
简单介绍

“In this paper, we introduced an alternate way of localizing self attention with respect to the structure of data, which computes key-value pairs dynamically for each token, along with a more data efficient configuration of models. This helps create a model that utilizes both the power of attention, as well as the efficiency and inductive biases of convolutions” “Our efforts are inspired by the localized nature of convolutions and how they created more local inductive biases that are beneficial to vision tasks. It is different from self attention being applied to local windows (Swin), and can be thought of as a convolution with a content-dependant kernel”
在我看来,本文的核心在于将Swin中的局部Attention操作进行朝着卷积的方向更进一步扩展。作者们更强调本文的设计是从卷积的角度获得启发的。
本文的核心内容主要集中在三个方面:
- 提出了一个neighborhood attention操作。顾名思义,其以query对应的位置为中心来设定局部窗口,从而提取key和value进行计算。这是一种概念上更加简单、灵活和自然的的注意力机制。
- 基于提出的neighborhood attention构建了一个完整的vision transformer模型。模型延续始终分层的金字塔结构,每一层跟着一个下采样擦欧洲哦来缩减一半的尺寸。不同于现有的Swin等模型中采用的等效于非重叠卷积的操作,这里使用小尺寸且带重叠的卷积操作来进行特征嵌入和下采样。同时对于Stem阶段,同样采用了重叠卷积的操作。这些设定也带来了良好的效果,虽然会引入更多的计算成本和参数量,但是通过合理配置模型的结构,仍然可以获得足够优异的表现。
分类、检测、分割上都获得了良好的表现,超过了现有的众多方法,包括Swin和ConvNeXt等。对于28M参数这个近似于ResNet50的量级,在ImageNet1K上都可以达到83.2%的Top1的分类表现,确实效果很好。
核心操作

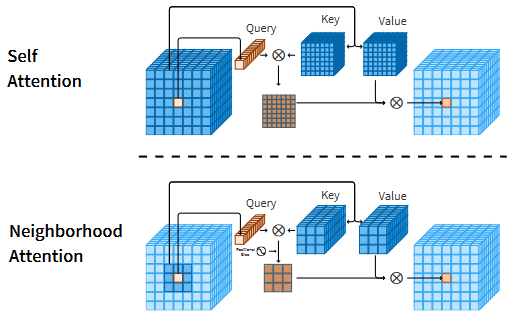

这个插图展示了自注意力操作和本文提出的NA之间的运算差异。自注意力操作允许每个token去和全局所有token之间进行交互;
- NA中会强制要求k,v的选择来自于以q为中心的邻域,即这里同时强调了两点,一个是局部区域,一个是以q为中心。
同时这里也体现出了和Swin这类的直接将原始的全局注意力机制约束到局部窗口内的局部注意力形式上的差异。
- 二者相同之处在于对于每个q都是和一个局部的窗口内的k和v来计算attention计算,这也因此使得二者之间的理论上的计算量是一致的,都是有着线性的计算复杂度和内存使用。
- 但是,本文的NA却有着一点额外的优势,即直接将注意力操作范围限制到了每个像素的邻域,而这些领域的计算天然地实现了一种类似于卷积那样的“滑动窗口”式的带重叠区域的交互,而不需要再像Swin那样需要额外借助于偏移操作来引入窗口的交互。同时更实际的一点是,也不再限制输入必须要能被窗口大小整除了。
“NA is a localization of dot-product self attention, limiting each query token’s receptive field to a fixed-size neighborhood around its corresponding tokens in the keyvalue pair.”
也就是说,从原本局部Attention操作的窗口内部计算标准Attention操作改为了特定点上的q和其局部范围内的kv计算Attention,即原本的固定等分的窗口变成了以q为中心的滑动窗口。
“Neighborhood Attention adaptively localizes the receptive field to a neighborhood around each token, introducing local inductive biases without a need for extra operations.” “This not only reduces computational cost compared to self attention, but also introduces local inductive biases, similar to that of convolutions.”
通过这样的形式,对Attention操作引入更多的局部偏置属性,从而针对视觉任务获得更好的表现。
“HaloNet [29] also explored a local attention block, and found that a combination of local attention blocks and convolutions resulted in the best performance, due to the best trade-off between memory requirements and translational equivariance.” “The authors argued that self attention preserves translational equivariance by definition, and that their local attention improves speed-memory tradeoff by relaxing this equivariance, while not greatly reducing the receptive field.”
