
本文不是按照之前的论文那样, 考虑显著性目标与背景之间的对比度, 而是通过使用流形排序方法, 来使用前景/背景线索对图像元素(像素或者区域)进行排序.
在这种方法中, 图像元素的显著性是基于它们与给定种子/查询的相关性来定义的.
我们将图像表示为一个以超像素为节点的闭环图。这些节点的排序是基于与背景和前景查询的相似性,基于关联矩阵(affinity matrices)。采用两阶段的显著性检测方法,有效地提取背景区域和前景显著目标。
同时本文也构建了一个大规模的数据集, 来进行显著性检测的测试评估.
主要内容
本篇论文主要专注的是一种由下而上的方法.
主要相关的几个方法结论或者观察.
- 显著目标检测算法通常生成边界框、二值前景和背景分割或显著性图表示每个像素的显著性似然。之前的大多数方法都是通过测量局部的中心和周围的对比度和整个图像上特征的罕见度来测量显著性。相反,Gopalakrishnan等人将目标检测问题表述为图形上的二值分割或标记任务。最显著的种子(seeds)和数个背景种子(seeds)通过在完全图(complete graph)和k正则图(k-regular graph)上的随机漫步(random walks)的行为来识别.
- 完全图: 是一个简单的无向图,其中每对不同的顶点之间都恰连有一条边相连.
- k正则图: 每个节点的度都是一样的.(也就是连接的节点数量是一样的.)
- 最近提出了一种使用背景先验的方法. 主要的观察是两个背景区域的距离是要小于一个背景和一个显著性目标之间的距离的. 基于此准则,将节点标记任务(显著性对象或背景)描述为能量最小化问题。(这个结论, 在文章后期是要用其进一步改进后的结论.)
- Y. C. Wei, F. Wen, W. J. Zhu, and J. Sun. Geodesic saliency using background priors. In ECCV, 2012
- 可以观察到, 背景通常具有局部或者全局的和四个边界中的每个的外观连通性, 前景表现出外观的连贯性和一致性.
这篇文章中, 使用这些线索基于超像素的排序来计算像素的显著性.
论文方法流程
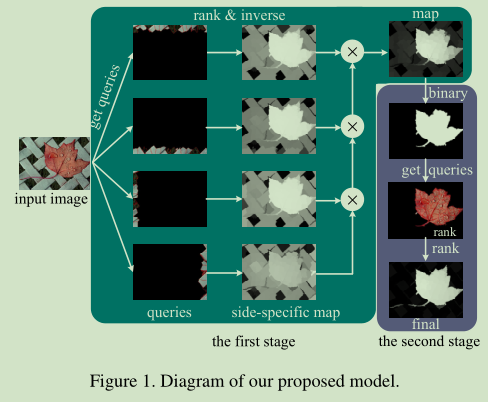
- 构造以超像素为节点的闭环图
- 将显著性检测问题建模为一个流形排序问题
- 使用一个两阶段算法来进行图的标记, 两个阶段有些流程类似, 但是实际上正好是个互补的过程.
- 第一阶段, 利用边界先验, 利用图像每一边的节点作为标记的背景查询, 对于每个标记的结果计算节点的显著性, 基于它们与这些查询的相关性作为背景标签. 四个标记图然后用来生成一副显著性图.
- 第二阶段, 对上一阶段的结果进行二值分割, 将标记的前景节点作为显著性查询. 每个节点的显著性基于其与前景查询的相关性来计算. 以获得最终的显著性图.
从这个流程中, 可以关注几个点:
- 闭环图:
- 什么是闭环图?
- 为什么是闭环图?
- 流行排序问题:
- 什么是流行排序问题?
- 为什么要建模成流行排序问题?
- 如何使用流行排序解决显著性检测问题?
基于图结构的流行排序问题
基于图的流形排序, 被描述为: 给定一个节点作为查询. 剩余节点基于与这个给定节点之间的相关性来进行排序. 目标是学习一个定义了未标记节点与查询之间的相关性的流形函数.
也就是说, 文中的基于图的流行排序实际上就是通过一个流行函数定义未标记节点与查询节点之间的相关性. 若是有了这个与前景或者背景查询节点的相关性, 就可以用来排序, 与前景相关性高的就可以用其表示显著性, 与背景相关性高的, 就可以用其表示非显著性(1-f可以用来表示显著性).(具体细节见后).
