
主要亮点
- 金字塔注意力模块
- 显著性边缘检测模块
- 融合多级预测进行最终输出
网络结构
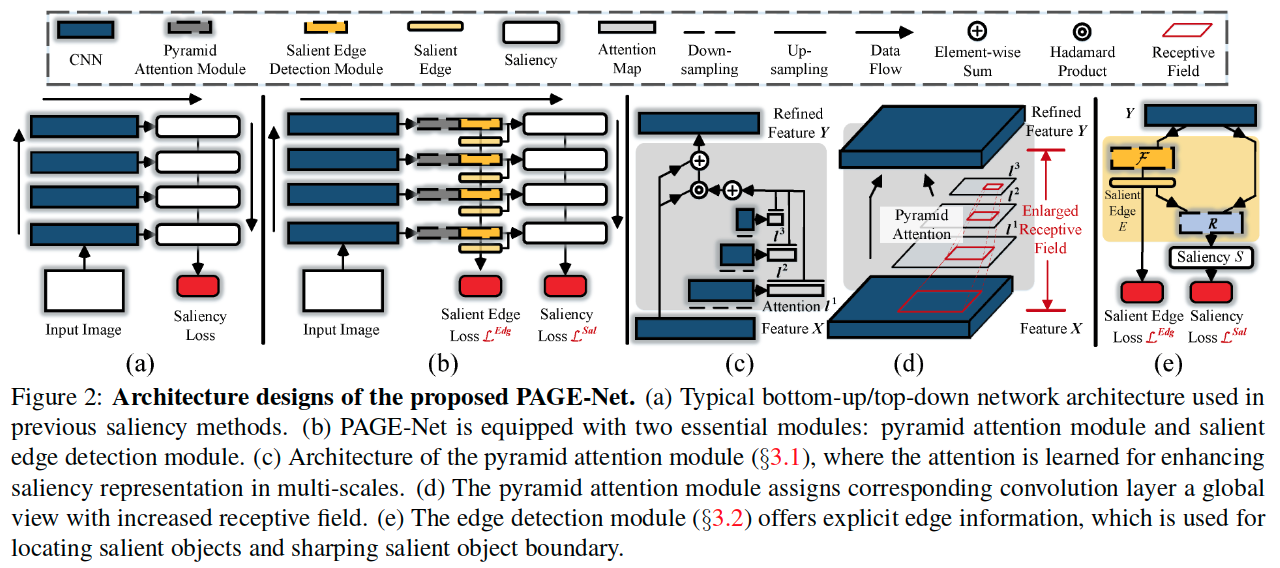
从上面的图中可以看出来,主要的两个结构可以在c和e中展示。分别介绍。
Pyramid Attention Module(2c)
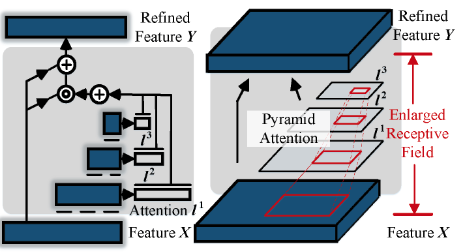
- 对于这里的X表示的而是对应于编码器特征X进行下采样之后的特征:
 ,这里有N层金字塔层。
,这里有N层金字塔层。 - 这里可以得到的是一个重要性图,即软注意力图:
 ;
; ,这里的i和式子1中的i含义相同,就是对于当前特征中的所有的点进行索引。
,这里的i和式子1中的i含义相同,就是对于当前特征中的所有的点进行索引。 - 通过对于该模块里得到的对应于所有
 计算注意力图集合:
计算注意力图集合: 。
。 - 最终将所有的注意力图进行放缩,调整到原始的该层分辨率的大小(MxM),得到一个新的注意力图集合:
 。
。 - 最终所有的注意力图会相加后与原特征进行哈达马乘积计算,初步的加权后的特征图。
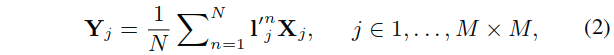
- 但由于被注意力图细化后的特征有大量的值趋于0,不利于梯度的传播,这里使用了一个额外的短连接作为改进,这使得,尽管较小的注意力值的情况下,也就是l‘近似于0,来自原始特征X的信息仍然可以保留下来。
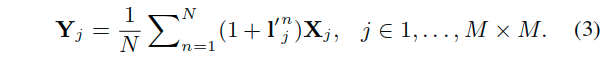
这样的金字塔注意力结构提供了一个赋予每个对应的卷积层(会拥有一个增大了的感受野,图2d)一个全局视角。

来自不同位置的特征对于显着性计算的贡献并不相同。 因此,引入注意机制来关注那些对显着对象的本质最重要的位置。通过设计,注意力模块可以通过迭代地对特征图进行下采样,来快速收集多尺度信息。这种金字塔结构使得特征层的感受区域能够容易且迅速地扩大。与之前的注意力模型相比,这里的金字塔注意力更加有利,因为它有效地通过扩大的感受野,利用了多尺度特征和强大的表示。所有这些都是像素显着性估计所必需的。
Salient Edge Detector(2e)
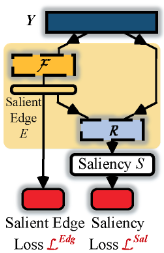
这里从图上可以看出来,实际上利用了一个残差结构。对于输入的当前特征Y进一步进行处理,残差支路进行边缘的预测,而恒等连接部分则保留了原始的特征信息,最终融合来自残差支路的边缘预测,通过一个readout处理R来进行最终的预测。当然,这里的图绘制的有些简略,图b中的数个阶段都有输出,但是最终的预测是在网络的最后。
