
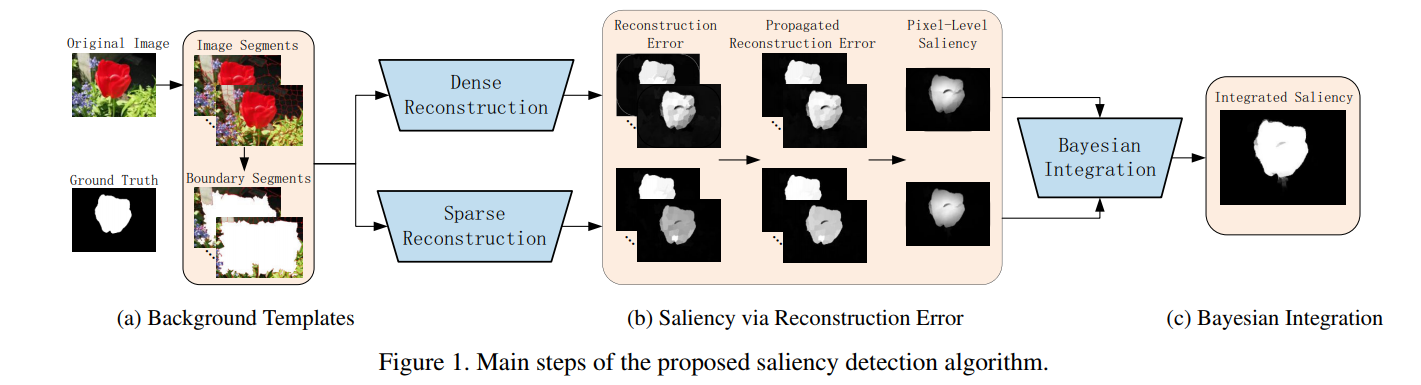
In this paper, we propose a visual saliency detection algorithm from the perspective of reconstruction errors. The image boundaries are first extracted via superpixels as likely cues for background templates, from which dense and sparse appearance models are constructed. For each image region, we first compute dense and sparse reconstruction errors. Second, the reconstruction errors are propagated based on the contexts obtained from K-means clustering. Third, pixel-level saliency is computed by an integration of multi-scale reconstruction errors and refined by an object-biased Gaussian model. We apply the Bayes formula to integrate saliency measures based on dense and sparse reconstruction errors. Experimental results show that the proposed algorithm performs favorably against seventeen state-of-the-art methods in terms of precision and recall. In addition, the proposed algorithm is demonstrated to be more effective in highlighting salient objects uniformly and robust to background noise.
主要贡献
- 提出了一种利用背景模版对每幅图像进行稠密和稀疏重建来检测突出目标的算法,该算法计算出的自底向上对比度更强。
- 提出了一种基于上下文的区域显著性检测传播机制,该机制均匀地突出突出目标,平滑区域显著性。
- 提出了一种结合显著性映射的贝叶斯积方法,取得了较好的效果。
主要流程
本文从重构误差的角度提出了一种视觉显著性检测算法。
- 首先通过超像素提取图像边界,作为背景模板的可能线索,然后构造密集和稀疏的外观模型。对于每个图像区域,我们首先计算密集和稀疏重建误差。
- SLIC(simple linear iterative clustering algorithm)算法生成超像素处理, 对每个分割使用 x={L, a, b, R, G, B, x, y} 表示的平均色彩特征和坐标来描述. 整个图像被表示为
 , 这里N是分割的数量, D是特征维度.
, 这里N是分割的数量, D是特征维度. - 提取边界对应的分割(超像素), 作为背景模版. (只包含边界超像素, 这里不同于Saliency Detection via Graph-Based Manifold Ranking和Ranking Saliency, 使用的SC流程, 分离组合, 而是直接使用了所有的边界元素)
- 计算密集重建误差:
- 基于背景模版
 得到它对应的PCA转换矩阵, 这里只选了最大的D’个B的协方差矩阵的特征值
得到它对应的PCA转换矩阵, 这里只选了最大的D’个B的协方差矩阵的特征值 
- 使用1中的矩阵, 计算重构系数.