论文[D. Zhou, J. Weston, A. Gretton, O. Bousquet, and B. Scholkopf. Ranking on data manifolds. In NIPS, 2004]提出了一种利用数据(如图像)固有流形结构进行图形标签排序的方法.
为什么要建模成流行排序问题?
为了充分捕捉图的内在结构信息,并在图的标注中加入局部分组线索(local grouping),我们利用流形排序技术(manifold ranking)来学习排序函数,这对于学习最优亲和矩阵是至关重要的.
对于该问题的建模如下:

主要是将映射  表示为一个排序问题. 赋予一个排序值到每个点数据点
表示为一个排序问题. 赋予一个排序值到每个点数据点  上, 汇总得到的
上, 汇总得到的 ,作为最终得到的排序值.
,作为最终得到的排序值.
将图片表示为一个无向图结构, 节点为超像素, 而边的权重总体表示为关联矩阵  , 对应的图所对应的度矩阵表示为
, 对应的图所对应的度矩阵表示为  这里的d对应于W特定行之和.
这里的d对应于W特定行之和.  反映了和特定节点连接的其他所有节点边的权重之和. 这个也在一定程度上可以认为是一种节点之间的相关程度/关联性. 这里计算显著性就是用它.
反映了和特定节点连接的其他所有节点边的权重之和. 这个也在一定程度上可以认为是一种节点之间的相关程度/关联性. 这里计算显著性就是用它.
是否可以表示为有向图, 这样可以表示更为丰富的信息, 比如特征之间的依赖性, 不过感觉这个想法不适合与这样的自下而上的传统方法, 因为这种有向的依赖关系, 对应的特征应该是更为高级的语义信息. 这里让我想到了分割的一个结构, DD-RNN和DAG-RNN
为了找到最好的一个排序, 这里将这个优化问题表述为:

从式子1可以了解到
- 这个式子的第一项, 被认为是一个平滑约束, 也就是说, 一个好的排序函数不应该在相邻点之间变化太多(平滑度约束). 也就是在相邻节点(w对应会很大, 导致第一项的作用影响比较大)之间, 二者的f差异不大.
- 这个式子的第二项, 被认为是一个拟合约束, 也就是说, 一个好的排序函数不应该与初始查询赋值情况(拟合约束)相差太多. 这一项实际上限制了, f应该趋近于此时查询点的分配情况.
最小解, 利用导数求解, 得到结果如下, 式子2是最终的排序结果对应的函数. 而式子3使用的是未标准化的拉普拉斯矩阵.

具体参数可见前面图片的定义. 实际使用的是式子3. 这里是测试比较:
The figure shows that the ranking results with the unnormalized Laplacian matrix are better, and used in all the experiments.
这里有一点, 文中没有细说, 最终的排序是对f中的元素进行排序, 还是说f中的元素实际上已经排好序了 (这里划掉的部分, 可以如此理解并推翻: f的索引实际上与y的索引是对应的, 也就是说, f表示的是特定节点到所有查询点之间的相关性之和. 所以说, 如果索引固定, 那么这里应该是基于得到的f来计算对应的显著性值.)
实际上这里说是排序, 其实并没有进行排序操作, 只是利用这个优化问题得到的相关性解, 来进行显著性值的计算. 虽然这个值在一定程度上反映了显著性的排序情况, 但是并没有具体用到排序的操作
关于式子2, 3. 二者的差别, 前者是用的是标准化参数, 后者使用的是更为直接的参数. 而在计算显著性的时候, 是需要进行标准化的, 所以使用3式的时候, 还是要进行标准化处理的. .
这里的标准化是将数据放缩到了0~1范围, 可以看下面的代码示例:
bsalt=optAff*Yt;bsalt=(bsalt-min(bsalt(:)))/(max(bsalt(:))-min(bsalt(:)));

传统的排序问题, 查询是要手动用真实标记的. 然而提出的算法选择的查询, 一些可能被标错了. 因此需要对每个查询计算一个置信度(也就是显著性值), 这个用它的排序得分, 这是通过其他查询计算出来的(排除自身).
最后, 设定A中的对角元素为0. 这个看似无关紧要的过程对最终结果有很大的影响, 这里如果没有设置A的对角元素为0来进行计算每一个查询的显著性的时候, 结果会包含查询与自身的相关性, 这个通常很大(是同一行其他项的和的负数), 会严重抑制其他查询对于排序得分的贡献.