HaloNet这篇文章其实策略与本文有相通之处,同样是重视并引入了卷积在视觉任务上的优良特性。
“Therefore, if the neighborhood size exceeds or matches the feature map size, neighborhood attention and self attention will have equivalent outputs given the same input.”
对于提出的Neighborhood Attention而言,如果邻域窗口超出或者正好等于特征图大小,那么就可以等效为标准的Self Attention了。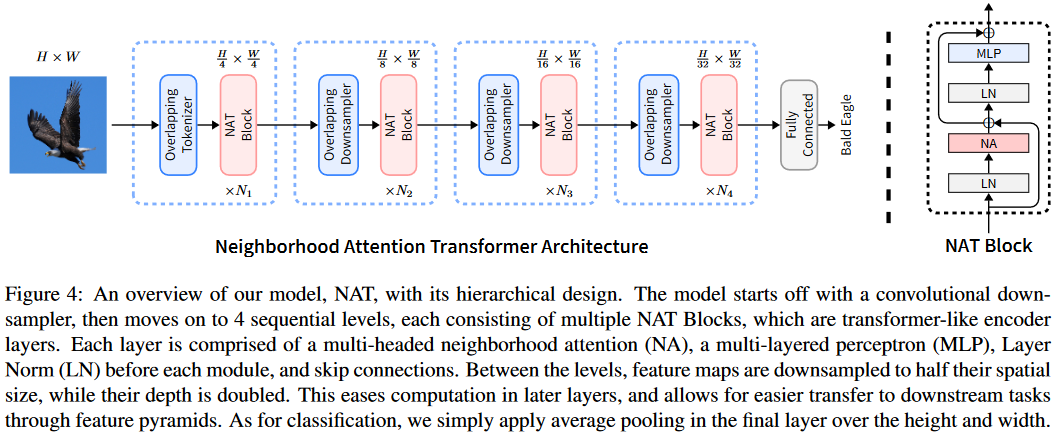
“Unlike Swin however, NAT uses overlapping convolutions to downsample feature maps, as opposed to non-overlapping (patched) ones. This creates a slight increase in computation and parameters, which we remedy by proposing new configurations that are less computationally expensive.”
“NAT embeds inputs using 2 consecutive 3 × 3 convolutions with 2 × 2 strides, resulting in a spatial size 1/4th the size of the input.”
NAT中,在下采样特征图和Stem阶段都使用的是重叠的跨步卷积操作。这不同于Swin。虽然可能引入更多的计算和参数,但是通过模型整体的配置,是可以得到更少计算量的结构的。
从公式来看,这里也对Attention Map上引入了局部的相对位置嵌入。
计算量和存储占用分析
“As for corner pixels that cannot be centered, the neighborhood is expanded to maintain receptive field size. This is a key design choice, which allows NA to generalize to self attention as the neighborhood size grows towards the feature map resolution.”
“For a corner pixel, the neighborhood is another 3 × 3 grid, but with the query not positioned in the center.”
对于角落的像素,在NAT的设定中,此时的局部邻域不再以其为中心,而是选择同样以其为角落的等大的局部邻域。具体可见本文开头引自代码仓库的动图。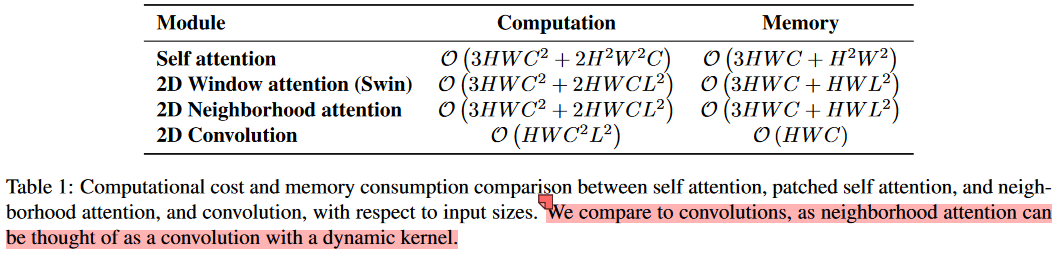
“Therefore, it can be concluded that 2D NA is less computationally complex than a 2D convolution in practical scenarios, while only suffering from the additional memory usage due to the QKV projections.”