在计算损失监督的时候,这里是会用L2损失来监督边缘预测。也就是下面公式4所描述的过程:
- 这里的P表示的是对应的显著性目标边界图。
- 这里的K表示的是训练数据的总数。
而另外的显著性图预测的线路,则是通过一个显著性读出网络R,输入原始特征图Y和显著性边缘图E,也就是F(Y),进而得到该阶段的初步显著性估计。
因此,对于这个整个模块的损失可以表示为:

- 这里的显著性的损失使用的是加权的交叉熵损失,考虑了计算损失的样本中,显著性与分显著性像素数量的不平衡。
- 式子6中的i索引了图像I中的像素。
- 这里的beta是在真值G中,显著性像素所占的比例。
利用这样得到的显著性损失,实际上R可以学习到,使用显式的边缘信息来优化显著性目标估计。
Dense connection
由于神经网络的层次性,引入密集连接,以利用来自不同层的信息,并增加表示能力。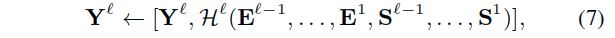
- 对于第l层的显著性特征Y,可以通过使用所有的之前层(1~l-1层)特征来进行进一步融合优化:
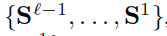 和
和 。
。 - 这里的H表示用于上采样和拼接来自所有先前层的输入的小型网络。
- 这里的第1层应该指的是编码器最终的那一层。
Discussion
- 为了保留更多的边界信息,添加了一个显着的边缘检测模块F,专门关注在真值边缘图P的监督下的对分割显着对象边界的优化。请注意,F可以包含其他边缘感知滤波器,例如Semantic image segmentation with task-specific edge detection using cnns and a discriminatively trained domain transform。
- 然后使用显着性特征Y和来自F的显式显着边缘信息来学习用于检测显着目标的读出网络R。
- 通过重新使用来自其他层的信息来进一步引入密集连接以绘制代表性功率。
Detailed Network Architecture

- Backbone Network
- The backbone network is built from the VGG-16 model. The first five convolutional blocks of VGG-16 are adopted. As shown in Fig. 5, we omit the last pooling layer (pool5) to preserve more spatial information.