因为度矩阵D的对角元素是仿射矩阵W的每行元素的和. 如果D不设定为0, 那么差值之后, 就会减掉自身的影响.
关于权重w, 有如下设定:

节点之间的权重使用颜色空间的距离的钟形函数来进行建模. 方差项用来控制权重的强度. 色彩距离(差异)越大, 赋予的权重也就越小.
图结构的划分

这里提到了两点:
- 无向图
- SLIC算法: https://www.cnblogs.com/supersponge/p/6546082.html
- 算法大致思想是这样的,将图像从RGB颜色空间转换到CIE-Lab颜色空间,对应每个像素的(L,a,b)颜色值和(x,y)坐标组成一个5维向量V[l, a, b, x, y],两个像素的相似性即可由它们的向量距离来度量,距离越大,相似性越小。
- 算法首先生成K个种子点,然后在每个种子点的周围空间里搜索距离该种子点最近的若干像素,将他们归为与该种子点一类,直到所有像素点都归类完毕。然后计算这K个超像素里所有像素点的平均向量值,重新得到K个聚类中心,然后再以这K个中心去搜索其周围与其最为相似的若干像素,所有像素都归类完后重新得到K个超像素,更新聚类中心,再次迭代,如此反复直到收敛。(类似与k均值聚类)
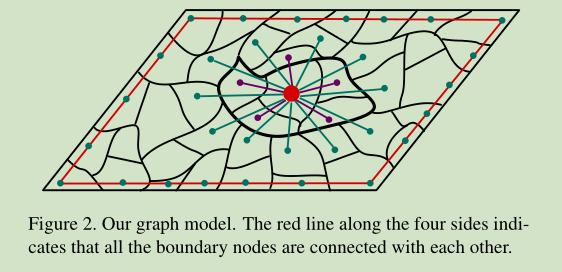
由于相邻节点可能具有相似的外观和显著性值,使用k-regular图来利用空间关系。
- 首先,每个节点不仅连接到与其相邻的节点,还连接到与其相邻节点共享公共边界的节点(参见图2)。
- 通过扩展具有相同k度的节点连接范围,我们有效地利用了局部平滑线索。
- 其次,我们强制连接图像四边的节点,即任何一对边界节点都被认为是相邻的。
- 因此,我们将该图表示为闭环图。这种闭环约束可以显著提高算法的性能,因为它可以减小相似超像素的测地线距离,从而改善了排序结果.
- 当显著对象出现在图像边界附近或某些背景区域不相同时,这些闭环约束很有效。

通过对边的约束,可以看出构造图是稀疏连接的。也就是说,关联矩阵  的大部分项都是零。
的大部分项都是零。
这里为什么是稀疏连接的? 虽然从结果上来看确实是稀疏的. 可见参考链接里的
SLIC算法测试, 里面有一些测试. 这里可以看python代码计算W和D的部分, 有一段:
W = sp.exp(-1*W / self.weight_parameters['delta'])# 归属于不同超像素的像素之间, 不相邻的赋予0W[adj.astype(np.bool)] = 0这里是反着取得邻接矩阵, 所以, 不相邻的部分对应的关联矩阵W是要置0的. 而这里的邻接矩阵, 在这里指定的关于邻接的约束, 导致大部分节点之间是不相邻的. 所以这里adj是稀疏的, 导致W也是一个稀疏矩阵.
使用背景查询排序
根据早期关于视觉显著性[17]的注意理论,我们将图像边界上的节点作为背景种子,即,将标记的数据(查询样本)对所有其他区域的相关性进行排序。具体地说,我们使用边界先验构造了四个显著性图,然后将它们集成到最终的映射中,这被称为分离/组合(SC)方法.

以图像顶部边界为例,使用这一侧的节点作为查询,其他节点作为未标记的数据。因此, 指示向量y被给定, 所有的节点是基于式子3中的f∗排名, 这是一个N维向量(N是图的节点总数)。此向量中的每个元素表示节点与背景查询节点的相关性, 其关于1的补数是显著性测量.
类似的计算其他三边的情况. 注意, 实际上, 在这个过程中, 矩阵D, W只需要计算一次, 而y都是可以确定的.
最后进行集成:

使用相乘的方法来进行集成. 这里有点类似于同一年的Graph-Regularized Saliency Detection With Convex-Hull-Based Center Prior文章中集成对比度先验与基于凸包的中心先验的方法.
- 这种通过相乘的方式来进行集成的方式来自哪里?
