
主要贡献
- 迭代式的top-down和bottom-up显著性推理过程。
- 每一步中使用卷积版本RNN、LSTM或GRU来构建推理并实现侧输出,配合深监督训练策略。
- 整体可以看作是一个通用的框架,很多的基于FCN的模型可以认为是该模型的变体。
- 参数共享与权重共享的各种改进变体,在损失一定的精度的同时可以降低参数量。
个人想法,这种迭代式的思想与之前的R3Net有些类似,这里对于每一层的特征都使用了深监督,反复结合编码器中的特征信息,而R3Net每一模块里利用残差配合迭代的方式反复结合编码器信息。但是R3Net的迭代结构是固定的残差结构,这里进一步研究了RNN的改进,使得外部迭代之后,进一步在内部也进行迭代,同时还进一步的扩展,探究了结构上的重复利用(共享权重)的情况,走的更远。
网络结构
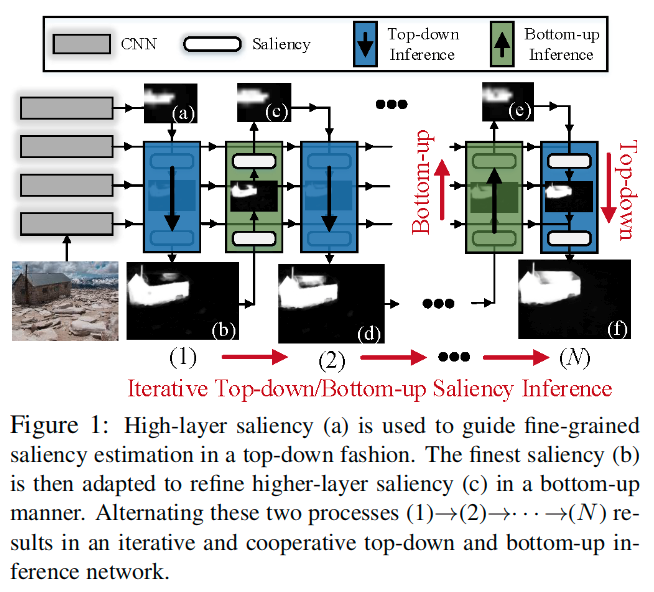
本文方法以迭代和协作的方式整合了自上而下和自下而上的显着性。
- 自上而下的过程用于粗略到精细的显着性估计,其中高层的显着性逐渐与更精细的下层特征集成以获得细粒度结果。
- 自下而上的过程通过逐渐使用上层的语义更丰富的特征来推断高层但粗略的显着性。
- 交替执行这两个过程,其中自下而上过程使用从自上而下过程获得的细粒度显着性来产生增强的高层显着性估计,而自上而下过程又进一步受益于改善了的高层信息。
- 自下而上/自上而下的过程中,网络层具有循环机制,用于分层逐步优化。因此可以有效地鼓励显着性信息以自下而上、自上而下和层内的方式进行流动。
基于全卷积网络(FCN)的大多数其他显着性模型本质上是该模型的变体。对几个著名基准的广泛实验清楚地表明了提出的显着性推理框架的卓越性能、良好的泛化能力和强大的学习能力。
主要动机
- 首先,我们的模型是由心理学和认知社区对人类感知系统的研究所激发的。为了解释人类视觉信息处理,两种类型的感知过程是有区别的:自下而上和自上而下的处理。
- 在自上而下的过程中,高级语义知识或上下文信息指导信息处理。
- 相反,自下而上的过程以相反的方向进行,从刺激到高级视觉理解,每个连续阶段对输入进行更复杂的分析。
- 大多数心理学家现在都认为,自上而下和自下而上的过程都与感知有关。这促使我们以联合和迭代的方式探索两个系统的显着性推断。众所周知,顶层网络层承载语义丰富的信息,而底层涉及低级细节,我们认为顶层显着性是视觉场景的全局和谐解释,用于在自上而下的方式中指导细粒度显着性估计。相反,如果从最好的显着性开始,可以利用它以自下而上的方式改进上层显着性。
- 基于FCN的SOD模型的最新进展是网络设计的第二个灵感。他们的成功归功于他们将粗糙的上层显着性与低级但空间定义的特征逐步整合。因此,最终估计是最精确和最准确的。
