
背景介绍
Google搜索引擎凭借其网页排名算法取得了巨大成功,该算法利用随机游走来利用网络的全局而非本地超链接结构。在这里,我们为位于欧几里德空间的数据提出了一种简单的通用排序算法,例如文本或图像数据。我们方法的核心思想是根据大量数据共同揭示的内在流形结构对数据进行排序。令人收到鼓励的来自合成数据、图像和文本数据的实验结果说明了我们的方法的有效性。

我们的兴趣在于,要排序的对象在欧几里德空间中表示为向量,例如文本或图像数据。我们的目标是根据大量数据共同揭示的内在全局流形结构对数据进行排序[Nonlinear dimensionality reduction by locally linear embedding,**Global geometric framework for nonlinear dimensionality reduction**]。我们相信,对于许多现实世界的数据类型,这应该优于局部方法,该方法仅通过成对欧几里德距离或内积来对数据进行排序。
让我们考虑一个 toy problem 来解释我们的动机。我们给出了一组以两个月形模式构建的点(图1a)。在上面的月形中给出查询,任务是根据其他点与查询的相关性对其进行排名。直观地,上面的月形数据对查询的相关度应沿着这个月形逐渐减小。对于下月中的点也应如此。此外,上面的月形数据中的所有点应该与查询相关,而不是下面的月形中的点。如果我们仅根据欧几里德距离对查询的点进行排序,则下面月形中最左边的点与上面月形中最右边的点相比将更加相关(图1b)。 显然这个结果与我们的直觉不一致(图1c是理想的结果)。
我们提出了一种简单的通用排序算法,它可以利用数据内在的流形结构。这种方法源于我们最近对半监督学习的研究[Learning with local and global consistency]。事实上,排序问题可以被视为半监督学习的极端情况,其中只有正标记点可用。
我们方法的直观描述如下:
- 我们首先在数据上形成加权网络,并为每个查询分配正排名分数,并为相对于查询排名的剩余点分配零。
- 然后所有点通过加权网络将他们的排名分数扩展到他们附近的邻居。
- 重复传播过程直到达到全局稳定状态,并且除了查询之外的所有点都根据它们的最终排名分数进行排名。
算法细节
算法设置:
- 给定点集X,包含n个点,第i个点记为xi,每个点都是一个m维的矢量。其中前q个点设置为查询点,剩余的n-q个点为想要排序的点,排序的依据就是他们与查询之间的相关性。
- 使用d表示点集X中的点之间的距离度量,例如欧氏距离,对于点xi和xj之间的距离表示为d(xi, xj)。
- 使用f表示排序函数,这个会赋给每个点xi一个排序值fi。f实际上可以认为是一个排序值的集合,对应的,一共有n个值,其中第i个值表示fi。
- 这里也定义矢量y,其中的第i个值指示了xi是否为查询,为查询则为1,否则为0。
- 如果对于查询点有先验知识,那么可以为查询分配不同的排名分数,与其各自(respective)的置信度成比例。
算法流程:
- 按照升序对所有点之间的成对距离排序。按照顺序重复使用边连接两个点,直到获得一个连接图(无环图)。
- 如果两个点之间有边连接,那么他们对应与关联矩阵W中的ij元素使用其距离的平方的指数形式(
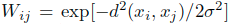 )来定义。由于图是无环的,所以对于ii元素就是0。
)来定义。由于图是无环的,所以对于ii元素就是0。 - 通过度矩阵(ii元素等于W的第i行的和)对关联矩阵进行对称标准化获得到S(
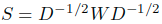 )。
)。 - 根据加权迭代的公式
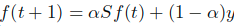 ,迭代计算排序值,直到收敛。