- Pyramid Attention Module
- Let
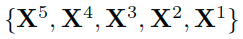 denote the features from the last convolution layers of five conv blocks: conv1-2, conv2-2, conv3-3, conv4-3, and conv5-3.
denote the features from the last convolution layers of five conv blocks: conv1-2, conv2-2, conv3-3, conv4-3, and conv5-3. - 对于每个X,首先将其下采样到多个尺度(金字塔),对于尺度n,注意力模块包含三个连续操作:BN-Conv1x1-ReLU,这里最小的注意力图被设置为i14x14。上采样操作被应用来放缩注意力图
 到原始的尺寸。
到原始的尺寸。 - 最终通过式子3来获得一个增强的显著性表示Y。
- Let
- Edge Detection Module
- The edge detection module F is defined as: BN-Conv(3×3, 64)-ReLU-Conv(1×1, 1)-sigmoid.
- The saliency readout function R is built as: BN-Conv(3×3, 128)-ReLU-BN-Conv(3× 3, 64)-ReLU-Conv(1×1, 1)-sigmoid.
- For ℓ-th layer,
- a set of upsampling operations (H) is adopted in order to enlarge all salient object estimations and salient edge information from all preceding layers with current feature resolutions(密集连接前调整分辨率).
- We then update the saliency representation Y through Eq.7.
- Next, the edge detection module F and saliency readout function R are adopted to generate the corresponding saliency map S.
- 最终的S就是最终输出。
- Overall Loss.
- All the training images {I} are resized to fixed dimensions of 224×224×3.
- The salient boundary maps Pk∈{0,1} are generated from the corresponding ground truth salient object map Gk∈{0,1} and dilated to a three-pixel radius.
- Considering all five-side outputs, the overall training loss for a train-ing image I is:
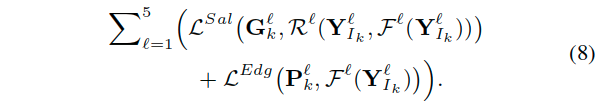
- Implementation Details
- PAGE-Net is implemented in Keras.
- We use THUS10K, containing 10,000 images with pixel-wise annotations, for training.
- During the training phase, the learning rate is set to 0.0001 and is decreased by a factor of 10 every two epochs.
- In each training iteration, we use a mini-batch of 10 images.
- The entire training procedure takes about 7 hours using an Nvidia TITAN X GPU.
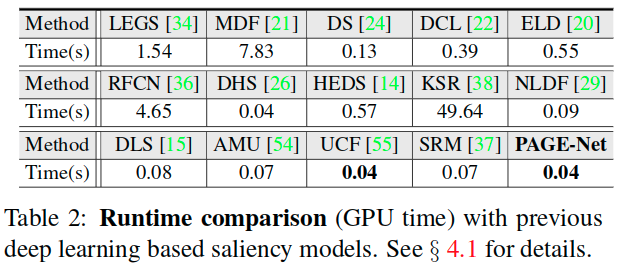
- Since our model does not need any pre- or post-processing, the inference only takes 0.04s to process an image of size 224×224. This makes it faster than most deep learning based competitors.
实验细节
- About other models: we use either the implementations with the recommended parameter settings or the saliency maps shared by the authors.
- For a fair comparison, we exclude other ResNet-based models, or the ones using more training data.
