
从摘要理解论文
For the past ten years, CNN has reigned supreme in the world of computer vision, but recently, Transformer is on the rise. However, the quadratic computational cost of self-attention has become a severe problem of practice.
这里指出了self-attention结构较高的计算成本。
There has been much research on architectures without CNN and self-attention in this context. In particular, MLP-Mixer is a simple idea designed using MLPs and hit an accuracy comparable to the Vision Transformer.
引出本文的核心,MLP架构。
However, the only inductive bias in this architecture is the embedding of tokens.
在MLP架构中,唯一引入归纳偏置的位置也就是token嵌入的过程。 这里提到归纳偏置在我看来主要是为了向原始的纯MLP架构中引入更多的归纳偏置来在视觉任务上实现更好的训练效果。估计本文又要从卷积架构中借鉴思路了。
Thus, there is still a possibility to build a non-convolutional inductive bias into the architecture itself, and we built in an inductive bias using two simple ideas.
这里主要在强调虽然引入了归纳偏置,但并不是通过卷积结构引入的。那就只能通过对运算过程进行约束来实现了。
- A way is to divide the token-mixing block vertically and horizontally.
- Another way is to make spatial correlations denser among some channels of token-mixing.
这里又一次出现了使用垂直与水平方向对计算进行划分的思路。类似的思想已经出现在很多方法中,例如:
- 卷积方法
- Axial-Attention Transformer方法
- Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
- CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
- MLP方法
- Hire-MLP: Vision MLP via Hierarchical Rearrangement
这里的第二点暂时不是太直观,看起来时对通道MLP进行了改进?
With this approach, we were able to improve the accuracy of the MLP-Mixer while reducing its parameters and computational complexity.
毕竟因为分治的策略,将原本凑在一起计算的全连接改成了沿特定轴向的级联处理。 粗略来看,这近似使得参数量从
变成了
。
Compared to other MLP-based models, the proposed model, named RaftMLP has a good balance of computational complexity, the number of parameters, and actual memory usage. In addition, our work indicates that MLP-based models have the potential to replace CNNs by adopting inductive bias. The source code in PyTorch version is available at https://github.com/okojoalg/raft-mlp.
主要内容
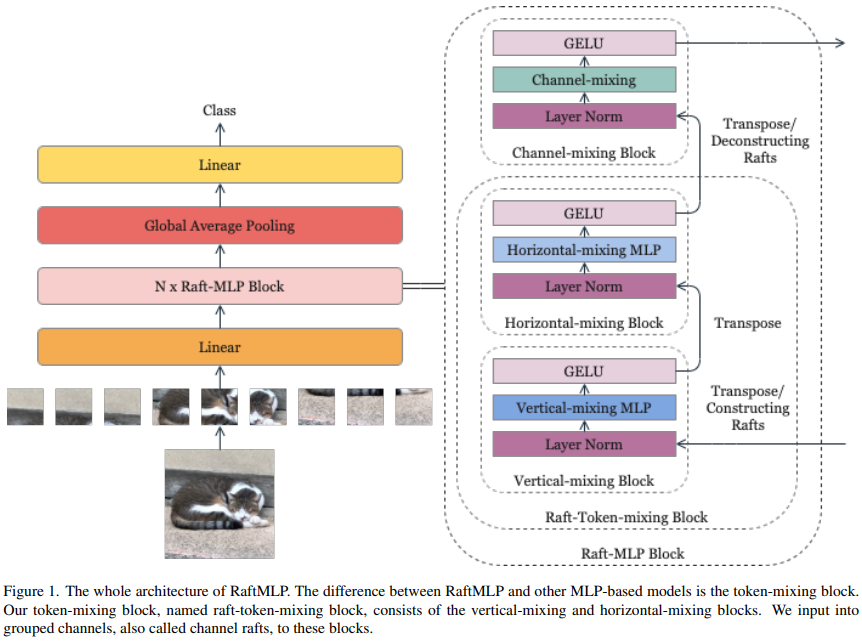
可以看到,实际上还是可以看作是对空间MLP的调整。
这里将原始的空间与通道MLP交叉堆叠的结构修改为了垂直、水平、通道三个级联的结构。通过这样的方式,作者们期望可以引入垂直和水平方向上的属于2D图像的有意义的归纳偏置,隐式地假设水平或者垂直对齐的patch序列有着和其他的水平或垂直对齐的patch序列有着相似的相关性。此外,在输入到垂直混合块和水平混合块之前,一些通道被连接起来,它们被这两个模块共享。这样做是因为作者们假设某些通道之间存在几何关系(后文将整合得到的这些通道称作Channel Raft,并且假定的是特定间隔 的通道具有这样的关系)。
