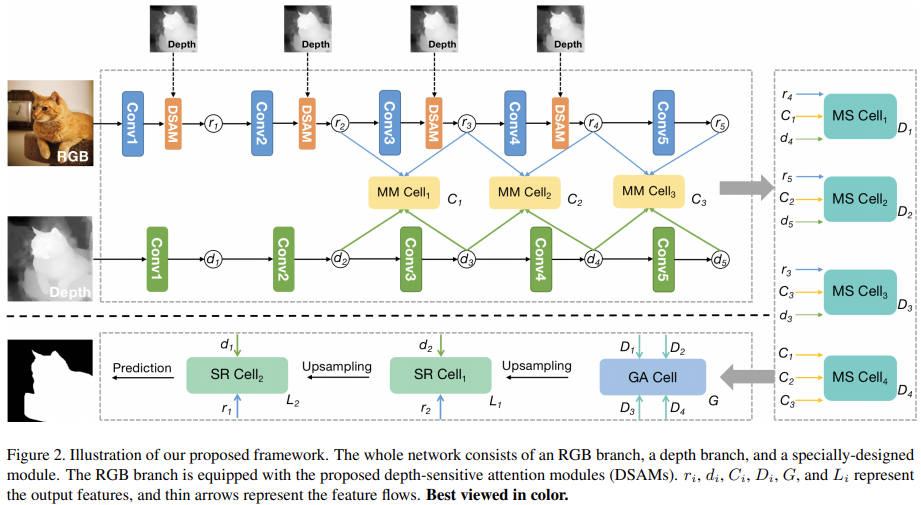
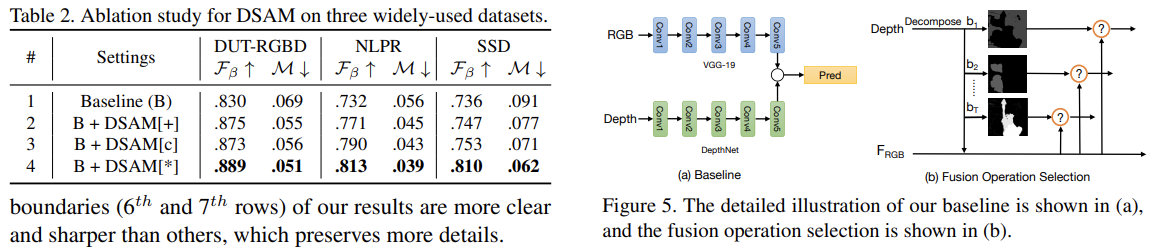
Depth-Sensitive Attention
关于Depth使用的部分,文章提出的双流模型的RGB流中更加显式的利用了Depth包含的几何先验信息。
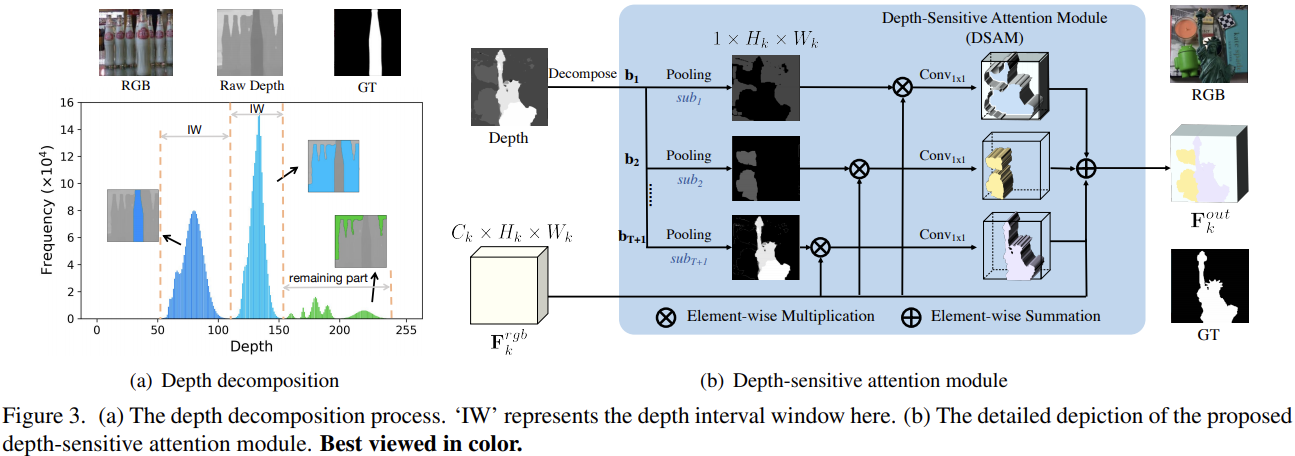
- 直接从Depth数据的直方图入手,从中选择T个最大的深度分布模式(depth distribution modes,论文中是这么说的,应该指代就是直方图中的各个独立的峰),对应T个depth intrerval windows,剩下的区域形成另外一个单独的区域。
- 最终获得的每个区域内部会被直接归一化到0~1,从而作为后续处理中的spatial attention mask。
也就是利用Depth数据直接构造了T+1个mask。为了匹配对应特征的尺度,这里直接使用最大池化来“对齐”(其实也不算真正意义上的对齐)mask与特征。后续与特征相乘后通过卷积融合。再利用家和操作直接整合所有的T+1个分支的信息,将其再加到原始特征上获得最终输出。
通过这种方式,DSAM不仅提供了RGB特征的深度几何先验知识,而且还消除了难以处理的背景干扰(例如杂乱的物体或类似的纹理)。
Auto Multi-Modal Multi-Scale Feature Fusion
NAS
有必要先了解下NAS当前的现状。
NAS旨在实现网络体系结构设计过程的自动化。
- 早期的NAS工作是基于强化学习或进化算法。尽管取得了令人满意的性能,但它们消耗了数百GPU天的时间。
- 近年来,one-shot方法通过训练父网络,而每个子网络都可以继承权值,极大地解决了耗时的问题。
- DARTs是基于梯度的NAS的开创性工作,它使用梯度有效地优化搜索空间。
为了进一步了解NAS,找到一个梳理NAS各种方法的系列博客,有必要通读一下:
- AutoDL论文解读(一):基于强化学习的开创性工作:https://blog.csdn.net/u014157632/article/details/101721343
- AutoDL论文解读(二):基于遗传算法的典型方法:https://blog.csdn.net/u014157632/article/details/102364694
- AutoDL论文解读(三):基于块搜索的NAS:https://blog.csdn.net/u014157632/article/details/102469380