- 得到最终的秘密集重建误差

- 对X数据(这里实际用的是
xi-mean(X)使用PCA方法进行降低维度, 压缩数据, 得到特征数据自身的偏离均值的差值在另一个空间上的投影结果, 再”反射”回来到X本身所在的空间计算密集重建误差. - 缺点
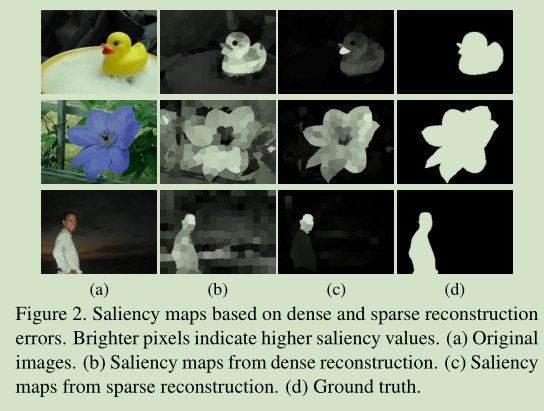
- 稠密表示在特征空间中对具有多元高斯分布的数据点进行建模,因此很难捕捉到多个分散的模式,尤其是在样本数量有限的情况下.
- 基于背景模版
- 计算稀疏重建误差:
- 基于背景模版编码图片分割结果,

- 得到稀疏重建误差,

- 由于所有的背景模板都被看作是基函数(basis),因此稀疏重建误差比稠密重建误差更能抑制背景,尤其是在杂乱图像中.
- 然而,利用稀疏重建误差测量显著性存在一些缺陷
- 如果将一些前景分割收集到背景模板中(例如,当对象出现在图像边界时),由于低稀疏重构误差,它们的显著性度量接近于0. 另外,由于不准确地将前景段作为稀疏基函数的一部分,使得其他区域的显著性度量不太准确。
- 另一方面,密集的外观模型不受这个问题的影响。当前景分割错误地包含在背景模板中时,从密集的外观模型中提取的主成分在描述这些前景区域时可能不太有效。
- 基于背景模版编码图片分割结果,
- SLIC(simple linear iterative clustering algorithm)算法生成超像素处理, 对每个分割使用 x={L, a, b, R, G, B, x, y} 表示的平均色彩特征和坐标来描述. 整个图像被表示为
- 其次,使用基于K-means聚类的上下文传播来平滑的重构误差。
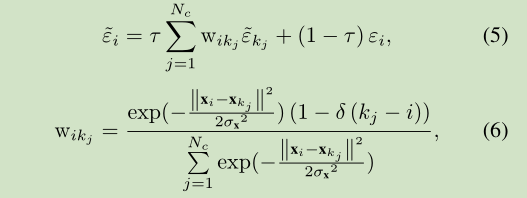
- 这里的两个 epsilon 都表示成了 epsilon_i 的形式(这里对应两个结果是并行处理, 最后要合并). 在聚类k中有Nc个超像素kj, 这里5中的第一项, 计算了除第i项之外的其他所有在聚类k中的超像素kj的特征空间加权平均的重建误差, 并使用参数 τ 加权平衡与原始的第i项的重建误差.
- 式子6中的方差项, 是X每个特征维度的方差和.

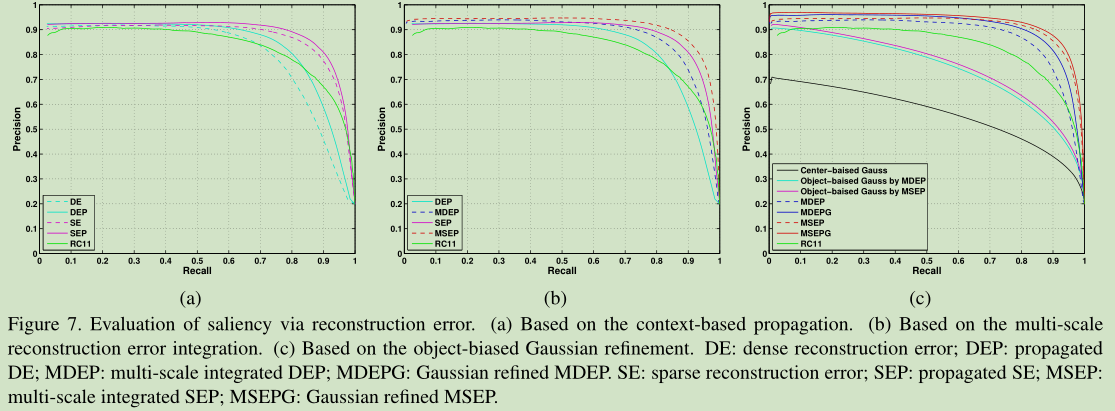
- 第三, 利用多尺度重建误差的整合计算像素级显著性,并利用目标偏置高斯模型进行细化。
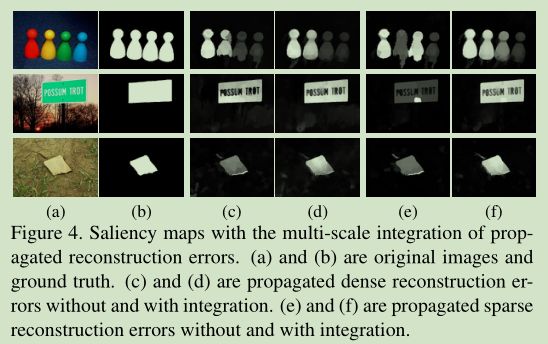
- 多尺度重建误差整合
- 为了处理尺度问题, 这里生成了Ns个不同尺度的超像素. 在不同尺度计算密集和稀疏重建误差. 集成多尺度重建误差.