文章对比了标准卷积、窗口注意力、文章提出的NA,以及标准的自注意力的计算和内存占用。卷积本身在内存占用上有着明显的优势,而且与窗口大小无关。而在计算量上,卷积与通道数量和方形窗口边长都呈二次关系。通过仔细对比二者的公式可知,在常用的通道和窗口配置下(例如L=3,C>3时),提出的NA在计算量上是可以小于标准卷积操作的。只是会有更多的内存占用。
“It is also equivalent in FLOPs and memory usage to Swin Transformer’s shifted window attention given the same receptive field size, while being less constrained. Furthermore, NA includes local inductive biases, which eliminate the need for extra operations such as pixel shifts.”
就理论计算量和内存使用而言,和Swin实际上是没有太大区别的,因为从更广的角度来看,都是每个q和一个局部窗口内的k和v计算。
“It is also noteworthy that Swin especially suffers from more FLOPs even beyond the original difference due to the fact that the image resolution input in this task specifically (512 × 512) will not result in feature maps that are divisible by 7 × 7, Swin’s window size, which forces the model to pad input feature maps with zeros to resolve that issue, prior to every attention operation. NAT does not require this, as feature maps of any size are compatible.”
而在实际的运算中,对于Swin这样的非重叠窗口的划分方式,在特征图尺寸无法被窗口尺寸整除的时候,是需要进行padding操作的。而本文的NA中,因为不会padding,所以由此造成的无用计算却是可以避免的。所以有时会出现相较于Swin,NT具有更少的FLOPs。
具体实现
“In PyTorch, the unfold function is the most straightforward solution.” “The combination of these two operations (unfold then replicated_pad) on the keyvalue pair tensors (H × W × C) will yield two tensors of shape H × W × C × L × L (one L × L for each channel and pixel). Neighborhood Attention can be computed by plugging these into (2) in the place of K and V.” “However, this implementation is highly inefficient, because it needs to temporarily store the extracted windows, and make 2 separate CUDA kernel calls on the very large tensors, just to replicate Neighborhood Attention. Additionally, it is not very flexible