- AutoDL论文解读(四):权值共享的NAS:https://blog.csdn.net/u014157632/article/details/102501816
- AutoDL论文解读(五):可微分方法的NAS:https://blog.csdn.net/u014157632/article/details/102556298
- AutoDL论文解读(六):基于代理模型的NAS:https://blog.csdn.net/u014157632/article/details/102568194
AutoDL论文解读(七):基于one-shot的NAS:https://blog.csdn.net/u014157632/article/details/102600575
本文的创新
虽然多模态融合的NAS工作有几种,但其设计目的主要是针对视觉问答任务或图像-音频融合任务。作者们认为这是第一次尝试利用NAS算法来解决RGB-D SOD的多模态多尺度特征融合问题。 :::info 这里提到了两篇做分割的NAS值得参考:
本文作者的另一份工作:Graph-guided architecture search for real-time semantic segmentation
Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation :::
搜索空间
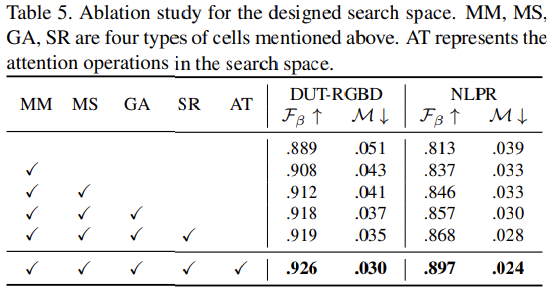
针对multi-modal multi-scale fusion设计了四种类型的cell,分别是MM、MS、GA、SR,用于构建整个任务特定的搜索空间。
MM用来处理RGBD多模态融合
- MS用来处理多尺度特征融合
- GA用来集成MS cell的输出来捕获全局上下文
- SR用来组合low/high-level特征从而补充由于下采样操作丢失的细节信息
对于MM而言,可能的输入为r2-5,d2-5(可见网络结构图):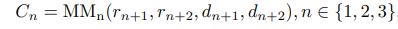
对于MS而言,主要包含两类结构,一个是融合来自不同level的特征的MS,以及融合来自MS的输出的MS: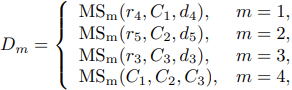
紧接着会用GA来整合MS的输出:
最终,使用SR来融合high/low-level的特征: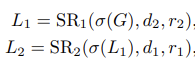