- 还有没有其他的集成的方式?
使用SC方法的主要的考虑是四边同时使用的效果不好, 主要体现在两个方面:
- 四边上的超像素之间互相可能并不相似, 不可合并, 同时使用通常不是最优.
- 四边同时使用对于查询的标注准确度要求较高, 而拆分开, 可转圜的余地较大, 容错性也较好.
对比结果如下图:

使用前景查询排序
进一步基于前景查询排序来优化结果, 主要是为了应对目标出现在靠近图像边缘的情况.
第一阶段的显著性映射是二值分割的(即,突出的前景和背景), 使用一个自适应阈值,这有助于选择节点的前景显著性目标作为查询节点。我们期望选择的查询尽可能地覆盖突出的对象区域(即)。因此,阈值被设置为整个显著性映射的平均显著性。
类似的, 这里则直接可以使用与查询节点计算相关性来获得显著性值:

这里就不用互补计算了, 因为这里是算的与前景的相关性.
显著目标区域通常是相对紧凑的(在空间分布方面)和均匀的外观(在特征分布方面),而背景区域正好相反。换句话说,对象内部的相关性(即,显著对象的两个节点)在统计上远大于对象背景和背景内相关性,可以从关联矩阵A中推断。为了进一步显示这个现象, 文章从数据集真值中, 进行了测试:
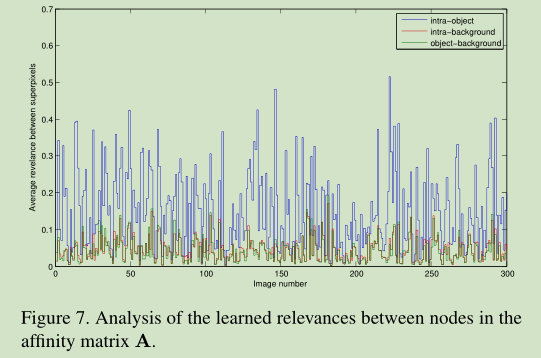
To show this phenomenon, we compute the average intra-object, intra-background and object-background relevance values in A for each of the 300 images sampled from a dataset with ground truth labels.
从真值标记统计出来, 明显可以看出来, 目标节点到所有真值的显著性查询的相关性之和要大于背景节点到所有查询的相关性之和. 这个是最优状态的A的结果对应的解释.
但是这个能够说明这个方法中的背景是可以被有效抑制的么? 可以的.
因为A是最终的的f的一个仿射变换矩阵, 其中的值对应着f的结果, 也就是对应着最终的显著性结果.
这里用实验解释了目标内部相关性是最大的. 而这个结论在使用前景查询进行优化提升的时候, 在一定程度上可以改善已经预测的显著性区域. 因为一般显著性目标对象区域更为紧凑, 均匀. 在计算距离的时候, 周围的一致性更强, 鉴于色彩空间加权的作用, 最终与相关性值会更高一些. 而先前错误标记的部分, 相对而言值更小了.
A是基于原始图像的色彩的. 从一开始就是个定值. 查询的选择, 影响的是y.
算法流程总结

主要流程:
- 超像素构建, 得到D和W矩阵.
- 获得A矩阵, 并将其对角元素设定为0.
- 第一阶段: 四边分别构建向量y, 计算对应的显著性图在进行集成得到第二阶段的输入.
- 第二阶段: 二分割得到前景查询和y, 计算最终的显著性图.
- 输出最终的显著性图.
参考代码
https://github.com/huchuanlu/13_4/blob/master/demo.m https://github.com/ruanxiang/mr_saliency/blob/master/MR/MR.py(主要从这里入手理解), python版本的实现与matlab实现细节有些差异, 主要是在于里面对于第一阶段的计算中, python版本是反着来的, 它把背景(边界)的指示值设定为了1, 最后集成的时候又用1算了个补数. 而matlab的流程设定和论文是一致的.
