
简单介绍
本文与上一篇Ranking on Data Manifolds关系密切,可以说这篇文章的内容包含了流行排序的情况。
我们考虑从有标记和未标记数据中学习的一般问题,这通常被称为半监督学习或转换学习(transductive inference)。半监督学习的原则方法是设计一种分类函数,该函数相对于由已知标记点和未标记点共同揭示的内在结构而言是足够平滑(smooth)的(贴合所有数据的共同内在结构)。我们提出了一种简单的算法来获得这样一个平滑的解(smooth solution)。我们的方法在许多分类问题上产生了令人鼓舞的实验结果,并证明了对于未标记数据的有效使用。
这里考虑一个半监督学习问题:
给出一个点集X,一共有n个点,第i个点表示为xi,其中,前l个点是有标记的数据,它们的标记会对应一个标量类别标记,一共有c类标记,其余的点都是无标记的数据。 最终的目的是为了对这些无标记数据进行预测。 算法性能通过这些无标记点的预测的错误率来进行衡量。
这种学习问题通常被称为半监督或转换学习问题。由于数据标记通常需要昂贵的人工成本,而未标记的数据更容易获得,半监督学习在许多现实问题中非常有用,并且最近吸引了大量的研究。典型的应用程序是Web页面分类,其中手动分类的Web页面始终是整个Web的一小部分,未标记的样本数量很大。
半监督学习问题的关键是一致性先验假设,这意味着:
- 邻近的点可能具有相同的标签
- 相同结构上的点(通常称为簇或流形)可能具有相同的标签
这个论点类似于[Semi-supervised learning on manifolds, Learning from labeled and unlabeled data using graph mincuts, f. Cluster kernels for semi-supervised learning, Learning with labeled and unlabeled data, Semi-supervised learning using gaussian yields and harmonic functions]中的论证,通常称为集群假设(cluster assumption)[Cluster kernels for semi-supervised learning, Learning with labeled and unlabeled data]。 注意第一个假设是局部的,而第二个假设是全局的。正统的监督学习算法,例如k-NN,通常仅取决于局部一致性,也就是第一个假设。
正统的监督学习方法,例如knn,通常只依赖于第一个假设,也就是局部的假设:相邻的点更可能有着相同的标签。
但是对于第二个假设:属于相同结构的点也应该有着相同的标签的情况没有考虑。
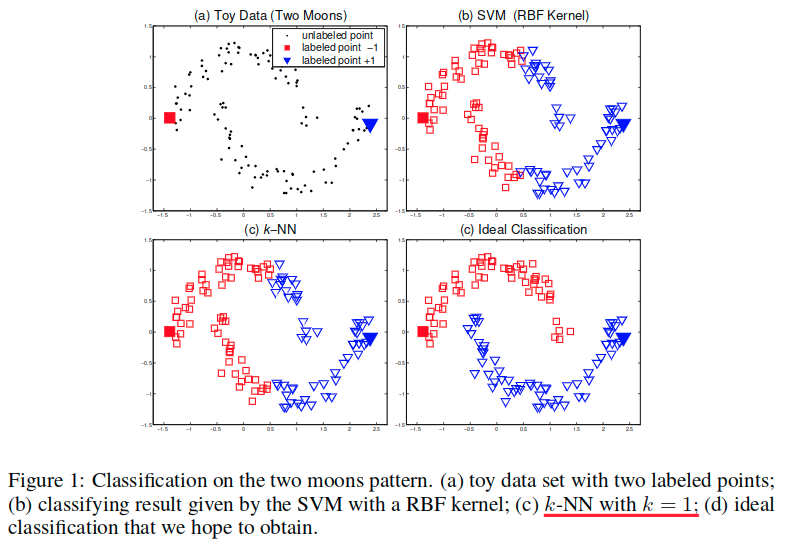
这里是使用了一个和Ranking on Data Manifolds中相同的问题。各种半监督学习算法,如谱方法,随机游走,graph minicut和 transductive SVM 之间的主要区别在于它们实现一致性假设的方式。
一种形式化假设的原则性的方法是设计一种分类函数,该函数相对于已知标记和未标记点所揭示的内在结构而言是足够平滑的。在这里,我们提出了一个简单的迭代算法来构建这样一个平滑的函数,其灵感来自于扩散激活网络和扩散核的工作,以及最近关于半监督学习和聚类的工作,更具体地说是Zhu等人的工作[Semi-supervised learning using gaussian yields and harmonic functions]。我们方法的关键点是让每个点迭代地将其标记信息传播给它的邻居,直到达到全局稳定状态。