- 这促使我们考虑为什么不利用最终的、最好的显着性来通过自下而上的过程反向改进先前的上层估计,然后重复从粗到细、自上而下的过程以获得更准确、最好的估计?通过这种直观而重要的洞察力,我们开发了一个功能强大的通用的显着性推理网络,以协作的方式部署这两个流程。
- 该网络使用自上而下过程中的细粒度显着性来自下而上地改进高层估计。然后使用精确的高层显着性来进一步鼓励更有效的自上而下推断。这种设计有效地促进了不同层之间的显着性信息的交换,从而产生了更好的学习和推理能力。更重要的是,模型配备了完整的、迭代的前馈/反馈推理策略,而不是常用的前馈网络或类UNet模型,它们只提供简单的粗到细推理。由于缺乏反馈策略,前馈显着性模型受到限制。尽管类似UNet的SOD模型部分地解决了这个问题,但它们并未考虑自上而下和自下而上的流程交互和集成。
- 从网络设计的角度来看,大多数以前的基于FCN的显着性模型可以被认为是我们提出的显着性推理网络的特定形式。虽然以前的一些作品采用了自上而下和自下而上的策略,但它们要么不是以端到端的可训练方式学习,要么不让这两个过程相互迭代地协作。
为了更高效,迭代显着性推断在两个级别上执行。
- 在宏观上,多个自上而下/自下而上的推理层堆叠在一起,以迭代实现自上而下/自下而上的推断。
- 在微观层面上,我们的显着性推理模块是通过循环网络实现的,在每个单独的层内执行逐步显着性估计。通过对每次迭代的所有侧输出添加监督,模型可以通过更深层次的监督策略进行有效训练。
总而言之,我们的模型有几个基本的特征和优点:
- 它通过模仿自上而下和自下而上的人类感知过程,提供对SOD任务的更深入的了解
- 它提供端到端的框架工作,以联合和迭代的方式学习自上而下/自下而上的显着性推理
- 它提供了一个强大的工具,通过完整的迭代前馈和反馈策略扩展深度SOD模型,使其足够通用和灵活,涵盖大多数其他基于FCN的显着性模型
之前工作的不足
- 全连接网络:空间信息损失并且非常耗时,因为它们通常基于分割方式来进一步执行显着性推断。
- 全卷机网络:在一定程度上保留了空间细节,表现出了不错的效果。但是,它们通常不会考虑自上而下的过程,很少以联合、迭代和端到端的方式探索自上而下和自下而上的推理。
与现有的基于FCN的模型的关联
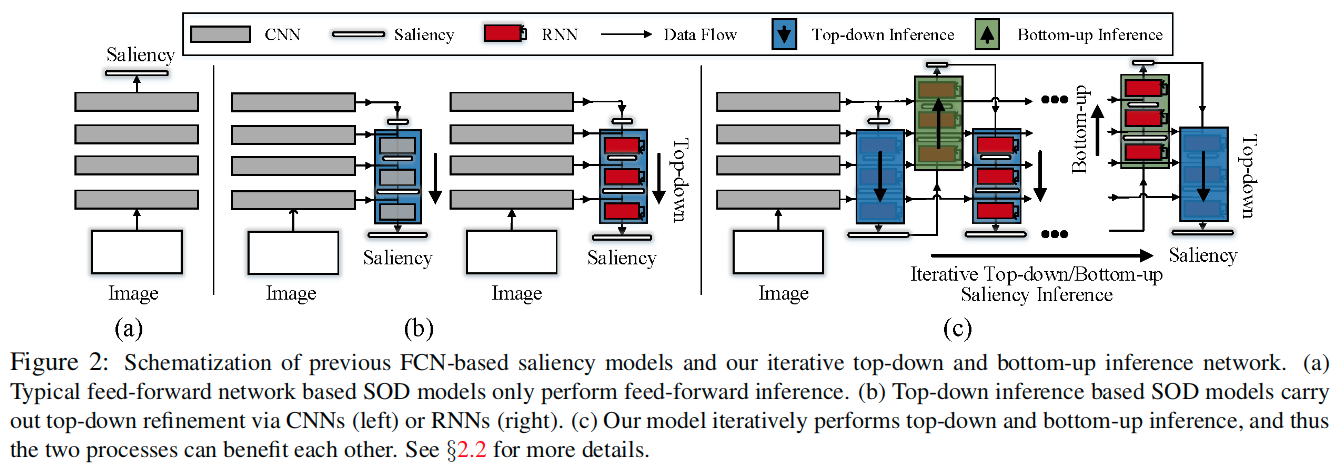
这里将现有的基于FCN的模型划分为两类:feed-forward network和top-down inference based 两种模型
- feed-forward network:如图a,这种网络设计是直截了当的并且被广泛使用,但由于编码器内的池化操作而具有丢失很多空间细节的缺点。
