
- 论文:https://arxiv.org/abs/2203.03952
代码:https://github.com/hkzhang91/EdgeFormer
核心内容
本文主要探究了轻量模型的设计。通过使用Vision Transformer的优势来改进卷积网络,从而获得更好的性能。
本文提出的核心算子,即global circular convolution (GCC),是一个卷积操作,但是会引入位置嵌入,同时还具有全局的感受野。另一个改进点是使用提出的GCC和SE操作构建了类似于Vision Transformer的基础操作单元。借助于SE引入了样本相关的注意力机制。
提出的结构组合起来可以作为一个基础的单元用于替换卷积网络或者Transformer架构中的相关模块。
基于这些提出的结构构建的轻量卷积结构在更少的参数量和推理速度的同时,获得了比轻量卷积网络和Vision Transformer更好的性能。
对于ImageNet-1K的分类,相较于基线模型MobileViT,EdgeFormer以约5M参数实现78.6%的TOP-1准确性,节省11%的参数和13%的计算成本,但准确性提高了0.2%,并且推理速度更快(在基于ARM的Rockchip RK3288上)。仅使用了DeIT 0.5倍参数量,但与DeiT相比,准确率提升了2.7%。在MS-CCOCO目标检测和Pascal VOC分割任务上,EdgeFormer还显示出更好的性能。ViT和ConvNet
二者都是必不可少的。
从实用角度而言,二者各有优缺点:
- ViT模型逐渐体现出更好的性能,但是通常面领着高昂的计算成本,并且难以训练。
- 相较于ViT类结构,卷积网络显示出了稍差一点的性能,但是仍然有着独特的优势。例如卷积网络有着更好的硬件支持,容易训练。另外,卷积网络在针对移动或者小模型上仍然大有可为。
- 从信息处理的视角而言,二者有着独特的特性:
- ViT架构擅长于提取全局信息,并且在数据驱动下,使用注意力机制从不同位置上提取信息。
- 卷积网络专注于建模局部关系,并且有着更强的归纳偏置带来的先验信息。