- 主要基于此计算像素级重建误差.
- 这里使用像素特征f与超像素特征(也就是超像素内部的像素偏离超像素均值的程度的倒数作为权重)来对于不同尺度超像素重建误差 epsilon 分数加权.
- 利用像素z与其对应超像素n(s)的相似性作为权重, 对多尺度重建误差进行平均. 某一尺度f与x越是相似, 则E中对应尺度的重建误差比例越大.
- 多尺度重建误差整合
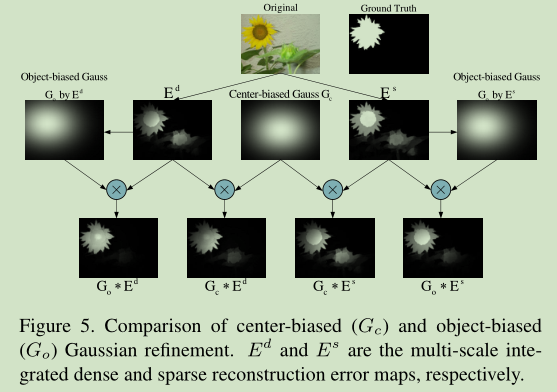
- 目标偏置高斯模型细化
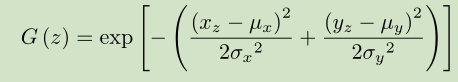
- 这里使用了中心先验, 但是为了避免该方法原始实现具有基于中心偏置的假设前提, 文章使用了由7的像素误差导出的目标中心.

- 使用这里确定的高斯模型与原本的像素级重建误差集成, 得到显著性值. 下图有一个不同尝试的比较结果.
- 第四, 利用贝叶斯公式对基于稠密和稀疏重构误差的显著性度量进行整合。
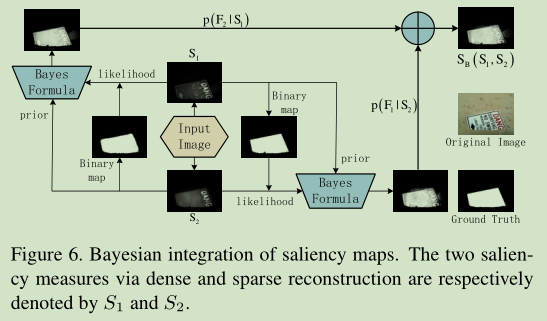
- 使用一个显著性图作为先验(Si), 一个来计算似然(Sj), 如此组合两个显著性图(i \= j).
- 对于前者Si, 使用显著性图的均值进行二值化, 设定为Fi和Bi
- 对于后者Sj,
 , NFi表示的是前景Fi包含像素数量, NBi表示背景Bi包含的像素数量. NbFi(Sj(z))表示的是对于那些特征Sj(z)属于前景Fi的特征集合bFi(Sj(z))中的像素数量.
, NFi表示的是前景Fi包含像素数量, NBi表示背景Bi包含的像素数量. NbFi(Sj(z))表示的是对于那些特征Sj(z)属于前景Fi的特征集合bFi(Sj(z))中的像素数量. 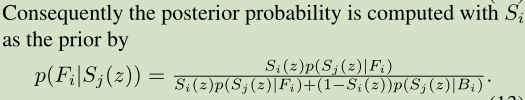
- 相似的还会计算关于Si的后验概率
 使用两个后验概率组合得到最终的显著性图.
使用两个后验概率组合得到最终的显著性图.
参数设置