- top-down inference based:如图b,这类方法一般启发于UNet和top-down分割模型。这些方法可以被进一步分成两类:第一类如图2b左侧的模型,这里的top-down推理过程通过卷积层来实现;第二类如图2b右侧的模型,它引入一个循环机制来迭代优化每个侧输出,通过RNN的隐藏状态的更新。然而这些方法都是从top-down推理过程中收益,很少考虑联合它和一个由下而上的过程。PiCANet探索过这个,然而只考虑了bottum-top的显著性传播,但这两个过程并不是以迭代和合作的方式进行的。
图2c给出了自上而下和自下而上显着性推理网络的核心方案。如图所示:
- 该模型首先执行自上而下、从粗到细的显着性,以获得最精细的显着性估计(显示在蓝色矩形中)
- 然后利用底层输出来反向细化上层估计(如绿色矩形所示)
- 使用更准确的顶层显着性估计,可以执行更有效的自上而下推断
- 这些自上而下和自下而上的过程都是为了产生改进的逐步结果而迭代进行的。
- 自上而下/自下而上的推理模块由RNN形成。通过这种方式,所提出的模型继承了上述自上而下推理的显着性模型的优点,同时更进一步,在联合、迭代和端到端中使用自上而下/自下而上的过程方式。
- 以前大多数基于FCN的SOD模型都可以视为我们提出的模型的特例。
网络细节
这里使用的骨干网路是VGGNet和ResNet结构。
迭代式增强结构中心假设是,自上而下推断得到的高度准确、最精细的显着性可通过自下而上的过程提供更准确的高层显着性估计。更准确的高层显着性进一步实现了更有效的自下而上推理。以这种方式,这两个过程以联合和迭代的方式执行以相互促进。
top-down saliency inference
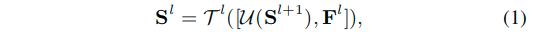
- 每一个推理流程包含L-1个阶段,一共有L个特征图。
- 这里的S表示的是特征阶段的预测的显著性结果。S表示的就是对于S而言的更为精细的显著性图,二者的转换通过推理层T来实现的由上而下的过程。
- 这里的F是来自编码器的特征,详细的位置可以看图3a中的结构。
- 这里的U表示的是上采样操作。
- 这里的
[ ]表示拼接操作。 - 由上而下的推理层由数个卷积或者RNN单元以及激活层构成。
正如前面讨论的,大多数基于FCN的SOD模型可以通过式子1来模拟。也就是他们通过由上而下的逐层推理,来最终获得一个精细的显著性估计结果S,可见图3a。但是一个基本的差异在于,文章的方法在获得初步的最精细的显著性结果之后,进一步通过一个由下而上的过程,用其来优化上层的显著性估计。
bottom-up saliency inference
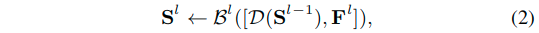
- 这里的符号表示同前面的式子1中的符号。
- 这里的D表示的是下采样操作。
- 而这里的
<-表示的是一个更新过程。 - 这里的B表示的是由下而上的传递过程。
Iterative top-down and bottom-up inference