经过这样的对比,作者们思考,是否可以从ViT的设计上学习一些东西来提升针对移动或者边缘设备的卷积网络的性能。这也正是本文的目的所在。文中,作者们想要设计一个新的轻量的卷积网络,来进一步增强其在移动设备和边缘计算设备友好模型领域中的力量。纯卷积是更加移动设备友好的,因为卷积操作被现有的工具链已经高度优化,并且被广泛使用于部署模型到资源受限设备上。甚至,由于这些年来卷积网络的流行,一些现有的神经网络加速器围绕着卷积风格的操作被设计出来,而并没有有效支持例如softmax这样复杂的非线性操作以及大矩阵乘法所需要的数据总线带宽数据。这些硬件和软件上的限制使得纯卷积的轻量模型相对于那些即使在其他方面具有同样竞争力的ViT类的模型仍然是更好的选择。
为了设计这样一个卷积网络,作者们比较并总结了ViT相较于卷积网络的三个主要不同:
- ViT更擅长于提取全局特征
- ViT应用了meta-former block
- 在ViT中,信息集成是数据驱动的(但是这种数据驱动的形式过于耗费内存,于是大量基于先验知识对此集成区域进行约束,压缩空间,从而提升Attention操作的效率)
为此,作者们针对这些点设计了EdgeFormer模块,来改进卷积网络:
- 提出一个全局循环卷积(Global Circular Convolution,GCC)操作来提取全局特征从而改善传统卷积操作的有限的感受野。其中,基于实例的卷积核(这里想说的应该是卷积核的参数与输入相关)和位置嵌入策略分别被用来应对输入尺寸的变化,并且向输出特征图中注入位置信息。
- 基于提出的GCC,构建了一个纯卷积风格的meta-former模块作为基础结构。
- 通过对FFN添加通道注意力(SE Block)来引入输入相关的核权重。
对于最终的模型EdgeFormer,则是借鉴CoatNet和MobileViT的结构风格,采用了双叉形式的结构(bifurcate structure)。
根据这些设计构建的最终模型在三个主流的视觉任务上的轻量模型的对比中获得了不错的性能表现。
从相关工作看论文
NLP中的Transformer被ViT引入视觉任务后,出现了大量工作对其结构进行优化,以提升其计算效率和训练效率。
- 从提升训练策略的角度来看,DeiT(Training data-efficient image transformers & distillation through attention)使用知识蒸馏策略来训练ViT,从而使用更少的预训练数据实现了极具竞争力的性能。
- 从提升模型架构的角度来看:
- 一些研究者试图通过借鉴卷积网络的思想来优化ViT,他们将卷积网络的一些操作整合到ViT中。