% Demo for paper "Saliency Detection via Graph-Based Manifold Ranking"% by Chuan Yang, Lihe Zhang, Huchuan Lu, Ming-Hsuan Yang, and Xiang Ruan% To appear in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2013), Portland, June, 2013.clear all;addpath('./others/');%%------------------------set parameters---------------------%%theta=10; % control the edge weightalpha=0.99;% control the balance of two items in manifold ranking cost functionspnumber=200;% superpixel numberimgRoot='./test/';% test image pathsaldir='./saliencymap/';% the output path of the saliency mapsupdir='./superpixels/';% the superpixel label file pathmkdir(supdir);mkdir(saldir);imnames=dir([imgRoot '*' 'jpg']);% 迭代图片for ii=1:length(imnames)disp(ii);imname=[imgRoot imnames(ii).name];[input_im,w]=removeframe(imname);% run a pre-processing to remove the image frame[m,n,k] = size(input_im);%%----------------------generate superpixels使用SLIC方法来生成超像素--------------------%%imname=[imname(1:end-4) '.bmp'];% the slic software support only the '.bmp' imagecomm=['SLICSuperpixelSegmentation' ' ' imname ' ' int2str(20) ' ' int2str(spnumber) ' ' supdir];system(comm);spname=[supdir imnames(ii).name(1:end-4) '.dat'];% 获得超像素标记矩阵superpixels=ReadDAT([m,n],spname); % superpixel label matrixspnum=max(superpixels(:));% the actual superpixel number%%----------------------design the graph model 计算聚拢的像素在lab颜色空间中的平均值--------------------------%%% compute the feature (mean color in lab color space)% for each node (superpixels)input_vals=reshape(input_im, m*n, k);rgb_vals=zeros(spnum,1,3);inds=cell(spnum,1);for i=1:spnuminds{i}=find(superpixels==i);rgb_vals(i,1,:)=mean(input_vals(inds{i},:),1);endlab_vals = colorspace('Lab<-', rgb_vals);seg_vals=reshape(lab_vals,spnum,3);% feature for each superpixel% get edges 获取节点之间的边adjloop=AdjcProcloop(superpixels,spnum);edges=[];for i=1:spnumindext=[];ind=find(adjloop(i,:)==1);for j=1:length(ind)indj=find(adjloop(ind(j),:)==1);indext=[indext,indj];endindext=[indext,ind];indext=indext((indext>i));indext=unique(indext);if(~isempty(indext))ed=ones(length(indext),2);ed(:,2)=i*ed(:,2);ed(:,1)=indext;edges=[edges;ed];endend% compute affinity matrix 计算关联矩阵, 表示了各种权重关系weights = makeweights(edges,seg_vals,theta);W = adjacency(edges,weights,spnum);% learn the optimal affinity matrix (eq. 3 in paper) 学习最优的关联矩阵% 这里是设定了一个稀疏矩阵.% 使用i=1:spnum和j=1:spnum指定的坐标, 赋予特定的值dd, 也就是D(i(k), j(k))=dd(k)% 得到的结果中,dd = sum(W); D = sparse(1:spnum,1:spnum,dd); clear dd;optAff =(D-alpha*W)\eye(spnum);mz=diag(ones(spnum,1));mz=~mz;optAff=optAff.*mz;%%-----------------------------stage 1--------------------------%%% compute the saliency value for each superpixel% with the top boundary as the queryYt=zeros(spnum,1);bst=unique(superpixels(1,1:n));Yt(bst)=1;bsalt=optAff*Yt;bsalt=(bsalt-min(bsalt(:)))/(max(bsalt(:))-min(bsalt(:)));bsalt=1-bsalt;% downYd=zeros(spnum,1);bsd=unique(superpixels(m,1:n));Yd(bsd)=1;bsald=optAff*Yd;bsald=(bsald-min(bsald(:)))/(max(bsald(:))-min(bsald(:)));bsald=1-bsald;% rightYr=zeros(spnum,1);bsr=unique(superpixels(1:m,1));Yr(bsr)=1;bsalr=optAff*Yr;bsalr=(bsalr-min(bsalr(:)))/(max(bsalr(:))-min(bsalr(:)));bsalr=1-bsalr;% leftYl=zeros(spnum,1);bsl=unique(superpixels(1:m,n));Yl(bsl)=1;bsall=optAff*Yl;bsall=(bsall-min(bsall(:)))/(max(bsall(:))-min(bsall(:)));bsall=1-bsall;% combinebsalc=(bsalt.