and makes the addition of relative positional bias very complicated.” “In order to resolve this issue, we wrote custom CUDA kernels for the QK and AV operations separately (leaving operations such as softmax and linear projections to the original kernels for the sake of efficiency).”
就具体实现而言,不考虑效率的情况下是可以使用pytorch自带的unfold操作和replicated_pad搭配来实现。
但是这并不是很有效,因为其需要存储每个提取出来的窗口的数据,并且要在非常大的张量上执行两个独立的CUDA核的调用。另外,这种设计也不够灵活,并且会使得添加相对位置编码的时候非常复杂。
于是本文是通过自定义CUDA核函数进行优化。但是当前的性能仍然有待进一步优化。
实验结果
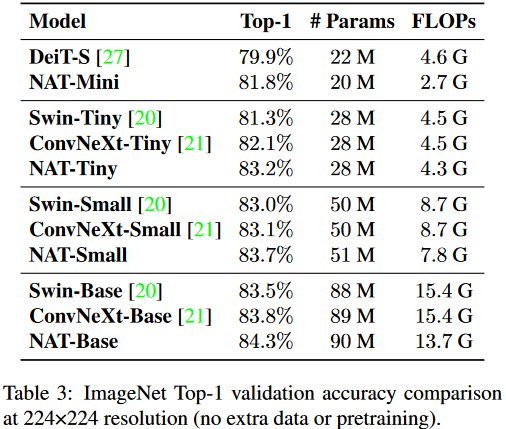
就性能而言,本文的效果确实不错,在28M这个近似于ResNet50的参数量级上已经实现了83.2的top1,确实比较强了。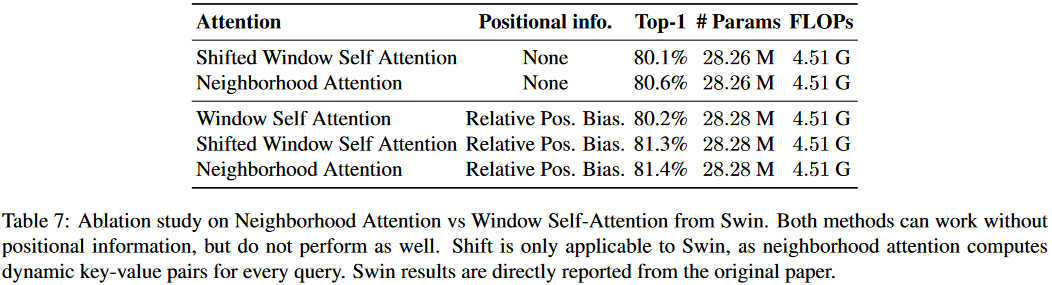
可以看到相对位置编码确实非常有用。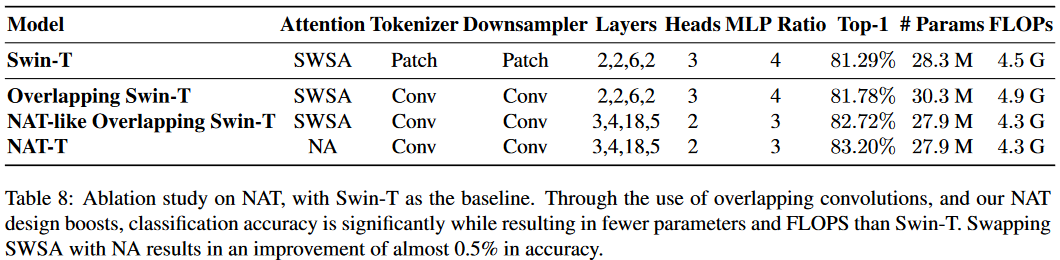
这里涉及到两个实验,可以看到Conv Tokenizer和Downsampler,以及提出的NA是更有效的。
- 注意力部分:将Swin的局部Attention改为本文提出的NA形式。
- tokenizer和downsampler部分:This change only involves using two 3 × 3 convolutions with 2 × 2 strides, instead of one 4 × 4 convolution with 4 × 4 strides, along with changing the downsamplers from 2×2 convolutions with 2×2 strides to 3 × 3 convolutions with the same stride.

“NAT appears to be slightly better at edge detection, which we believe is due to the localized attention mechanism, that we have presented in this work, as well as the convolutional tokenizer and downsamplers.”
在可视化部分,作者们可视化了部分验证集数据的Salient Map。可以看到图中对于目标边缘的反应比较清晰。这可能是因为提出的NA良好的局部偏置特性以及卷积Tokenizer和Downsampler带来的。也就是说,够强的局部偏置带来的效果。
相似文章
文章提出的策略实际上和另一篇google在2019年的文章非常相似:Stand-Alone Self-Attention in Vision Models。这类结构确实看起来非常自然,因为是在延续着卷积的思路,但是实现起来确实比较麻烦。不像卷积有着良好的基础框架的支持。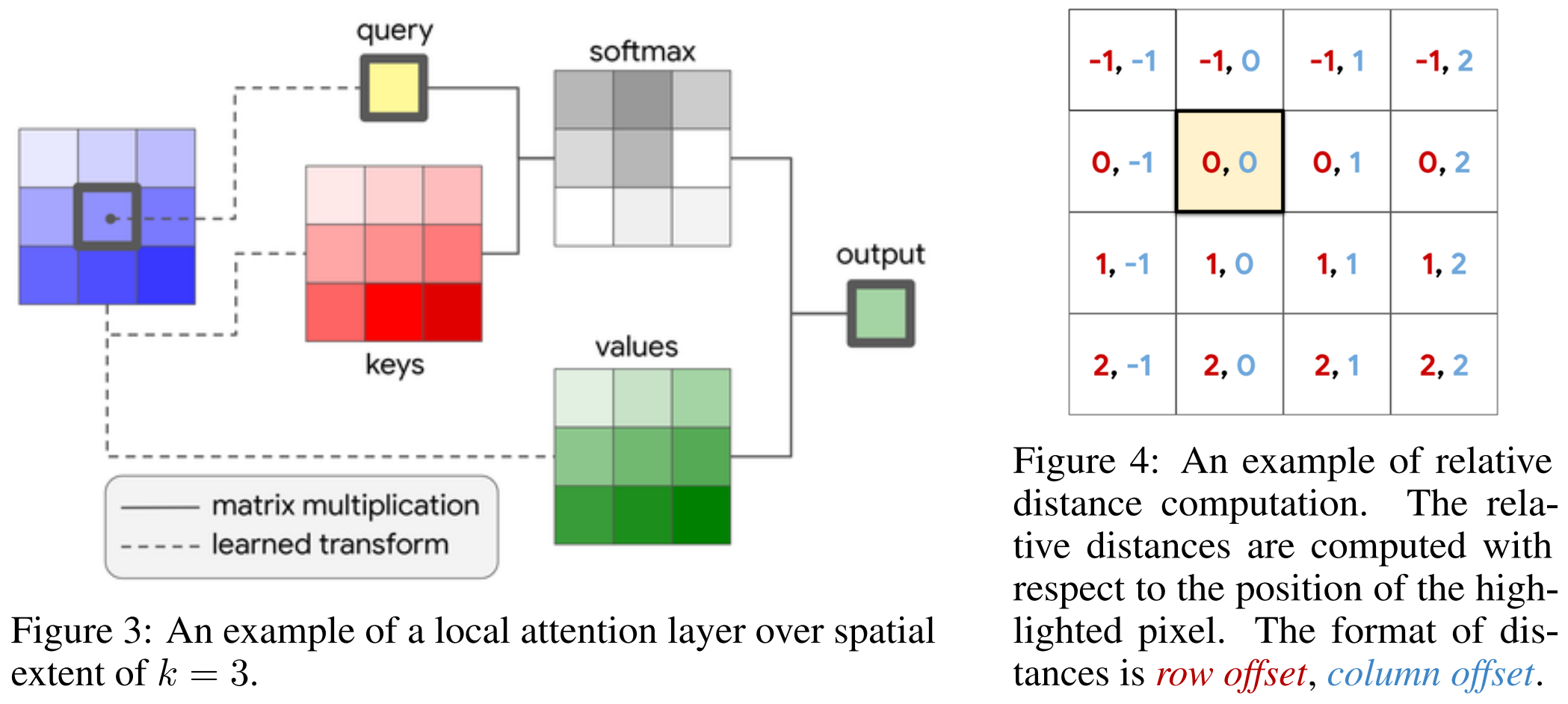
在问到与这篇工作的相似的时候,作者有如下回复。主要着重于两点,一点是邻域定义方式的不同,另一点是应用角度的不同。