- PVT(Pyramid vision transformer: A versatile backbone for dense prediction without convolutions)和CVT(Cvt: Introducing convolutions to vision transformers)在不同阶段中插入卷积操作来减少token的数量,构建了分层的多阶段结构。
- Swin(Swin transformer: Hierarchical vision transformer using shifted windows)则是将Attention的计算约束在了固定尺寸的局部窗口之中。
- PiT(Rethinking spatial dimensions of vision transformers)则是通过联合使用池化层和深度卷积层来实现特征图通道的扩张和空间的缩减。
- 而另一些工作则是通过直接组合两种风格来设计新的混合架构。他们都相似地在模型起始阶段使用卷积stem来提取局部特征,而在后续的结构中使用transformer风格的结构提取“全局”或者“局部-全局”特征。本文提出的纯卷积架构的工作同样使用类似的思想。
- LeViT(Levit: a vision transformer in convnet’s clothing for faster inference)混合了卷积网络和Transformer,实现了很好的速度和准确率的权衡。
- BoTNet(Bottleneck transformers for visual recognition)则替换ResNet深层的卷积层为多头自注意力结构。
- ViT-C(Early convolutions help transformers see better)则将原始的ViT的patchify stem结构(核大小等于跨步的卷积)替换为convolutional stem结构从而有效提升了ViT优化的稳定性和峰值性能。
- ConViT(Convit: Improving vision transformers with soft convolutional inductive biases)则将通过门控位置自注意力合并了soft convolutional inductive biases。