与现有模型的比较
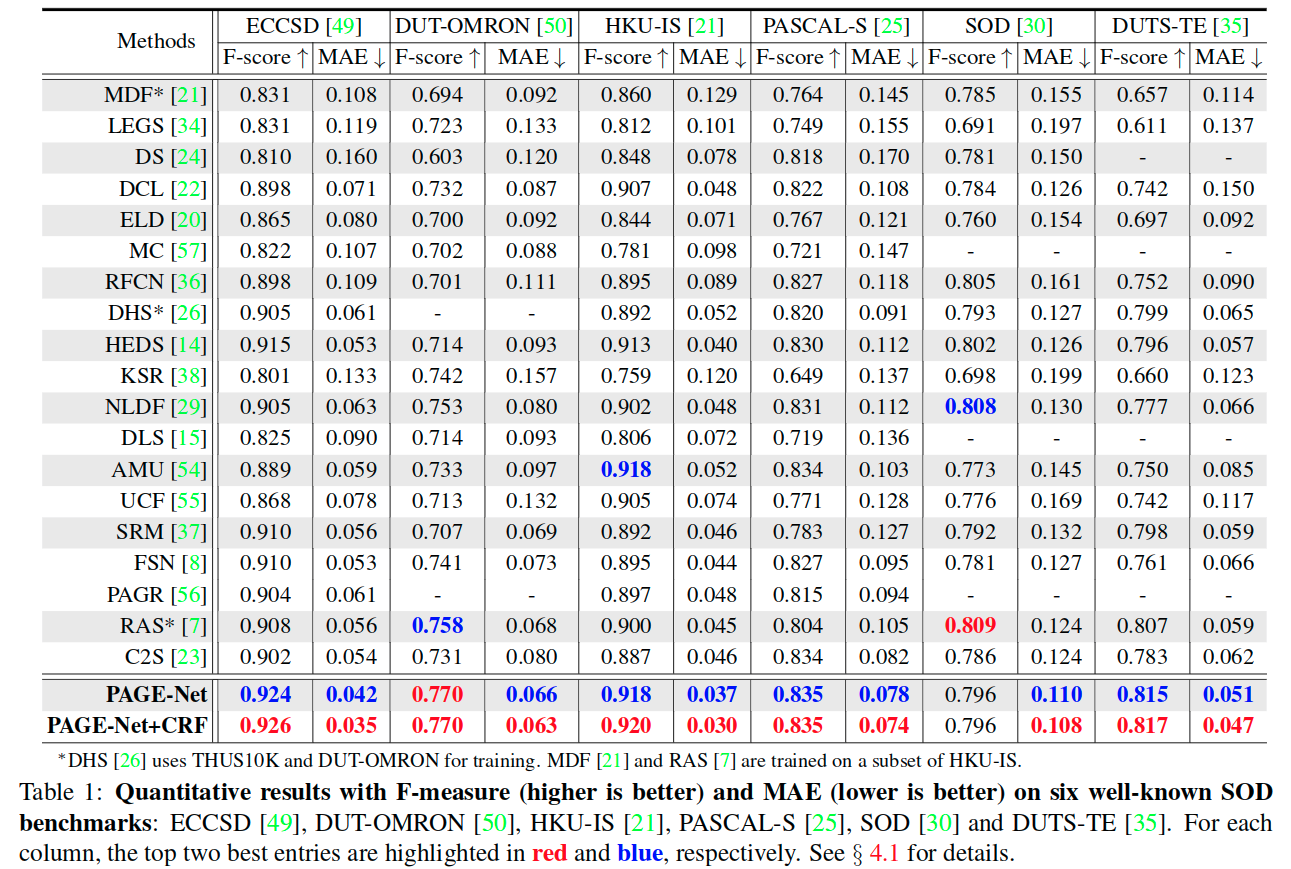
 **
**
In particular, PAGE-Net shows a significantly improved F-measure compared to the second best method, RAS, for the DUT-OMRON dataset (0.770 vs 0.758), which is one of the most challenging benchmarks. This clearly demonstrates the superior performance of PAGE-Net in complex scenes.
