
前言
关于文章总体概览,这篇文章https://mp.weixin.qq.com/s/LCLQltmBxL9f1XzV4Ci-iw已经讲的非常好了。总的核心就是,实现了一种多阶段具有不同分辨率的Transformer Vision的Backbone。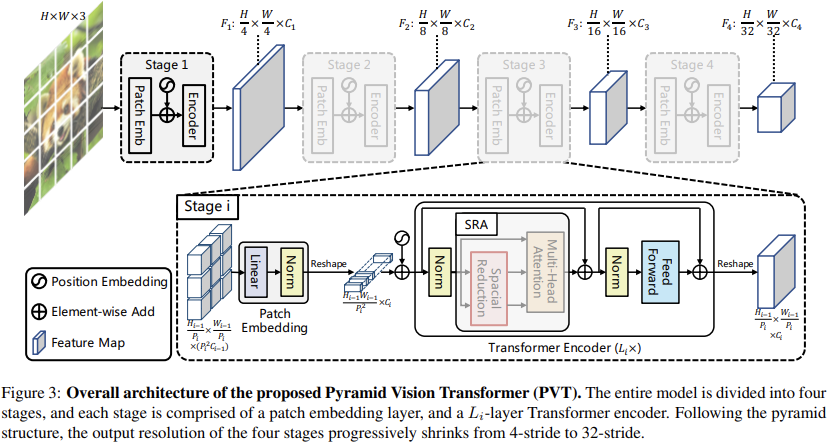
由于提供了不同分辨率的特征,尤其是高分辨率的特征,所以整合PVT和类似FPN的结构可以很好的应对密集预测任务(检测、分割)。 同时可以比较有效的缓解计算负担,因为后续的Self-Attention都是在一个较低的分辨率上运行的。 从下图中分类任务上的表现对比来看,由于前期的分辨率要大于ViT、DeiT这类模型,在整体层数较少的时候,参数上优势并不明显,但是随着模型的增大,参数会相对更少,并且计算量也有优势,整体而言性能很有竞争力。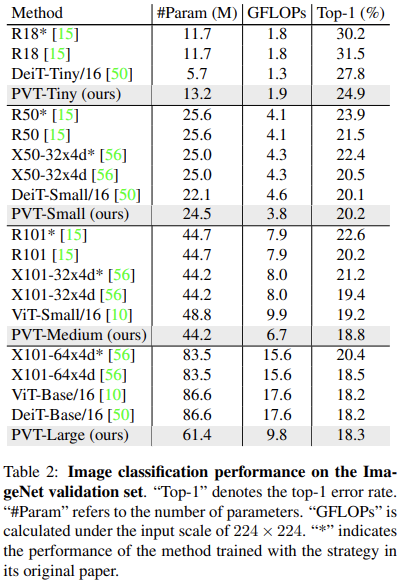 :::info
这里反映出来了一个重要的现象,逐步缩小Token序列的结构其实也是可以实现与Deit以及ViT那种定长Token序列模型相同的效果,甚至更好。
:::info
这里反映出来了一个重要的现象,逐步缩小Token序列的结构其实也是可以实现与Deit以及ViT那种定长Token序列模型相同的效果,甚至更好。
即针对图像构造的Token实际上仍是有待进一步优化以更加高效的提炼图像的局部上下文信息,这一点在Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet中的T2T Module,以及Visual Transformers: Token-based Image Representation and Processing for Computer Vision中的Tokenizer等结构的设计中也是有所体现的。
:::
抛开其他的不说,这里的多分辨率特征的提取实际上既有传统又结合新潮:
- 既有CNN多层级特征提取以为后续结构提供丰富的多尺度信息的常见密集预测任务的增强策略
- 亦有最近的SETR: Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers这种利用多层Transformer Layer中间的输出特征来送入CNN解码器服务于分割预测的恢复的有效尝试
二者拍拍手,诶,似乎思路顺其自然。但是想尝试和能做出也并不等价,具体实操细节过程中,遇到的问题,针对性的解决手段,策略的尝试与调整,都不足为外人道也。不过从结果而言,倒也确实可以说是很好的结合了现有的CNN和Transformer的工作的探索。
与ViT和CNN的比较
作者指出,ViT(DeiT)存在的问题:
Although ViT is applicable to image classification, it is challenging to be directly adapted to pixel-level dense predictions, e.g., object detection and segmentation, because
- its output feature map has only a single scale with low resolution
- its computations and memory cost are relatively high even for common input image size
针对性的解决策略:
different from ViT, PVT overcomes the difficulties of conventional Transformer by:
- taking finegrained image patches (i.e., 4 × 4 per patch) as input to learn high-resolution representation, which is essential for dense prediction tasks
- introducing a progressive shrinking pyramid to reduce the sequence length of Transformer when the depth of network is increased, significantly reducing the computational consumption
- adopting a spatial-reduction attention (SRA) layer to further reduce the resource cost to learn high-resolution feature maps.