- CMT(Cmt: Convolutional neural networks meet vision transformers)则应用了基于深度卷积的局部感知单元和一个轻量的Transformer模块(使用跨步等于卷积核的深度卷积缩减K和V)。
- CoatNet(Coatnet: Marrying convolution and attention for all data sizes)合并了卷积和自注意力来设计新的transformer模块(浅层使用卷积,深层使用额外引入全局静态权重的Attention),这可以同时关注局部和全局信息。
- 一些研究者试图通过借鉴卷积网络的思想来优化ViT,他们将卷积网络的一些操作整合到ViT中。
针对本文着重探究的轻量模型的设计的领域,作者们也详细的回顾了卷积神经网络和视觉Transformer的一些工作。
- 卷积神经网络:ShuffleNet系列,MobileNet系列,MicroNet,GhostNet,EfficientNet,TinyNet和MnasNet。相较于标准卷积网络,他们具有更少的参数,更低的计算成本,更快的推理速度。另外,轻量的卷积神经网络可以被应用到各种设备上。但是尽管有这样的优势,但是这些轻量模型性能稍差于更重的模型。
- 卷积神经网络与视觉Transformer的组合:
- Mobile-Former(Mobile-former: Bridging mobilenet and transformer)并行组合了MobileNet和Transformer,利用前者提取局部特征,利用后者捕获全局信息。
- MobileViT(Mobilevit: light-weight, general-purpose, and mobilefriendly vision transformer)中使用提出的MobileViT模块来替换MobileNetV2的深层模块。提出的模块中,通过卷积提取的局部表征,与全局表征被拼接来获得“局部-全局”表征。
就本文而言,提出的结构与Mobile-Former和MobileViT比较相关。不同点在于这两个方法仍然去保留Transformer块,而本文结构却是一个纯的卷积网络,这使得提出的结构对移动端更加友好。论文针对低算力平台的的实验也证实了这一点。在通过向视觉Transformer学习来设计一个纯卷积网络这一点上,本文和ConvNeXt有相近之处。主要有两点不同:
- 想法和架构并不相同。ConvNeXt通过将一系列增量但是有效的设计引入,从而将一个标准的ResNet朝着视觉Transformer的方向来改动。而本文则直接从三个卷积网络和视觉Transformer的差异的角度入手来设计网络,这从一个宏观的层面上填补了缺口。由于想法不同,对应的结构也就有所差异。
- 提出的目的不同。本文主要针对移动设备。相较于ConvNeXt,在轻量模型的设定下,本文的方法更有优势。
提出的方法
EdgeFormer Block
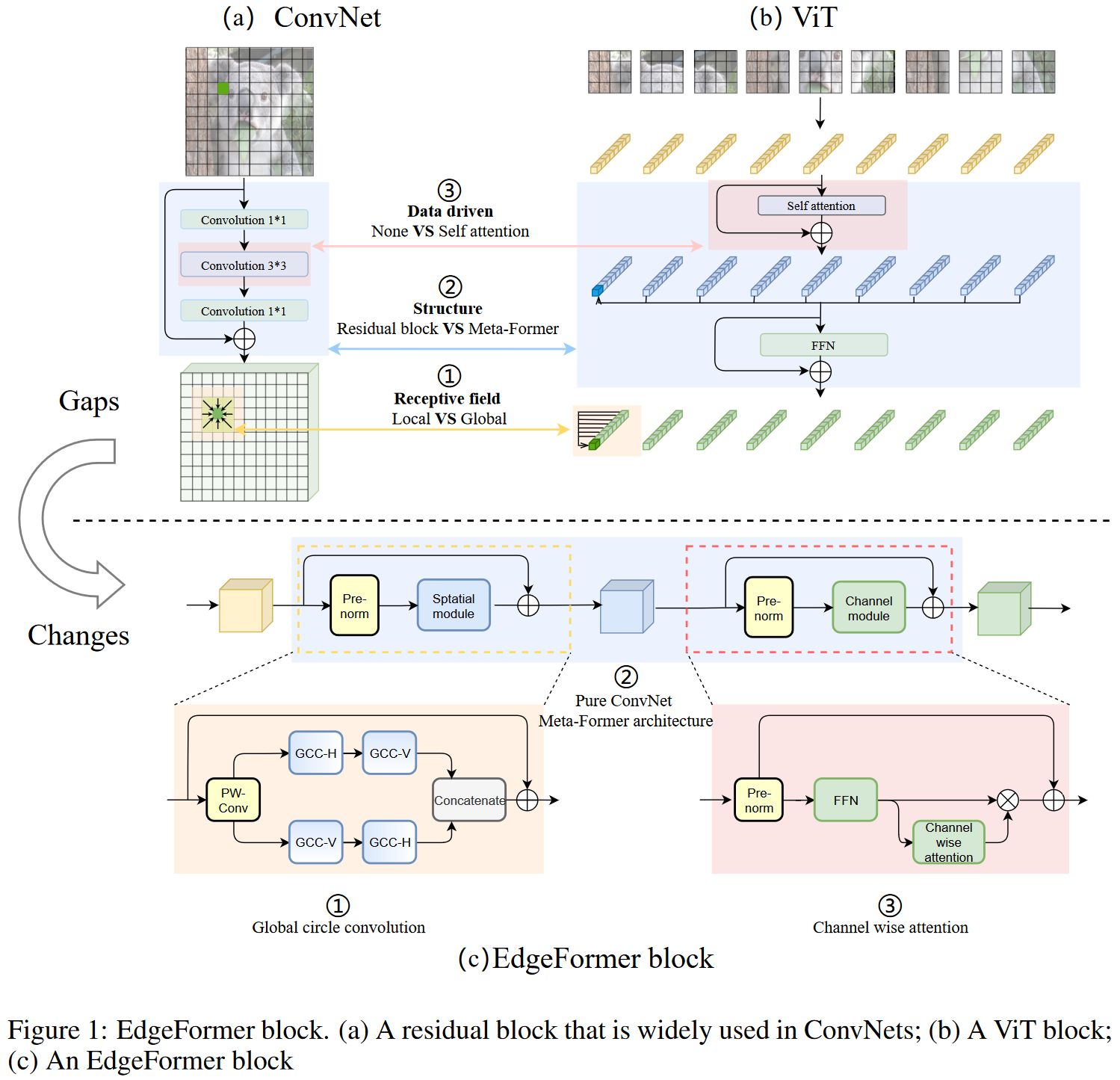
图1中显示了卷积网络和ViT类结构主要差异。而图中下半部分则是提出的模块的结构。使用全局循环卷积提取全局特征
卷积操作中,每个位置上的输出特征是通过对以其为中心的局部邻域上的输入特征进行加权聚合得到的。而ViT类结构中,自注意力模块提取特征则是通过对全局空间范围上的特征进行聚合后得到的,而且聚合权重是基于特征相似性生成的动态参数。相较于卷积的局部感受野,后者可以从整个空间维度上学习全局特征。
针对这点不足,本文提出了全局循环卷积GCC。提出的GCC通过使用水平和垂直方向进行分解从而得到了一个单一来看足够轻量的操作。二者各自可以同时覆盖到向同行和相同列的所有输入位置。
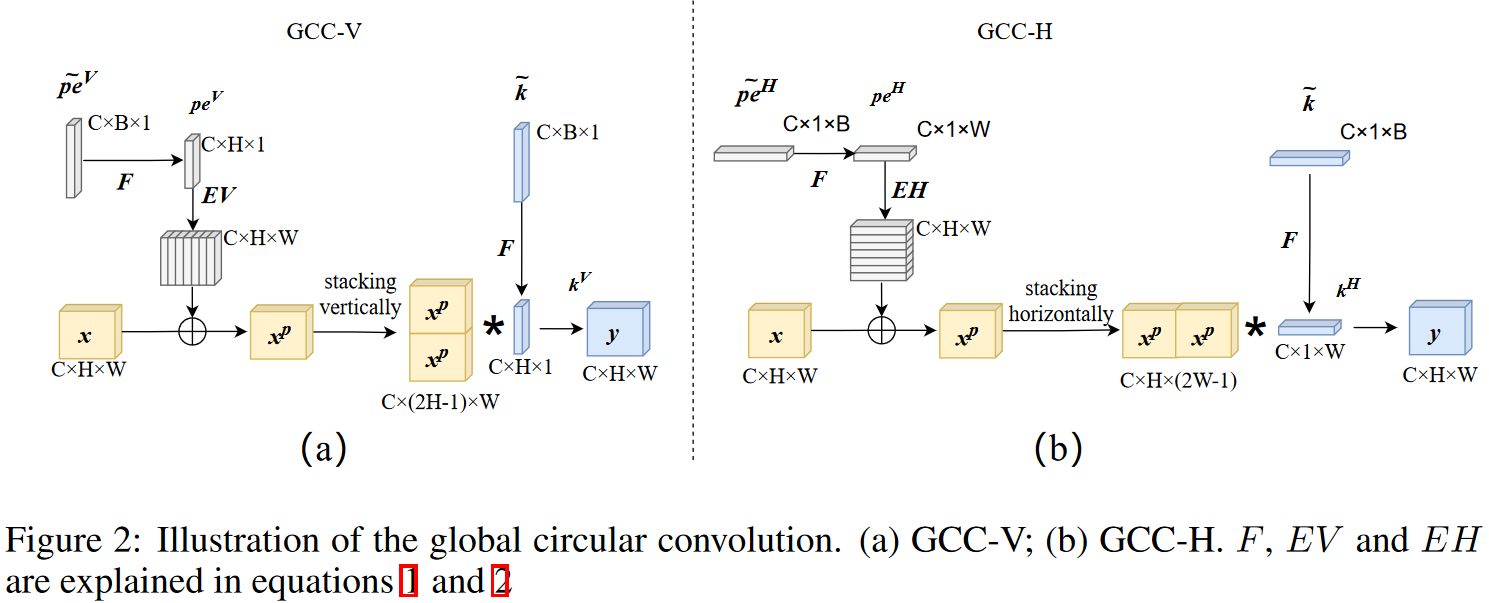
具体而言,以垂直方向的GCC为例,即GCC-V,其步骤如下:
- 输入特征为CxHxW
- 引入一个基础位置嵌入信息为CxBx1,通过扩展它,使其完全等于输入特征的形状,从而可以灵活地适应不同尺寸的输入特征。
- 通过双线性插值,变为CxHx1
- 轴向复制扩展,变为CxHxW
- 加到输入上
- 将得到的特征言H方向堆叠,得到Cx(2H-1)xW,这步操作非常重要,由此便可以实现具有全局感受野且仍然参数共享的标准卷积操作了。
- 接下来开始构造卷积核参数,其同样由一个大小为CxBx1的基础量插值到CxHx1而得到。此时卷积核的空间感受野为Hx1。搭配着GCC-H中的Cx1xW,便近似得到了全局的覆盖。当然,这里同样可以引入偏置,具体的实现也同样是基于一个基础量扩展而成。
- 使用插值后的卷积核和嵌入位置信息的输入张量计算标准卷积操作,得到大小为CxHxW的输出。
