
主要贡献
- 对于显著性目标检测任务进一步明确其主要的两个难点,是一个对于变与不变都有需求的问题.
- 针对变与不变,提出了一种分而治之的模型,三支路各自实现不同的任务,三者相互补充.
- 提出了一种新颖的ASPP的替代结构.不同扩张率的分支的特征逐个传递,实现了丰富的多尺度上下文信息的提取.
针对问题
这篇文章还是从显著性目标边界的角度入手,着重解决两个问题:
- First, the interiors of a large salient object may have large appearance change, making it difficult to detect the salient object as a whole.
- Second, the boundaries of salient objects may be very weak so that they cannot be distinguished from the surrounding background regions.
这实际上也就是所谓的 selectivity–invariance dilemma(困境) (我们需要一组特征,它们能够选择性地响应图片中的重要部分,而对图片中不重要部分的变化保持不变性)。显着对象的不同区域(内部与边界)对SOD模型提出了不同的要求,而这种困境实际上阻止了具有各种大小,外观和上下文的显着对象的完美分割。
In the interiors, the features extracted by a SOD model should be invariant to various appearance changes such as size,color and texture. Such invariant features ensure that the salient object can pop-out as a whole. However, the features at boundaries should be sufficiently selective at the same time so that the minor difference between salient objects and background regions can be well distinguished.
主要方法
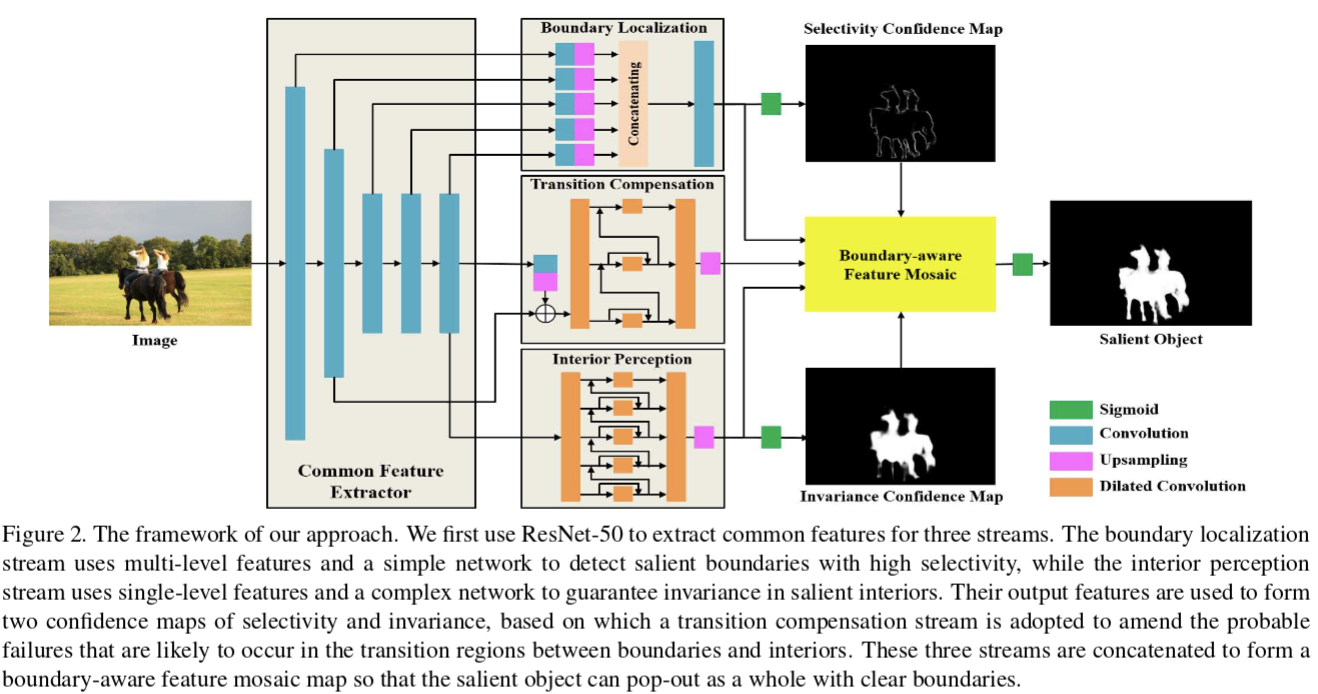
图中的特征提取网络使用的是ResNet50,但是对于第四个和第五个卷积块的步长设置为1,使其不改变分辨率,同时为了扩大感受野,在这两个结构里又使用了扩张率分别为2和4的扩张卷积。最终该网络仅会下采样输入的1/8。
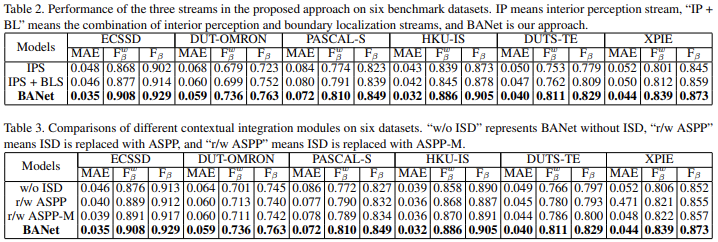
这篇文章提出的应对方法就是adopt different feature extraction strategies at object interiors and boundaries,在分析文章https://blog.csdn.net/c9yv2cf9i06k2a9e/article/details/99687783中指出,这里与BASNet的策略有些相似,只是这里使用了分支网络来实现边界的增强,而BASNet使用了损失函数来处理。
这里在特征提取网络的基础上构建了三个分支,来进行可选择性(selective)和不变性(invariance)特征的提取,同时修正边界与内部过渡区域的误判情况。分别称为:
- boundary localization stream:the boundary localization stream is a simple subnetwork that aims to extract selective features for detecting the boundaries of salient objects
- interior perception stream:the interior perception stream emphasizes the feature invariance in detecting the salient objects
- transition compensation stream:a transition compensation stream is adopted to amend the probable failures that may occur in the transitional regions between interiors and boundaries, where the feature requirement gradually changes from invariance to selectivity
