
摘要
弱监督语义图像分割的主要障碍是难以从粗略的图像级注释获得像素级信息。大多数基于图像级注释的方法都使用从分类器中获得的定位图,但这些方法只关注对象的较小的部分,而不是捕获精确的边界。FickleNet探索了由通用深度神经网络创建的特征图上的各种定位组合。它随机选择隐藏单元,然后使用它们获得图像分类的激活分数。
FickleNet隐含地学习了特征映射中每个位置的一致性,从而产生了一个定位图,它可以识别对象的其他部分。通过选择随机隐藏单元对从单个网络获得整体效果,这意味着从单个图像生成各种定位图。我们的方法不需要任何额外的训练步骤,只需在标准卷积神经网络中添加一个简单的层; 然而,它在弱和半监督环境中的Pascal VOC 2012基准测试中表现优于最近的可比技术。
主要贡献
The main contributions of this paper can be summarized as follows:
- We propose FickleNet, which is simply realized using the dropout method, that discovers the relationship between locations in an image and enlarges the regions activated by the classifier.
- We introduce a method of expanding feature maps which makes our algorithm much faster, with only a small cost in GPU memory.
- Our work achieves state-of-the-art performance on the Pascal VOC 2012 benchmark in both weakly supervised and semi-supervised settings.

- 利用卷积神经网络中隐藏单元的随机组合,可以从一张图像生成多种定位图,如图a所示.
- FickleNet从VGG-16等一般分类网络创建的特征图开始,为每个滑动窗口位置随机选择隐藏单元,对应于卷积运算中的每一步,如图b所示. 这个过程简单地通过dropout实现。
- 在滑动窗口位置选择所有可用的隐藏单元(确定性方法)往往会产生一种平滑效果,混淆前景和背景,这可能导致两个区域同时被激活或停用。
- 隐藏单元的随机选择(随机方法)产生了不同形状的区域,这些区域可以更清晰地描述对象。
- 因为FickleNet隐藏单元随机选择的模式包括不同膨胀率的扩张卷积的卷积核形状, 所以FickleNet可以被视为一个泛化的扩张卷积.
- 但FickleNet可能匹配不同尺度和形状的目标, 只使用一个网络, 因为它并不局限于一个方格的隐藏单元, 而膨胀卷积则需要不同膨胀率的网络去缩放其卷积核。
主要工作
主要流程包括以下步骤:
- Stochastic hidden unit selection: FickleNet,它使用随机选择的隐藏单元,多分类任务训练。
- Training Classifier: 然后生成训练图像的定位图。
- Inference CAMs: 最后,利用定位图作为伪标签训练分割网络。
我们将标准深度神经网络的典型特征图表示为 ,其中w为宽度, h为高度, k为通道数, 训练FickleNet和生成定位图的过程如算法所示
,其中w为宽度, h为高度, k为通道数, 训练FickleNet和生成定位图的过程如算法所示

主要分为三个部分, 随机隐藏单元选择, 训练分类器, 推理CAMs.