这个流程中,GCC-V中大小为CxHx1的卷积核的输出特征坐标i,实际上对应着输入特征上的坐标范围 (i+t)%h,这里的t是一个0到H-1之间的值,不同的t对应着卷积核覆盖的局部邻域中的相对坐标。
也就是说,通过这样一个取模的计算,作者们构建出了一个“循环”的概念。可以说是非常会变通了。但是作者们的实现,却是更考验着思维上的转化了。因为针对这样卷积操作计算方式的改变,一般有两种实现策略,一种是从卷积运算的本身着手,另一种则是从被卷积的特征的角度去变换。这一点在我自己的一份关于动态滤波器的工作中也有所体现。一般而言,前者虽然直接但是实现却非常复杂,可能需要重新写算子。而后者则更考验思维变通的能力。本文的实现思路就是后者。所以更具参考和启发意义。这部分结构主要实现可见:https://github.com/hkzhang91/EdgeFormer/blob/df5ab09c7f60187d022a891ad083f4596838ff54/cvnets/modules/edgeformer_block.py#L534-L677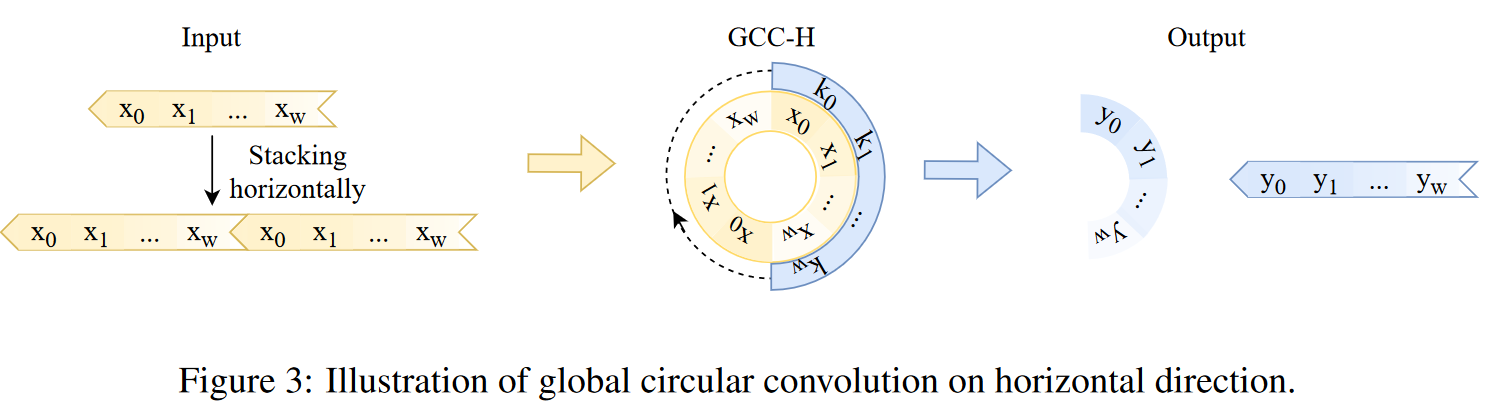
具体而言,作者们直接将两个特征沿着指定轴向维度进行拼接(注意这里后面的特征只取了H-1行的数据,不然输出的特征形状就比输入大1了):torch.cat((x_1_r, x_1_r[:, :, :-1, :]), dim=2)
相较于传统卷积操作,提出的GCC引入了三处修改:
- 感受野扩大到了全局空间。要注意和直接扩大传统局部卷积核到全局范围的设定区分开。因为传统卷积需要引入padding操作来维持特征尺寸,如果直接增大卷积核,绝大多数位置上的处理过程中,仍然只有部分像素被覆盖到。尤其是在边缘区域。大部分区域都是0值。
- 位置嵌入被用来保证输出特征对于空间位置的敏感性。GCC可以提取全局特征,但是也打乱了原始输入的空间结构(因为循环的存在,所以也就无法严格按照局部邻域的本身的相对顺序来处理了)。对于分类任务而言,空间结构的保持可能不是一个大的问题,但是文中的实验中也展现了分割检测这样的密集预测任务对于保持空间结构的需求还是有的。也就是说位置信息的嵌入对于这样的任务而言有一定的益处。
卷积核和位置嵌入是根据输入尺寸动态插值生成的。GCC中,卷积核的尺寸和位置嵌入和输入是一致的,这增强了对于不同尺寸输入的适应能力。