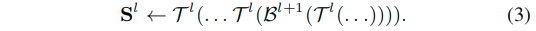
- 符号含义与前面的式子相同。
- 这里的核心在于重复迭代,更准确的起始点可以进一步获得更为准确的由上而下的推理过程。重复的过程可以实现一个迭代式的由上而下、由下而上的显著性推理框架。
- 每一级的输出的显著性图会被后期的显著图的预测过程所使用,所以总体来看就是在不断的
l->l+1->l的过程。
Feature-sharing and weight-sharing
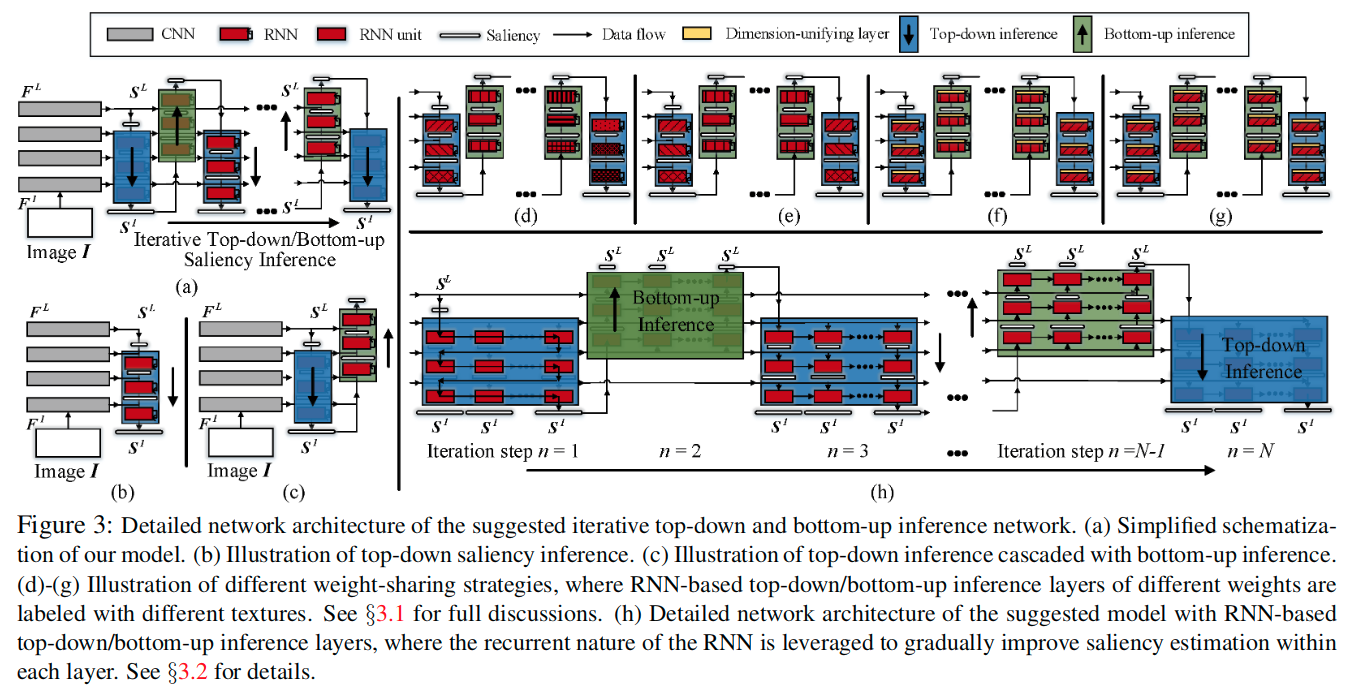
关于图中的示例要注意的是,对于不同权重参数的层使用不同样式方向的线来区分。 对于图d,可以看出,所有的结构的权重参数都是不同的,也就是不共享权重的情况。 对于图e,可以看出,这里对于由上而下的过程中对应级别的处理都是权重共享的,由下而上的过程也是如此,但是过程中的不同层级中的权重是不共享的。 对于图f,可以看出,这里在e的基础上,进一步统一了不同层级之间的权重。 对于图g,可以看出,这里统一了所有的推理层的权重。 这里的h,将结构中的CNN替换成了RNN,可见每一个流程中都对应着数个时间步的RNN。
- 从前面的描述中可以看出来,这里在由上而下和由下而上的不同迭代的推理过程中,特征F是共享使用的,这位高效计算提供了一个优势,因为只需要计算一次就可以反复调用。
- 另外的一个重要特征是权重共享。不再是在不同的迭代中独立的简单的学习每个由上而下、由下而上的推理层,对于每个相同层级的推断层,在不同的迭代步中,两个由上而下/由下而上的推理层之间共享参数。
- 另外,通过稍微改变网络设计(图3f),可以在所有迭代和层之间的不同自下而上(或自上而下)推理层之间强制执行参数共享。
- 具体来说,由于自下而上(和自上而下)推理层是由一组卷积核进行参数化的,可以添加维度统一层R(可以使用1x1卷积实现,来调整维度),它们统一所有自下而上(和自上而下)的推理层的输入特征通道尺寸使它们相同。于是等式1-2可以转换为下面的式子:
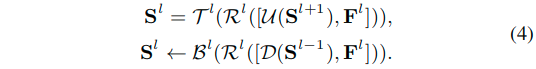
- 此外,如果追求极轻量级的形式,甚至可以在所有迭代步骤中,所有自下而上和自上而下的推理层中使用参数共享(图3g)。这可以通过使唯独统一层压缩自下而上/自上而下推断层的每个输入以具有相同的通道尺寸来实现。在这种情况下,迭代的上下传播过程可以通过一个参数量很少的轻量级网络来实现。
- 总之,通过权重共享,提出的迭代式自上而下和自下而上推理层可以用作现代网络架构的附加组件。 这证明了提出的模型的一般性和灵活性。
Possible Variants and Other Detail
这里实际上提出了一个通用、统一又灵活的框架,而不是仅仅局限于一个特定的网络结构。所以这里进一步探索了不同的构造变体。