Stochastic Hidden Unit Selection
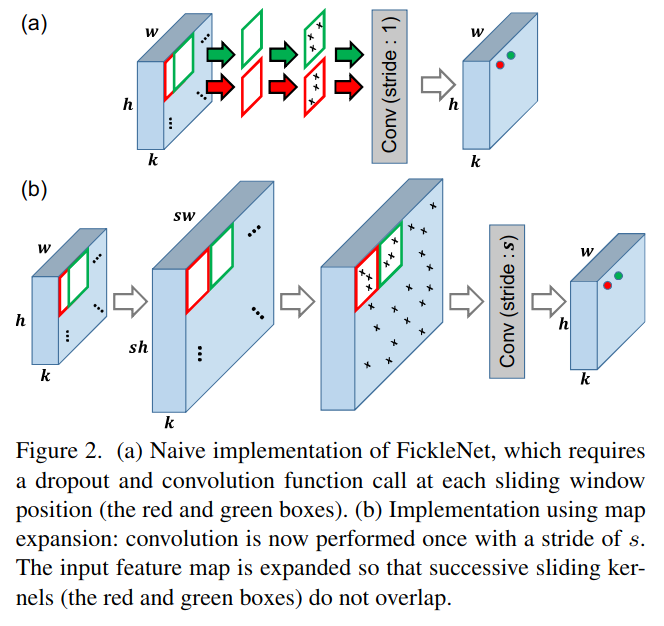
FickleNet采用随机隐藏单元选择的方法,通过对随机选择的隐藏单元对儿计算出的分类分值进行挖掘,发现对象的各部分之间的关系,目的是将对象的非判别部分与同一对象的判别部分联系起来。这个过程是通过在每个滑动窗口位置对特征 x 应用空间dropout实现的,如图2(a)所示。
这与标准的dropout技术不同,标准的dropout技术在每次向前传递时只对特征图中的隐藏单元进行一次采样,因此没有采样的隐藏单元不能对分类得分做出贡献。我们的方法在每个滑动窗口位置采样隐藏单元,这意味着隐藏单元可能在某些窗口位置被激活,而在其他位置被丢弃。
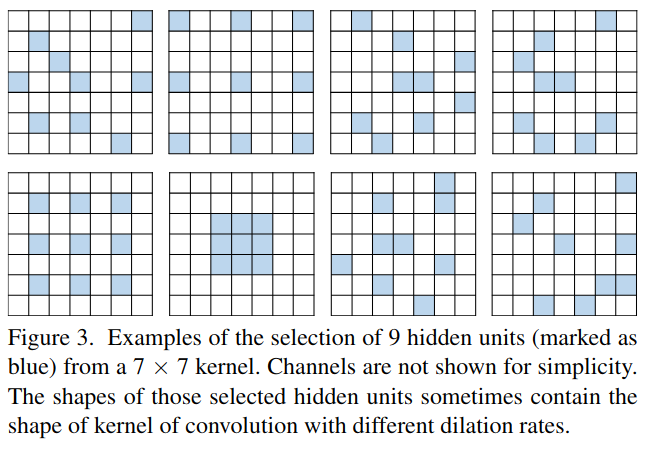
这种选择隐藏单元的方法可以生成许多不同形状和大小的感受野,如图3所示。其中一些场可能与标准的膨胀卷积产生的感受野相似. 因此,该技术产生的结果可以预期包含标准膨胀卷积在不同速率下产生的结果。这个选择过程可以通过提出的扩展技术和保留中心的dropout方法简单有效地实现。
Feature Map Expansion
由于我们的方法需要在每个滑动窗口位置采样新的组合,我们不能直接利用流行的深度学习框架如PyTorch提供的cuda级优化卷积函数。如果我们天真地实现我们的方法,如图2(a)所示,我们将不得不调用卷积函数和dropout函数在每一次向前传递的wxh次。
这里存在的问题主要是因为滑动窗口重叠带来的. 但是有需要保留与原始相同的分辨率, 所以这里使用了特征图扩展的方式. 通过扩展特征图,我们将其缩减为在每次前向传播过程中对每个函数的一次调用。
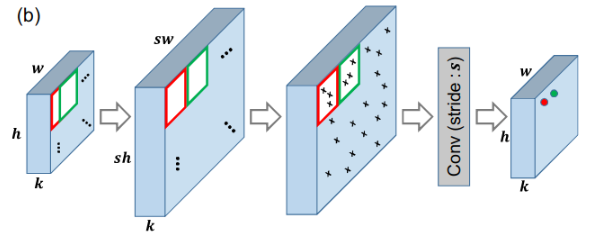
图2(b)显示了我们如何展开输入特征映射,以避免滑动窗口位置重叠。
- 在展开特征图,我们在x上应用零填充,这样最终输出的大小就等于输入的大小。补零后的特征图大小为kx(h+s-1)(w+s-1),其中s为卷积核的大小(w方向或者h方向, 需要补充的部分实际上就是卷积核大小减去1的值)。
- 我们展开零填充的特征图,这样连续的滑动窗口位置就不会重叠,并且展开的特征图 x^expand的大小为kx(sh)x(sw)(相当于在每个wxh平面上的元素都对应着一个sxs大小的映射区域)。
- 然后,我们使用保留中心的dropout技术来选择x^expand上的隐藏单元。虽然扩展后的特征图需要更多的GPU内存,但是需要训练的参数数量保持不变(因为还是那些卷积权重, 只是跨步大了些),GPU的负载没有明显增加,
Center-preserving Spatial Dropout
将dropout应用于空间位置,实现了随机隐藏单元的选择。我们可以通过仅将dropout应用于展开的feature map x一次来实现与原始实现相同的结果。注意,dropout在所有通道上都是一致应用的。
我们会保留每个滑动窗口位置中心的元素,这样就可以找到卷积核中心与每个步骤中的其他位置之间的关系。
当空间丢失率为p时,我们将修改后的特征图表示为 。
。
虽然dropout通常只在训练中使用,但我们将其应用于训练和推理。
Classifier
为了得到分类分数:
- 对dropout处理过的特征图用大小为s和步长为s的核进行卷积。
- 然后我们得到一个大小为cxwxh的输出特征图,其中c是对象类的数量。
- 将全局平均池化(会获得一个长为c的向量)和一个sigmoid函数应用到特征图上,得到一个分类得分s(1xc).