实验测试
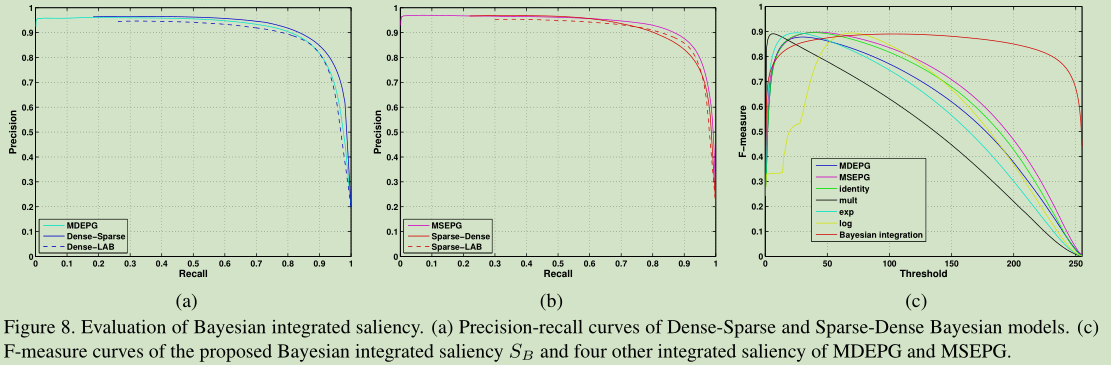
- 由图8(a)可知,以秘籍重建的显著性为先验,基于稀疏重建的似然性(密集-稀疏)结果要比CIELab颜色空间(密集-lab)的结果更准确。
- 将基于稀疏重建的显著性映射作为先验,基于密集重建(稀疏-密集)的似然性结果与CIELab颜色空间(稀疏-lab)的相似,如图8(b)所示。
- 尽管S-D/S-L(后验)有着相对于先验(MSEPG)较低的准确率(预测为真的范围大了, 噪声增加), 但是召回率被提升了(预测为真的范围更趋近于真值范围). 这也表明, 在某些情况下,似然概率可能会引入被先验去除了的噪声,从而导致比先验更差的后验。
也尝试了其他的集成方法:

5: A. Borji, D. N. Sihite, and L. Itti. Salient object detection: A benchmark. In ECCV, 2012.
8c可见, 提出的方法最好. 这里使用了两个结果的乘积, 可以思考:
对于两个F曲线较低的方法的结果, 乘积是否可以对F提升很多?
总结
本文提出了一种基于背景模板的密集稀疏重建显著性检测算法。
设计了一种基于上下文的误差传播机制。像素级的显著性,然后计算一个集成的多尺度重建误差,然后对象偏置高斯细化。
为了将这两种显著性映射通过密集和稀疏重构相结合,我们引入了一种比传统集成策略性能更好的贝叶斯集成方法。
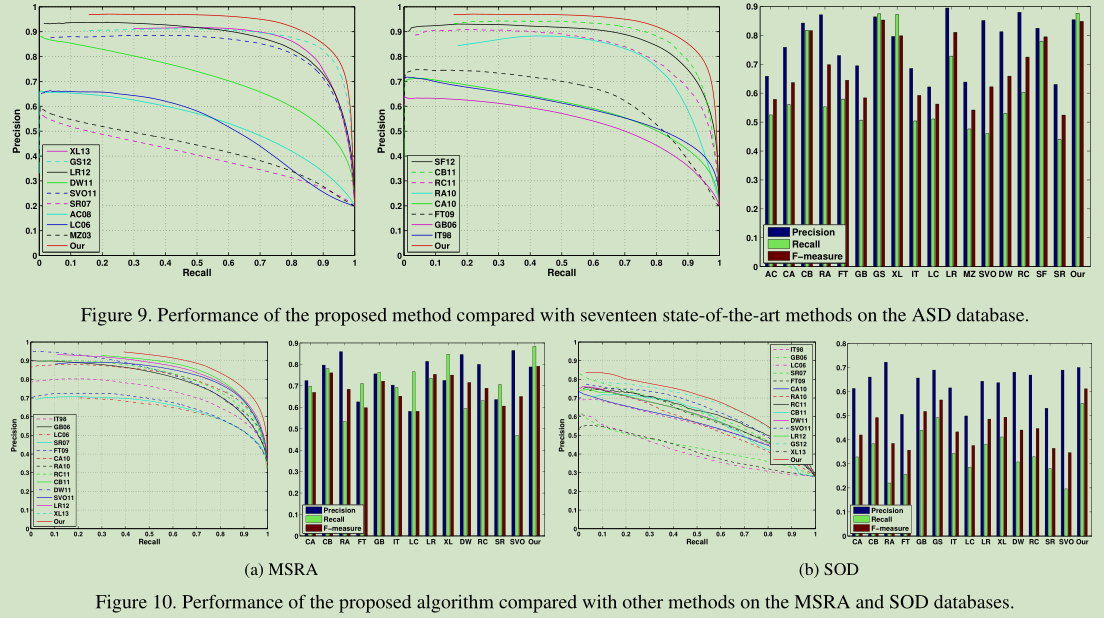
实验结果表明,与现有的17种模型相比,该方法有较大的改进。
参考链接

若有收获,就点个赞吧
0 人点赞