针对方案简单粗暴:
- 输出分辨率不够,那么就加大;
- patch token序列太长,导致attention矩阵的计算量太大,那么就针对性的缩减总体序列长度,或者是仅仅缩减k和v的长度(如下图)。
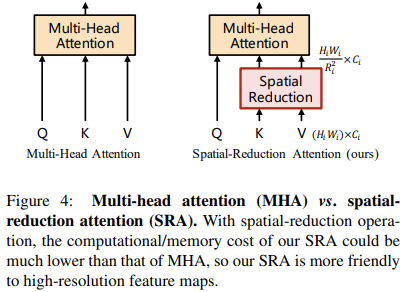
这里的空间缩减实际上更像是一个空间的Unfold操作,将空间元素在通道上堆叠后再压缩到原始维度,进而减小了长度,但是这里还会跟一个LayerNorm
整体来看,PVT的优势如下:
- Self-Attention的计算利用了全局信息,这也是相较于仅仅具有局部感受野的CNN的优势,对于检测和分割任务而言,这是比较有需要的。
- 而多尺度的输出,实际上也可以更好地和现有的这些任务的方法进行整合,这倒是一个便利性上的优势。
对于现有的许多针对Vision Transformer的探索的工作,实际上也可以比较方便的整合起来,实现更有效的Vision Transformer,例如文中展示的PVT+DETR的结构。
下游任务
分类
为了实现分类任务,PVT实在最后一个阶段的输入上添加了learnable classification token,之后在输出上应用全连接层来实现类别预测。
检测
使用四个stage的输出F1~F4作为FPN结构的输入,然后被后续的检测或者实例分割头进一步处理。注意,这里的特征都恢复了HxWxC的结构。
为了应对任意的输入形状并利用预训练权重,这里的位置嵌入是直接使用双线性插值调整预训练权重中的位置嵌入后得到的。这一策略在ViT的微调过程中也有体现。
另外,在检测任务的训练中,PVT中的层将不会被冻结,都要加入训练(这里实际上倒是需要思考,对于Vision Transformer结构,冻结部分层来微调的策略是否有效)。
分割
这里是基于Semantic FPN进行验证的,中间特征也是直接被送入了FPN结构,也是用双线性插值来调整位置嵌入。
其他的一些细节
所有的实验都是基于AdamW的,这是Adam的一个比较有效的修正版本。另外,许多Vision Transformer模型都会使用Adam类的优化器。
- ImageNet上的训练和对比反映出来一个问题,原始的ViT如果不适用额外的JFT300,效果并不能比得上CNN模型,而本文的仅使用ImageNet就可以训练出来这样好的效果,这是否说明这样的逐渐缩小的结构对于Vision Transformer结构而言实际上是一个更合适的选择呢?
