
本文是作者在11CVPR, 15PAMI上的作品, 但是阅读是基于11年的版本, 本文结合了15年的一些改动,
自动估计的突出目标区域的图像,没有任何预先假设或知识的内容,相应的场景,提高了许多计算机视觉和计算机图形应用。
文章提出了一种基于区域对比度的显著目标检测算法,该算法能同时评估全局对比度差异和空间加权相干性得分。该算法简单、高效、自然多尺度,生成高质量的全分辨率显著性图。
提出了基于全局对比度的显著性计算方法,即基于直方图的对比度计算方法(HC)和基于空间信息增强区域的对比度计算方法(RC)。虽然HC方法速度快,生成的结果非常详细,但RC方法生成的是空间连贯的高质量显著性图,代价是降低了计算效率。
在提出的显著性检测方法的基础上,我们引入了一种新的unsupervised分割算法,即 SaliencyCut ,自动分割图像中最显著的目标,而不需要昂贵的训练数据。 这些显著性映射进一步用于初始化一个新的迭代版本的**GrabCut**,即**SaliencyCut**
这里可以考虑在深度学习的显著性目标检测的最后, 使用该方法来处理预测出来的概率图, 来获得更好的分割结果.
我们广泛地评估我们的算法使用传统的突出目标检测数据集,以及更具挑战性的互联网图像数据集。
- 我们的实验结果表明,我们的算法始终优于现有的15种突出目标检测和分割方法,具有更高的准确率和更好的召回率。
- 我们也证明了我们的算法可以有效地从网络图像中提取出显著的目标掩码,使得基于草图的图像检索(SBIR)通过简单的形状比较变得有效。
- 尽管网络图像存在噪声,且显著性区域存在模糊性,但我们的显著性引导图像检索与目前最先进的SBIR方法相比,具有较高的检索率,并且提供了重要的目标对象区域信息.
- 虽然我们的显著性检测和分割方法不能保证对单个图像的鲁棒性,但是它们的效率和简单性使得自动处理大量的图像成为可能,这些图像可以被进一步过滤以获得可靠性和准确性
论文内容
文章主要依据图像的对比度来进行自底向上, 数据驱动的显著性检测.
文章提出了基于直方图对比度的方法来进行检测显著性. HC方法, 主要依据与其他像素的色彩差异来分配像素的显著性值, 并用以产生全分辨率显著性图像. 这里使用基于直方图的方法来进行高效处理, 并使用色彩空间的平滑操作来控制量化的缺陷.
作为HC方法的提升, RC方法融合了空间相关性. 先将输入图像分割为小的区域, 然后分配显著性值. 区域的显著性值使用全局对比度得分来计算, 通过区域对比度和到图像上其他区域的空间距离来测量.
我们提出了一种改进的迭代式 GrabCut 算法 SaliencyCut ,并将其与我们的显著性检测方法相结合,实现了优于目前最先进的无监督显著性目标提取方法的性能。
HC方法-基于直方图统计的对比度
基于输入图像的颜色统计特征提出了基于直方图对比度的图像像素显著性值检测方法.
具体而言, 一个像素的显著性值用它和图像中的各其他像素颜色的对比度来定义. 对于图像I中的像素Ik的显著性值定义为:

上面的式子缺少空间关系, 会使得具有相同颜色的像素产生相同的显著性值, 这里调整了式子的计算, 使得具有相同颜色值得像素归到一起, 进而得到每个颜色的显著性值:

这里计算的还是颜色距离, 但是变量从像素变成了颜色值, 是对于图像中所有的颜色值进行按照概率加权累加颜色距离.
上面的式子缺少空间关系, 会使得具有相同颜色的像素产生相同的显著性值,.
(对于结构较为复杂, 背景颜色中存在与目标颜色较为接近的情况, 会导致错误.)这样的理解似乎不符合这里的语境, 这里如此重排, 并不是为了解决这个问题. 也没有在这里把这个结果看成一个问题, 而是基于这个结果, 重新转化了式子, 使其表示的更为直接.
基于直方图的加速
这里使用了颜色的量化来降低计算量, 提高速度. 为了降低需要考虑的颜色数量, 先量化每个颜色通道为12个值, 使得颜色数量降低到12x12x12=1728.
考虑到自然图像实际上只是覆盖了部分的全色彩空间的色彩, 通过选择频率最高的颜色, 并且确保这些颜色覆盖95%以上的像素, 这样可以将颜色数目减少到n=85左右. 剩下的小于5%的像素所占的颜色被直方图中对应色彩空间距离最近的颜色所代替.
颜色空间平滑
但是由于颜色亮化本身可能会产生一些小问题, 一些相似的颜色可能被量化为不同的值, 为了减少这种随机性给显著性值计算带来的噪声, 使用平滑操作来改善每个颜色的显著性值. 每个颜色的显著性值被替换为Lab*空间距离测量相似的颜色的显著性值的加权平均.
这个实际上是颜色空间的一种平滑过程. 选择m=n/4个最邻近颜色来改善颜色c的显著性值:

为了平滑, 每个颜色的显著性值替换为相似颜色显著性值的加权平均(这里想到了11年论文中计算先验概率的时候, 使用的是与其他超像素之间的对比度倒数计算的显著性值的均值来作为自身到自身的一个显著性值).
该公式中的S也在累和符号运算范围内. 对于T-D部分, 其自身的i的迭代累加结果实际上是(m-1)T, 也就是第二行式所述, T中的各项都出现了(m-1)次, 所以会导致最终由(m-1)个T. 所以使用该项配合前面的分数项, 实现了一个归一化因数.
这里使用了一个线性变化平滑权值, 而非高斯权值, 实验效果要比急剧下降的高斯权值效果好.
可以实现色彩特征空间距离c较近的颜色, D会偏小, 因而分数权重会偏大, 也就是颜色改变会被分配较大的权值.

颜色空间平滑后, 按照显著性值将序排列, 可以看到相似的直方图区间在平滑后会非常接近, 相似的颜色非常可能分配到相似的显著性值, 因此减少了量化的瑕疵.
注意
为了将颜色空间量化为12x12x12种颜色, 统一将每个颜色通道划分为12级.
在RGB颜色空间量化, 更为接近真实色彩情况, 因为在Lab色彩空间中, 并不是所有的颜色都对应于真实的颜色, 而计算颜色的**距离, 则是在更为接近人类感知的Lab色彩空间进行度量**.
RC方法-基于区域的对比度方法
人们会更加关注图像中和周围对比度相差较大的二区域, 除了对比度, 空间关系也在人类注意力方面起到很大的作用, 相邻区域的高对比度比起远区域的高对比度更容易导致一个区域引起视觉注意力. 在计算像素级对比度时引入空间关系计算代价会非常大, 这里引入了RC方法, 来讲空间关系和区域级对比度计算结合到一起.
此方法中:
- 先得将图像分割成若干区域
- 然后计算区域及颜色对比度
- 再用每个区域与其他区域对比度加权和来为此区域定义显著性值. 权值由区域空间距离决定, 较远的区域分配较小的权值.
用稀疏直方图比较来计算区域对比度

[11]: P. Felzenszwalb and D. Huttenlocher, “Efficient graph-based image segmentation,” IJCV, vol. 59, no. 2, pp. 167–181, 2004.
区域颜色距离定义为: 两个区域中各有n1&n2种颜色, 通过各区域中对应于第i&j种颜色的出现频率, 以及两种颜色的lab空间距离, 来累加得到整体的两个区域的颜色距离. 两个色彩出现的概率是各自独立的, 所以总体出现的情况是概率的相乘.
其中, 上式里的 表示第i个颜色
表示第i个颜色 在第k个区域
在第k个区域 的所有
的所有 种颜色中出现的概率, k={1, 2}. 注意到使用区域的概率密度函数(即归一化的颜色直方图)中颜色出现概率作为权值,以强调主要的颜色之间的区别。
种颜色中出现的概率, k={1, 2}. 注意到使用区域的概率密度函数(即归一化的颜色直方图)中颜色出现概率作为权值,以强调主要的颜色之间的区别。
空间加权区域对比度
更进一步, 基于此, 配合区域的空间距离作为权重, 以及控制这个空间权重的参数σ, 和对应于区域的权重w, 可以得到 基于空间加权区域对比度的显著性值:

[35]: H. Jiang, J. Wang, Z. Yuan, T. Liu, N. Zheng, and S. Li, “Automatic salient object segmentation based on context and shape prior,” in BMVC, 2011, pp. 1–12.
这里与11年cvpr论文有所不同:
这里多了一项空间先验加权项, 类似于一个中心偏置的作用. 当该区域里图像中心越远, 则该权重却小.
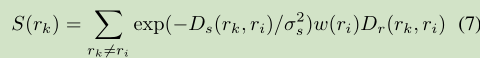
通过两个步骤进一步细化RC显著性映射:
- 首先,我们使用空间先验显式估计非显著性区域(背景)
- 其次,我们应用颜色空间平滑(如前HC小节的内容)
我们观察到与图像边界重叠的长边界区域是典型的非显著背景区域,我们称之为边界区域。
我们将它们合并为另一个空间先验(式子7中的 )来检测非显著区域。在我们的实现中,我们按照区域大小对位于15个像素宽的图像边界区域的像素数量进行规范化,并将该值高于阈值的区域视为边界区域。在实践中,这种硬约束通过改善初始条件, 改进了显著性图和
)来检测非显著区域。在我们的实现中,我们按照区域大小对位于15个像素宽的图像边界区域的像素数量进行规范化,并将该值高于阈值的区域视为边界区域。在实践中,这种硬约束通过改善初始条件, 改进了显著性图和 SaliencyCut 的收敛速度. 我们的边界区域估计以高精度为目标,而不是高召回。一个严格固定的阈值,在我们数据集上平均对应于2%的漏报率, 用于检测边缘区域.
为了均匀高亮整体显著性区域,我们得到每个颜色在颜色直方图中的平均显著性, 并且采用颜色空间平滑以改善的RC显著性图。平滑后,一些边缘区域像素可能得到非零显著值。我们将边缘区域的显著性重置为零,并将每个区域的显著性重新估计为其对应像素的平均显著性值。
由于初始RC图通常比没有颜色空间平滑的HC显著性映射更均匀地高亮,因此我们通常选择较少的近似颜色(在本部分中m=n/10)。图5(f)展示了这样一个例子。与图5(e)相比,跳跃人区域的高亮更加均匀。