基于CNN的推理:实现自顶向下/自底向上推理层的最直接方法是将它们建模为卷积层的堆叠。通过搭配非线性激活,卷积层可以学习复杂的推理函数,利用上层或下层显着性和当前层特征以非线性方式,进行细粒度(自上而下过程)或更高层次(自下而上过程) )的显着性推断。
基于RNN的推理:和基于RNN的SOD模型有着相似的核心,在推理层中使用RNN结构。对于循环模型,在每次迭代时,对每个层逐步执行显着性推断。此外,为了保留空间细节,应采用卷积RNN,而不是全连接RNN。可以通过用空间卷积替换点积来构造卷积RNN。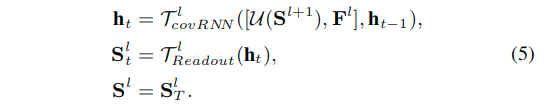
这里实际上计算了前面的式子1。其中,h是t步上的隐藏状态,而T是一个readout function,这里使用1x1卷积配合sigmoid函数实现,输出的显著性结果是S,最终的地T步的显著性结果S被用于最终输出S。 注意,对于给定的自上而下推断层T**l**,输入特征对于每个步骤是相同的,因为它在静态图像上操作。 式子2里的方程式中的推理层,可以以类似的方式计算。 具体图示可以看3h。
这里使用RNN结构,可以进一步迭代优化静态图像的显著性特征,而不是用来模拟序列数据的时间依赖关系。同时要注意,这里不只局限于特定的RNN结构,文章尝试了卷积RNN、卷积GRU和卷积LSTM结构。另外,基于CNN的推理模型,可以认为是基于RNN模型的特例,也就是每个RNN的更新步数为1的时候。因此测试的时候使用基于RNN的模型。
深监督训练策略:深监督的策略从Deeply-supervised nets引入,已经广泛使用在了基于FCN的SOD模型中。这里提出的模型也是用深监督的策略。这里对每一次迭代(B-U/U-B)和每个更新时间步(RNN单元)的输出都进行监督。于是有如下损失公式: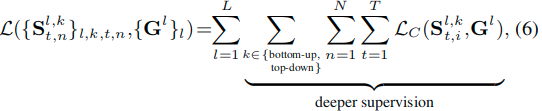
这里使用的还是SOD中常用的交叉熵损失。这也将提升每个推理层的判别能力,并且通过对即时输出的监督,鼓励RNN单元更快更有效的学习显著性表示。
实验细节
- 使用VGGNet或者ResNet50的卷积部分作为特征提取器。
- In our implementation, for simplicity:
- each conv kernels of the convRNN unit in the bottom-up/top-down inference layers is set as 3x3 with 16 channels.
- The channels of the input features of the bottom-up/top-down inference layers are uniformly compressed to 64.