使用GCC构建EdgeFormer块
从卷积网络到ViT架构,一个相当重要的修改就是meta-former block替换了残差块。meta-former block一般包含着两个核心组件:token mixer和channel mixer。前者用于在不同空间位置上的token之间交换信息,后者则是重点关注通道的交互。而且二者都会应用残差结构。
受此启发,GCC被插入meta-former风格的结构中,从而构建了EdgeFormer block。其中替换自注意力模块为GCC,从而作为一个新的空间处理单元。这主要有两点原因:GCC可以提取全局特征,并在不同像素之间进行信息交互,这满足token mixer的要求。
自注意力模块的计算复杂度是平方级别的,通过改用GCC,可以显著降低计算成本,有助于实现设计轻量的卷积网络。
向Channel Mixer中添加通道注意力
ViT架构中,自注意力模块可以根据输入调整权重,这造就了ViT这来数据驱动的模型。通过引用注意力机制,数据驱动模型可以专注于重要的特征,并且抑制不必要的信息,这带来了更好的性能。曾经的一些工作(例如SENet等)也强调了保持数据驱动的重要性。
通过替换自注意力操作为GCC结构,我们得到了一个可以提取全局特征的纯卷积网络。但是替换后的模型不再是数据驱动的结构了,为此,文中向Channel Mixer中引入了通道注意力。这里参考了SENet的结构。EdgeFormer
通过为提出的EdgeFormer block选择一个外框架(outer frame),构建了本文的模型EdgeFormer。
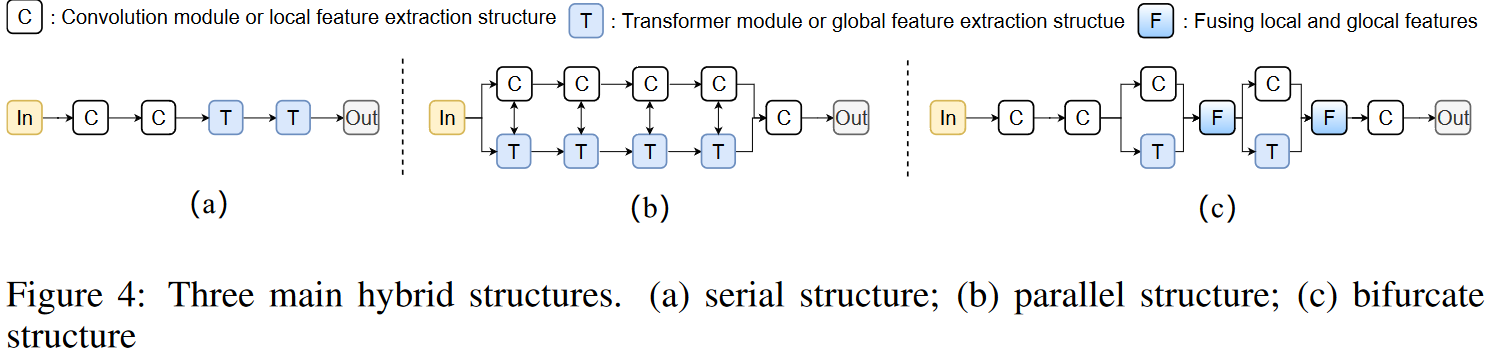
现存的混合架构基本可以分为三类,包括序列结构、并行结构和双叉式(bifurcate)结构。其中双叉式结构目前获得了最好的效果,典型如CoatNet,而对于轻量结构,MobileViT也采用了这一形式。因此本文也延续了这一设计,基于MobileViT构建了最终的外框架。具体而言,针对baseline MobileViT,本文做出了如下改进:MobileViT包含两个主要类型的模块,ViT和MobileNetV2。本文保持了所有MobileNetV2模块,替换了ViT结构。这一替换使得最终模型从混合架构变成了纯卷积架构。
- 适当地增加了EdgeFormer块的宽度。即便如此,替换的模型仍然具有较少的参数和较少的计算成本。