算法细节
给定点集X,其中包含n个点,第i个点表示为xi,都是m维的矢量。对应有一个部分标记集合L,是一个有着c个元素的集合(对应c个类别),对于X中的前l个点中的点xi,都对应有一个标记yi(属于集合L)(是个标量,指示类别),X中剩下的点是没有标记的。最终的目标就是预测未标记点的标记。
首先定义几个变量:F是一个nxc的矩阵,其中包含n个c维的矢量,对应着所有的n个点的标记矢量。其中对于点xi,有标记yi满足: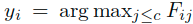 ,表示对于xi的最终标记yi实际上是F中第i行数据中的最大得分的索引。这里可以讲F看作是对各点针对各个类别的得分情况的统计。也可以将F理解为一个从点集X映射到一个c维的矢量的映射关系,这里对于每个矢量Fi都被赋给xi。另外有一个nxc指示矩阵Y,对于有标记(yj=1)数据xi则对应于Yij=1,其他情况被设置为0。Y实际上表示的就是数据点与类别之间的关联关系。可以清楚地是,Y和根据决策规则确定的初始标记是一致的。
,表示对于xi的最终标记yi实际上是F中第i行数据中的最大得分的索引。这里可以讲F看作是对各点针对各个类别的得分情况的统计。也可以将F理解为一个从点集X映射到一个c维的矢量的映射关系,这里对于每个矢量Fi都被赋给xi。另外有一个nxc指示矩阵Y,对于有标记(yj=1)数据xi则对应于Yij=1,其他情况被设置为0。Y实际上表示的就是数据点与类别之间的关联关系。可以清楚地是,Y和根据决策规则确定的初始标记是一致的。
算法流程:
- 通过高斯核函数定义关联矩阵W,其中的项可以表示为:
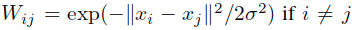 ,
,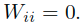 。
。 - 构造对称归一化处理W后的矩阵S:
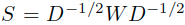 ,这里的D矩阵是度矩阵,其中的ii项是W的第i行的和。
,这里的D矩阵是度矩阵,其中的ii项是W的第i行的和。 - 迭代公式:
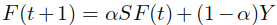 直到收敛,这里的alpha是一个(0,1)之间的参数。
直到收敛,这里的alpha是一个(0,1)之间的参数。 - 使用
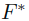 表示
表示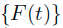 序列的极限,点xi的标记可以记为yi:
序列的极限,点xi的标记可以记为yi: ,也就是最终的
,也就是最终的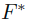 对应于第i行中最大值的索引类别。
对应于第i行中最大值的索引类别。
根据实验心理学中的传播激活网络,可以直观地理解该算法。
- 我们首先在数据集X上定义成对关系W,对角元素为零。我们可以认为图G =(V; E)是在X上定义的,其中顶点集V仅为X而边E由W加权。
- 在第二步中,G的权重矩阵W被对称归一化,这是后续迭代收敛所必需的。
- 前两个步骤与谱聚类[9]完全相同。在第三步的每次迭代期间,每个点从其邻居(第一项)接收信息,并且还保留其初始信息(第二项)。该参数指定来自其邻居的信息的相对量及其初始标签信息。