- The dimension-unifying layer R is acquired through a 1x1 conv layer.
- For these layers, RELU is used as the activation function.
- We set the total number of update steps T of the RNN units to 2and the total iteration steps N of the top-down and bottom-up process to 3.
- we train our model using the THUS10K dataset, which has 10,000 images with pixel-wise annotations.
- The training images are uniformly resized to 224x224.
- Data augmentation techniques (e.g., flipping, cropping) are also performed.
- The networks are trained over 10 epochs, for a total of about 12 hours, using an Nvidia TITAN X GPU.
- The output S in [0, 1] of the last top-down inference layer after the final update step T and final iteration step N is used as our final saliency result.
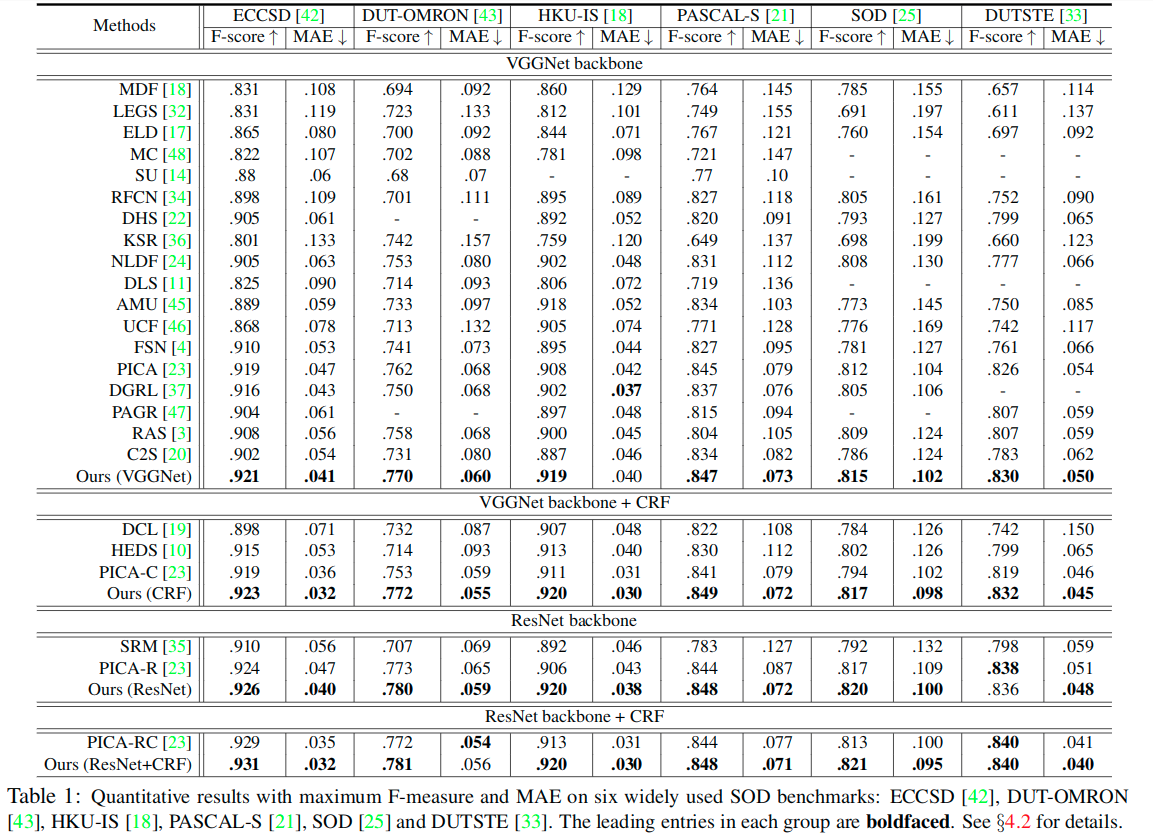
定量分析Quantitative evaluation. Because some methods are post-processed using fully connected conditional random field (CRF) or different backbones (e.g., VGGNet, ResNet50), we also report our results with these settings. In Table 1, we show the results of quantitative comparisons for the Maximum F-measure and MAE. We observe that our model consistently outperforms all other competitors, across all metrics.