- 看起来,训练起来会更容易?这一点不太好说,因为本文的方法并没有追求极致的分类性能,从文章的讨论中还不太好说。文章也没有过多的讨论这个问题。文章更多是在强调对于下游密集预测任务的友好性和有效性。
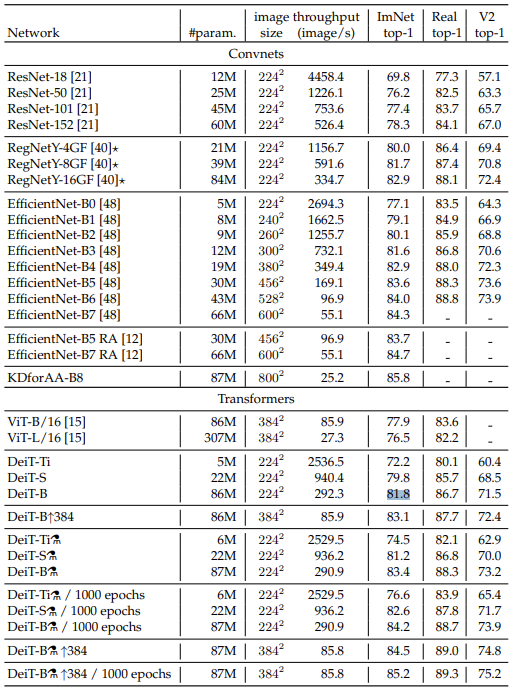
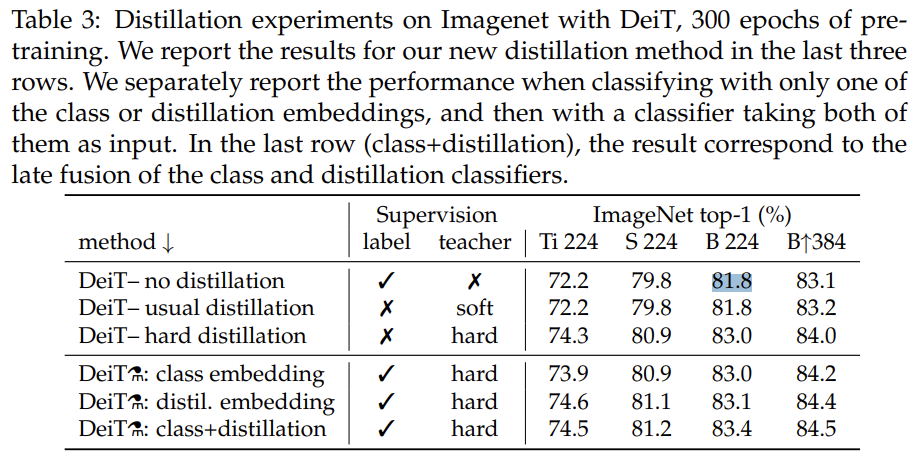
- 另外,这里非常奇怪的一点是Table 2中ViT-Base/16的Top1精度81.8%我在原始的ViT中并没有找到,就很奇怪,感觉是不是作者弄错了?
- 关于这一点,实际上这里的ViT-B/16和DeiT-B是同样的模型,所以是指标没有差别;
- 这里的ViT-B/16效果要比ViT论文中的好,主要还是因为本文的训练策略比较有效。
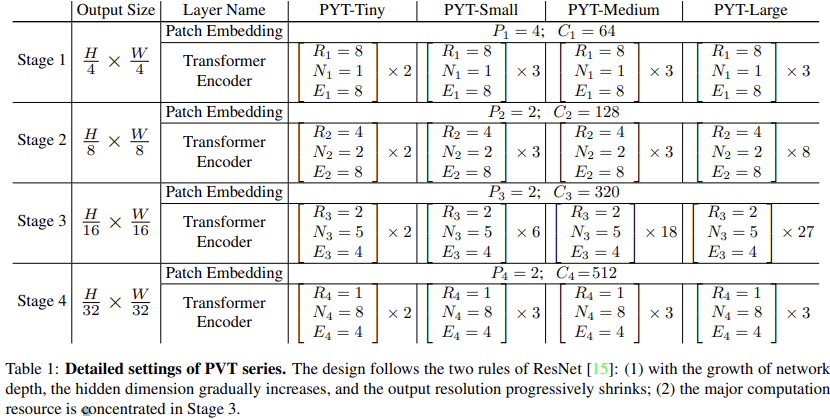
- 以及,这里比较的DeiT结果并不是DeiT最有代表性的结果,放两个来自DeiT的表:
链接

若有收获,就点个赞吧
0 人点赞