同时也提出了integrated successive dilation module来增强interior perception和transition compensation两个信息流,可以获得丰富的上下文信息产生,以使其可以对于各样的视觉模式都能提取不变的特征,并引入来自低级特征的跳跃连接以促进边界的选择性表示。该模块结构如下:
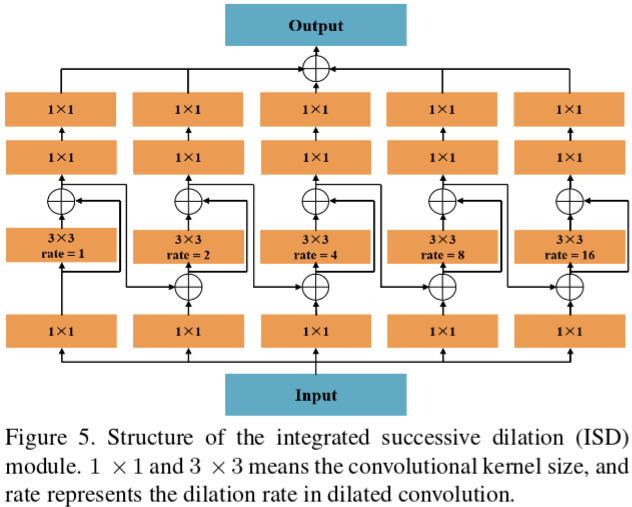
The ISD module with N parallel branches with skip connections is denoted as ISD-N, and we show the structureof ISD-5 in Fig.5 as an example. 从实现的角度来看,五个支路是需要有先后顺序的,得从左往右开构建。
- The first layer of each branch is a convolutional layer with 1×1 kernels that is used for channel compression.
- The second layer of each branch adopts dilated convolution, in which the dilation rates start from 1 in the first branch and double in the subsequent branch.
- 通过不同分支之间的跳跃连接,the feature map from the first branch of the second layer is also encoded in the feature maps of subsequent branches, which actually gets processed by successive dilation rates.
- After that, the third and the forth layers adopt 1×1 kernels to integrate feature maps formed under various dilation rates.
In practice, we use ISD-5 in the interior perception stream and ISD-3 in the transition compensation streams.
这里损失函数包含几部分:
- 边界交叉熵损失E,这里的GB表示the boundary map of salient objects:
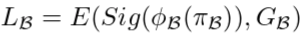
- 内部交叉熵损失E:
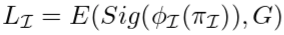
- 最后的交叉熵损失E:
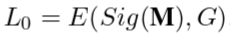
这里第三个损失中,Sig(M)表示最终的预测结果,这里的M是对三路信息流特征的整合,这里的整合方式没有使用常规的元素级加法或者拼接,因为相对而言效果不好.作者自行设计了一种方法: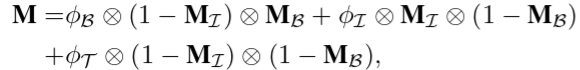

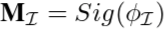
这里的三个 表示B(边界定位)/I(内部感知)/T(过渡补偿)三个分支输出的单通道特征图.
表示B(边界定位)/I(内部感知)/T(过渡补偿)三个分支输出的单通道特征图.
最终训练用的损失是一个三者的组合: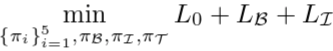
实验细节
- The training images are not done with any special treatment except the horizontal flipping.
- The training process takes about 15 hours and converges after 200k iterations with mini-batch of size 1.
- During testing, the proposed network removes all the losses, and each image is directly fed into the network to obtain its saliency map without any pre-processing.
- The proposed method runs at about 13 fps with about 400 × 300 resolution on our computer with a 3.60GHz CPU and a GTX 1080ti GPU.

参考链接

若有收获,就点个赞吧
0 人点赞