*bsald.*bsall.*bsalr);bsalc=(bsalc-min(bsalc(:)))/(max(bsalc(:))-min(bsalc(:)));% 这时 ,bsalc是第一阶段最终的显著性标记% assign the saliency value to each pixel 为每个像素分配显著性值tmapstage1=zeros(m,n);for i=1:spnumtmapstage1(inds{i})=bsalc(i);endtmapstage1=(tmapstage1-min(tmapstage1(:)))/(max(tmapstage1(:))-min(tmapstage1(:)));mapstage1=zeros(w(1),w(2));mapstage1(w(3):w(4),w(5):w(6))=tmapstage1;mapstage1=uint8(mapstage1*255);outname=[saldir imnames(ii).name(1:end-4) '_stage1' '.png'];imwrite(mapstage1,outname);%%----------------------stage2-------------------------%%% binary with an adaptive threhold (i.e. mean of the saliency map) 自适应阈值二值化, 阈值被设置为整个显著图上的平均显著性th=mean(bsalc);bsalc(bsalc<th)=0;bsalc(bsalc>=th)=1;% compute the saliency value for each superpixelfsal=optAff*bsalc;% assign the saliency value to each pixeltmapstage2=zeros(m,n);for i=1:spnumtmapstage2(inds{i})=fsal(i);endtmapstage2=(tmapstage2-min(tmapstage2(:)))/(max(tmapstage2(:))-min(tmapstage2(:)));mapstage2=zeros(w(1),w(2));mapstage2(w(3):w(4),w(5):w(6))=tmapstage2;mapstage2=uint8(mapstage2*255);outname=[saldir imnames(ii).name(1:end-4) '_stage2' '.png'];imwrite(mapstage2,outname);end
###################################################################### Author:## Xiang Ruan## httpr://ruanxiang.net## ruanxiang@gmail.com## License:## GPL 2.0## NOTE: the algorithm itself is patented by OMRON, co, Japan## my previous employer, so please do not use the algorithm in## any commerical product## Version:## 1.0#### ----------------------------------------------------------------## A python implementation of manifold ranking saliency## Usage:## import MR## import matplotlib.pyplot as plt## mr = MR.MR_saliency()## sal = mr.saliency(img)## plt.imshow(sal)## plt.show()#### Check paper.pdf for algorithm details## I leave all th parameters open to maniplating, however, you don't## have to do it, default values work pretty well, unless you really## know what you want to do to modify the parametersimport scipy as spimport numpy as npimport cv2from skimage.segmentation import slicfrom skimage.segmentation import mark_boundariesfrom skimage.data import camerafrom scipy.linalg import invimport matplotlib.pyplot as pltcv_ver = int(cv2.__version__.split('.')[0])_cv2_LOAD_IMAGE_COLOR = cv2.IMREAD_COLOR if cv_ver >= 3 else cv2.CV_LOAD_IMAGE_COLORclass MR_saliency(object):"""Python implementation of manifold ranking saliency"""weight_parameters = {'alpha':0.99,'delta':0.1}superpixel_parameters = {'segs':200,'compactness':10,'max_iter':10,'sigma':1,'spacing':None,'multichannel':True,'convert2lab':None,'enforce_connectivity':False,'min_size_factor':0.5,'max_size_factor':3,'slic_zero':False}binary_thre = Nonedef __init__(self, alpha = 0.99, delta = 0.1,segs = 200, compactness = 10,max_iter = 10, sigma = 1,spacing = None, multichannel = True,convert2lab = None, enforce_connectivity = False,min_size_factor = 0.5, max_size_factor = 3,slic_zero = False):self.weight_parameters['alpha'] = alphaself.weight_parameters['delta'] = deltaself.superpixel_parameters['segs'] = segsself.superpixel_parameters['compactness'] = compactnessself.superpixel_parameters['max_iter'] = max_iterself.superpixel_parameters['sigma'] = sigmaself.superpixel_parameters['spacing'] = spacingself.superpixel_parameters['multichannel'] = multichannelself.superpixel_parameters['convert2lab'] = convert2labself.superpixel_parameters['enforce_connectivity'] = enforce_connectivityself.superpixel_parameters['min_size_factor'] = min_size_factorself.superpixel_parameters['max_size_factor'] = max_size_factorself.superpixel_parameters['slic_zero'] = slic_zerodef saliency(self,img):"""主要的处理函数, 反映了算法的主要流程"""# read imageimg = self.