这里的 表示上采样函数。
表示上采样函数。
最终一个简单的解码器被用来输出最后的预测,包含两个双线性上采样函数以及各自紧接的三层卷积层。
Cell结构搜索
前面提到的每个cell都是可以通过一个包含N个节点( )的有序序列的有向无环图来统一表示。每个节点是一个latent representation,即特征图,并且每条有向边(i,j)与一些候选操作
)的有序序列的有向无环图来统一表示。每个节点是一个latent representation,即特征图,并且每条有向边(i,j)与一些候选操作 相关联,例如卷积、池化等,这表示了从节点i到节点j之间的所有可能的转换。每个中间节点j会基于它所有的前驱节点进行计算:
相关联,例如卷积、池化等,这表示了从节点i到节点j之间的所有可能的转换。每个中间节点j会基于它所有的前驱节点进行计算: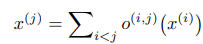
为了使得搜索空间连续,这里将特定操作的硬性选择放松为所有可能操作的softmax,这一点是来自Darts: Differentiable architecture search。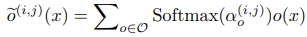
这里的o表示操作集合中的一个操作,而α表示对于边(i,j)而言,针对操作选择的科学系的架构参数。因此每个cell结构有 表示。而整个可搜索的融合模块可以表示为
表示。而整个可搜索的融合模块可以表示为 。相同类型的cell共享相同的架构参数,但是权重不同。
。相同类型的cell共享相同的架构参数,但是权重不同。
搜索之后,最终的操作可以通过使用具有最大 的操作替换每个混合操作
的操作替换每个混合操作 。
。
优化
在搜索过程中,使用原始训练数据的一半作为验证集。另外使用bi-level optimization来联合优化架构参数 和网络权重
和网络权重 :
: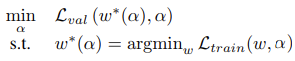
这里的的两个L分别表示验证损失和训练损失,二者皆为交叉熵。最终融合模块通过离散的获得。
在获得融合模块后,整个网络通过标准交叉熵损失来在整个训练集数据上直接基于训练损失来优化。
实验细节
- Backbone:RGB(VGG-19),Depth(VGG-19)
- 对于depth-sensitive attention module,其中使用的depth decomposition regions是3。