的通道具有这样的关系)。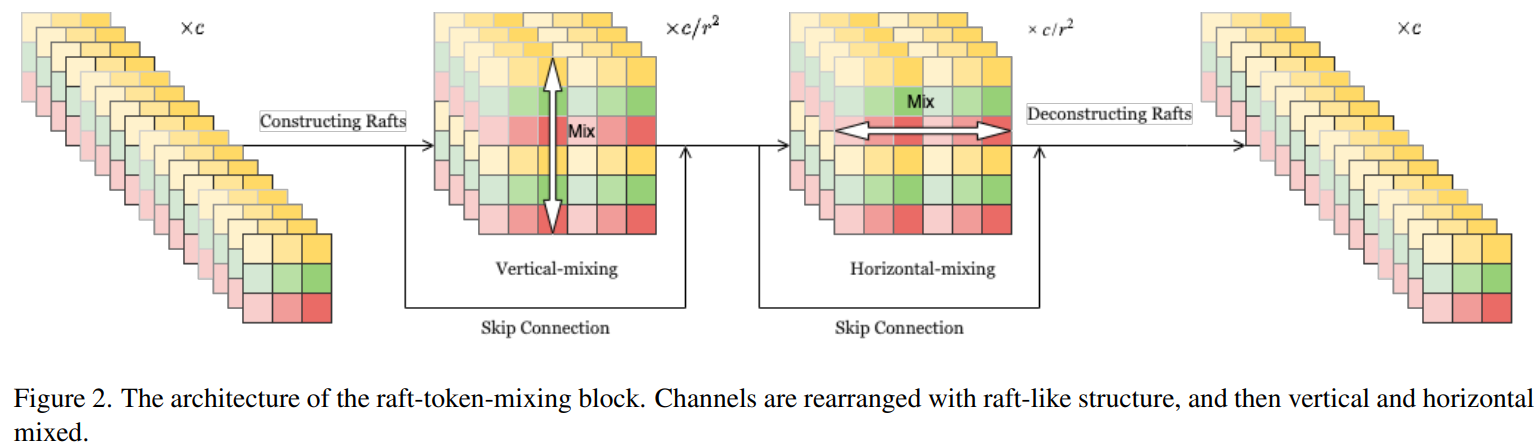
Vertical-Mixing Block的索引形式变化过程:((rhrwsr,h,w) -> (sr, rhh, rww) <=> (rwsrw, rh*h) (因为这里是通道和水平方向共享,所以可以等价,而图中绘制的是等价符号左侧的形式),Horizontal-Mixing Block类似。
针对水平和垂直模块构成的Raft-Token-Mixing Block,作者给出的代码示例和我上面等式中等价符号右侧内容一致。从代码中可以看到,其中的归一化操作不受通道分组的影响,而直接对原始形式的特征的通道处理。
class RaftTokenMixingBlock(nn.Module):# b: size of mini -batch, h: height, w: width,# c: channel, r: size of raft (number of groups), o: c//r,# e: expansion factor,# x: input tensor of shape (h, w, c)def __init__(self):self.lnv = nn.LayerNorm(c)self.lnh = nn.LayerNorm(c)self.fnv1 = nn.Linear(r * h, r * h * e)self.fnv2 = nn.Linear(r * h * e, r * h)self.fnh1 = nn.Linear(r * w, r * w * e)self.fnh2 = nn.Linear(r * w * e, r * w)def forward(self, x):"""x: b, hw, c"""# Vertical-Mixing Blocky = self.lnv(x)y = rearrange(y, 'b (h w) (r o) -> b (o w) (r h)')y = self.fcv1(y)y = F.gelu(y)y = self.fcv2(y)y = rearrange(y, 'b (o w) (r h) -> b (h w) (r o)')y = x + y# Horizontal-Mixing Blocky = self.lnh(y)y = rearrange(y, 'b (h w) (r o) -> b (o h) (r w)')y = self.fch1(y)y = F.gelu(y)y = self.fch2(y)y = rearrange(y, 'b (o h) (r w) -> b (h w) (r o)')return x + y
对于提出的结构,通过选择合适的 可以让最终的raft-token-mixing相较于原始的token-mixing block具有更少的参数(
可以让最终的raft-token-mixing相较于原始的token-mixing block具有更少的参数( ),更少的MACs(multiply-accumulate)(
),更少的MACs(multiply-accumulate)( )。这里假定
)。这里假定 ,并且token-mixing block中同样使用膨胀参数
,并且token-mixing block中同样使用膨胀参数 。
。
实验结果

这里的中,由于模型设定的原因,RaftMLP-12主要和Mixer-B/16和ViT-B/16对比。而RaftMLP-36则主要和ResMLP-36对比。
Although RaftMLP-36 has almost the same parameters and number of FLOPs as ResMLP-36, it is not more accurate than ResMLP-36. However, since RaftMLP and ResMLP have different detailed architectures other than the raft-token-mixing block, the effect of the raft-token-mixing block cannot be directly compared, unlike the comparison with MLP-Mixer. Nevertheless, we can see that raft-token-mixing is working even though the layers are deeper than RaftMLP-12.
关于最后这个模型36的比较,我也没看明白想说个啥,层数更多难道raft-token-mixing可能就不起作用了?
一些扩展与畅想
- token-mixing block可以扩展到3D情形来替换3D卷积。这样可以用来处理视频。
本文进引入了水平和垂直的空间归纳偏置,以及一些通道的相关性的约束。但是作者也提到,还可以尝试利用其他的归纳偏置:例如平行不变性(parallel invariance,这个不是太明白),层次性(hierarchy)等。
链接
- 代码:https://github.com/okojoalg/raft-mlp

若有收获,就点个赞吧
0 人点赞