定性分析Qualitative evaluation. Results for qualitative comparisons are given in Fig. 4; showing the proposed model is applicable to several challenging scenes well, including large foregrounds, complex backgrounds and objects with similar appearances to backgrounds, etc.

不同类型推理层效果比较
**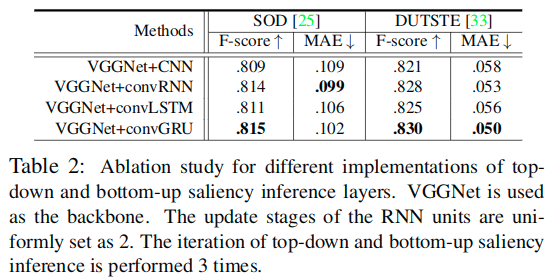
From Table 2 we find that the RNN variants perform better than the one based on CNNs. This is because RNN units introduce a feed-back mechanism into each inference layer, enabling intra-layer step-wise optimization, while CNN constituents only allow feed-forward estimation. We also find slight changes in performance among the different RNN variants. The best choice appears to be the basic RNN or the GRU. This is perhaps because there is no need to model long-term dependency. It is also more difficult to train the LSTM due to its larger number of parameters. 后续测试都是基于卷积GRU的实现。
迭代、联合式的T-B/B-T推理的有效性
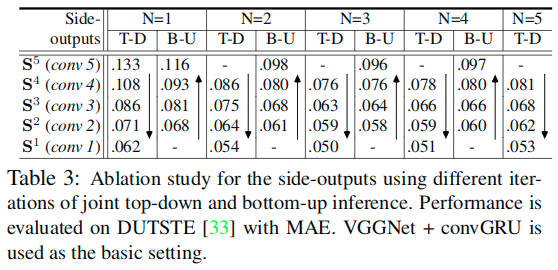
It is clearly shown that, within each top-down (T-D) and bottom-up (B-U) iteration, the saliency estimates from theT-D are improved through the use of B-U. Additionally, the results gradually improve with more iterations (N<=3). We find that, with upper-layer guidance, the inferior layers gradually produce better results, demonstrating the effectiveness of our coarse-to-fine process. 这里也反映出来,更多的迭代并不代表效果的提升。
推理层中RNN的更新步数对于推理的影响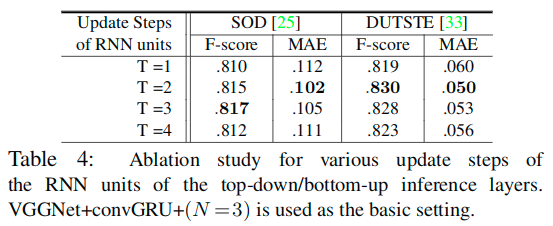
从表中可以看出来,随着更新步数的增加,效果有一定的提升,但也有上限。这里关于T=1的情况,也可以看作是基于CNN的实现。
不同参数共享策略的效果比较
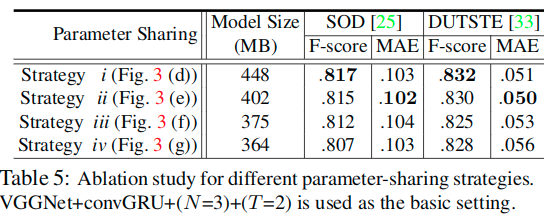
As can be seen, the model with strategy i shows relatively high performance, but has the largest number of parameters, while strategy iv is the most light-weight. The model with strategy ii achieves the best trade-off between performance and model size.
深监督的效果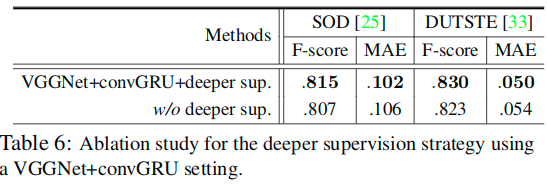
Our model is trained using a deeper supervision strategy. In other words, for each side-out layer, supervisions are fed into each RNN update-step outputs during each top-down/bottom-up iteration. Table 6 shows that such a strategy enhances performance.
This is because the errors in the loss can be directly back-propagated into each iteration of the top-down and bottom-up inferences and update steps of the RNN units.
相关链接

若有收获,就点个赞吧
0 人点赞