,迭代计算排序值,直到收敛。 - 根据排序的收敛得到排序得分f的极限情况,对所有点进行排序,分数越大越靠前。
可以直观地理解该迭代算法。
- 首先,在第一步中形成连接网络。
- 在第二步中简单地对网络进行加权,并且在第三步中将权重对称地归一化。
- 第三步的归一化是证明算法收敛的必要条件。
- 在第四步中,所有点通过加权网络将他们的排名分数扩散到他们的邻居。
- 重复传播过程直到达到全局稳定状态,并且在第五步骤中,根据它们的最终排名分数对点进行排序。
- 参数alpha指定了来自邻居的排名分数和初始排名分数的相对贡献。
- 值得一提的是,由于在第二步中将亲和矩阵的对角元素设置为零,因此避免了自增强(self-reinforcement)。另外,由于S是对称矩阵,所以信息会对称地扩散。
关于最终收敛结果闭式解的一个简单推导: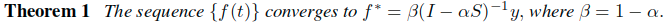
- 假设f(t)收敛到f*。进而替换前面提到的迭代公式中的f(t)和f(t+1),从而得到:
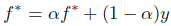
- 合并f*化简得到:
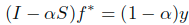
- 由于这里的
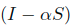 可逆,所以进一步得到:
可逆,所以进一步得到: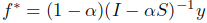
- 这里假设
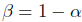 ,但是要清楚的是,这里的放缩因子beta对于最终的排序任务而言,并没有贡献,因此直接去掉,所以闭式解可以等价为:
,但是要清楚的是,这里的放缩因子beta对于最终的排序任务而言,并没有贡献,因此直接去掉,所以闭式解可以等价为: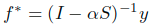
实验细节
论文中在三中数据集上进行了测试,一个是自己构造的 toy problem ,也就是前面显示的月形数据的排序问题,另外则是处理的图像与文本。这里主要介绍这个简单的 toy problem的情况。
在实验中,使用的闭式解,其中的alpha设置为0.99。
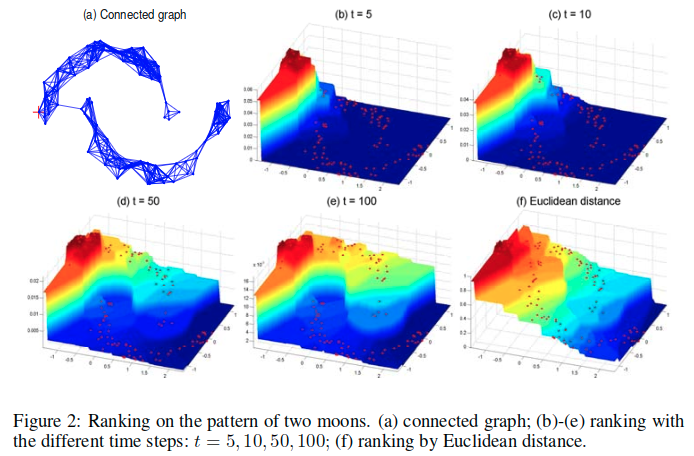
算法的第一步中描述的连通图如图2a所示。不同时间步长下的排名得分情况(t=5, 10, 50, 100)显示在图2b-e中。请注意,每个月形区域上的分数沿着月形整体形状远离而减少,并且包含查询点的月形上的分数大于其他月形上的分数。欧几里德距离的排序得分如图2f所示,其无法捕捉到两个月形数据的结构。
值得一提的是,简单地根据图上的最短路径[Global geometric framework for nonlinear dimensionality reduction]对数据进行排序并不奏效。特别是,为了引起读者注意,在图2a中画了一个连接两个月形的长边。这可以看出来,最短路径对图中的微小变化很敏感。强大的解决方案是组合两点之间的所有路径,并通过递减因子对它们进行加权。这正是我们所做的。请注意,封闭形式可以扩展为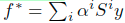 。
。
参考链接
- 论文:
- 本文:http://papers.nips.cc/paper/2447-ranking-on-data-manifolds.pdf
- 本文作者的另一份工作(Learning with Local and Global Consistency):https://www.microsoft.com/en-us/research/wp-content/uploads/2017/01/LLGC.pdf

若有收获,就点个赞吧
0 人点赞