- 然后使用sigmoid交叉熵损失函数更新FickleNet,该函数广泛用于多标签分类。
(这里使用的应该是softmax)
Inference Localization Map
我们现在可以从一张图像中获得不同的分类分数,它对应于随机选择的隐藏单元组合,每一次随机选择都会生成不同的定位图。
如何从每个随机选择中获得一个定位图
我们使用基于梯度的CAM(Grad-CAM),它是类激活图(CAM)的泛化,来获得定位图。 Grad-CAM发现每个隐藏单元对梯度流的分类分数的类特定贡献。
我们计算目标类别得分相对于x的渐变,x是扩展前的特征图,然后沿着通道轴对特征图求和,并按这些梯度加权。 我们可以为每个目标类c如下表达Grad-CAM:
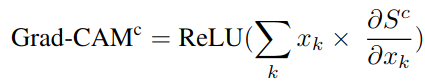
这里的xk表示特征图x的第k个通道. 大小为hxw, 而Sc是分类c的类别得分.
这里实际上计算的是, x特征图上各个通道对于最终分类c得分贡献程度作为权重, 对各个通道进行加权, 计算最终的定位图.
如何将随机选择的图聚合为一个单一的定位图
FickleNet允许从单个图像构建许多定位图,因为隐藏单元的不同组合用于计算每个随机选择的分类分数。 我们从单个图像构建N个不同的定位图并将它们聚合成单个定位图。
- 令Mi表示由第i个随机选择构造的定位图, 我们聚合N个定位图,以便如果在任何M[i]中的类别c的激活分数高于阈值theta,则聚合图中位于u的像素被分配给类别c。
- 在训练期间忽略未分配给任何类的像素。
- 如果有一个像素分配给多个类,我们将在N个图上平均的图中检查其类别分数,并将该像素分配给平均图中具有最高分数的类。
Training the Segmentation Network
定位图提供了伪标签, 以训练一个精确的图像分割网络。我们使用与DSRG相同的背景线索。我们将生成的定位图从FickleNet提供给DSRG,作为弱监督分割的种子线索。
对于半监督学习,我们引入了一个从人完全注释的数据中得到的附加损失. 让C表示图像中存在的一组类。我们训练具有以下损失函数的分割网络:

其中L种子和L边界分别是DSRG[Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing]中使用的平衡种子损失和边界损失,和
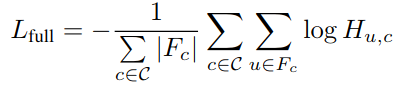
其中H_ {u, c}是在分割图H中在位置u处类别c的概率,并且Fc是真值Mask。
实验相关
网络详细信息:FickleNet基于VGG-16网络,使用Imagenet数据集进行预训练。 通过去除所有完全连接的层和最后的池层来修改VCG-16网络,并且用扩散的卷积以2的扩张率替换最后卷积块的卷积层。我们将卷积核大小s和dropout率p分别设置为9和0.9。DSRG基于Deeplab-CRF-LargeFOV以用来执行分割。
实验细节:我们使用小批量大小训练FickleNet为10.我们在随机位置将训练图像裁剪为321x 321像素,使得特征图x的大小变为512x 41x 41.初始学习率设置为0.001并且每10个时期减半。 我们使用Adam优化器及其默认设置。在微调训练期间,我们使用与DSRG相同的设置。 我们将每个图像的不同定位图数量N设置为200,将阈值beta设置为0.35。 我们在半监督学习中设置alpha为2。
总结
我们仅使用图像级注释解决了语义图像分割的问题。通过在训练和推理期间随机选择特征,我们从单个图像中获得许多不同的定位图,然后将这些图聚合成单个定位图。该图包含与对象的部分相对应的区域,这些区域比由等效的确定性技术生成的图上的目标的部分更大且更一致。
我们的方法可以通过扩展特征图来使用GPU上容易获得的操作来有效地实现,以避免在卷积期间使用的滑动核心之间的重叠。
我们证明了FickleNet在弱监督和半监督分割上产生的结果优于其他最先进的方法产生的结果。
新的名词
- A class activation map (CAM)
- 类激活图(CAM)[37]是对图像级注释中的像素进行分类的良好起点。
- CAM可以发现神经网络中每个隐藏单元对分类分数的贡献,从而识别出贡献较大的隐藏单元。
- 然而,CAM往往只关注目标对象的小识别区域,不适合训练语义分割网络。
- 最近引入的弱监督方法扩展了CAM的激活区域,对图像进行操作,对特征进行操作,或者对CAM发现的区域进行增长。

若有收获,就点个赞吧
0 人点赞