- 值得一提的是,由于在第一步中将关联矩阵的对角元素设置为零,因此避免了自增强(self-reinforcement)。此外,由于S是对称矩阵,因此信息对称地扩展。
- 最后,每个未标记点的标签被设置为在迭代过程中它已收到大部分信息的类(得分最高的类别)。
这里首先证明序列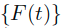 是收敛的,并且收敛于结果:
是收敛的,并且收敛于结果: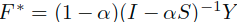 。
。
Without loss of generality(不失一般性),假设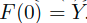 。通过迭代
。通过迭代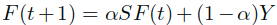
可以得到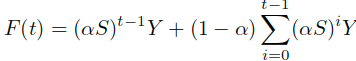
这里的alpha是(0, 1)的常数,S的特征值位于[-1, 1]之间,这里的相似于随机矩阵P。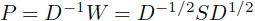
在t取极限的时候,可以得到下面式子: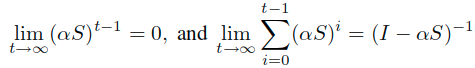
第一项容易理解:由于S的特征值在[-1, 1]之间,由于其幂指数是由特征向量和特征值对角矩阵的对应幂指数构成。
可见:
由此可知第一个极限式子是趋于0的。
关于第二项如何推导暂时没有思路。
进一步转化为: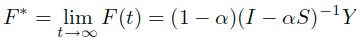
对于分类任务,前面的放缩参数不会影响最终的结果,所以可以忽略:
这里就可以得到收敛结果了。
进一步考虑其变体,若是对于上述结果进一步迭代,可以得到如下的变体: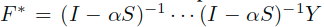
另一种,由于S和P是相似的,所以替换表示为: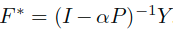
同样的也可以替换为: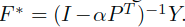
这个可以等价为: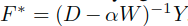
虽然具体的值可能不同最终索引应该是一致的。
正则化框架
这里为上述迭代算法设置了一个正则化框架,损失函数可以表示为: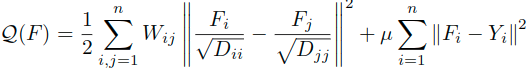
这里的μ是大于0的数正则化参数,分类函数可以表示为: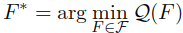
- 对于第一项的平滑约束,实际上就是要保证在相邻点之间不会有太大的变化。所以这里使用的是权重矩阵W对不同边加权下,各相连接的点(i,j)之间的归一化差值。
- 第二项的拟合约束,要保证在最终的分类结果不会导致与原始赋值太大的差异。 所以这里使用的是最终分类与原始的类别设定的差值平方和。
- 这里的μ就是对于两个约束的一个权衡参数。注意这里的拟合约束包含所有数据,包括没有标记的和有标记的。
我们可以将平滑项理解为局部变化的总和,即邻近点之间的函数的局部变化。正如我们已经提到的,涉及成对关系的点可以被认为是无向加权图,其权重表示成对关系。然后实际上在每个边上测量局部变化。我们不是简单地通过边缘两端的函数值的差异来定义边缘上的局部变化。平滑项本质上,是在计算局部变化之前,在沿着附着于其上的边的每个点上,分离函数值,并且赋给每个边的值与其权重成正比(乘以了Wij)。
这里让Q关于F求偏导数:
可以进一步合并移项转换为:
引入两个变量:
所以这里可以表示为:
由于这里的 可逆,所以调整式子为:
可逆,所以调整式子为:
这里也就得到了上述迭代算法的闭式解。相似的,同样可以得到对应于其他变体的优化框架。
实验效果
这里使用k-NN和one-vs-rest SVMs作为基线,比较提出的方法的两个变体: 和
和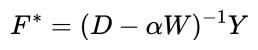 。我们还比较了Zhu等人的使用的谐波高斯场方法和类质量归一化(Class Mass Normalization,CMN)方法,它与我们的方法密切相关。据我们所知,如果只有很少的标记点可用,则没有可靠的模型选择方法。因此,我们让所有算法都使用它们各自的最佳参数,除了我们的方法及其变体中使用的参数alpha只是固定在0.99。
。我们还比较了Zhu等人的使用的谐波高斯场方法和类质量归一化(Class Mass Normalization,CMN)方法,它与我们的方法密切相关。据我们所知,如果只有很少的标记点可用,则没有可靠的模型选择方法。因此,我们让所有算法都使用它们各自的最佳参数,除了我们的方法及其变体中使用的参数alpha只是固定在0.99。
文章考虑了三个实验,这里分别介绍。
Toy Problem
这里考虑开头提出的问题。对此,使用的关联矩阵通过一个径向基函数核来定义,而其对角元素被设置为0。迭代算法的收敛过程(t=1=>400)展示在图2中。
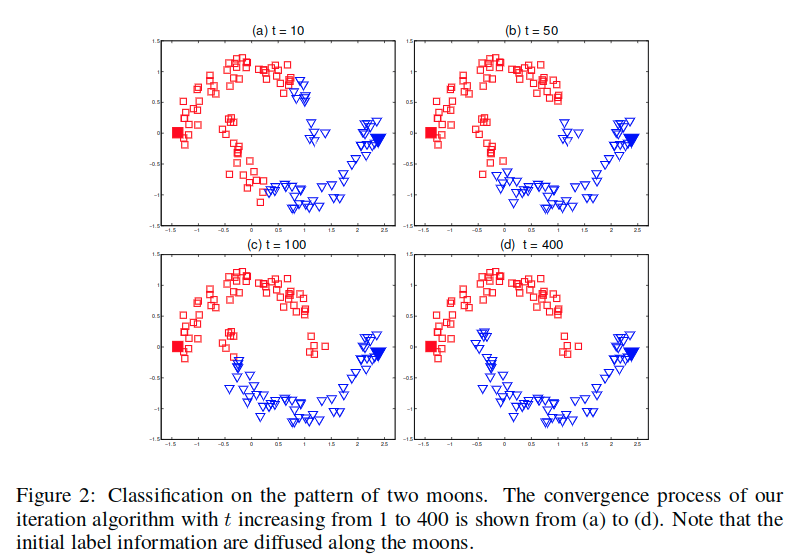
注意,初始标签信息沿着月形结构逐渐传播。一致性假设本质上意味着良好的分类函数应该在由大量数据聚合的相关结构上缓慢变化。这可以被这个问题直观的展示出来。
这里定义一个函数:
使用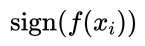 作为决策函数,这里等价于前面提到的决策规则。
作为决策函数,这里等价于前面提到的决策规则。
在图3中,显示了随着t的增长,逐渐在两个月形模式中趋于平坦,最终得到了一个清晰的月形结构。
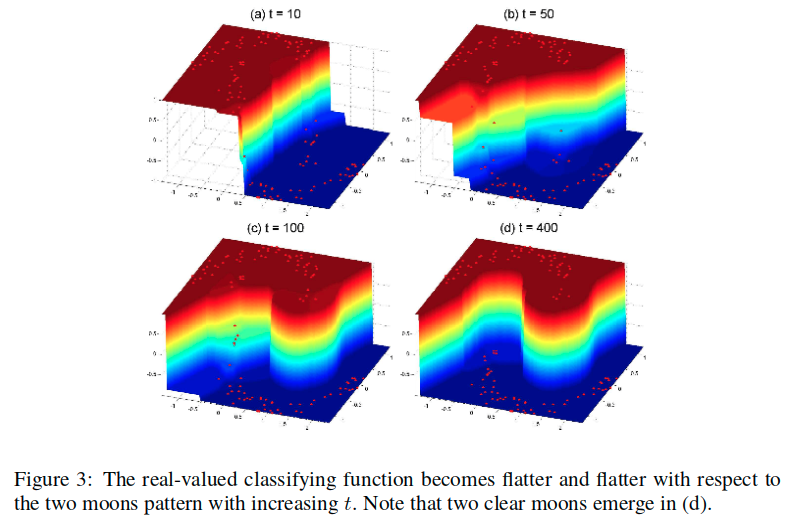
我们方法的基本思想是构造一个平滑函数。很自然地考虑,使用这种方法来通过平滑其分类结果以改进有监督的分类器。换句话说,我们使用有监督分类器给出的分类结果作为我们算法的输入。
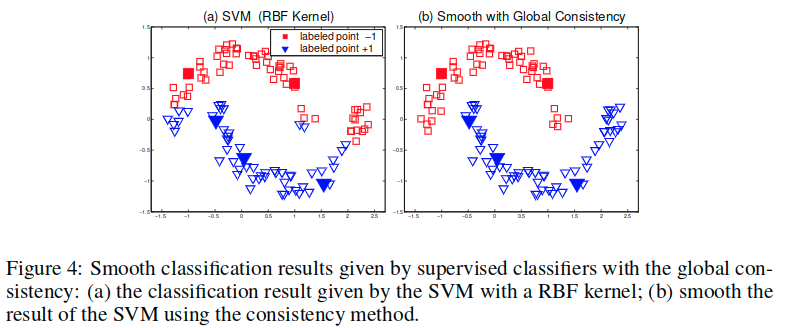
图4中的问题证明了这个猜想。图4a是用RBF核的SVM给出的分类结果。然后在我们的方法中将该结果分配给Y(作为初始分数)。我们方法的输出如图4b所示。请注意,SVM错误分类的点可通过一致性方法成功进行平滑处理。
数字识别
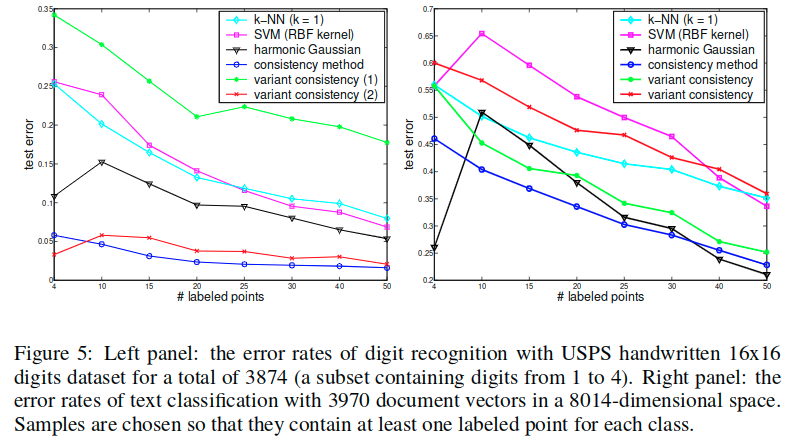
在本实验中,我们使用USPS手写数字数据集的16x16图片数据解决了分类任务。我们在实验中使用数字1,2,3和4作为四类。每个类有1269,929,824和852个示例,总共3874个。
- k-NN中的k设置为1。
- SVM的RBF内核的宽度设置为5。
- 并且对谐波高斯场方法设定为1.25。
- 在我们的方法及其变体中,关联矩阵由RBF核构建,其宽度与谐波高斯方法相同,但对角元素设置为0。
平均超过100次试验的测试误差总结在图5的左面板(panel),选择样本使得它们每个类别包含至少一个标记点。我们的一致性方法及其变体之一明显优于正统监督学习算法k-NN和SVM,并且也优于谐波高斯方法。