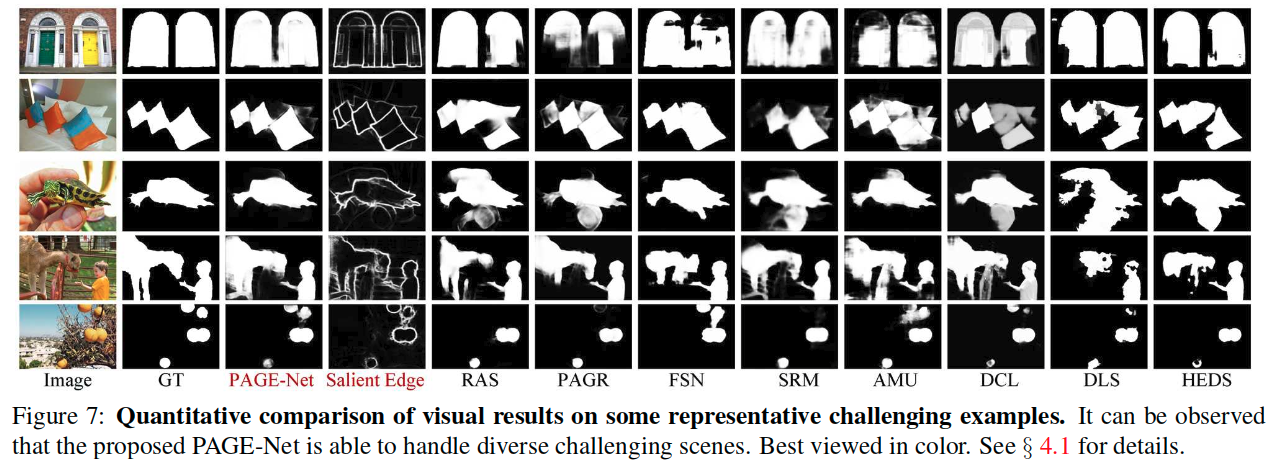
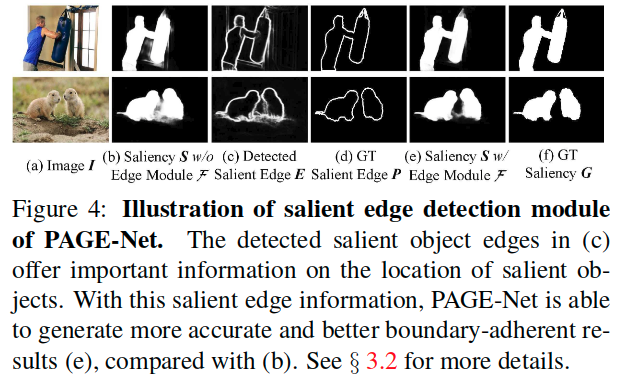
We find that PAGE-Net performs well in a variety of challenging scenarios, e.g., for large salient objects (first row), low contrast between objects and backgrounds (second row), cluttered backgrounds (forth row), and multiple disconnected objects (last row). Additionally, we observe that our method captures salient boundaries quite well due to its use of salient edge detection modules.
速度
**
Multi-Scale Attention的有效性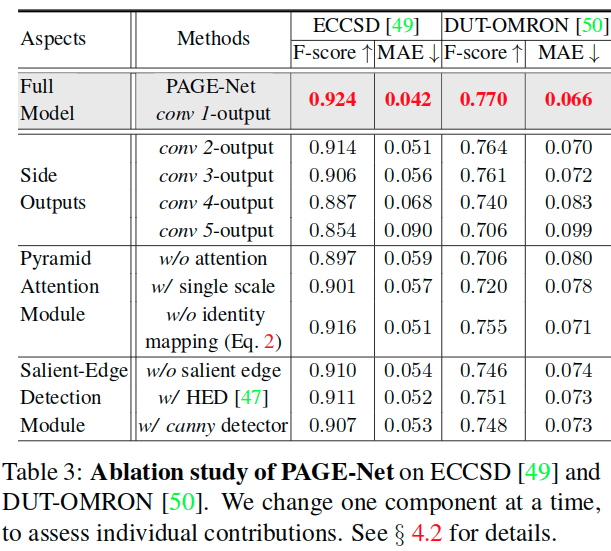 **
**
The baseline _w/ single scale _corresponds to the results obtained with a single-scale attention module (N=1 in Eq. 3).
Salient Edge Information的影响
To provide deeper insight into the importance of salient edge information, we test the model again after replacing the salient edge detection module with two different edge detectors: HED and the canny filter.
还观察到两种情况下的性能都有轻微下降。这表明使用显着边缘信息对于获得更好的性能至关重要。这是因为显着边缘提供了用于检测和分割显着目标的信息提示,而不是简单地确定颜色或强度变化。
Side Outputs的有效性
Finally, we study the effect of our hierarchical architecture on inferring saliency in a top-down manner (Fig.2(b)).
We introduced four additional base-lines corresponding to the outputs from the intermediate layers of PAGE-Net: conv2-output, conv3-output, conv4-output, and conv5-output. Note that the final prediction of PAGE-Net can be viewed as the output from the conv1 layer. We find that the saliency results are gradually optimized by adding more details from the lower layers.
**
相关链接

若有收获,就点个赞吧
0 人点赞