SaliencCut-自动显著性区域提取

考虑将计算所得的显著性图像用于帮助显著物体分割。
在已有的工作中,显著性图已经被用于非监督物体分割:
- Ma和Zhang[21]通过在显著性图上进行模糊区域增长来找到矩形显著的区域。
- Ko和Nam[18]在图像线段特征上训练支持向量机,然后将这些区域聚类来提取显著性物体。
- Han等人[13]用颜色、纹理和边缘特征建立马尔可夫随机场模型,用显著性图的种子值来增长显著性物体区域。
- 最近,Achanta等人[2]先通过mean-shift分割得到图像区域,然后再图像区域内对显著性值进行平均,再通过识别平均显著性值大于整个图像平均显著性值的2倍的图像区域来确定显著性区域。
在文章的方法中,迭代应用GrabCut[24]来改善二值化显著性图像后得到的分割结果(见图6). 传统的GrabCut方法是由人工选中矩形区域来进行初始化操作,而这里用一个固定阈值二值化后的显著性图来得到显著性分割,并用这个显著性分割来自动地进行GrabCut初始化。
使用固定阈值二值化得到的显著性图分割, 初始化分割算法, 对于显著性值高于这个固定阈值的部分认为是未知的, 而低于则认为是背景区域. 注意这里并没有标记前景, 这是要在后续的迭代中不断约束细化的. 未知区域初始用来训练前景颜色, 来帮助算法识别前景像素.
这个阈值的我们经验性的选择固定阈值实验中与95%召回率对应的阈值。
因为已初始化的背景区域在迭代优化过程中是被维持不变的, 而其他区域被优化逐渐改变, 在三元图中,我们优先使用自信的背景标签。 因此初始化GrabCut算法, 使用的是给定一个有着更高召回率潜在前景区域的阈值.这里的阈值, 我们经验性的选择固定阈值实验中与95%召回率对应的阈值. 召回率高, 对应着划分出来的前景区域中包含着更多的真实前景. 这样的话, 认为是背景的部分基本上更可以被认为是背景. 这个阈值也就是文中使用的70.
初始化之后,我们迭代运行GrabCut来改进显著性分割结果(在我们的实验中最多迭代4次)。在每一次迭代后,我们用膨胀和腐蚀操作来得到新的Trimap以进行下一次迭代。
如图6所示,膨胀区域外的区域设置成背景,腐蚀区域内的区域设定为前景, 其余的区域为Trimap中的未知。
**Grubcut**本身是用高斯混合模型和Grapcut进行迭代,来改善每一步的区域分割效果,靠近初始显著性物体区域的部分成为显著性物体的几率更大。因此,我们的新的初始化方法可以使GrabCut包含显著性区域附近的显著性区域,并根据颜色特征的差异排除非显著性区域。
我们对初始分割进行了迭代优化,并对初始条件进行了自适应调节,以适应新分割的凸形区域。 自适应拟合是基于一项重要的观测结果: 距离初始显著目标区域较近的区域比较远的区域更有可能成为该显著目标的一部分。 在每次GrabCut迭代之后,
SaliencyCut将新获得的trimap所给出的约束条件结合起来,并根据之前的结果训练出一个更好的外观模型。
在算法实现中,我们设置了狭窄的图像边界区域(15像素宽)作为背景来提高边界区域的收敛速度。
与单通道GrabCut或基于显著性分割[48]的更简单的图分割不同,SaliencyCut中的新方案对初始显著性区域进行了迭代细化。这种迭代设计对于处理显著性检测算法(而不是人工注释)提供的噪声初始化非常重要.
这种方法对于初始区域有一定的依赖, 因为初始背景区域会被标记为硬标签. 如果初始化不正确,如图6(b)中的flower示例所示,初始背景区域对前景对象的处理不正确。虽然我们仍然可以使用
GrabCut得到包含花很多部分的分割结果,但是由于背景有一个硬标签(hard labeling),所以使用GrabCut无法正确提取出初始背景区域中剩余的花朵。 可以考虑放松GrabCut的硬约束来解决这个问题。然而,实验结果表明,这将使该方法不稳定,往往产生的结果包含所有前景或所有背景。
总结
在实验比较部分, 作者给出了一个很有意思的结论:
显著性检测方法的真实有效性取决于应用. The true effectiveness of a saliency detection method depends on the applications [R. Achanta, S. Hemami, F. Estrada, and S. S¨ usstrunk, “Frequency-tuned salient region detection,” in IEEE CVPR, 2009.].

我们的方法旨在找出图像中最显著的物体。对于具有多个对象的图像(如图17),它可能产生次优结果,特别是当这些对象相互遮挡时, 对于这些, 即使是专门的对象检测器也不能可靠地为大多数对象类生成良好的结果.
提出一些候选对象区域, 而不是在早期做出艰难的决定, 对于那些需要高检测率的应用, 比如在杂乱的场景中检测对象, 可能是有用的.
未来的工作
We further discuss possible applicationsand extensions by highlighting a few of the many exciting works using the preliminary version of our work:
- The ability to generate high quality saliency maps is essential for many applications including content-aware image manipulation, non-photorealist rendering, image scene analysis, adaptive compression, forgery detection, etc.(内容感知图像处理,非真实感渲染,图像场景分析,自适应压缩,伪造检测)
- Unsupervised segmentation of the entire salient object, without extensive training data annotation, naturally benefits applications like autocropping, scene classification, semantic manipulation, and data-driven image synthesis(自动裁剪、场景分类、语义处理和数据驱动的图像合成).
- A tool to retrieve internet images and get precise object of interest regions is powerful to explore this big data for image composition, semantic colorization, information discovery, image retrieval, etc.(图像合成、语义着色、信息发现、图像检索等)
- The proposed saliency measure has already been used to produce state-of-the-art results on cosegmentation benchmarks without using cosegmentation, or simultaneously analyze multiple images for better salient object extraction.(提出的显著性度量已经被用于在不使用共分割的情况下在共分割基准上产生最先进的结果,或者同时分析多个图像以获得更好的突出目标提取)
参考链接

若有收获,就点个赞吧
0 人点赞