__MR_readimg(img)# superpixel# labels得到的是什么: 对于各个像素的超像素划分的标记labels = self.__MR_superpixel(img)# affinity matrixaff = self.__MR_affinity_matrix(img,labels)# first roundfirst_sal = self.__MR_first_stage_saliency(aff,labels)# second roundfin_sal = self.__MR_final_saliency(first_sal, labels,aff)return self.__MR_fill_superpixel_with_saliency(labels,fin_sal)def __MR_superpixel(self,img):"""超像素划分"""return slic(img,self.superpixel_parameters['segs'],self.superpixel_parameters['compactness'],self.superpixel_parameters['max_iter'],self.superpixel_parameters['sigma'],self.superpixel_parameters['spacing'],self.superpixel_parameters['multichannel'],self.superpixel_parameters['convert2lab'],self.superpixel_parameters['enforce_connectivity'],self.superpixel_parameters['min_size_factor'],self.superpixel_parameters['max_size_factor'],self.superpixel_parameters['slic_zero'])def __MR_superpixel_mean_vector(self,img,labels):"""返回关于关于每个超像素的三个颜色通道的均值."""s = sp.amax(labels)+1vec = sp.zeros((s,3)).astype(float)# 每个超像素的得到的颜色均值是三个值, 三个通道各自一个均值.for i in range(s):mask = labels == i# img[mask]表示图像上被标记为同一个超像素的像素值super_v = img[mask].astype(float)mean = sp.mean(super_v,0)vec[i] = meanreturn vecdef __MR_affinity_matrix(self,img,labels):"""获得关联矩阵A"""W,D = self.__MR_W_D_matrix(img,labels)# 获得矩阵Aaff = inv(D-self.weight_parameters['alpha']*W)aff[sp.eye(sp.amax(labels)+1).astype(bool)] = 0.0 # diagonal elements to 0return affdef __MR_saliency(self,aff,indictor):"""计算A*y"""return sp.dot(aff,indictor)def __MR_W_D_matrix(self,img,labels):"""获得矩阵W和D"""s = sp.amax(labels)+1vect = self.__MR_superpixel_mean_vector(img,labels)# 获取超像素之间的邻接矩阵, 这里邻接关系对应着Falseadj = self.__MR_get_adj_loop(labels)W = sp.spatial.distance.squareform(sp.spatial.distance.pdist(vect))W = sp.exp(-1*W / self.weight_parameters['delta'])# 归属于不同超像素的像素之间, 不相邻的赋予0W[adj.astype(np.bool)] = 0D = sp.zeros((s,s)).astype(float)for i in range(s):D[i, i] = sp.sum(W[i])return W,Ddef __MR_boundary_indictor(self,labels):"""这里将四个边界像素所在超像素指示值都设定为0"""s = sp.amax(labels)+1up_indictor = (sp.ones((s,1))).astype(float)right_indictor = (sp.ones((s,1))).astype(float)low_indictor = (sp.ones((s,1))).astype(float)left_indictor = (sp.ones((s,1))).astype(float)upper_ids = sp.unique(labels[0,:]).astype(int)right_ids = sp.unique(labels[:,labels.shape[1]-1]).astype(int)low_ids = sp.unique(labels[labels.shape[0]-1,:]).astype(int)left_ids = sp.unique(labels[:,0]).astype(int)up_indictor[upper_ids] = 0.0right_indictor[right_ids] = 0.0low_indictor[low_ids] = 0.0left_indictor[left_ids] = 0.0return up_indictor,right_indictor,low_indictor,left_indictordef __MR_get_adj_loop(self, labels):"""获取超像素的邻接矩阵"""# 总的超像素数量, amax方法会返回最大的类别值s = sp.amax(labels) + 1# 超像素邻接矩阵预定义adj = np.ones((s, s), np.bool)# 对图像的各个像素的超像素标记进行遍历for i in range(labels.shape[0] - 1):for j in range(labels.shape[1] - 1):# 下面的四个判断, 检查了以(i,j)为左上角的一个2x2像素区域四个像素之间的连通关系if labels[i, j] != labels[i+1, j]:# (i,j)与(i+1,j)不位于同一个超像素中, 就在超像素邻接矩阵中对应位置置为False# 注意, 有两个位置, 