- 搜索过程中,MM、MS、GA、SR各个cell中,节点数量分别为8,、8、8、4。
- 候选操作集合包含以下操作:
- max pooling
- skip connection
- 3x3 conv
- 1x1 conv
- 3x3 separable conv
- 3x3 dilated conv (dilation=2)
- 3x3 spatial attention
- 1x1 channel attention
- 搜索过程中,训练参数:batch size=8
- 架构参数被使用adam优化,初始学习率为3e-4,
 ,权重衰减为1e-3。
,权重衰减为1e-3。 - 网络参数通过SGD优化,初始学习率为0.025,动量为0.9,权重衰减为3e-4。
- 整个搜索过程包含50个epoch,4x1080Ti花费20个小时。
- 架构参数
- 搜索结束后,整个网络在一块1080Ti上训练,输入图像为256x256。动量、权重衰减、学习率为0.9、5e-4、1e-10。60个epoch受凉,batch size为2。使用随机翻转剪裁和旋转增强训练数据。
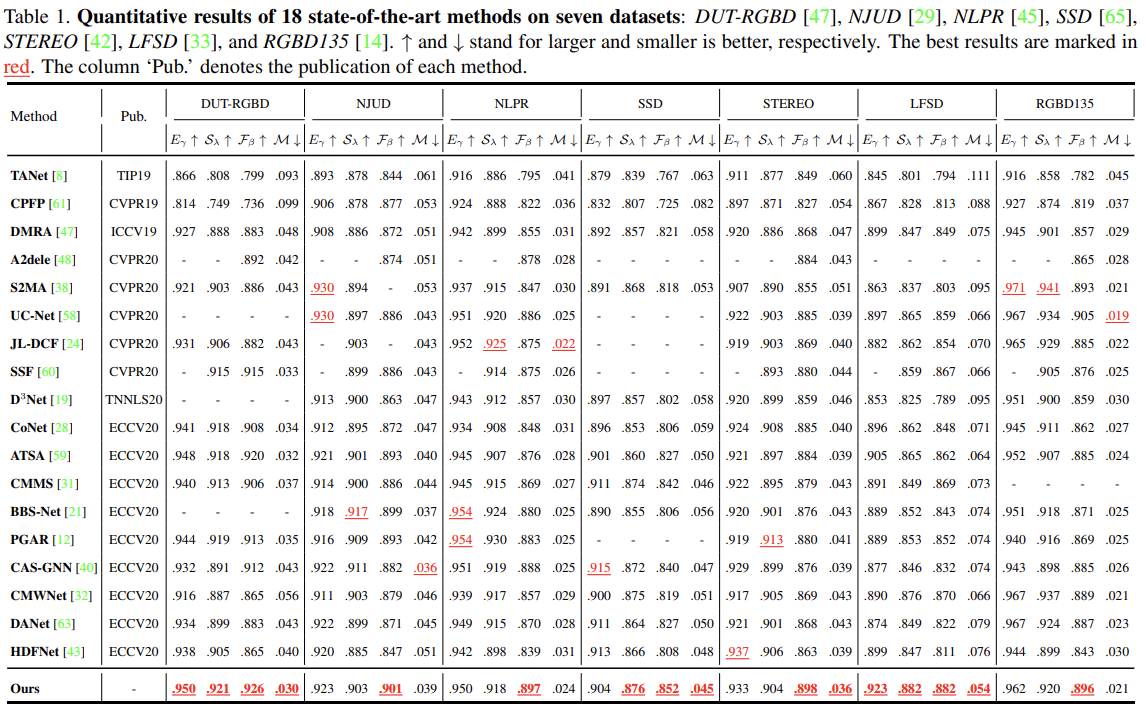


由于Arxiv版本没有附出补充材料,具体搜出的结构仍未可知,但是关于搜出的结构,作者也稍微提了一下:
An interesting observation is that in the MM cell, the numbers of operations connected to RGB features are more than those connected to depth features. The phenomenon demonstrates that considering the differences between RGB and depth data, numerous redundant operations or channels of depth features are unnecessary, which also verifies the asymmetric two-stream architecture for RGB and depth branches in ATSA[Asymmetric two-stream architecture for accurate rgb-d saliency detection] is reasonable.
相关链接

若有收获,就点个赞吧
0 人点赞