注意,我们的方法不要求关联矩阵W是正定的。这使我们能够以优雅(elegant)的方式结合关于数字图像不变性的先验知识,例如,通过使用抖动核(jittered kernel)来计算关联矩阵。 其他的核方法也有类似的问题。在我们的例子中,抖动1像素的转换导致的30个标记点的错误率约为0.01。
文本分类
在这个实验中,我们使用20-newsgroups数据集调查了文本分类的任务。我们从20-news-18828版本的数据中选择了包含汽车、摩托车、棒球和曲棍球的主题rec。
这些文章由Rainbow软件包处理,具有以下设置:
- 在计数之前将所有单词通过Porter stemmer
- 丢弃SMART系统停词列表(stoplist)中的任何令牌(token)
- 跳过任何标题
- 忽略在5个或更少的文档中出现的单词
没有进行进一步的预处理。删除空文档,我们在8014维空间中获得了3970个文档向量。最后,文档被归一化为TFIDF表示。
对于点xi和xj之间的距离可以定义为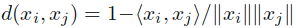 。k-NN算法中的k设置为1,SVM的RBF的宽度设置为1.5,并且对于谐波高斯方法,设置为0.15。
。k-NN算法中的k设置为1,SVM的RBF的宽度设置为1.5,并且对于谐波高斯方法,设置为0.15。
在我们的方法中,关联矩阵由RBF核构建,其宽度与在谐波高斯方法中相同,但对角元素设置为0。平均超过100次试验的测试误差总结在图5的右侧面板中。选择样本,使其每个类别至少包含一个标记点。
值得注意的是,当标记点的数量为4时,谐波方法非常好,即每个类别的一个标记点。我们认为这是因为数据集中的不同类别的比例几乎相等,因此对于四个标记点,恰好会对比例进行精确估计。然而,如果使用稍微更多的标记点,则谐波方法变得更糟,例如,10个标记点,这导致相当差的估计。随着标记点的数量进一步增加,谐波方法再次运行良好,并且比我们的方法稍好,因为类的比例再次成功估计。然而,我们的决策规则更简单,这实际上对应于所谓的朴素阈值(naive threshold),即谐波方法的基线。
总结
半监督学习问题的关键是一致性假设,它基本上要求分类函数相对于由大量标记和未标记点揭示的内在结构而言足够平滑。我们提出了一种简单的算法来获得这样的解决方案,该算法证明了在实验中有效使用未标记的数据,包括toy data,数字识别和文本分类。在我们的进一步研究中,我们将专注于模型选择和理论分析。
补充信息
20newsgroups
数据集是用于文本分类、文本挖据和信息检索研究的国际标准数据集之一。数据集收集了大约20,000左右的新闻组文档,均匀分为20个不同主题的新闻组集合。一些新闻组的主题特别相似,还有一些却完全不相关。
- 链接:https://blog.csdn.net/imstudying/article/details/77876159#OLE_LINK2
- 介绍:https://blog.csdn.net/imstudying/article/details/77876159
TF-IDF
是Term Frequency-Inverse Document Frequency的缩写,是一种非常常见的算法,可将文本转换为有意义的数字表示。该技术被广泛用于跨各种NLP应用程序提取功能。
是一种用于信息检索与文本挖掘的常用加权技术。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了tf-idf以外,互联网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜索结果中出现的顺序。

若有收获,就点个赞吧
0 人点赞