因为邻接矩阵可以表示有向图.adj[labels[i, j] , labels[i+1, j]] = Falseadj[labels[i+1, j], labels[i, j]] = Falseif labels[i, j] != labels[i, j + 1]:# (i,j)与(i,j+1)adj[labels[i, j] , labels[i, j+1]] = Falseadj[labels[i, j+1], labels[i, j]] = Falseif labels[i, j] != labels[i + 1, j + 1]:# (i,j)与(i+1,j+1)adj[labels[i, j] , labels[i+1, j+1]] = Falseadj[labels[i+1, j+1], labels[i, j]] = Falseif labels[i + 1, j] != labels[i, j + 1]:# (i+1,j)与(i,j+1)adj[labels[i+1, j], labels[i, j+1]] = Falseadj[labels[i, j+1], labels[i+1, j]] = False# 这里循环结束后, 得到的adj中的True表示的是图像像素的超像素标记并不是相邻的.(这两个超像素的# 像素之间并不相邻), 而对应的False表示的是超像素的元素之间是相邻的.# 这里确定了四个边上的像素对应的超像素标记, 这里会查找特定向量的唯一超像素标记的集合upper_ids = sp.unique(labels[0,:]).astype(int)right_ids = sp.unique(labels[:,labels.shape[1]-1]).astype(int)low_ids = sp.unique(labels[labels.shape[0]-1,:]).astype(int)left_ids = sp.unique(labels[:,0]).astype(int)# np.append会拼接指定的向量. 四个边拼接起来, 得到的bd表示被认为是背景的超像素标记bd = np.append(upper_ids, right_ids)bd = np.append(bd, low_ids)bd = sp.unique(np.append(bd, left_ids))for i in range(len(bd)):for j in range(i + 1, len(bd)):# 任意两个包含边界像素的超像素, 对应的邻接关系也被设置为Falseadj[bd[i], bd[j]] = Falseadj[bd[j], bd[i]] = False# 这里的循环结束后, adj表示的是所有包含边界像素的超像素之间都认为是元素相邻的, 这里设定为Falsereturn adjdef __MR_fill_superpixel_with_saliency(self,labels,saliency_score):"""为各个超像素区域赋予对应的显著性得分"""sa_img = labels.copy().astype(float)for i in range(sp.amax(labels)+1):mask = labels == isa_img[mask] = saliency_score[i]return cv2.normalize(sa_img,None,0,255,cv2.NORM_MINMAX)def __MR_first_stage_saliency(self,aff,labels):"""获取边界查询(种子)对应的图得分."""# 边界指示对应为0up,right,low,left = self.__MR_boundary_indictor(labels)# 计算的是节点到非边界元素的相关性的补数, 也就是非显著性图up_sal = 1-self.__MR_saliency(aff,up) # sp.dot(aff, up)up_img = self.__MR_fill_superpixel_with_saliency(labels,up_sal)right_sal = 1-self.__MR_saliency(aff,right)right_img = self.__MR_fill_superpixel_with_saliency(labels,right_sal)low_sal = 1-self.__MR_saliency(aff,low)low_img = self.__MR_fill_superpixel_with_saliency(labels,low_sal)left_sal = 1-self.__MR_saliency(aff,left)left_img = self.__MR_fill_superpixel_with_saliency(labels,left_sal)# 使用非显著性图乘积的补数来作为显著性图return 1-up_img*right_img*low_img*left_imgdef __MR_second_stage_indictor(self,saliency_img_mask,labels):s = sp.amax(labels)+1# get ids from labels imageids = sp.unique(labels[saliency_img_mask]).astype(int)# indictorindictor = sp.zeros((s,1)).astype(float)indictor[ids] = 1.0return indictordef __MR_final_saliency(self,integrated_sal, labels, aff):# get binary imageif self.binary_thre == None:thre = sp.median(integrated_sal.astype(float))mask = integrated_sal > thre# get indicatorind = self.__MR_second_stage_indictor(mask,labels)return self.__MR_saliency(aff,ind)# read imagedef __MR_readimg(self,img):if isinstance(img,str): # a image pathimg = cv2.imread(img, _cv2_LOAD_IMAGE_COLOR)img = cv2.cvtColor(img,cv2.COLOR_RGB2LAB).astype(float)/255h = 100w = int(float(h)/float(img.shape[0])*float(img.shape[1]))return cv2.resize(img,(w,h))
参考链接
- 拉普拉斯矩阵: https://github.com/lartpang/Machine-Deep-Learning/blob/master/图像分割/Deep Propagation Based Image Matting翻译(2018).md#拉普拉斯矩阵.md#%E6%8B%89%E6%99%AE%E6%8B%89%E6%96%AF%E7%9F%A9%E9%98%B5)
- SLIC算法: https://www.cnblogs.com/supersponge/p/6546082.html
- SLIC算法测试: https://github.com/lartpang/mypython/blob/master/2019-2-20SLIC算法测试/SLIC.ipynb

若有收获,就点个赞吧
0 人点赞