- 现有的双叉结构包含着一些交互模块,这负责本地和全局特征模块之间的信息交互。原始MobileViT中,ViT块是最重的结构,经过替换后,这些交互结构反而成了大头。因此,本文将分组卷积和点卷积引入这些模块来减少了参数数量还不会伤害性能。
实验结果
性能对比

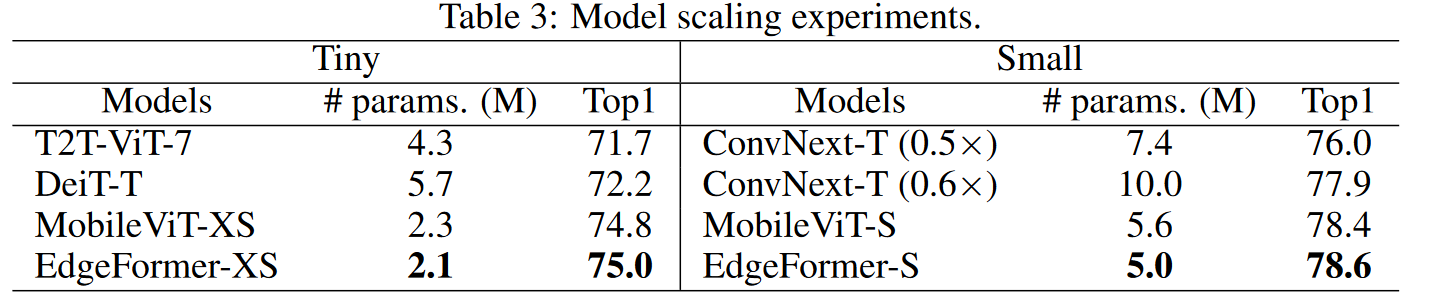

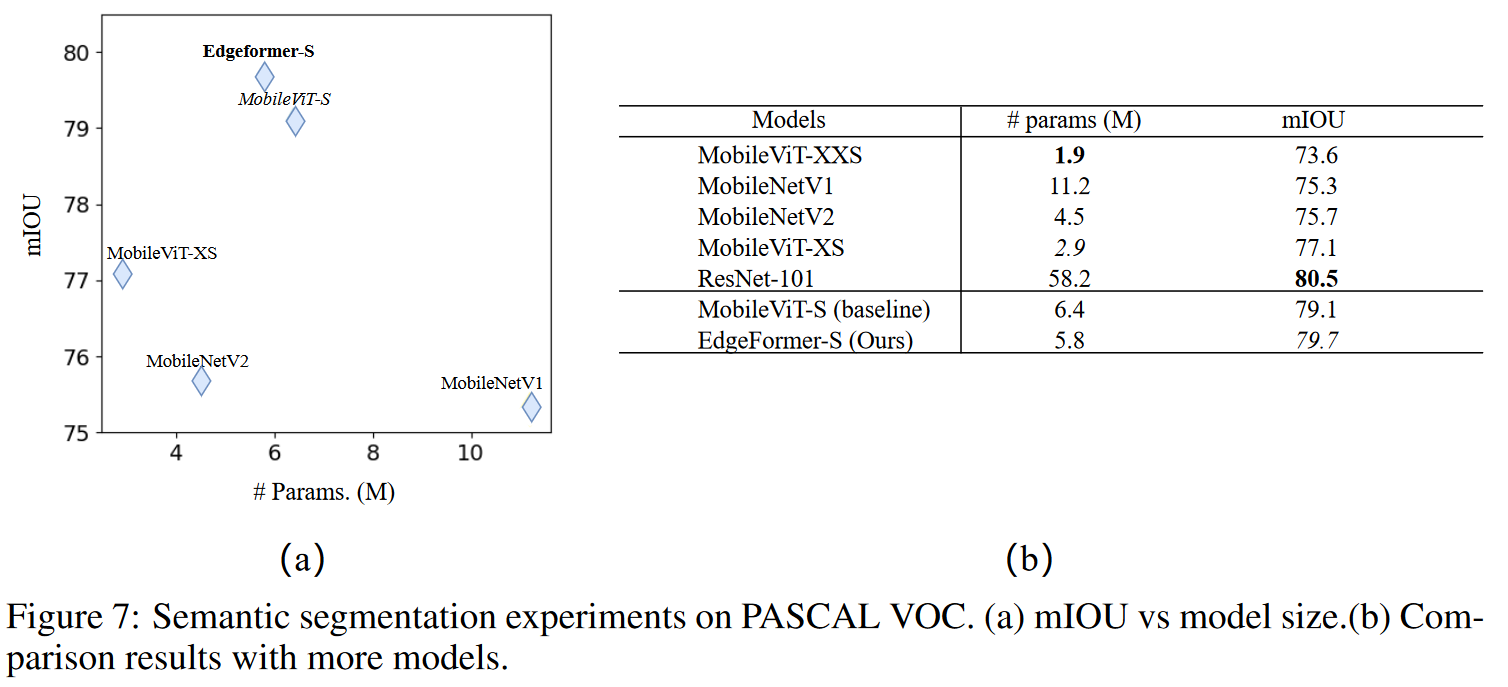
作者们在分类检测分割上都验证了提出模型和组件的性能。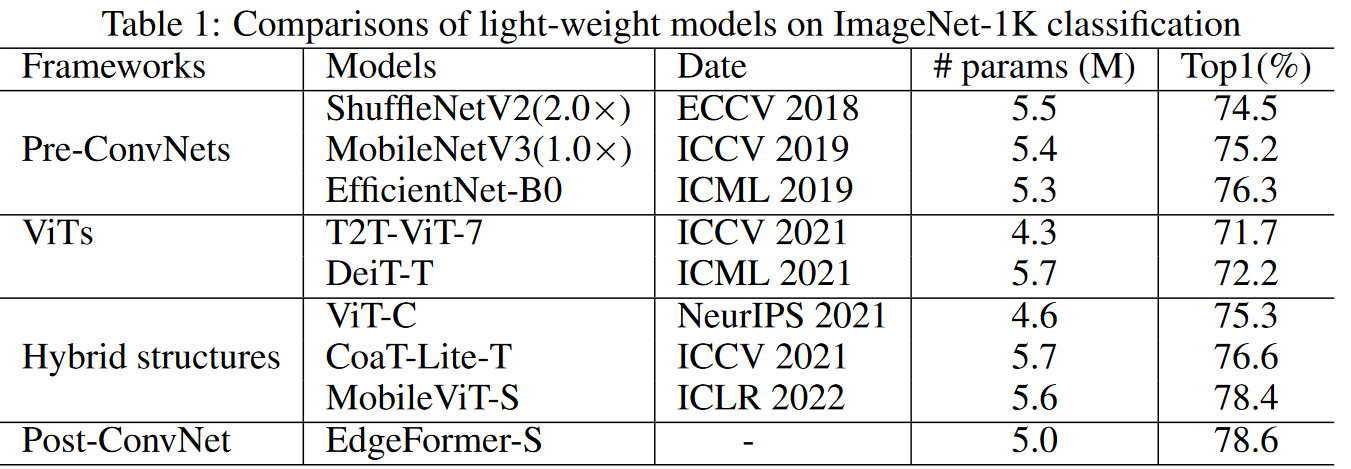
在轻量模型的对比中,可以看到混合架构超越了以往的纯卷积架构和ViT类架构,而本文的升级版的纯卷积架构获得了整体更好的效果。消融实验

这里的消融实验在三个任务上验证了提出组件的效果,这里的baseline为MobileViT。主要做了以下几个方面的对比:
- 用于替换自注意力的(对比消融GCC)卷积核:普通卷积、两种尺度的大核卷积、GCC
- 这里一开始就引入了通道注意力,似乎不太满足控制变量的要求
- 2、3、6的对比可见GCC的优势。
- 这里在大核卷积的实验中(2、3),随着卷积核的增大性能区域饱和(倒是再增大是否会下降就很难说,只能说可能有这个趋势。这一点现象据说在ConvNeXt中也有反映)。而直接覆盖了全局的GCC却可以获得更好的表现。
- meta-former架构的应用
- 这里为了替换meta-former结构,作者们将GCC集成到ResNeXt block中作为替代品。
- 4、7的对比可以看到使用meta-former构建纯卷积网络的潜力。
- 通道注意力的应用
- 5、7的对比可以看到通道注意力的性能增益。
- 位置嵌入的引入
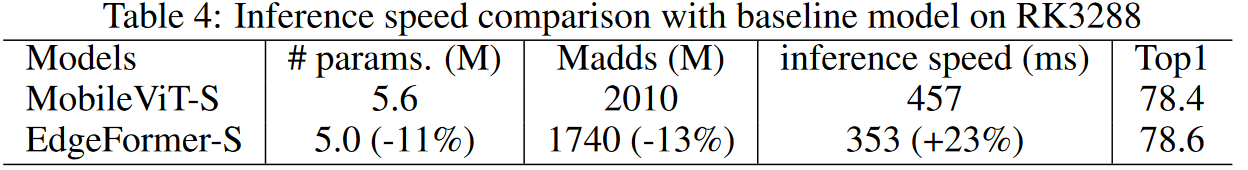
- 卷积已经被现有的广泛用于部署模型到这些资源有限的设备上的工具链高度优化。
- 相较于卷积,Transformer需要更多的数据带宽来计算attention map,这涉及到两个大的矩阵K和Q,然而在卷积中,核相对于输入特征而言,是一个很小的矩阵。如果带宽需求超过了芯片设计,那么CPU将闲置来等待数据,从而导致CPU利用率较低和总体推理速度较慢。

若有收获,就点个赞吧
0 人点赞