Thank you for pointing this out. We actually cited a more recent follow-up work to SASA by the same group of authors, HaloNet. As stated in the paper, the idea of localizing attention is not a new idea, just as attention is not a new idea. Swin is also localizing attention (as others have too), but the difference is in the choice of receptive fields.
- A key difference between NA and SASA is in the definition of neighborhoods. NA is based on the concept of each pixel attending to its nearest neighbors, while SASA, following “same” Convolutions, is based on the concept of each pixel attending to its surrounding pixels only. Those two are very different at the edges, and the edges grow with window size (see our fig 6, or the animation in the README, for an illustration of how NA handles edges and corners). In addition, neither SASA nor HaloNet were open-sourced and thus are difficult to directly compare to; and HaloNet’s Table 1 seems to suggest that SASA even has a different computational complexity and memory usage compared to NA. So there may be other differences that we are not aware of.
- Another big difference between the papers is the application of NA vs SASA. SASA aimed to replace spatial convolutions in existing models, typically all with small kernel sizes for models like ResNets, while our idea is to use large-neighborhood NAs to build efficient hierarchical transformers that work well for both image classification and downstream vision applications, similar to what Swin Transformer is doing. This is the reason why our Related section did not focus on works such as SASA and HaloNet, because while there are similarities in their attention mechanisms, the focus and application of the papers are very different. Our NAT directly competes with existing state-of-the-art hierarchical models such as Swin.
相关链接

若有收获,就点个赞吧
0 人点赞
